终于讲到了排序的重点了。快排即使不是排序中最经典的算法,能算上是非常出色的算法了。
快速排序是一种基于分治技术的重要排序算法,是冒泡算法的一种改进。是由东尼.霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要O(n log n)次比较。在最坏状况下则需要Ο(n2)次比较,但这种状况并不常见。事实上,快速排序通常明显比其他Ο(n log n) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
快速排序用分治的思想,将一个整串分为两个子串。左边子串中所有的数都不会大于右边子串中的数。
步骤为:(1)从数组中挑选一个数作为“中轴”,(选择中轴有许多不同的策略,不过我们一般会选择数组的第一个元素)。
(2)重新排列数组,使得所有比中轴小的元素放在中轴的左边,所有比中轴大的元素放在中轴的右边,中轴元素放在中间。当然,跟中轴相等的数放在哪边都无所谓。
(3)按上述步骤递归执行新生成的子串。
递归的最底层是零个或者一个数,也就说是已经排好序的。
我看了网上很多的数学证明,也不想多说。再说,即使用数学证明出来了,实际应用也是另一回事。我到现在也就知道快排的最好、平均和最坏的时间复杂度,而没有去纠结是怎么证明出来的(或许这样不好吧)。最好:O(nlogn), 平均:O(1.38nlogn,也就是nlogn),最坏:O(n2)。平均情况下只比最好情况多执行38%的比较操作,不过最坏情况下就已经是平方的数量级了。
被快速排序所使用的空间,依照使用的版本而定。使用原地(in-place)分区的快速排序版本,在任何递归调用前,仅会使用固定的額外空間。然而,如果需要产生O(logn)嵌套递归调用,它需要在他们每一个存储一个固定数量的信息。因为最好的情况最多需要O(log n)次的嵌套递归调用,所以它需要O(log n)的空间。最坏情况下需要O(n)次嵌套递归调用,因此需要O(n)的空间。
然而我们在这里省略一些小的细节。如果我们考虑排序任意很长的数列,我们必须要记住我们的变量像是left和right,不再被认为是占据固定的空间;也需要O(log n)对原来一个n项的数列作索引。因为我们在每一个堆栈框架中都有像这些的变量,实际上快速排序在最好跟平均的情况下,需要O(log2 n)空间的比特数,以及最坏情况下O(n log n)的空间。然而,这并不会太可怕,因为如果一个数列大部份都是不同的元素,那么数列本身也会占据O(n log n)的空间字节。
非原地版本的快速排序,在它的任何递归调用前需要使用O(n)空间。在最好的情况下,它的空间仍然限制在O(n),因为递归的每一阶中,使用与上一次所使用最多空间的一半,且
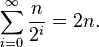
它的最坏情况是很恐怖的,需要

空间,远比数列本身还多。如果这些数列元素本身自己不是固定的大小,这个问题会变得更大;举例来说,如果数列元素的大部份都是不同的,每一个将会需要大约O(logn)为原来存储,导致最好情况是O(n log n)和最坏情况是O(n2 log n)的空间需求。
1 <?php 2 //交换两个数 3 function swap(&$x, &$y){ 4 $temp = $x; 5 $x = $y; 6 $y = $temp; 7 } 8 function partition(&$a, $left, $right){ 9 $p = $a[$left]; 10 $i = $left; 11 $j = $right+1; 12 do{ 13 //寻找大数 14 do{ 15 $i++; 16 }while($a[$i]<$p && $i<=$j); 17 //寻找小数 18 do{ 19 $j--; 20 }while($a[$j]>$p && $j>=$i); 21 //交换 22 swap($a[$i], $a[$j]); 23 }while($i<$j); 24 25 swap($a[$i], $a[$j]); 26 swap($a[$left], $a[$j]); 27 28 return $j; 29 } 30 31 //快排,数组,左边界,右边界(数组长度) 32 function quickSort(&$a, $left, $right){ 33 if($left>=$right){ 34 return; 35 } 36 $mid = partition($a, $left, $right); 37 quickSort($a, $left, $mid); 38 quickSort($a, $mid+1, $right); 39 } 40 ?>
快排的算法很简单,而且大部分高级语言的排序库函数都是用的快排。不过我们从快排的这个分治思想中还是能够学到很多的东西的。
(1)第一个就是在数量级很大的数中寻找第j大(小)的数,这个j一般小于等于10,比如在100万个数中找出第3小的数。我们通常的想法是用一种最快的排序算法,比如堆排序或者归并排序,将整个数组排好序之后取出第三个数。这样时间复杂度是O(nlogn)。可是如果我们用快排的思想,只需要O(n)的时间复杂度就行了。因为我们就是要的第3小的数,而不关心其他的数是第几,因此我们只需要取出下标是2(下标从0开始)数就是第三小的数了。因此,我们改进一下quickSort()函数,在返回$mid后,判断一下$mid与3的大小。如果正好等于3那么正好找到了,如果比3大,那么我们需要在后面的部分找,否则我们在前面的部分找。
(2)在大数量级中找出前10个最小的数,这个与第一种情况是一样的,只需要检测返回的$mid值就行了,不过这个返回的是一个数组罢了。
(3)在有n个实数组成的数组中,有正数,有负数,怎样让所有的负数都位于正数之前。这个通过快排就非常好解决了。我们自己可以认为地引入一个0,然后对数组进行一次快速排序就可以了。
好的,快排就先这样吧。