SGD,Momentum,Adagard,Adam原理
SGD为随机梯度下降,每一次迭代计算数据集的mini-batch的梯度,然后对参数进行更新。
Momentum参考了物理中动量的概念,前几次的梯度也会参与到当前的计算中,但是前几轮的梯度叠加在当前计算中会有一定的衰减。
Adagard在训练的过程中可以自动变更学习的速率,设置一个全局的学习率,而实际的学习率与以往的参数模和的开方成反比。
Adam利用梯度的一阶矩估计和二阶矩估计,动态调整每个参数的学习率,在经过偏置的校正后,每一次迭代后的学习率都有个确定的范围,使得参数较为平稳。
L1不可导的时候该怎么办
1,当损失函数不可导,梯度下降不再有效,可以使用坐标轴下降法,梯度下降是沿着当前点的负梯度方向进行参数更新,而坐标轴下降法是沿着坐标轴的方向,假设有m个特征个数,坐标轴下降法进参数更新的时候,先固定m-1个值,然后再求另外一个的局部最优解,从而避免损失函数不可导问题。
2,使用Proximal Algorithm对L1进行求解,此方法是去优化损失函数上界结果。(对于目标函数不是处处连续可微的情况,通常是使用次梯度来进行优化,由于次梯度自身的原因会导致两方面问题:求解慢
,通常不会产生稀疏解。Proximal Algorithm主要解决这两个问题)
sigmoid函数特性
定义域为

值域为(-1,1)
函数在定义域内为连续和光滑的函数
处处可导,导数为

切比雪夫不等式
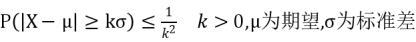
一根绳子,随机截成3段,可以组成一个三角形的概率有多大
设绳子长为a,折成三段的长度为x,y,a-x-y从而得到
最大似然估计和最大后验概率的区别?
最大似然估计提供了一种给定观察数据来评估模型参数的方法,而最大似然估计中的采样满足所有采样都是独立同分布的假设。
最大后验概率是根据经验数据获难以观察量的点估计,与最大似然估计最大的不同是最大后验概率融入了要估计量的先验分布在其中,所以最大后验概率可以看做规则化的最大似然估计。
什么是共轭先验分布
假设 θ 为总体分布中的参数, θ 的先验密度函数为 π(θ),而抽样信息算得的后验密度函数与π(θ)具有相同的函数形式,则称 π(θ) 为 θ 的共轭先验分布。
频率学派和贝叶斯学派的区别
贝叶斯学派认为分布存在先验分布和后验分布的不同,而频率学派则认为一个事件的概率只有一个。
频率派认为抽样是无限的,在无限的抽样中,对于决策的规则可以很精确。贝叶斯派认为世界无时无刻不在改变,未知的变量和事件都有一定的概率,即后验概率是先验概率的修正。频率派认为模型参数是固定的,一个模型在无数次抽样后,参数是不变的。而贝叶斯学派认为数据才是固定的而参数并不是。频率派认为模型不存在先验而贝叶斯派认为模型存在先验。
0~1均匀分布的随机器如何变化成均值为0,方差为1的随机器
均匀分布均值为1/2,方差为1/12
要变为均值为0,方差为1则xv变换为√12(x–1/2)
Lasso的损失函数
Lasso的损失是均方误差+L1正则项 J(θ) = 1/2 ||Y-XW ||2 + λ ∑|θ|
Sfit特征提取和匹配的具体步骤
1. 生成高斯差分金字塔(DOG金字塔),尺度空间构建;2. 空间极值点检测(关键点的初步查探);3. 稳定关键点的精确定位;4. 稳定关键点方向信息分配;5. 关键点描述;6. 特征点匹配
求m*k矩阵A和n*k矩阵B欧几里得距离?
先得到矩阵ABT,然后对矩阵A和矩阵BT分别求出其中每个向量的模平方,并扩展为两个m*k的矩阵A'和B'。最终求得新的矩阵A'+B'-2ABT,并将此矩阵开平方得到A,B向量集的欧几里得距离。
PCA中第一主成分是第一的原因?
PCA本质上是将方差最大的方向作为主要特征,并且在各个正交方向上将数据“离相关”,也就是让它们在不同正交方向上没有相关性。而方差最大的那个维度是主成分
欧拉公式
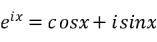
矩阵正定性的判断,Hessian矩阵正定性在梯度下降中的应用
若矩阵所有特征值均不小于0,则判定为半正定。若矩阵所有特征值均大于0,则判定为正定。
判断优化算法的可行性时Hessian矩阵的正定性起到了很大的作用,若Hessian正定,则函数的二阶偏导恒大于0,函数的变化率处于递增状态。
在牛顿法等梯度下降的方法中,Hessian矩阵的正定性可以很容易的判断函数是否可收敛到局部或全局最优解。
概率题:抽蓝球红球,蓝结束红放回继续,平均结束游戏抽取次数
讲一下PCA
PCA是比较常见的线性降维方法,通过线性投影将高维数据映射到低维数据中,所期望的是在投影的维度上,新特征自身的方差尽量大,方差越大特征越有效,尽量使产生的新特征间的相关性越小。
PCA算法的具体操作为对所有的样本进行中心化操作,计算样本的协方差矩阵,然后对协方差矩阵做特征值分解,取最大的n个特征值对应的特征向量构造投影矩阵。
拟牛顿法的原理
牛顿法的收敛速度快,迭代次数少,但是Hessian矩阵很稠密时,每次迭代的计算量很大,随着数据规模增大,Hessian矩阵也会变大,需要更多的存储空间以及计算量。拟牛顿法就是在牛顿法的基础上引入了Hessian矩阵的近似矩阵,避免了每次都计算Hessian矩阵的逆,在拟牛顿法中,基本思想是不计算二阶偏导数,构造出一个近似Hesse的逆矩阵的正定对称阵,从而根据这个近似矩阵来优化目标函数,虽然不能像牛顿法那样保证最优化的方向,但其矩阵始终是正定的,因此算法始终朝最优化的方向搜索。