问题导入
在实际开发中,我们可能会遇到跨库查询数据的需要,可能是同一连接下的不同数据库的表,或是远程数据库的表。为了开发方便,我们通常会把异库的表映射到本地来读取数据。本文来说说MySQL下的处理办法,其他数据库思路相同,可能具体过程略有差异。
一、同一连接下的不同数据库通过视图映射到本地
假设在同一连接下有数据库db1和db2,现需要将db2.user表映射到db1中,可以使用如下语句在db1中创建视图
CREATE OR REPLACE VIEW db1.vuser AS SELECT * FROM db2.user
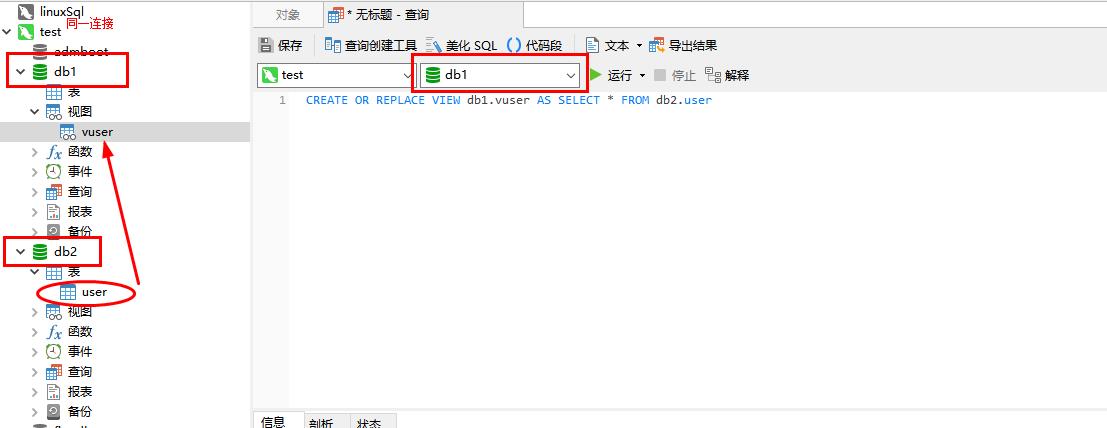
db2.user成功映射到db1中
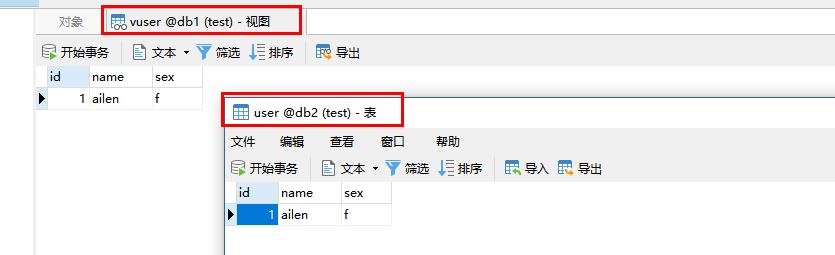
在这样 我们对db1.vuser中的数据增删改查,就可以直接影响到db2.user,当然前提是拥有操作db2.user相关操作权限,把我们db2中需要的表通过视图全部映射到db1中,我们就可以像操作本地库一样操作异库。
二、不同服务下通过FEDERATED存储引擎访问在远程数据库的表中的数据
Federate存储引擎也是mysql比较常用的存储引擎,使用它可以访问远程的mysql数据库上的表,这种引擎的作用类似于oracle数据库的dblink
1.查看federated引擎是否开启
点击进入Navicat并点击键盘上F6,出现命令行界面 ,输入指令:show engines;
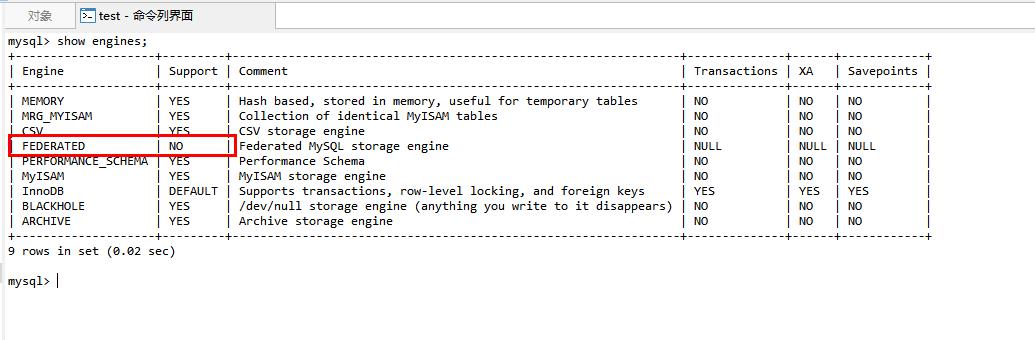
以上说明federated已经安装但是并没有开启
2.开启federated引擎
Windows系统 : 在my.ini的[mysqld]中加入federated(注意:我这里是mysql解压版,直接在解压目录就可以找到ini文件,安装版该文件路径可能有出入)
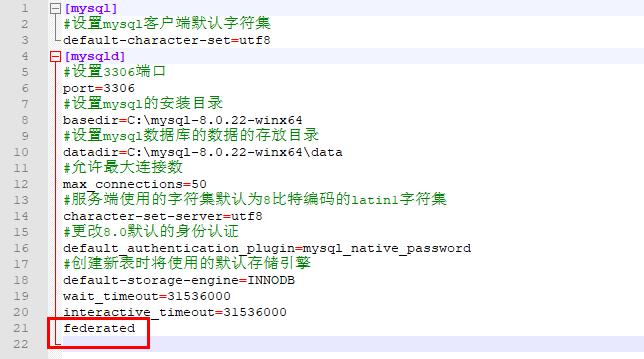
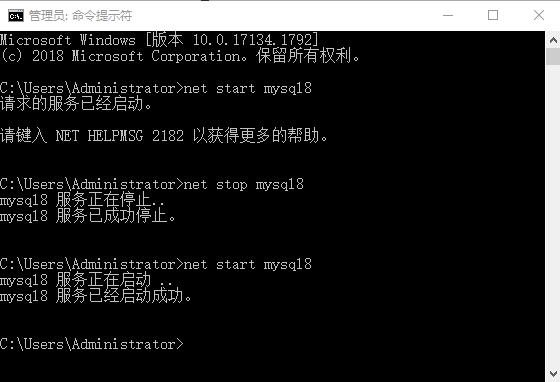
重启mysql服务,管理员打开CMD
cmd>net stop mysql
cmd>net start mysql
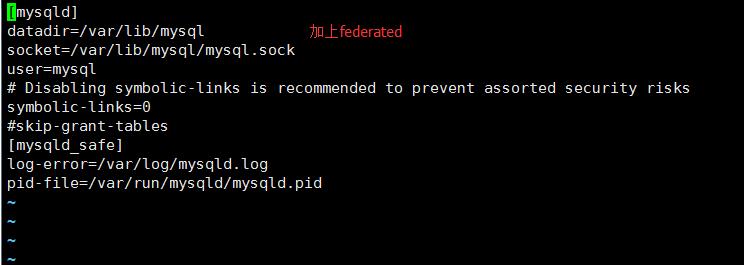
Linux操作系统:vi /etc/my.cnf(以实际路径为准),加入一行federated,保存并退出
重启mysql服务
mysql>service mysqld restart
再次查看,输入指令:show engines;

3.创建fedearted表
CREATE TABLE (......) ENGINE =FEDERATED CONNECTION='mysql://[name]:[pass]@[location]:[port]/[db-name]/[table-name]'
name--mysql用户名
pass--mysql密码
location--ip
port:端口号
db-name:数据库名
table-name:表名
例子:
CREATE TABLE `user` (
`Id` int(0) NOT NULL AUTO_INCREMENT COMMENT '主键',
`UserName` varchar(128) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,
`Name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '姓名',
`Password` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '密码',
`Status` int(0) NOT NULL COMMENT '状态1有效0无效',
`LastLoginTime` datetime(0) NULL DEFAULT NULL,
`CreateTime` datetime(0) NULL DEFAULT NULL,
`Email` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,
PRIMARY KEY (`Id`) USING BTREE
) ENGINE = FEDERATED CONNECTION='mysql://root:root@远程数据库IP:3306/admboot/user';
至此远程数据库的user表就同步到我们本地数据库上了。我们就可以像操作本地库一样操作远程数据库了。
注意事项:
- 对本地虚拟表的结构修改,并不会修改远程表的结构
- truncate 命令,会清除远程表数据
- drop命令只会删除虚拟表,并不会删除远程表
- 不支持 alter table 命令
- 使用索引时,虚拟表与实体表应同步建立索引
三、跨库操作的其他方案
跨库操作的方案有很多种,比如我们还可以在程序上支持多库连接,那么在数据库上我们什么都不需要做,在程序中设置好对应数据库数据即可。
优点:
- 不受数据库类型限制,主库和从库可以是不同的数据库。
- 不建立数据库链,查询速度快。
缺点:
- 表间关联查询只能在内存中进行
- 多库事务一致性不好处理
比如还可以通过接口的方式调用从库数据,等等。大家还有什么比较好的方案可以留言探讨。