背景
• 引入原因:
– 对存在HDFS上的文件或HBase中的表进行查询时,是要手工写一堆MapReduce代码 – 对于统计任务,只能由动MapReduce的程序员才能搞定 – 耗时耗力,更多精力没有有效的释放出来
• Hive基于一个统一的查询分析层,通过SQL语句的方式对HDFS上的数据进行查询、统计和分析
Hive 是什么
• Hive是一个SQL解析引擎,将SQL语句转译成MR Job,然后再Hadoop平台上运行,达到快速 开发的目的。
• Hive中的表是纯逻辑表,就只是表的定义等,即表的元数据。本质就是Hadoop的目录/文件, 达到了元数据与数据存储分离的目的
• Hive本身不存储数据,它完全依赖HDFS和MapReduce。
• Hive的内容是读多写少,不支持对数据的改写和删除
• Hive中没有定义专门的数据格式,由用户指定,需要指定三个属性:
– 列分隔符
– 行分隔符
– 读取文件数据的方法
Hive 中的SQL 与传统SQL区别

与传统关系数据库特点比较
• hive和关系数据库存储文件的系统不同,hive使用的是hadoop的HDFS(hadoop的分布式文件 系统),关系数据库则是服务器本地的文件系统;
• hive使用的计算模型是mapreduce,而关系数据库则是自己设计的计算模型;
• 关系数据库都是为实时查询的业务进行设计的,而hive则是为海量数据做数据挖掘设计的,实时 性很差
• Hive很容易扩展自己的存储能力和计算能力,这个是继承hadoop的,而关系数据库在这个方面 要比数据库差很多。
Hive 体系架构
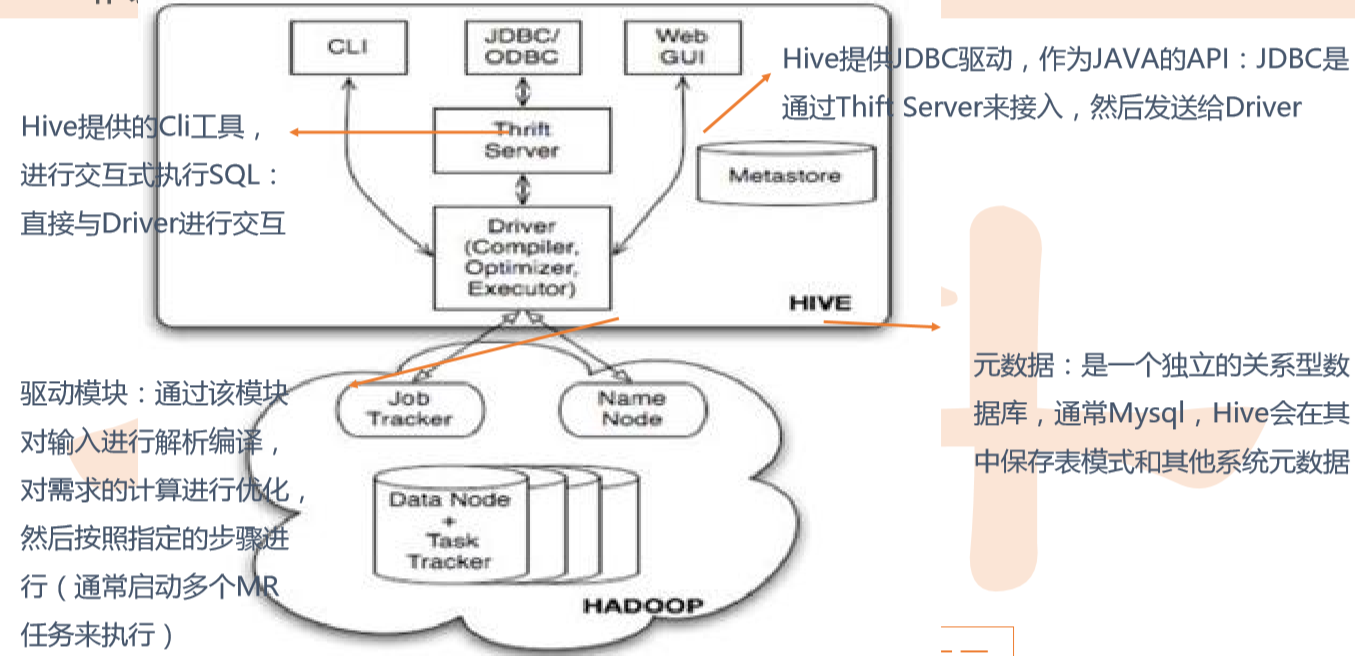
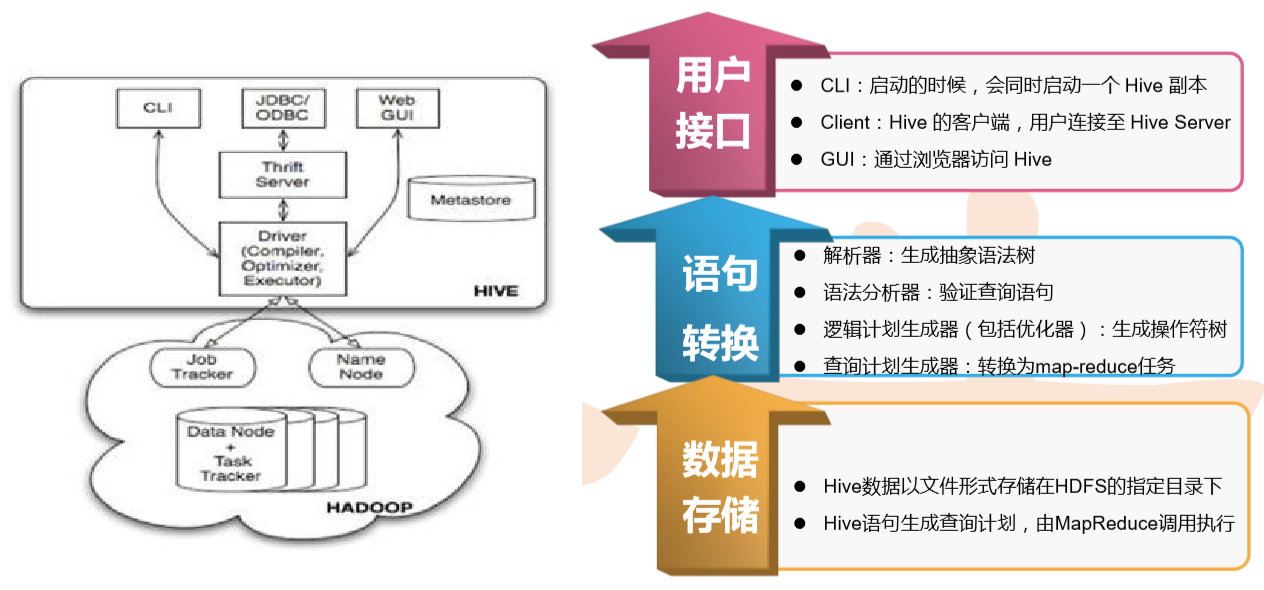
Hive数据管理
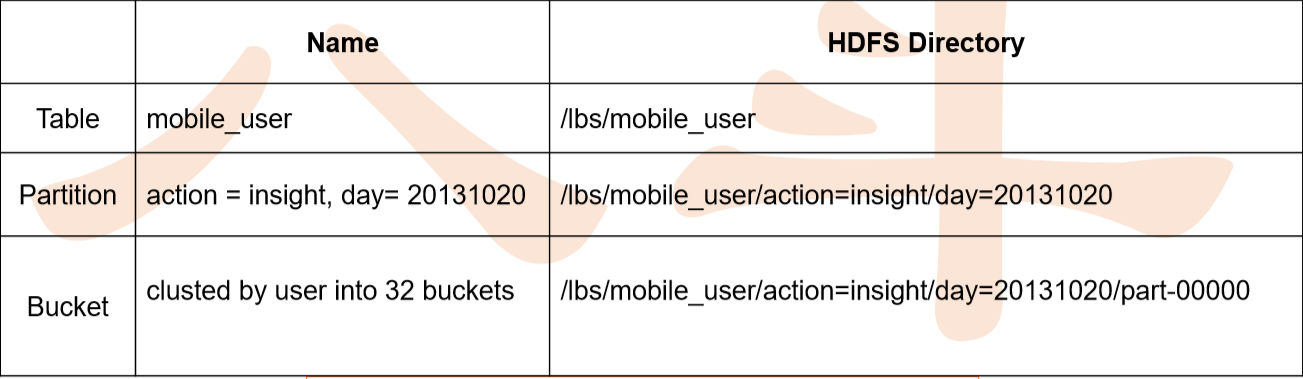
• hive的表本质就是Hadoop的目录/文件
– hive默认表存放路径一般都是在你工作目录的hive目录里面,按表名做文件夹分开,如果你 有分区表的话,分区值是子文件夹,可以直接在其它的M/R job里直接应用这部分数据
Hive 内部表和外部表
• Hive的create创建表的时候,选择的创建方式:
– create table
– create external table
• 特点:
– 在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由它 自己来管理的!而表则不一样;
– 在删除表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除 外部表的元数据,数据是不会删除的!
Hive 中的 Partition,分区表
• 在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的 数据都存储在对应的目录中
– 例如:pvs 表中包含 ds 和 city 两个 Partition,则
– 对应于 ds = 20090801, ctry = US 的 HDFS 子目录为:/wh/pvs/ds=20090801/ctry=US;
– 对应于 ds = 20090801, ctry = CA 的 HDFS 子目录为;/wh/pvs/ds=20090801/ctry=CA
分区表优点:
所有数据都放到一个表的文件夹中查询数据需要遍历(扫一遍所有数据),如果这个文件夹中的数据包含了一年的用户行为数据。这样扫一遍数据就扫一年所有的数据。如果做了分区,想要获取分析昨天的数据,只需要取对应昨天日期的文件夹中的数据即可。只需用找到对应日期的文件夹就行。具体限定约束条件在where后面: select userid from table where dt='20190420'
Hive 中 的Bucket,分桶表
• hive中table可以拆分成partition,table和partition可以通过‘CLUSTERED BY ’进一步分bucket,bucket中的数据可以通过‘SORT BY’排序。
• create table bucket_user (id int,name string)clustered by (id) into 4 buckets;
• 'set hive.enforce.bucketing = true' 可以自动控制上一轮reduce的数量从而适 配bucket的个数,当然,用户也可以自主设置mapred.reduce.tasks去适配 bucket个数
• Bucket主要作用:
– 数据sampling
– 提升某些查询操作效率,例如mapside join
• 查看sampling数据:
– select * from student tablesample(bucket 1 out of 2 on id);
– tablesample是抽样语句,语法:TABLESAMPLE(BUCKET x OUT OF y)
y决定抽样的bucket数目,y必须是table总bucket数的倍数或者因子,抽样的bucket数目为y/bucket_num
x决定抽样的数据,抽样的数据为对y取余为x-1这些数据
Hive 数据类型
• 数据类型
– 原生类型
• TINYINT
• SMALLINT
• INT
• BIGINT
• BOOLEAN
• FLOAT
• DOUBLE
• STRING
• BINARY(Hive 0.8.0以上才可用)
• TIMESTAMP(Hive 0.8.0以上才可用)
– 复合类型
• Arrays:ARRAY<data_type>
• Maps:MAP<primitive_type, data_type>
• Structs:STRUCT<col_name: data_type[COMMENT col_comment],……>
• Union:UNIONTYPE<data_type, data_type,……>
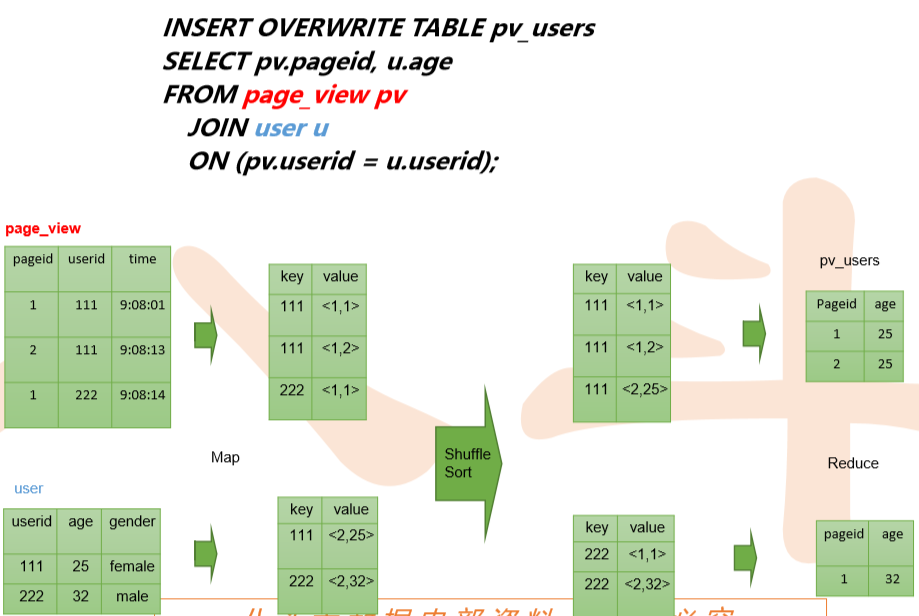
join on
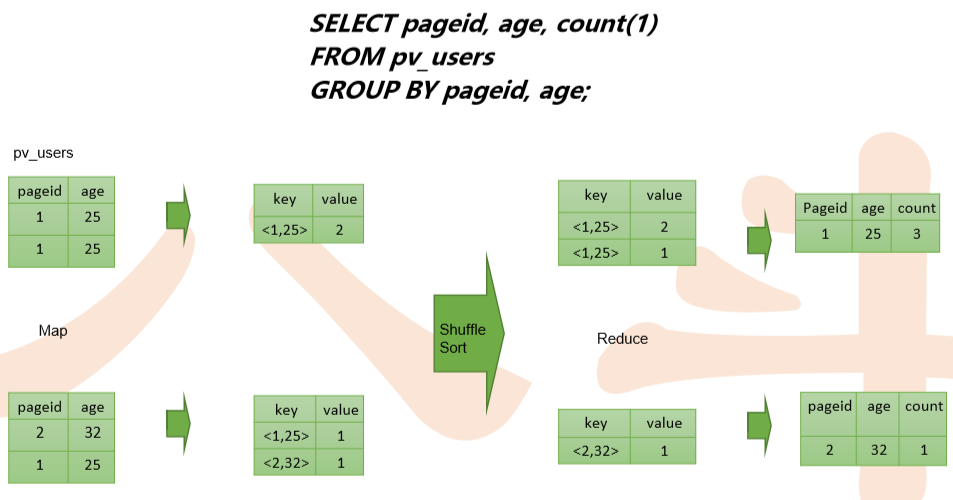
group by
Hive 优化
指定小表

指定大表


where 语句放在 join on 中

并行执行

数据倾斜解决方法
