什么是mysql的主从复制
MySQL 主从复制是指数据可以从一个MySQL数据库服务器主节点复制到一个或多个从节点。
MySQL 默认采用异步复制方式,从节点不用一直访问主服务器来更新自己的数据,数据的更新可以在远程连接上进行,从节点可以复制主数据库中的所有数据库或者特定的数据库,或者特定的表。
主从复制优点
数据热备:主库故障后,可切换到从数据库继续工作,一定程度上实现高可用。
读写分离:让主库负责写,从库负责读,使数据层能支持更大的并发;在报表统计等业务形态中尤其重要。比如后台生成报表的多表查询sql语句非常的慢,导致锁表,影响前台实时服务。如果前台使用master,报表使用slave,那么报表sql将不会造成前台锁,保证了前台实时业务的响应速度。
架构扩展:业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。
主从复制原理
一句话概括就是把主服务器上的 binlog日志复制到从服务器上再执行一遍,具体过程:
(1)master必须启用二进制日志,二进制binlog日志中记录了每一次数据变化事件
(2)slave会在一定时间间隔内对master二进制日志进行探测其是否发生改变,如果发生改变,则开启一个I/O Thread请求master二进制日志中的事件
(3)master为slave的I/O Thread启动一个dump线程(二进制日志转储线程),检查自己二进制日志中的事件,跟对方请求的位置对比后,向其发送二进制事件
(4)slave接收到master发送过来的数据把它放置到中继日志(Relay log,也是二进制)文件中;并记录该次请求到master的具体哪一个二进制日志文件内部的哪一个位置
(5)slave将启动一个sql Thread从中继日志中读取二进制日志,在本地重放,使得其数据和主节点的保持一致;并记录relay log中该次执行的位置信息
(6)最后I/O Thread和SQL Thread将进入睡眠状态,等待下一次被唤醒
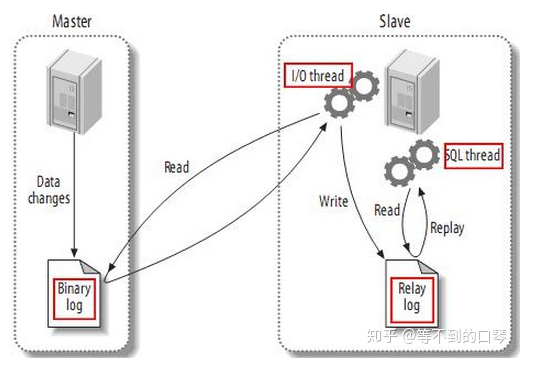
三个线程:
每个主/从连接有三个线程。master为每个当前连接的slave创建一个dump线程(二进制日志转储线程),每个slave都有自己的I / O和SQL线程
master的Binlog转储线程
可以在master执行SHOW PROCESSLIST,输出中标识为Binlog Dump的线程就是:
mysql> SHOW PROCESSLISTG*************************** 16. row *************************** Id: 13630413 User: backuper Host: 10.12.5.3:42672 db: NULL Command: Binlog Dump Time: 603825 State: Master has sent all binlog to slave; waiting for binlog to be updated Info: NULL
Binlog Dump为连接slave的复制线程。该 State信息表明所有未完成的更新已发送到从站,并且主站正在等待更多更新发生。如果Binlog Dump在主服务器上看不到任何线程,则表示复制未运行; 也就是说,目前没有连接任何从站。
这个user就是slave上执行change master to时的master_user,此账号必须有master的复制权限 REPLIACTION SLAVE
slave上的io thread和sql thread
io线程请求并接收master的二进制日志信息并写入到本地的relay log中;sql线程从relay log 中读取日志事件并在本地完成重放。
在slave上,输出SHOW PROCESSLIST如下所示:
root [(none)]> show processlistG *************************** 1. row *************************** Id: 1 User: system user Host: db: NULL Command: Connect Time: 666270 State: Waiting for master to send event Info: NULL *************************** 2. row *************************** Id: 955615 User: system user Host: db: NULL Command: Connect Time: 0 State: Slave has read all relay log; waiting for the slave I/O thread to update it Info: NULL
State信息表示线程1是与主服务器通信的I / O线程,线程2是处理存储在中继日志中的更新的SQL线程,两个线程都处于空闲状态,等待进一步更新。
两个位置信息:
这里我们注意到,slave在每一次数据复制过程中,需要在slave本地记录两个位置信息,以提供下一次的数据复制:
1.io线程读取到的master二进制日志的当前位置信息,写在master.info中;
2.sql线程读取到的当前relay log位置信息,写在realy-log.info中;
由于每次slave都记录了自己当前处理二进制日志的这两个位置,因此可以随时断开slave的连接,重新连接后恢复继续复制,即stop slave再start slave;
在mysql 5.5之前,master.info和realy-log.info是以文件的形式,这样存在一个问题,由于复制的位置信息是在事务提交后才写入这两个文件的,如果在事务提交后slave发生了crash,而此时realy-log.info信息是还没有被刷进磁盘的,实例重启后,当SQL Thread去读取realy-log.info中的位置信息时,会回放已经执行过的relay log,就可能会发生复制错误;
从5.6开始,引进了两个参数relay_log_info_repository、master_info_repository
设置relay_log_info_repository=table,就会创建表mysql.slave_relay_log_info,并将realy-log.info文件中的信息写入到该表中。
设置master_info_repository=table,就会创建表mysql.slave_master_info,并将master.info文件中的信息写入该表。
这样做的好处,就是把SQL线程的事务和更新mysql.slave_relay_log_info的语句看成一个事务处理,这样就会一直同步。
具体步骤:
1、slave执行change master to 命令连接主库,包括主库的连接信息(user 、password、port、ip),并且让从库知道需要复制的binlog起点位置(file名 、position 号)
mysql> change master to > master_host='master_ip', > master_user='user', > master_password='pwd', > master_port=3306, > master_log_file=localhost-bin.000022', > master_log_pos=12345678 ; 1 row in set (0.00 sec)
2、slave会将以上信息,记录到master.info
3、slave执行 start slave 命令后,立即开启io thread和sql thread这两个线程
4、slave的io thread读取master.info文件中的信息获取到IP,PORT,User,Password,binlog的位置信息,然后请求master
5、master通过binlog_dump_thread将最新的本地binlog,通过网络TP以events的方式发给slave的io thread
6、slave的io thread接收到新的binlog日志,存储到TCP/IP缓存,立即返回ACK给slave,并更新master.info
7、slave的io thread将TCP/IP缓存中数据,转储到磁盘relaylog中.
8、slave的sql thread读取realy-log.info中的信息,获取到上次已经应用过的relaylog的位置信息
9、slave的sql thread会按照上次的位置点回放最新的relaylog,再次更新realy-log.info信息
10、slave会自动对应用过的relaylog进行定期清理
一主多从
如果一主多从的话,这时master既要负责写又要负责为几个slave提供二进制日志。此时可以稍做调整,将二进制日志只给某一个slave,这个slave再开启二进制日志并将自己的二进制日志再发给其它slave。这种情况叫做级联复制,工作原理图如下:
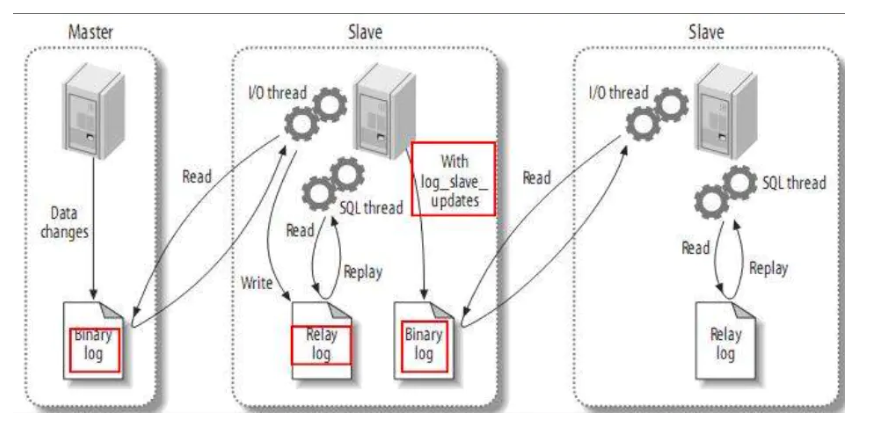
注意:第一个slave必须设置log_slave_updates=1,log_slave_updates是指将slave从master收到的更新记入到slave自己的二进制日志文件中.
因此,对于mysql级联复制,上游的从服务器不仅仅要开启log_bin还要开启log_slave_updates,否则将导致下游的从服务器无法更新复制.
主从复制的两个问题
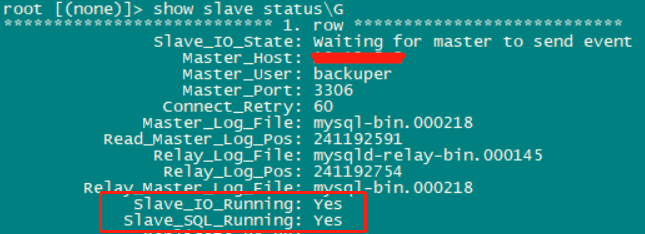
主从复制一般出问题就是slave上两个关键线程,slave_sql_running:No或者Slave_IO_Running:No
如果是slave_sql_running:No
一般在执行主从同步的时候,slave出现了执行不了的sql,导致slave的事务回滚了,所以sql的进程就被关闭了,常见的这个问题的出现方式:
1.程序可能在slave上进行了写操作
2.也可能是slave机器重起后,事务回滚造成的
解决办法:
mysql> stop slave ; mysql> set GLOBAL SQL_SLAVE_SKIP_COUNTER=1; mysql> start slave ;
SQL_SLAVE_SKIP_COUNTER=1的意思是跳过一个复制错误,前提是操作者确定在slave上只进行了一次写操作,只要把这个错误跳过就能顺利继续后面的复制。
当操作者自己都不确定slave误操作了多少写操作时,建议根据slave的备份重做slave,再去和master复制同步。
事件描述1:8月27日,我把需要刷master库的4个脚本,误操作刷到了slave库,9月3日发现问题后又在master库补刷脚本,这时slave出现slave_sql_running:No,主从停止复制

原因:当slave根据master的binlog去create table时,表已存在,导致复制失败,slave_sql_running死掉。
由于slave不止只做了一次写操作,当我SQL_SLAVE_SKIP_COUNTER=1掉过一个错误时,新的Last_Error又会出现。
所以最后只能根据slave的备份,选择8月27日之前的备份(保证还未刷4个脚本)来重做slave,再去和master复制同步。
事件描述2:11月18日半夜zabbix告警
很奇怪的是告警于02:02分自动恢复
查询每日备份的日志发现:slave从库的备份为每日凌晨01:10开始,一般持续5-6分钟,于01:15结束,而当天的备份于02:02才结束
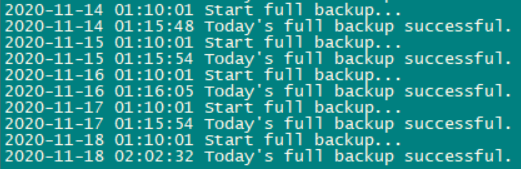
由于监控恢复的时间和备份结束的时间完全吻合,很自然联想到是备份的某个原因导致了slave_sql_running:No
从库备份的脚本,使用mysql的物理备份innobackupex工具,并带了参数--safe-slave-backup
--safe-slave-backup:该选项表示为保证一致性复制状态,这个选项停止SQL线程并且等到show status中的slave_open_temp_tables为0的时候开始备份,如果没有打开临时表,bakcup会立刻开始,否则SQL线程关闭直到没有打开的临时表。如果slave_open_temp_tables在--safe-slave-backup-timeount(默认300秒)秒之后不为0,从库sql线程会在备份完成的时候重启。
简单的说,就是先暂停salve的sql线程,直到没有打开的临时表的时候开始备份,待备份结束后sql线程会自动启动,这样操作的目的主要是确保一致性的复制状态。
由此推断是不是有一直未关闭的临时表,导致了sql线程被暂停后却无法开始备份。
查看slave的慢查询日志,果然有一条在02:02才完成,历时8小时多的记录:
![]()
最后翻盘下完整过程:
当01:10开始从库备份任务,由于设置了参数--safe-slave-backup,首先暂停salve的sql线程;
但因为8个小时的慢查询导致了一直有打开的临时表,备份无法开始,就是这段备份进程挂起等待的时间(50分钟左右),触发了slave_sql_running:No告警
直到02:02慢查询结束并关闭临时表,从库备份顺利开始并完成后,从库sql线程重启,zabbix告警恢复。
参考:
https://blog.csdn.net/wfs1994/article/details/80398234
https://www.cnblogs.com/lehao/p/3924263.html
Slave_IO_Running:No
slave和master断开了binlog的同步,show slave statusG中的Master_Log_File没有对应show master statusG中的File
mysql > slave stop; mysql >CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.xxxxx',MASTER_LOG_POS=0;
mysql > slave start;
MASTER_LOG_FILE 与 MASTER_LOG_POS:
这两项确定slave的io线程下次开始执行时从master开始读取的位置坐标。
总之,主从复制中,Slave_IO_Running: Yes Slave_SQL_Running: Yes 这两项必须为Yes ,以及slave的Log_File、Log_Pos要于master状态下的File,Position相同。
主从复制架构中应注意的问题:
从节点要设置某些限定使得它不能进行写操作,才能保证复制当中的数据一致。
一、限制从服务器为只读
在从服务器上设置:
read_only = ON,但是此限制对拥有SUPER权限 的用户均无效。
阻止所有用户:
mysq>FLUSH TABLES WITH READ LOCK;
二、如何保证主从复制时的事务安全?
1:在master设置参数
sync_binlog=1: Mysql开启bin-log日志使用bin-log时,默认情况下,并不是每次执行写入就与硬盘同步,这样在服务器崩溃时,就可能导致bin-log最后的语句丢失。可以通过这个参数来调节,sync_binlog=N,使执行N次写入后,与硬盘同步。1是最安全的,但是也是最慢的。
如果用到innode 存储引擎:
innodb_flush_logs_at_trx_commit=ON(刷写日志:在事务提交时,要将内存中跟事务相关的数据立即刷写到事务日志中去。)
innodb_support_xa=1 (分布式事务:基于它来做两段式提交功能)
sync_master_info=1:每次给从节点dump一些事件信息之后,主节点的master info 信息会立即同步到磁盘上。让从服务器中的 master_info 及时更新。
2:在每个slave设置参数
skip_slave_start =ON (跳过自动启动,使用手动启动。)
relay_log也会在内从中先缓存,然后在同步到relay_log中去,可以使用下面参数使其立即同步。
sync_relay_log =1 ,默认为10000,即每10000次sync_relay_log事件会刷新到磁盘。为0则表示不刷新,交由OS的cache控制。
sync_relay_log_info=1每间隔多少事务刷新relay-log.info,如果是table(innodb)设置无效,每个事务都会更新。
参考:https://zhuanlan.zhihu.com/p/96212530
https://blog.csdn.net/daicooper/article/details/79905660