持续关注MongoDB博客(https://www.mongodb.com/blog)的同学一定会留意到,技术大牛Daniel Coupal 和 Ken W. Alger ,从 今年 2月17 号开始,在博客上持续发表了 如何在MongoDB中设计数据库模式的方法。截止到今日(4月20号),12种模式设计的方法已全部与读者见面。本人认为,此系列文章,总结的非常全面,很多地方有首创性,涵盖的场景也很多,并且有理论总结,也有案例分析。文中分享的很多知识使人"如听仙乐耳暂明",开卷受益,常读常新。鉴于此,忍不住在自己的博客转载,希望能对学习、使用MongoDB的同学有所裨益。
1.Building with Patterns(一): The Polymorphic Pattern
One frequently asked question when it comes to MongoDB is “How do I structure my schema in MongoDB for my application?” The honest answer is, it depends. Does your application do more reads than writes? What data needs to be together when read from the database? What performance considerations are there? How large are the documents? How large will they get? How do you anticipate your data will grow and scale?
All of these questions, and more, factor into how one designs a database schema in MongoDB. It has been said that MongoDB is schemaless. In fact, schema design is very important in MongoDB. The hard fact is that most performance issues we’ve found trace back to poor schema design.
Over the course of this series, Building with Patterns, we’ll take a look at twelve common Schema Design Patterns that work well in MongoDB. We hope this series will establish a common methodology and vocabulary you can use when designing schemas. Leveraging these patterns allows for the use of “building blocks” in schema planning, resulting in more methodology being used than art.
MongoDB uses a document data model. This model is inherently flexible, allowing for data models to support your application needs. The flexibility also can lead to schemas being more complex than they should. When thinking of schema design, we should be thinking of performance, scalability, and simplicity.
Let’s start our exploration into schema design with a look at what can be thought as the base for all patterns, the Polymorphic Pattern. This pattern is utilized when we have documents that have more similarities than differences. It’s also a good fit for when we want to keep documents in a single collection.
The Polymorphic Pattern
When all documents in a collection are of similar, but not identical, structure, we call this the Polymorphic Pattern. As mentioned, the Polymorphic Pattern is useful when we want to access (query) information from a single collection. Grouping documents together based on the queries we want to run (instead of separating the object across tables or collections) helps improve performance.
Imagine that our application tracks professional sports athletes across all different sports.
We still want to be able to access all of the athletes in our application, but the attributes of each athlete are very different. This is where the Polymorphic Pattern shines. In the example below, we store data for athletes from two different sports in the same collection. The data stored about each athlete does not need to be the same even though the documents are in the same collection.
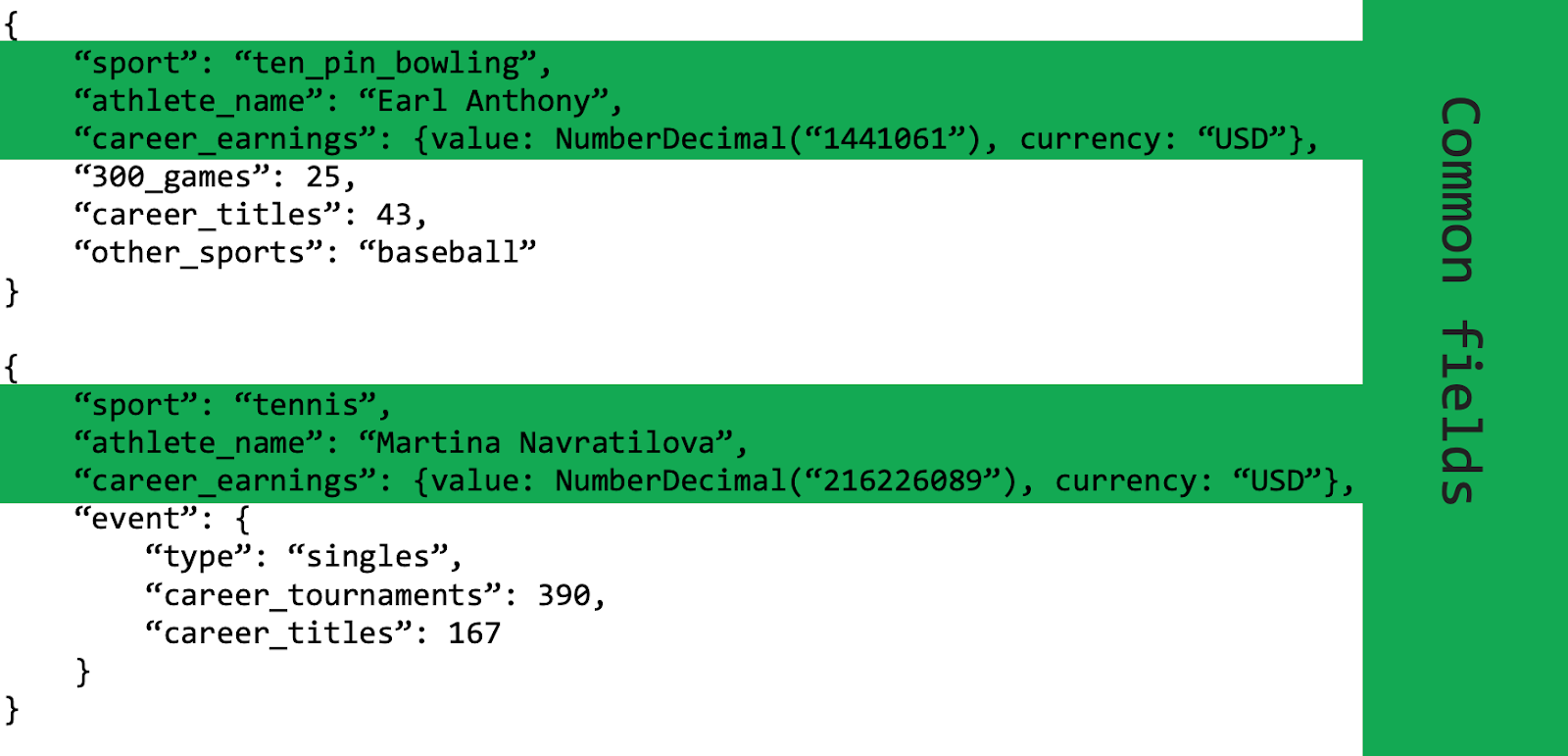
Professional athlete records have some similarities, but also some differences. With the Polymorphic Pattern, we are easily able to accommodate these differences. If we were not using the Polymorphic Pattern, we might have a collection for Bowling Athletes and a collection for Tennis Athletes. When we wanted to query on all athletes, we would need to do a time-consuming and potentially complex join. Instead, since we are using the Polymorphic Pattern, all of our data is stored in one Athletes collection and querying for all athletes can be accomplished with a simple query.
This design pattern can flow into embedded sub-documents as well. In the above example, Martina Navratilova didn’t just compete as a single player, so we might want to structure her record as follows:
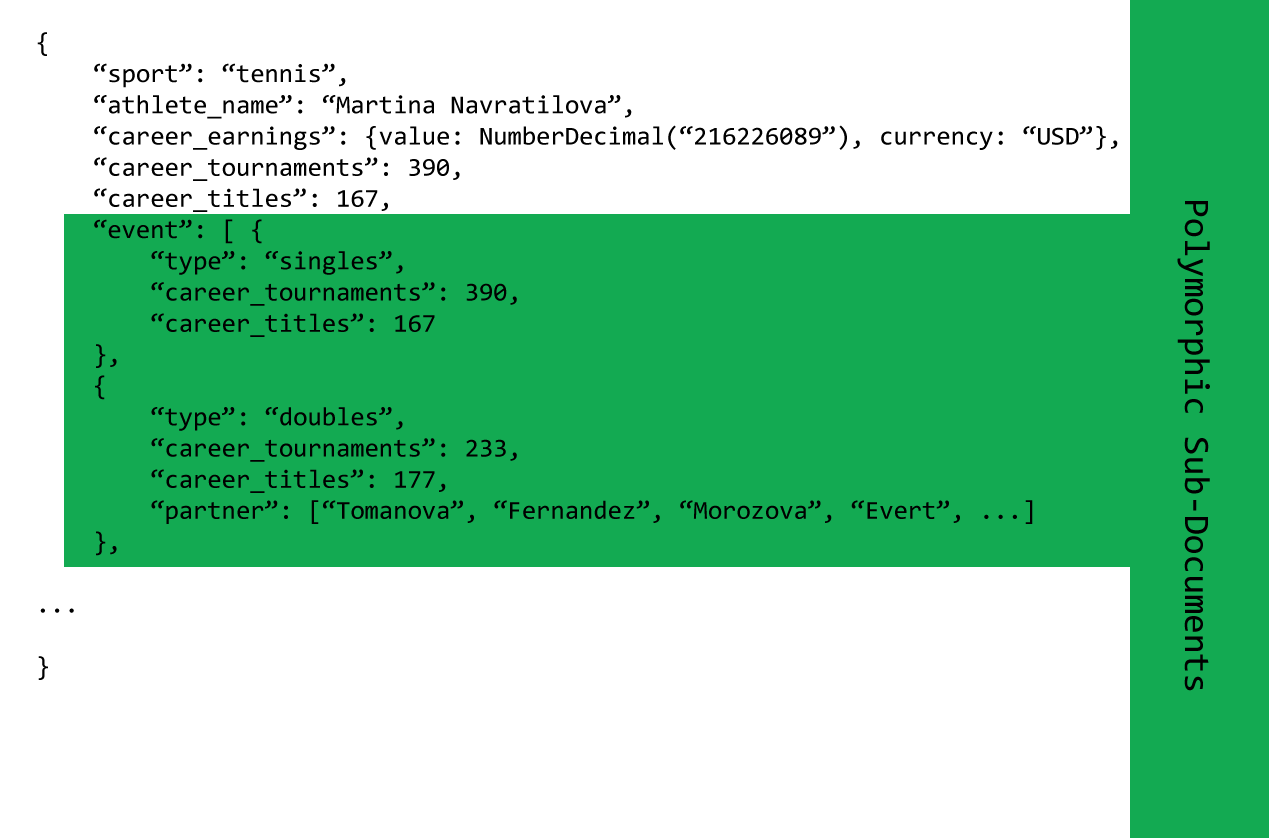
From an application development standpoint, when using the Polymorphic Pattern we’re going to look at specific fields in the document or sub-document to be able to track differences. We’d know, for example, that a tennis player athlete might be involved with different events, while a different sports player may not be. This will, typically, require different code paths in the application code based on the information in a given document. Or, perhaps, different classes or subclasses are written to handle the differences between tennis, bowling, soccer, and rugby players.
Sample Use Case
One example use case of the Polymorphic Pattern is Single View applications. Imagine working for a company that, over the course of time, acquires other companies with their technology and data patterns. For example, each company has many databases, each modeling "insurances with their customers" in a different way. Then you buy those companies and want to integrate all of those systems into one. Merging these different systems into a unified SQL schema is costly and time-consuming.
MetLife was able to leverage MongoDB and the Polymorphic Pattern to build their single view application in a few months. Their Single View application aggregates data from multiple sources into a central repository allowing customer service, insurance agents, billing, and other departments to get a 360° picture of a customer. This has allowed them to provide better customer service at a reduced cost to the company. Further, using MongoDB’s flexible data model and the Polymorphic Pattern, the development team was able to innovate quickly to bring their product online.
A Single View application is one use case of the Polymorphic Pattern. It also works well for things like product catalogs where a bicycle has different attributes than a fishing rod. Our athlete example could easily be expanded into a more full-fledged content management system and utilize the Polymorphic Pattern there.
Conclusion
The Polymorphic Pattern is used when documents have more similarities than they have differences. Typical use cases for this type of schema design would be:
- Single View applications
- Content management
- Mobile applications
- A product catalog
The Polymorphic Pattern provides an easy-to-implement design that allows for querying across a single collection and is a starting point for many of the design patterns we’ll be exploring in upcoming posts. The next pattern we’ll discuss is the Attribute Pattern.
【以上内容转载于】:https://www.mongodb.com/blog/post/building-with-patterns-the-polymorphic-pattern
2. Building with Patterns(二): The Attribute Pattern
Welcome back to the Building with Patterns series. Last time we looked at the Polymorphic Pattern which covers situations when all documents in a collection are of similar, but not identical, structure. In this post, we’ll take a look at the Attribute Pattern. The Attribute Pattern is particularly well suited when:
- We have big documents with many similar fields but there is a subset of fields that share common characteristics and we want to sort or query on that subset of fields, or
- The fields we need to sort on are only found in a small subset of documents, or
- Both of the above conditions are met within the documents.
For performance reasons, to optimize our search we’d likely need many indexes to account for all of the subsets. Creating all of these indexes could reduce performance. The Attribute Pattern provides a good solution for these cases.
The Attribute Pattern
Let’s think about a collection of movies. The documents will likely have similar fields involved across all of the documents: title, director, producer, cast, etc. Let’s say we want to search on the release date. A challenge that we face when doing so, is which release date? Movies are often released on different dates in different countries.
{
title: "Star Wars",
director: "George Lucas",
...
release_US: ISODate("1977-05-20T01:00:00+01:00"),
release_France: ISODate("1977-10-19T01:00:00+01:00"),
release_Italy: ISODate("1977-10-20T01:00:00+01:00"),
release_UK: ISODate("1977-12-27T01:00:00+01:00"),
...
}
A search for a release date will require looking across many fields at once. In order to quickly do searches for release dates, we’d need several indexes on our movies collection:
{release_US: 1}
{release_France: 1}
{release_Italy: 1}
...By using the Attribute Pattern, we can move this subset of information into an array and reduce the indexing needs. We turn this information into an array of key-value pairs:
{
title: "Star Wars",
director: "George Lucas",
…
releases: [
{
location: "USA",
date: ISODate("1977-05-20T01:00:00+01:00")
},
{
location: "France",
date: ISODate("1977-10-19T01:00:00+01:00")
},
{
location: "Italy",
date: ISODate("1977-10-20T01:00:00+01:00")
},
{
location: "UK",
date: ISODate("1977-12-27T01:00:00+01:00")
},
…
],
…
}Indexing becomes much more manageable by creating one index on the elements in the array:
{ "releases.location": 1, "releases.date": 1}By using the Attribute Pattern we can add organization to our documents for common characteristics and account for rare/unpredictable fields. For example, a movie released in a new or small festival. Further, moving to a key/value convention allows for the use of non-deterministic naming and the easy addition of qualifiers. For example, if our data collection was on bottles of water, our attributes might look something like:
"specs": [
{ k: "volume", v: "500", u: "ml" },
{ k: "volume", v: "12", u: "ounces" }
]Here we break the information out into keys and values, “k” and “v”, and add in a third field, “u” which allows for the units of measure to be stored separately.
{"specks.k": 1, "specs.v": 1, "specs.u": 1}Sample Use Case
The Attribute Pattern is well suited for schemas that have sets of fields that have the same value type, such as lists of dates. It also works well when working with the characteristics of products. Some products, such as clothing, may have sizes that are expressed in small, medium, or large. Other products in the same collection may be expressed in volume. Yet others may be expressed in physical dimensions or weight.
A customer in the domain of asset management recently deployed their solution using the Attribute Pattern. The customer uses the pattern to store all characteristics of a given asset. These characteristics are seldom common across the assets or are simply difficult to predict at design time. Relational models typically use a complicated design process to express the same idea in the form of user-defined fields.
While many of the fields in the product catalog are similar, such as name, vendor, manufacturer, country of origin, etc., the specifications, or attributes, of the item may differ. If your application and data access patterns rely on searching through many of these different fields at once, the Attribute Pattern provides a good structure for the data.
Conclusion
The Attribute Pattern provides for easier indexing the documents, targeting many similar fields per document. By moving this subset of data into a key-value sub-document, we can use non-deterministic field names, add additional qualifiers to the information, and more clearly state the relationship of the original field and value. When we use the Attribute Pattern, we need fewer indexes, our queries become simpler to write, and our queries become faster.
The next pattern we’ll discuss is the Bucket Design Pattern.
【以上内容转载于】:https://www.mongodb.com/blog/post/building-with-patterns-the-attribute-pattern
3.Building with Patterns(三): The Bucket Pattern
In this edition of the Building with Patterns series, we're going to cover the Bucket Pattern. This pattern is particularly effective when working with Internet of Things (IoT), Real-Time Analytics, or Time-Series data in general. By bucketing data together we make it easier to organize specific groups of data, increasing the ability to discover historical trends or provide future forecasting and optimize our use of storage.
The Bucket Pattern
With data coming in as a stream over a period of time (time series data) we may be inclined to store each measurement in its own document. However, this inclination is a very relational approach to handling the data. If we have a sensor taking the temperature and saving it to the database every minute, our data stream might look something like:
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
}
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
}
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:02:00.000Z"),
temperature: 41
}
This can pose some issues as our application scales in terms of data and index size. For example, we could end up having to index sensor_id and timestamp for every single measurement to enable rapid access at the cost of RAM. By leveraging the document data model though, we can "bucket" this data, by time, into documents that hold the measurements from a particular time span. We can also programmatically add additional information to each of these "buckets".
By applying the Bucket Pattern to our data model, we get some benefits in terms of index size savings, potential query simplification, and the ability to use that pre-aggregated data in our documents. Taking the data stream from above and applying the Bucket Pattern to it, we would wind up with:
{
sensor_id: 12345,
start_date: ISODate("2019-01-31T10:00:00.000Z"),
end_date: ISODate("2019-01-31T10:59:59.000Z"),
measurements: [
{
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
},
{
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
},
…
{
timestamp: ISODate("2019-01-31T10:42:00.000Z"),
temperature: 42
}
],
transaction_count: 42,
sum_temperature: 2413
}
By using the Bucket Pattern, we have "bucketed" our data to, in this case, a one hour bucket. This particular data stream would still be growing as it currently only has 42 measurements; there's still more measurements for that hour to be added to the "bucket". When they are added to the measurements array, the transaction_count will be incremented and sum_temperature will also be updated.
With the pre-aggregated sum_temperature value, it then becomes possible to easily pull up a particular bucket and determine the average temperature (sum_temperature / transaction_count) for that bucket. When working with time-series data it is frequently more interesting and important to know what the average temperature was from 2:00 to 3:00 pm in Corning, California on 13 July 2018 than knowing what the temperature was at 2:03 pm. By bucketing and doing pre-aggregation we're more able to easily provide that information.
Additionally, as we gather more and more information we may determine that keeping all of the source data in an archive is more effective. How frequently do we need to access the temperature for Corning from 1948, for example? Being able to move those buckets of data to a data archive can be a large benefit.
Sample Use Case
One example of making time-series data valuable in the real world comes from an IoT implementation by Bosch. They are using MongoDB and time-series data in an automotive field data app. The app captures data from a variety of sensors throughout the vehicle allowing for improved diagnostics of the vehicle itself and component performance.
Other examples include major banks that have incorporated this pattern in financial applications to group transactions together.
Conclusion
When working with time-series data, using the Bucket Pattern in MongoDB is a great option. It reduces the overall number of documents in a collection, improves index performance, and by leveraging pre-aggregation, it can simplify data access.
The Bucket Design pattern works great for many cases. But what if there are outliers in our data? That's where the next pattern we'll discuss, the Outlier Design Pattern, comes into play.
【以上内容转载于】:https://www.mongodb.com/blog/post/building-with-patterns-the-bucket-pattern
4. Building With Patterns(四): The Outlier Pattern
So far in this Building with Patterns series, we've looked at the Polymorphic, Attribute, and Bucket patterns. While the document schema in these patterns has slight variations, from an application and query standpoint, the document structures are fairly consistent. What happens, however, when this isn't the case? What happens when there is data that falls outside the "normal" pattern? What if there's an outlier?
Imagine you are starting an e-commerce site that sells books. One of the queries you might be interested in running is "who has purchased a particular book". This could be useful for a recommendation system to show your customers similar books of interest. You decide to store the user_id of a customer in an array for each book. Simple enough, right?
Well, this may indeed work for 99.99% of the cases, but what happens when J.K. Rowling releases a new Harry Potter book and sales spike in the millions? The 16MB BSON document size limit could easily be reached. Redesigning our entire application for this outlier situation could result in reduced performance for the typical book, but we do need to take it into consideration.
The Outlier Pattern
With the Outlier Pattern, we are working to prevent a few queries or documents driving our solution towards one that would not be optimal for the majority of our use cases. Not every book sold will sell millions of copies.
A typical book document storing user_id information might look something like:
{
"_id": ObjectID("507f1f77bcf86cd799439011")
"title": "A Genealogical Record of a Line of Alger",
"author": "Ken W. Alger",
…,
"customers_purchased": ["user00", "user01", "user02"]
}This would work well for a large majority of books that aren't likely to reach the "best seller" lists. Accounting for outliers though results in the customers_purchased array expanding beyond a 1000 item limit we have set, we'll add a new field to "flag" the book as an outlier.
{
"_id": ObjectID("507f191e810c19729de860ea"),
"title": "Harry Potter, the Next Chapter",
"author": "J.K. Rowling",
…,
"customers_purchased": ["user00", "user01", "user02", …, "user999"],
"has_extras": "true"
}We'd then move the overflow information into a separate document linked with the book's id. Inside the application, we would be able to determine if a document has a has_extrasfield with a value of true. If that is the case, the application would retrieve the extra information. This could be handled so that it is rather transparent for most of the application code.
Many design decisions will be based on the application workload, so this solution is intended to show an example of the Outlier Pattern. The important concept to grasp here is that the outliers have a substantial enough difference in their data that, if they were considered "normal", changing the application design for them would degrade performance for the more typical queries and documents.
Sample Use Case
The Outlier Pattern is an advanced pattern, but one that can result in large performance improvements. It is frequently used in situations when popularity is a factor, such as in social network relationships, book sales, movie reviews, etc. The Internet has transformed our world into a much smaller place and when something becomes popular, it transforms the way we need to model the data around the item.
One example is a customer that has a video conferencing product. The list of authorized attendees in most video conferences can be kept in the same document as the conference. However, there are a few events, like a company's all hands, that have thousands of expected attendees. For those outlier conferences, the customer implemented "overflow" documents to record those long lists of attendees.
Conclusion
The problem that the Outlier Pattern addresses is preventing a few documents or queries to determine an application's solution. Especially when that solution would not be optimal for the majority of use cases. We can leverage MongoDB's flexible data model to add a field to the document "flagging" it as an outlier. Then, inside the application, we handle the outliers slightly differently. By tailoring your schema for the typical document or query, application performance will be optimized for those normal use cases and the outliers will still be addressed.
One thing to consider with this pattern is that it often is tailored for specific queries and situations. Therefore, ad hoc queries may result in less than optimal performance. Additionally, as much of the work is done within the application code itself, additional code maintenance may be required over time.
In our next Building with Patterns post, we'll take a look at the Computed Pattern and how to optimize schema for applications that can result in unnecessary waste of resources.
【以上内容转载于】:https://www.mongodb.com/blog/post/building-with-patterns-the-outlier-pattern
5. Building with Patterns(五): The Computed Pattern
We've looked at various ways of optimally storing data in the Building with Patterns series. Now, we're going to look at a different aspect of schema design. Just storing data and having it available isn't, typically, all that useful. The usefulness of data becomes much more apparent when we can compute values from it. What's the total sales revenue of the latest Amazon Alexa? How many viewers watched the latest blockbuster movie? These types of questions can be answered from data stored in a database but must be computed.
Running these computations every time they're requested though becomes a highly resource-intensive process, especially on huge datasets. CPU cycles, disk access, memory all can be involved.
Think of a movie information web application. Every time we visit the application to look up a movie, the page provides information about the number of cinemas the movie has played in, the total number of people who've watched the movie, and the overall revenue. If the application has to constantly compute those values for each page visit, it could use a lot of processing resources on popular movies
Most of the time, however, we don't need to know those exact numbers. We could do the calculations in the background and update the main movie information document once in a while. These _computations _then allow us to show a valid representation of the data without having to put extra effort on the CPU.
The Computed Pattern
The Computed Pattern is utilized when we have data that needs to be computed repeatedly in our application. The Computed Pattern is also utilized when the data access pattern is read intensive; for example, if you have 1,000,000 reads per hour but only 1,000 writes per hour, doing the computation at the time of a write would divide the number of calculations by a factor 1000.
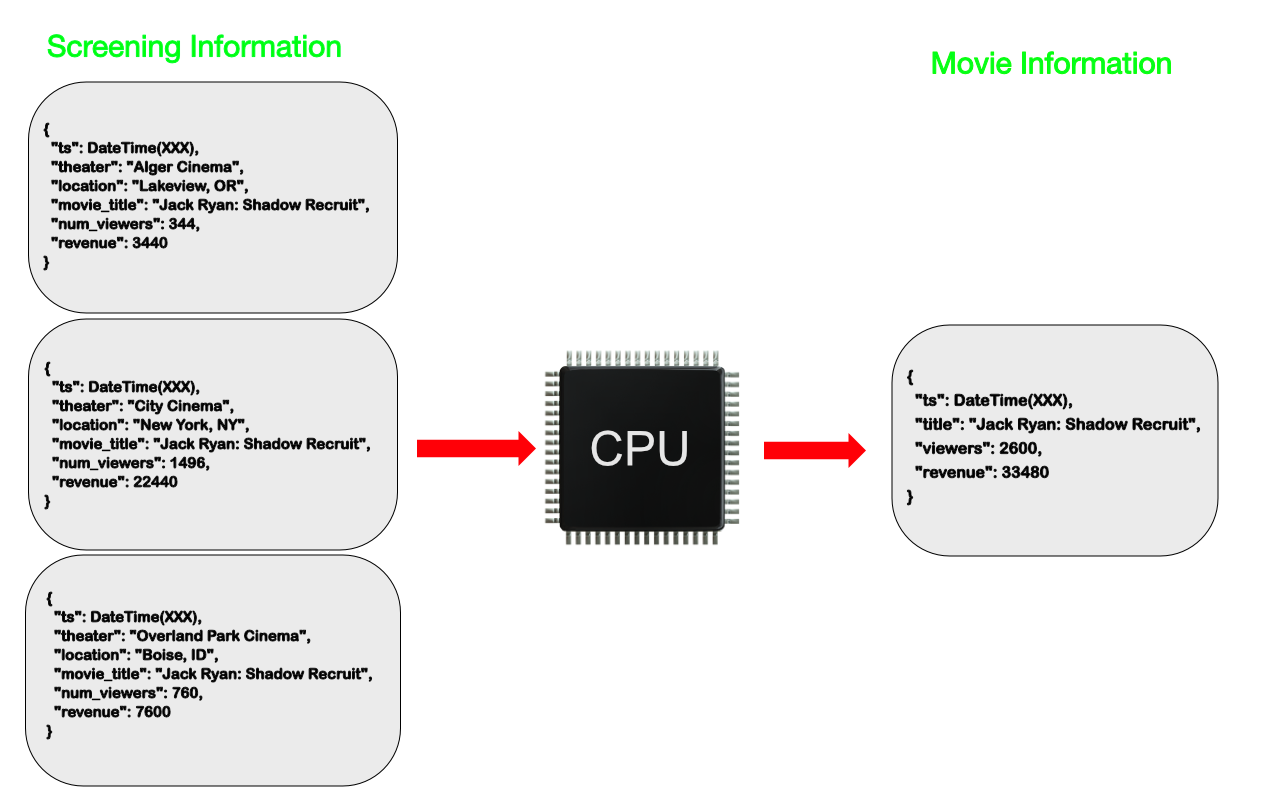
In our movie database example, we can do the computations based on all of the screening information we have on a particular movie, compute the result(s), and store them with the information about the movie itself. In a low write environment, the computation could be done in conjunction with any update of the source data. Where there are more regular writes, the computations could be done at defined intervals - every hour for example. Since we aren't interfering with the source data in the screening information, we can continue to rerun existing calculations or run new calculations at any point in time and know we will get correct results.
Other strategies for performing the computation could involve, for example, adding a timestamp to the document to indicate when it was last updated. The application can then determine when the computation needs to occur. Another option might be to have a queue of computations that need to be done. Selecting the update strategy is best left to the application developer.
Sample Use Case
The Computed Pattern can be utilized wherever calculations need to be run against data. Datasets that need sums, such as revenue or viewers, are a good example, but time series data, product catalogs, single view applications, and event sourcing are prime candidates for this pattern too.
This is a pattern that many customers have implemented. For example, a customer does massive aggregation queries on vehicle data and store the results for the server to show the info for the next few hours.
A publishing company compiles all kind of data to create ordered lists like the "100 Best ...". Those lists only need to be regenerated once in a while, while the underlying data may be updated at other times.
Conclusion
This powerful design pattern allows for a reduction in CPU workload and increased application performance. It can be utilized to apply a computation or operation on data in a collection and store the result in a document. This allows for the avoidance of the same computation being done repeatedly. Whenever your system is performing the same calculations repeatedly and you have a high read to write ratio, consider the Computed Pattern.
We're over a third of the way through this Building with Patterns series. Next time we'll look at the features and benefits of the Subset Pattern and how it can help with memory shortage issues.
【以上内容转载于】:https://www.mongodb.com/blog/post/building-with-patterns-the-computed-pattern
6. Building with Patterns(六): The Subset Pattern
Some years ago, the first PCs had a whopping 256KB of RAM and dual 5.25" floppy drives. No hard drives as they were incredibly expensive at the time. These limitations resulted in having to physically swap floppy disks due to a lack of memory when working with large (for the time) amounts of data. If only there was a way back then to only bring into memory the data I frequently used, as in a subset of the overall data.
Modern applications aren't immune from exhausting resources. MongoDB keeps frequently accessed data, referred to as the working set, in RAM. When the working set of data and indexes grows beyond the physical RAM allotted, performance is reduced as disk accesses starts to occur and data rolls out of RAM.
How can we solve this? First, we could add more RAM to the server. That only scales so much though. We can look at sharding our collection, but that comes with additional costs and complexities that our application may not be ready for. Another option is to reduce the size of our working set. This is where we can leverage the Subset Pattern.
The Subset Pattern
This pattern addresses the issues associated with a working set that exceeds RAM, resulting in information being removed from memory. This is frequently caused by large documents which have a lot of data that isn't actually used by the application. What do I mean by that exactly?
Imagine an e-commerce site that has a list of reviews for a product. When accessing that product's data it's quite possible that we'd only need the most recent ten or so reviews. Pulling in the entirety of the product data with all of the reviews could easily cause the working set to expand.

Instead of storing all the reviews with the product, we can split the collection into two collections. One collection would have the most frequently used data, e.g. current reviews and the other collection would have less frequently used data, e.g. old reviews, product history, etc. We can duplicate part of a 1-N or N-N relationship that is used by the most used side of the relationship.

In the Product collection, we'll only keep the ten most recent reviews. This allows the working set to be reduced by only bringing in a portion, or subset, of the overall data. The additional information, reviews in this example, are stored in a separate Reviews collection that can be accessed if the user wants to see additional reviews. When considering where to split your data, the most used part of the document should go into the "main" collection and the less frequently used data into another. For our reviews, that split might be the number of reviews visible on the product page.
Sample Use Case
The Subset Pattern is very useful when we have a large portion of data inside a document that is rarely needed. Product reviews, article comments, actors in a movie are all examples of use cases for this pattern. Whenever the document size is putting pressure on the size of the working set and causing the working set to exceed the computer's RAM capacities, the Subset Pattern is an option to consider.
Conclusion
By using smaller documents with more frequently accessed data, we reduce the overall size of the working set. This allows for shorter disk access times for the most frequently used information that an application needs. One tradeoff that we must make when using the Subset Pattern is that we must manage the subset and also if we need to pull in older reviews or all of the information, it will require additional trips to the database to do so.
The next post in this series will look at the features and benefits of the Extended Reference Pattern.
【以上内容转载于】:https://www.mongodb.com/blog/post/building-with-patterns-the-subset-pattern
7.Building with Patterns(七): The Extended Reference Pattern
Throughout this Building With Patterns series, I hope you've discovered that a driving force in what your schema should look like, is what the data access patterns for that data are. If we have a number of similar fields, the Attribute Pattern may be a great choice. Does accommodating access to a small portion of our data vastly alter our application? Perhaps the Outlier Pattern is something to consider. Some patterns, such as the Subset Pattern, reference additional collections and rely on JOIN operations to bring every piece of data back together. What about instances when there are lots of JOIN operations needed to bring together frequently accessed data? This is where we can use the Extended Reference pattern.
The Extended Reference Pattern
There are times when having separate collections for data make sense. If an entity can be thought of as a separate "thing", it often makes sense to have a separate collection. For example, in an e-commerce application, the idea of an order exists, as does a customer, and inventory. They are separate logical entities.

From a performance standpoint, however, this becomes problematic as we need to put the pieces of information together for a specific order. One customer can have N orders, creating a 1-N relationship. From an order standpoint, if we flip that around, they have an N-1 relationship with a customer. Embedding all of the information about a customer for each order just to reduce the JOIN operation results in a lot of duplicated information. Additionally, not all of the customer information may be needed for an order.
The Extended Reference pattern provides a great way to handle these situations. Instead of duplicating all of the information on the customer, we only copy the fields we access frequently. Instead of embedding all of the information or including a reference to JOIN the information, we only embed those fields of the highest priority and most frequently accessed, such as name and address.

Something to think about when using this pattern is that data is duplicated. Therefore it works best if the data that is stored in the main document are fields that don't frequently change. Something like a user_id and a person's name are good options. Those rarely change.
Also, bring in and duplicate only that data that's needed. Think of an order invoice. If we bring in the customer's name on an invoice, do we need their secondary phone number and non-shipping address at that point in time? Probably not, therefore we can leave that data out of the invoice collection and reference a customer collection.
When information is updated, we need to think about how to handle that as well. What extended references changed? When should those be updated? If the information is a billing address, do we need to maintain that address for historical purposes, or is it okay to update? Sometimes duplication of data is better because you get to keep the historical values, which may make more sense. The address where our customer lived at the time we ship the products make more sense in the order document, then fetching the current address through the customer collection.
Sample Use Case
An order management application is a classic use case for this pattern. When thinking about N-1 relationships, orders to customers, we want to reduce the joining of information to increase performance. By including a simple reference to the data that would most frequently be JOINed, we save a step in processing.
If we continue with the example of an order management system, on an invoice Acme Co. may be listed as the supplier for an anvil. Having the contact information for Acme Co. probably isn't super important from an invoice standpoint. That information is better served to reside in a separate supplier collection, for example. In the invoice collection, we'd keep the needed information about the supplier as an extended reference to the supplier information.
Conclusion
The Extended Reference pattern is a wonderful solution when your application is experiencing many repetitive JOIN operations. By identifying fields on the lookup side and bringing those frequently accessed fields into the main document, performance is improved. This is achieved through faster reads and a reduction in the overall number of JOINs. Be aware, however, that data duplication is a side effect of this schema design pattern.
The next post in this series will look at the Approximation Pattern.
【以上内容转载于】:https://www.mongodb.com/blog/post/building-with-patterns-the-extended-reference-pattern
8. Building with Patterns(八): The Approximation Pattern
Imagine a fairly decent sized city of approximately 39,000 people. The exact number is pretty fluid as people move in and out of the city, babies are born, and people die. We could spend our days trying to get an exact number of residents each day. But most of the time that 39,000 number is "good enough." Similarly, in many applications we develop, knowing a "good enough" number is sufficient. If a "good enough" number is good enough then this is a great opportunity to put the Approximation Pattern to work in your schema design.
The Approximation Pattern
We can use the Approximation Pattern when we need to display calculations that are challenging or resource expensive (time, memory, CPU cycles) to calculate and for when precision isn't of the highest priority. Think again about the population question. What would the cost be to get an exact calculation of that number? Would, or could, it have changed since I started the calculation? What's the impact on the city's planning strategy if it's reported as 39,000 when in reality it's 39,012?
From an application standpoint, we could build in an approximation factor which would allow for fewer writes to the database and still provide statistically valid numbers. For example, let's say that our city planning strategy is based on needing one fire engine per 10,000 people. 100 people might seem to be a good "update" period for planning. "We're getting close to the next threshold, better start budgeting."
In an application then, instead of updating the population in the database with every change, we could build in a counter and only update by 100, 1% of the time. Our writes are significantly reduced here, in this example by 99%. Another option might be to have a function that returns a random number. If, for example, that function returns a number from 0 to 100, it will return 0 around 1% of the time. When that condition is met, we increase the counter by 100.
Why should we be concerned with this? Well, when working with large amounts of data or large numbers of users, the impact on performance of write operations can get to be large too. The more you scale up, the greater that impact is too and at scale, that's often your most important consideration. By reducing writes and reducing resources for data that doesn't need to be "perfect," it can lead to huge improvements in performance.
Sample Use Case
Population patterns are an example of the Approximation Pattern. An additional use case where we could use this pattern is for website views. Generally speaking, it isn't vital to know if 700,000 people visited the site, or 699,983. Therefore we could build into our application a counter and update it in the database when our thresholds are met.
This could have a tremendous reduction in the performance of the site. Spending time and resources on business critical writes of data makes sense. Spending them all on a page counter doesn't seem to be a great use of resources.

In the image above we see how we could use the Approximation Pattern and reduce not only writes for the counter operations, but we might also see a reduction in architecture complexity and cost by reducing those writes. This can lead to further savings beyond just the time for writing data. Similar to the Computed Pattern we explored earlier, it saves on overall CPU usage by not having to run calculations as frequently.
Conclusion
The Approximation Pattern is an excellent solution for applications that work with data that is difficult and/or expensive to compute and the accuracy of those numbers isn't mission critical. We can make fewer writes to the database increasing performance and still maintain statistically valid numbers. The cost of using this pattern, however, is that exact numbers aren't being represented and that the implementation must be done in the application itself.
The next post in this series will look at the Tree Pattern.
【以上内容转载于】:https://www.mongodb.com/blog/post/building-with-patterns-the-approximation-pattern
9.Building with Patterns(九): The Tree Pattern
Many of the schema design patterns we've covered so far have stressed that saving time on JOIN operations is a benefit. Data that's accessed together should be stored together and some data duplication is okay. A schema design pattern like Extended Reference is a good example. However, what if the data to be joined is hierarchical? For example, you would like to identify the reporting chain from an employee to the CEO? MongoDB provides the $graphLookup operator to navigate the data as graphs, and that could be one solution. However, if you need to do a lot of queries of this hierarchical data structure, you may want to apply the same rule of storing together data that is accessed together. This is where we can use the Tree Pattern.
The Tree Pattern
There are many ways to represent a tree in a legacy tabular database. The most common ones are for a node in the graph to list its parent and for a node to list its children. Both of these representations may require multiple access to build the chain of nodes.


Alternatively, we could store the full path from a node to the top of the hierarchy. In this case, we'd basically be storing the "parents" for each node. In a tabular database, it would likely be done by encoding a list of the parents. The approach in MongoDB is to simply represent this as an array.

As can be seen here, in this representation there is some data duplication. If the information is relatively static, like in genealogy, your parents and ancestors won't change making this array easy to manage. However, in our corporate structure example, when things change and there is restructuring, you will need to update the hierarchy as needed. This is still a small cost compared to the benefits you can gain from not calculating the trees all the time.
Sample Use Case
Product catalogs are another very good example of using the Tree pattern. Often products belong to categories, which are part of other categories. For example, a Solid State Drive may be under Hard Drives, which is under Storage, which is under Computer Parts. Occasionally the organization of the categories may change, but not too frequently.

Note in the document above the ancestor_categories field which keeps track of the entire hierarchy. We also have the field parent_category. Duplicating the immediate parent in these two fields is a best practice we've developed after working with many customers using the Tree Pattern. Including the "parent" field is often handy, especially if you need to maintain the ability to use $graphLookup on your documents.
Keeping the ancestors in an array provides the ability to create a multi-key index on those values. It allows for all descendants of a given category to be easily found. As for the immediate children, they are accessible by looking at the documents that have our given category as its immediate "parent". We just told you that this field would be handy.
Conclusion
As for many patterns, there is often a tradeoff between simplicity and performance when using them. In the case of the tree pattern, you get better performance by avoiding multiple joins, however, you will need to manage the updates to your graph.
The next post in this series will look at the Pre-Allocation Pattern.
【以上内容转载于】:https://www.mongodb.com/blog/post/building-with-patterns-the-tree-pattern
10.Building with Patterns(十): The Preallocation Pattern
One of the great things about MongoDB is the document data model. It provides for a lot of flexibility not only in schema design but in the development cycle as well. Not knowing what fields will be required down the road is easily handled with MongoDB documents. However, there are times when the structure is known and being able to fill or grow the structure makes the design much simpler. This is where we can use the Preallocation Pattern.
Memory allocation is often done in blocks to avoid performance issues. In the earlier days of MongoDB (prior to MongoDB version 3.2), when it used the MMAPv1 storage engine, a common optimization was to allocate in advance the memory needed for the future size of a constantly growing document. Growing documents in MMAPv1 needed to be relocated at a fairly expensive cost by the server. With its lock-free and rewrite on update algorithms, WiredTiger does not require this same treatment.
With the deprecation of MMAPv1 in MongoDB 4.0, the Preallocation Pattern appeared to lose some of its luster and necessity. However, there are still use cases for the Preallocation Pattern with WiredTiger. As with the other patterns we've discussed in the Building with Patterns series, there are a few application considerations to think about.
The Preallocation Pattern
This pattern simply dictates to create an initial empty structure to be filled later. It may sound trivial, however, you will need to balance the desired outcome in simplification versus the additional resources that the solution may consume. Bigger documents will make for a larger working set resulting in more RAM to contain this working set.
If the code of the application is much easier to write and maintain if it uses a structure that is not completed filled, it may easily outweigh the cost of the RAM. Let's say there is a need to represent a theater room as a 2-dimensional array where each seat has a "row" and "number", for example, the seat "C7". Some rows may have fewer seats, however finding the seat "B3" is faster and cleaner in a 2-dimensional array, than having a complicated formula to find a seat in a one-dimensional array that has only cells for the existing seats. Being able to identify accessible seating is also easier as a separate array can be created for those seats.

Two dimensional representation of venue, valid seats available in green. Accessible seating notated with a blue outline.

One dimensional representation of venue, accessible seats shown in blue.
Sample Use Case
As seen earlier, representing a 2 dimension structure, like a venue, is a good use case. Another example could be a reservation system where a resource is blocked or reserved, on a per day basis. Using one cell per available day would likely make computations and checking faster than keeping a list of ranges.

The month of April 2019 with an array of U.S. work days.

The month of April 2019 with an array of U.S. work days as a list of ranges.
Conclusion
This pattern may be one of the most used when using the MMAPv1 storage engine with MongoDB. However due to the depreciation of this storage engine, it has lost its generic use case, but it is still useful in some situations. And like other patterns, you have a trade-off between "simplicity" and "performance".
The next post in this series will look at the Document Versioning Pattern.
【以上内容转载于】:https://www.mongodb.com/blog/post/building-with-patterns-the-preallocation-pattern
11.Building with Patterns(十一): The Document Versioning Pattern
Databases, such as MongoDB, are very good at querying lots of data and updating that data frequently. In most cases, however, we are only performing queries on the latest state of the data. What about situations in which we need to query previous states of the data? What if we need to have some functionality of version control of our documents? This is where we can use the Document Versioning Pattern.
This pattern is all about keeping the version history of documents available and usable. We could construct a system that uses a dedicated version control system in conjunction with MongoDB. One system for the few documents that change and MongoDB for the others. This would be potentially cumbersome. By using the Document Versioning Pattern, however, we are able to avoid having to use multiple systems for managing the current documents and their history by keeping them in one database.
The Document Versioning Pattern
This pattern addresses the problem of wanting to keep around older revisions of some documents in MongoDB instead of bringing in a second management system. To accomplish this, we add a field to each document allowing us to keep track of the document version. The database will then have two collections: one that has the latest (and most queried data) and another that has all of the revisions of the data.
The Document Versioning Pattern makes a few assumptions about the data in the database and the data access patterns that the application makes.
- Each document doesn’t have too many revisions.
- There aren’t too many documents to version.
- Most of the queries performed are done on the most current version of the document.
If you find that these assumptions don’t fit your use case, this pattern may not be a great fit. You may have to alter how you implement your version of the Document Versioning Pattern or your use case may simply require a different solution.
Sample Use Case
The Document Versioning Pattern is very useful in highly regulated industries that require a specific point in time version of a set of data. Financial and healthcare industries are good examples. Insurance and legal industries are some others. There are many use cases that track histories of some portion of the data.
Think of how an insurance company might make use of this pattern. Each customer has a “standard” policy and a second portion that is specific to that customer, a policy rider if you will. This second portion would contain a list of policy add-ons and a list of specific items that are being insured. As the customer changes what specific items are insured, this information needs to be updated while the historical information needs to be available as well. This is fairly common in homeowner or renters insurance policies. For example, if someone has specific items they want to be insured beyond the typical coverage provided, they are listed separately, as a rider. Another use case for the insurance company may be to keep all the versions of the "standard policy" they have mailed to their customers over time.
If we take a look at the requirements for the Document Versioning Pattern, this seems like a great use case. The insurance company likely has a few million customers, the revisions to the “add-on” list likely don’t occur too frequently, and the majority of searches on a policy will be about the most current version.
Inside our database, each customer might have a current_policy document — containing customer specific information — in a current_policies collection and policy_revisiondocuments in a policy_revisions collection. Additionally, there would be a standard_policy collection that would be the same for most customers. When a customer purchases a new item and wants it added to their policy, a new policy_revision document is created using the current_policy document. A version field in the document is then incremented to identify it as the latest revision and the customer's changes added.


The newest revision will be stored in the current_policies collection and the old version will be written to the policy_revisions collection. By keeping the latest versions in the current_policy collection queries can remain simple. The policy_revisions collection might only keep a few versions back as well, depending on data needs and requirements.

In this example then, Middle-earth Insurance would have a standard_policy for its customers. All residents of The Shire would share this particular policy document. Bilbo has specific things he wants insuring on top of his normal coverage. His Elven Sword and, eventually, the One Ring are added to his policy. These would reside in the current_policies collection and as changes are made the policy_revisions collection would keep a historical record of changes.
The Document Versioning Pattern is relatively easy to accomplish. It can be implemented on existing systems without too many changes to the application or to existing documents. Further, queries accessing the latest version of the document remain performant.
One drawback to this pattern is the need to access a different collection for historical information. Another is the fact that writes will be higher overall to the database. This is why one of the requirements to use this pattern is that it occurs on data that isn’t changed too frequently.
Conclusion
When you need to keep track of changes to documents, the Document Versioning Pattern is a great option. It is relatively easy to implement and can be applied to an existing set of documents. Another benefit is that queries to the latest version of data still perform well. It does not, however, replace a dedicated version control system.
The next post in this series will look at the final design pattern, Schema Versioning.
【以上内容转载于】:https://www.mongodb.com/blog/post/building-with-patterns-the-document-versioning-pattern
12.Building with Patterns(十二): The Schema Versioning Pattern
It has been said that the only thing constant in life is change. This holds true to database schemas as well. Information we once thought wouldn’t be needed, we now want to capture. Or new services become available and need to be included in a database record. Regardless of the reason behind the change, after a while, we inevitably need to make changes to the underlying schema design in our application. While this often poses challenges, and perhaps at least a few headaches in a legacy tabular database system, in MongoDB we can use the Schema Versioning pattern to make the changes easier.
Updating a database schema in a tabular database can as mentioned, be challenging. Typically the application needs to be stopped, the database migrated to support the new schema and then restarted. This downtime can lead to poor customer experience. Additionally, what happens if the migration wasn’t a complete success? Reverting back to the prior state is often an even larger challenge.
The Schema Versioning pattern takes advantage of MongoDB’s support for differently shaped documents to exist in the same database collection. This polymorphic aspect of MongoDB is very powerful. It allows documents that have different fields or even different field types for the same field, to peaceful exist side by side.
The Schema Versioning Pattern
The implementation of this pattern is relatively easy. Our applications start with an original schema which eventually needs to be altered. When that occurs we can create and save the new schema to the database with a schema_version field. This field will allow our application to know how to handle this particular document. Alternatively, we can have our application deduce the version based on the presence or absence of some given fields, but the former method is preferred. We can assume that documents that don’t have this field, are version 1. Each new schema version would then increment the schema_version field value and could be handled accordingly in the application.
As new information is saved, we use the most current schema version. We could make a determination, depending on the application and use case, as to the need of updating all documents to the new design, updating when a record is accessed, or not at all. Inside the application, we would create handling functions for each schema version.
Sample Use Case
As stated, just about every database needs to be changed at some point during its lifecycle, so this pattern is useful in many situations. Let’s take a look at a customer profile use case. We start keeping customer information before there is a wide range of contact methods. They can only be reached at home or at work:
{
"_id": "<ObjectId>",
"name": "Anakin Skywalker",
"home": "503-555-0000",
"work": "503-555-0010"
}As the years go by and more and more customer records are being saved, we notice that mobile numbers are needing to be saved as well. Adding that field in is straight forward.
{
"_id": "<ObjectId>",
"name": "Darth Vader",
"home": "503-555-0100",
"work": "503-555-0110",
"mobile": "503-555-0120"
}More time goes by and now we’re discovering that fewer and fewer people have a home phone, and other contact methods are becoming more important to record. Items like Twitter, Skype, and Google Hangouts are becoming more popular and maybe weren’t even available when we first started keeping contact information. We also want to attempt to future proof our application as much as possible and after reading the Building with Patterns series we know about the Attribute Pattern and implement that into a contact_method array of values. In doing so, we create a new schema version.
{
"_id": "<ObjectId>",
"schema_version": "2",
"name": "Anakin Skywalker (Retired)",
"contact_method": [
{ "work": "503-555-0210" },
{ "mobile": "503-555-0220" },
{ "twitter": "@anakinskywalker" },
{ "skype": "AlwaysWithYou" }
]
}The flexibility of the MongoDB document model allows for all of this to occur without downtime of the database. From an application standpoint, it can be designed to read both versions of the schema. This application change in how to handle the schema difference shouldn’t require downtime either, assuming there is more than a single app server involved.
Conclusion
The Schema Versioning pattern is great for when application downtime isn’t an option, updating the documents may take hours, days, or weeks of time to complete, updating the documents to the new version isn’t a requirement, or a combination of any of these. It allows for a new schema_version field to easily be added and for the application to adjust to these changes. Additionally, it provides us as developers the opportunity to better decide when and how data migrations will take place. All of these things result in less future technical debt, another big advantage for this pattern.
As with the other patterns mentioned in this series, there are some things to consider with the Schema Versioning pattern too. If you have an index on a field that is not located at the same level in the document, you may need 2 indexes while you are migrating the documents.
One of the main benefits of this pattern is the simplicity involved in the data model itself. All that is required is to add the schema_version field. Then allow the application to handle and process the different document versions.
Additionally, as was seen in the use case example, we are able to combine schema design patterns together for extra performance. In this case, using the Schema Versioning and Attribute patterns together. Allowing to make schema upgrades without downtime makes the Schema Versioning pattern particularly powerful in MongoDB and could very well be enough of a reason to use MongoDB’s document model versus a legacy tabular database for your next application.
The next post in this series will be a wrap up of all of the patterns we’ve looked at thus far and provide some additional information about use cases we’ve found to be particularly well suited for each pattern.
【以上内容转载于】:https://www.mongodb.com/blog/post/building-with-patterns-the-schema-versioning-pattern