前言:
由于目前网飞系的停更,国内阿里系微服务生态的大火,考虑到将来社区的活跃度,在这次公司级的微服务选型我选择了springcloud alibaba生态。结合原有netflix的架构做一个本地预研。
目前预研进度:
1.只保留原有组件库下的common、log、restful(swagger3,exception fallback)、feign(含各个微服务的feignClient)与 netflix相关的及数据库缓存等解耦先不引入后续基础框架成型后一次引入。本次我们重点关注放在分布式注册中心、配置中心及服务间的调用。
2.注册中心由Eureka 配置中心由apollo 替换成alibaba-nacos
3.路由网关由zuul-gateway 替换成spring自己的springcloud-gateway,此时nacos本身已实现默认的ribbon负载均衡策略。
4.服务间的调用沿用feign+ribbon,相对alibaba-dubbo的上手复杂度及性价比,综合考虑团队及业务体量,仍然选用前者。
5.微服务的高可用性主角担当(限流与熔断)将hystrix替换成alibaba-sentinel 。满眼都是sentinel的优点。方法级的细颗粒度控制、搭配直观的控制平台、极易可读api、实时查看实时修改的规则。相对hystrix简单粗暴的针对一个微服务做信号量或线程数的配置。前者显得更加的人性化。值得一提,生产环境下的sentinel使用必须做到配置规则持久化这是一个大前提。
6.sleuth+zipkin 分布式调用链追踪
7.未完待续:既然决定了全面拥抱阿里巴巴生态,当然不能放过一些已有的优秀组件。
服务级:分布式事务seata、任务调度服务Alibaba Cloud SchedulerX、消息中间件rocketmq的封装
业务级:Alibaba Cloud OSS: 阿里云对象存储服务、Alibaba Cloud SMS: 覆盖全球的短信服务(ps啥时候把自己的支付业务也集成开源下)
遇到的坑:
1.1 Nacos作为注册中心,swagger2升级3中间遇到的问题难点
a.gateway路由总入口对下属各个服务的命名空间的获取


b.swagger3页面对微服务调用无法带上命名空间的问题处理
通过接口的源码追踪 可以发现swagger3内对页面渲染时没有带上微服务的命名空间。
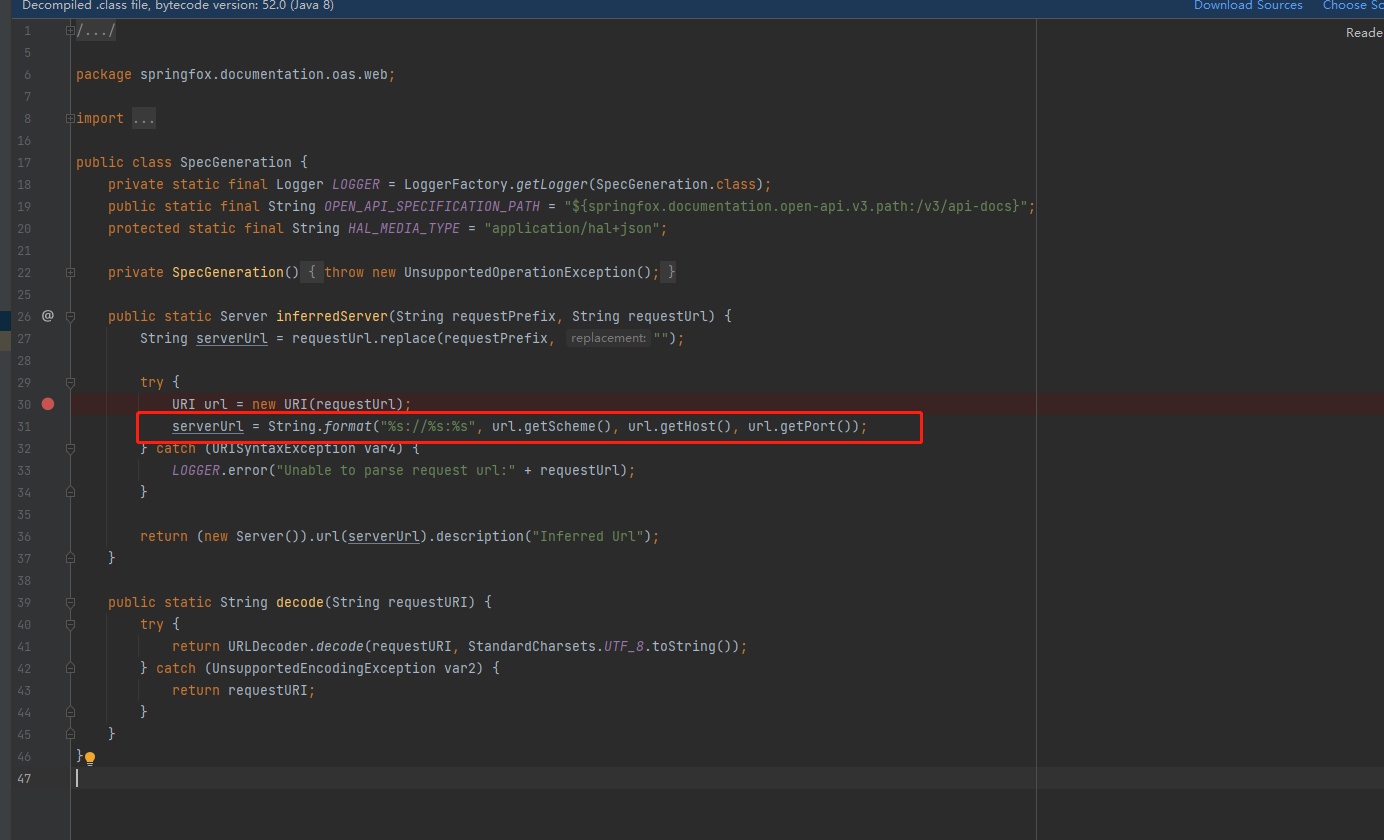
由于swagger3没有开放这部分的重写接口,只能用同包名同类名的方法加@Primary注解强制替换
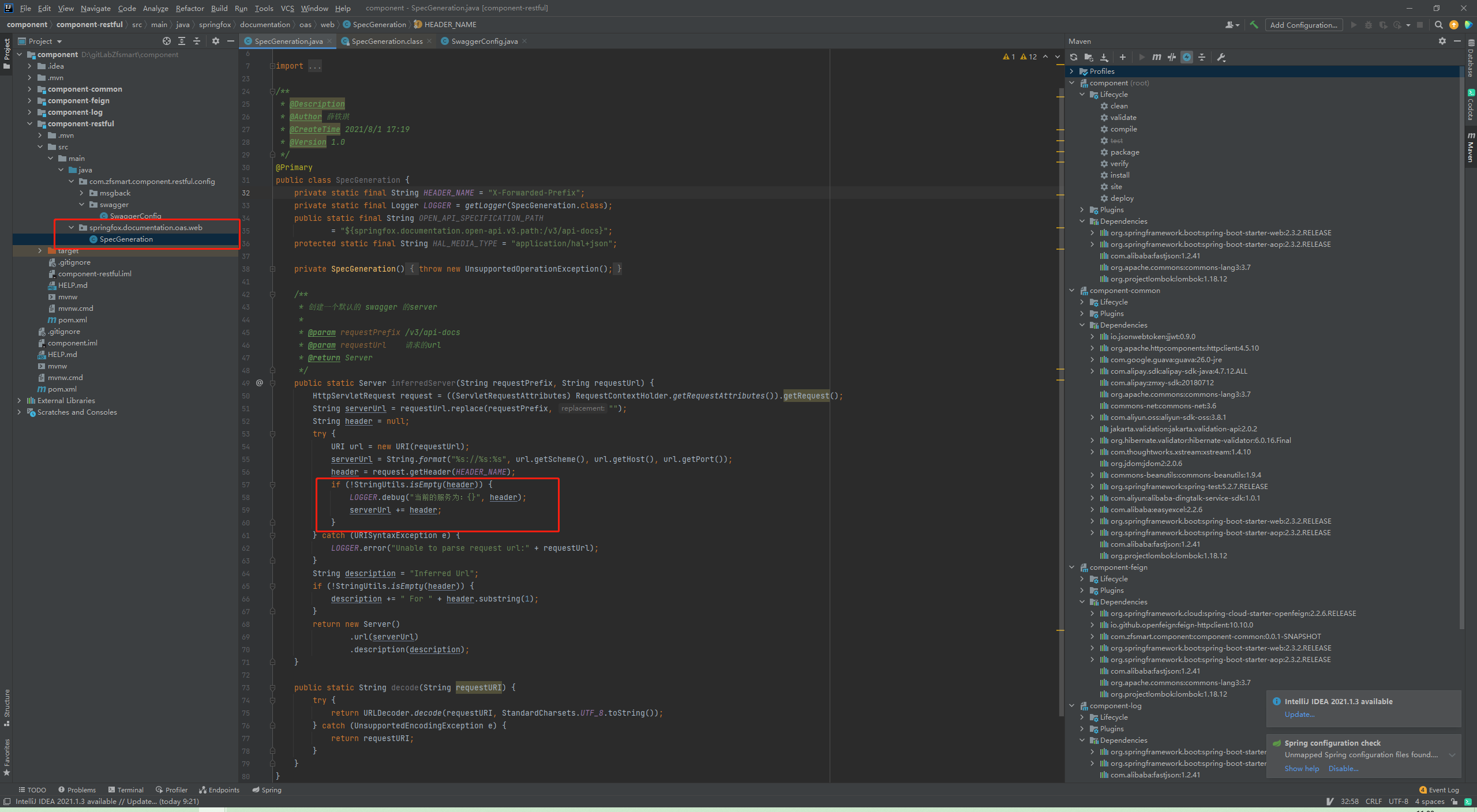
效果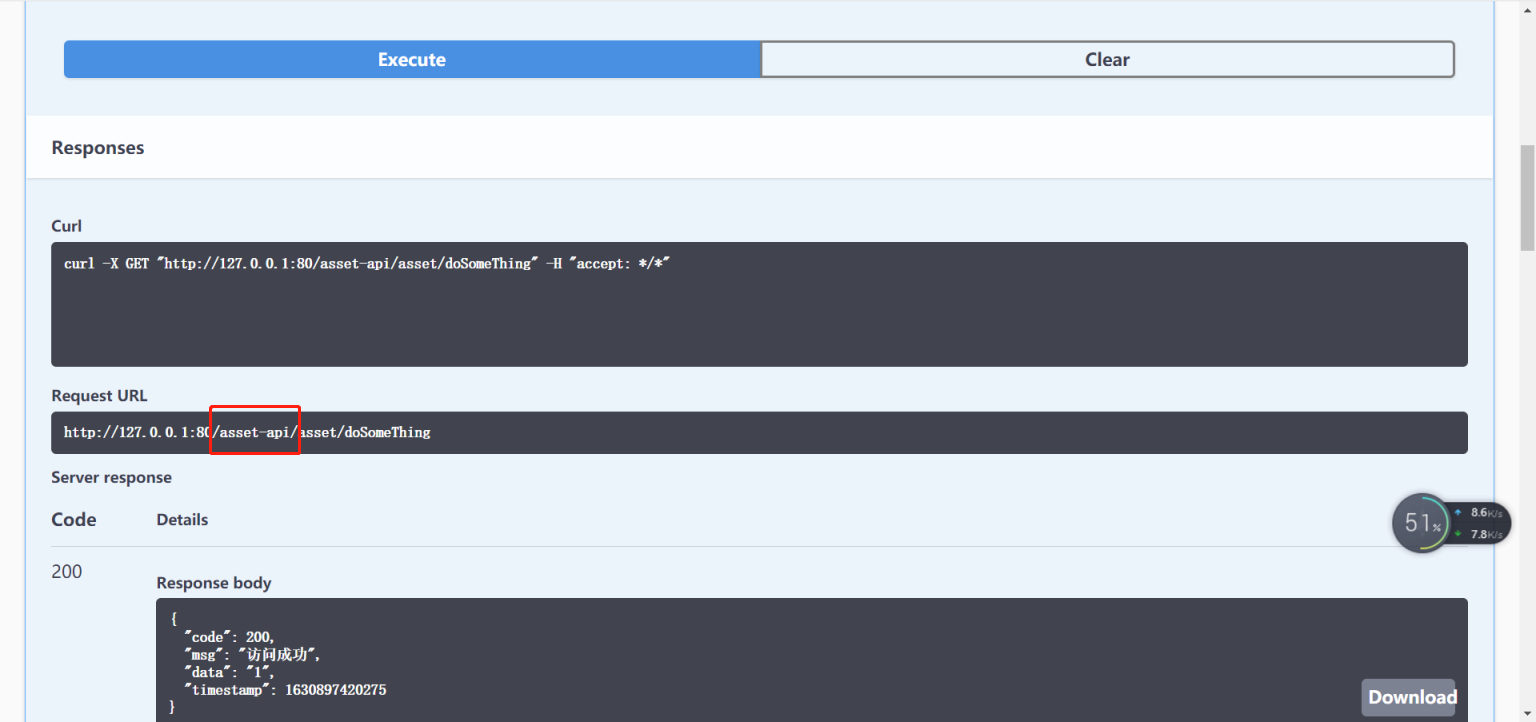
2.1 Nacos部署 服务注册 配置中心引用
a. 服务注册时gateway和其他微服务需要在相同的命名空间
b. 配置中心可以区分环境、项目等隔离,nacos配置中心可以指定dataId grou 
4.1 feign ribbon的配置及优化
a. feign httpClient启用
b. 压缩优化,主要针对文件上传的情况
c.ribbon负载均衡的超时问题
先说结论:1.在没有做好幂等工作情况下,禁用feign跟ribbon两个重试机制。
2.如果需要开启重试机制,超时时间(重试)必须小于熔断时间,否则直接熔断不触发重试。
Feign重试和Ribbon重试
feign自身重试目前只有一个简单的实现Retryer.Default,包含三个属性:maxAttempts:重试次数,包含第一次 period:重试初始间隔时间,单位毫秒 maxPeriod:重试最大间隔时间,单位毫秒
ribbon重试包含两个属性:MaxAutoRetries和MaxAutoRetriesNextServer
总重试次数= 访问的服务器数 * 单台服务器最大重试次数,即:(1+MaxAutoRetriesNextServer)*(1+MaxAutoRetries )
超时时间设置
feign和ribbon的超时时间只会有一个生效,规则:如果没有设置过feign超时,也就是等于默认值的时候,就会读取ribbon的配置,使用ribbon的超时时间和重试设置。否则使用feign自身的设置。两者是二选一的,且feign优先。

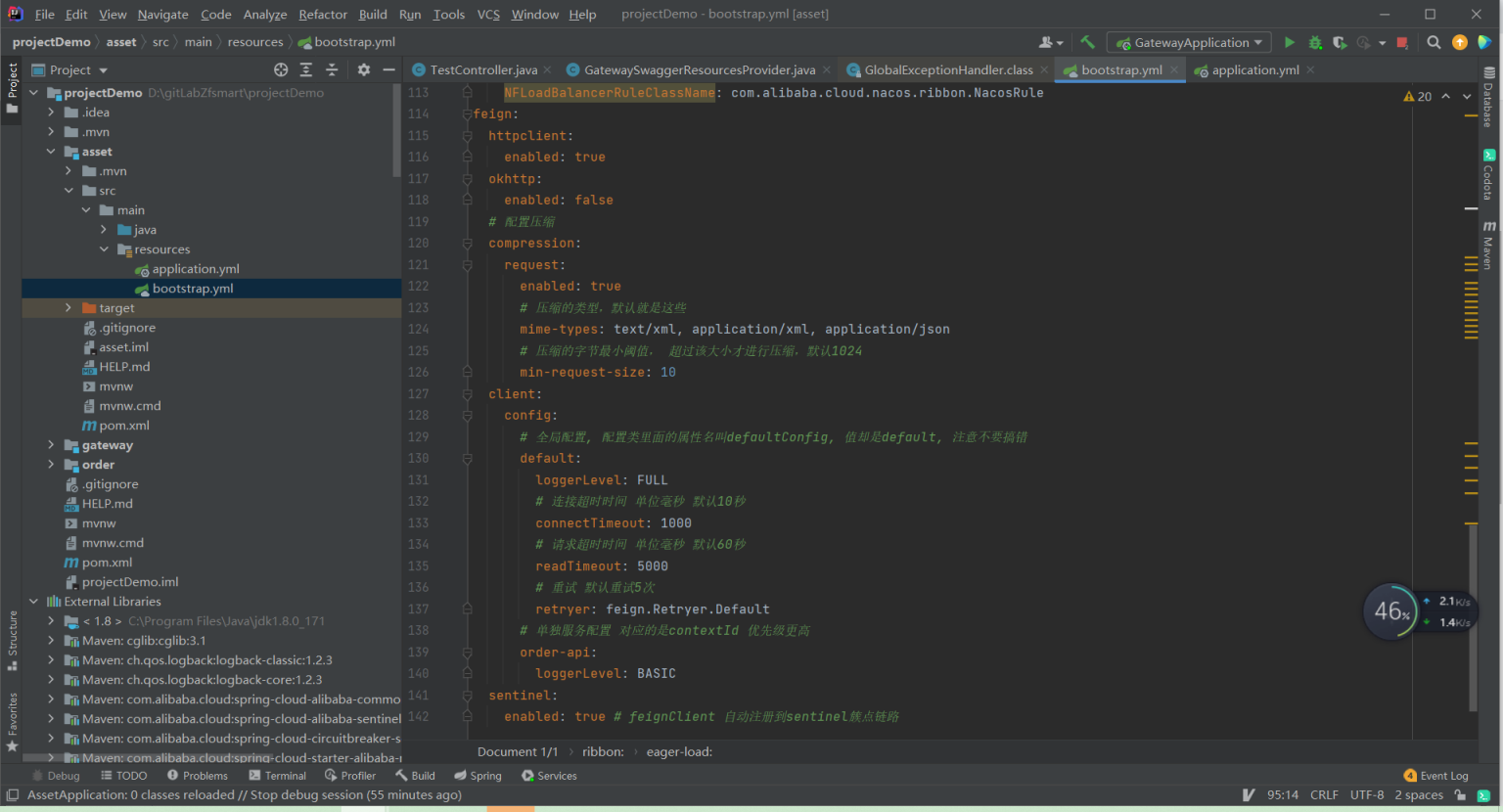
优化后
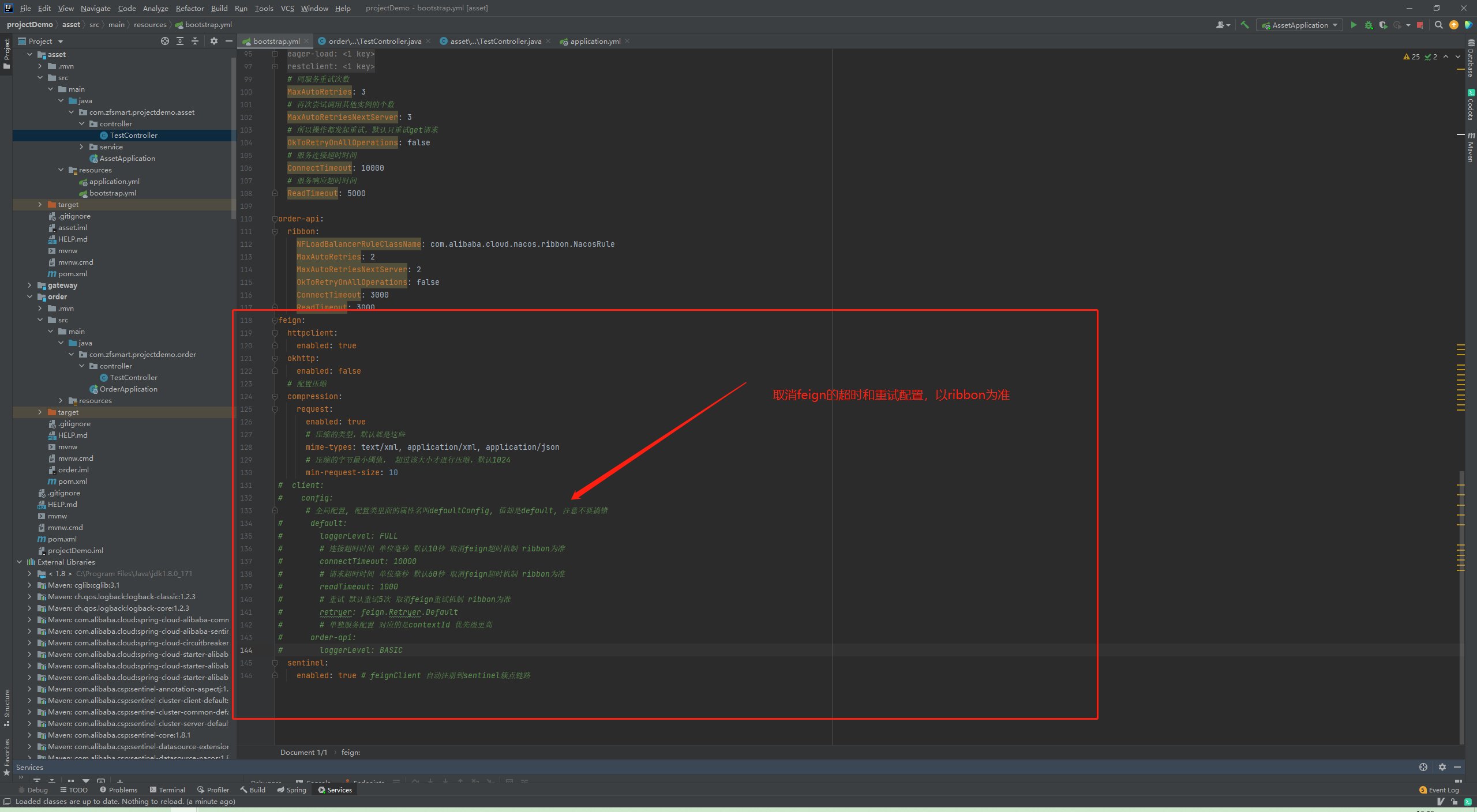
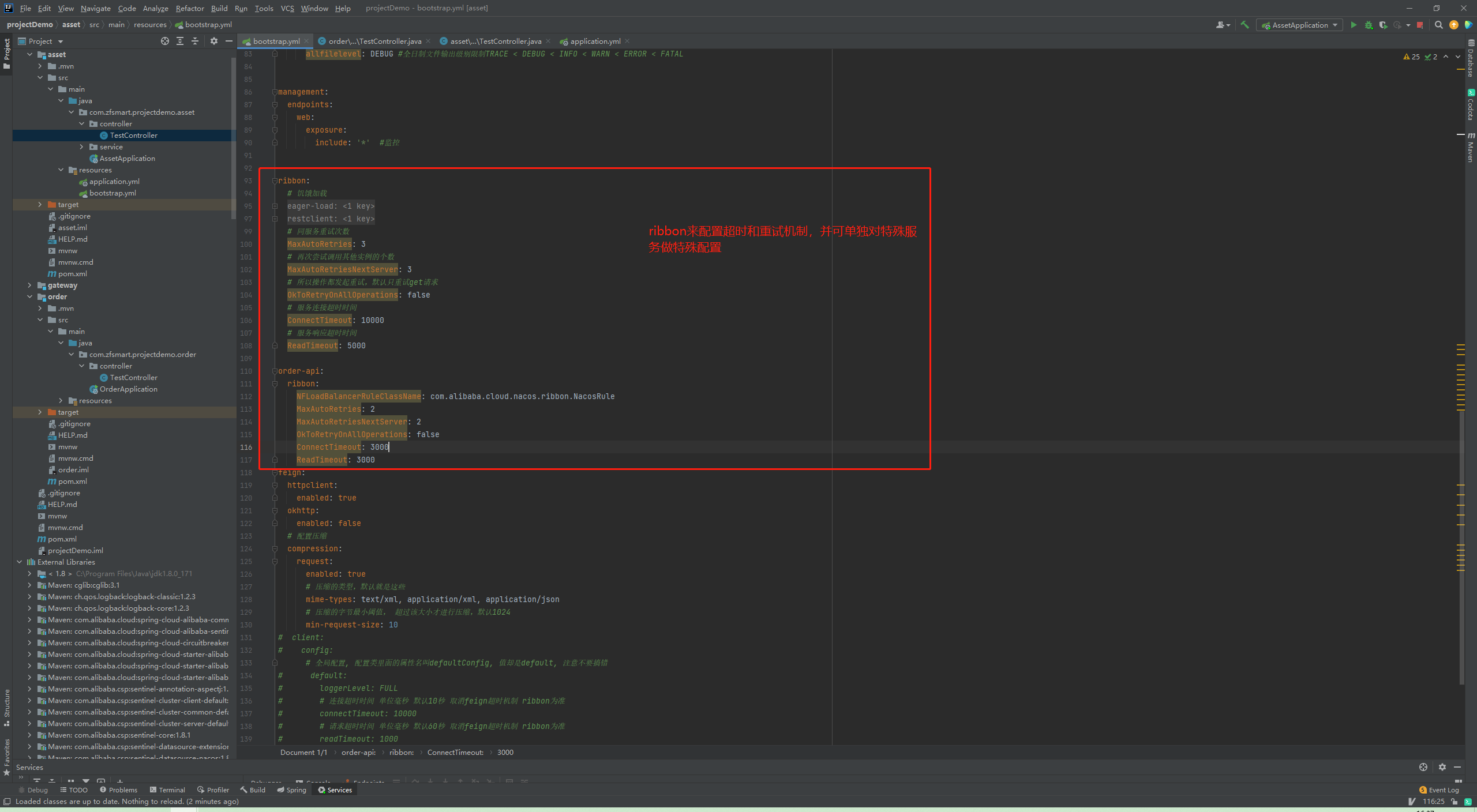
以上述的配置为例如果要开启重试机制,此时sentinel对order-api的熔断时间必须要大于3*(1+2)*(1+2) = 18秒 否则提前进入熔断 后续无法重试
5.1 sentinel部署 资源的简单使用
a. 在配置资源到sentinel以后,达到sentinel的触发阈值默认是抛出异常。如果增加blockHandler或者fallbackHandler将进入方法块(可理解为捕获异常),如未抛出自定义业务异常将继续向下执行。
b.sentinel的配置数据默认存储是memory方式,也就是说随着微服务节点的重启,声明的资源虽然能直接初始化还在簇点链路,但是对应的限流、熔断配置将清空。(ps这还得了几百个的规则重新配置谁受得了)
5.2 sentinel持久化到nacos,sentinel与nacos的双向同步改造
a.引入sentinel-datasource-nacos,微服务在启动时读取nacos的配置文件(专门为sentinel五个规则增加配置文件单独获取),自动的加载到sentinel。(ps感觉还是有点麻烦,那不是每次都要在nacos里面写配置几百个照样很累人啊。。继续寻找解决途径)

b. 对sentinel源码下手,双向同步改造,增加对sentinel规则的监听在sentinel簇点增加规则同时,将规则配置同步更新到对应nacos的配置文件(注意这里配置文件命名规范要一致,不然找不到会新建一个新的)(ps这下舒服了,既可以在sentinel方便的增加规则并同步到nacos配置,又可以线上更新nacos的规则实时同步到sentinel)

参考 https://blog.csdn.net/weixin_40816738/article/details/119453019
也可以直接下载我已经上传的git仓库 https://gitee.com/xuetieqi/sentinel-nacos.git
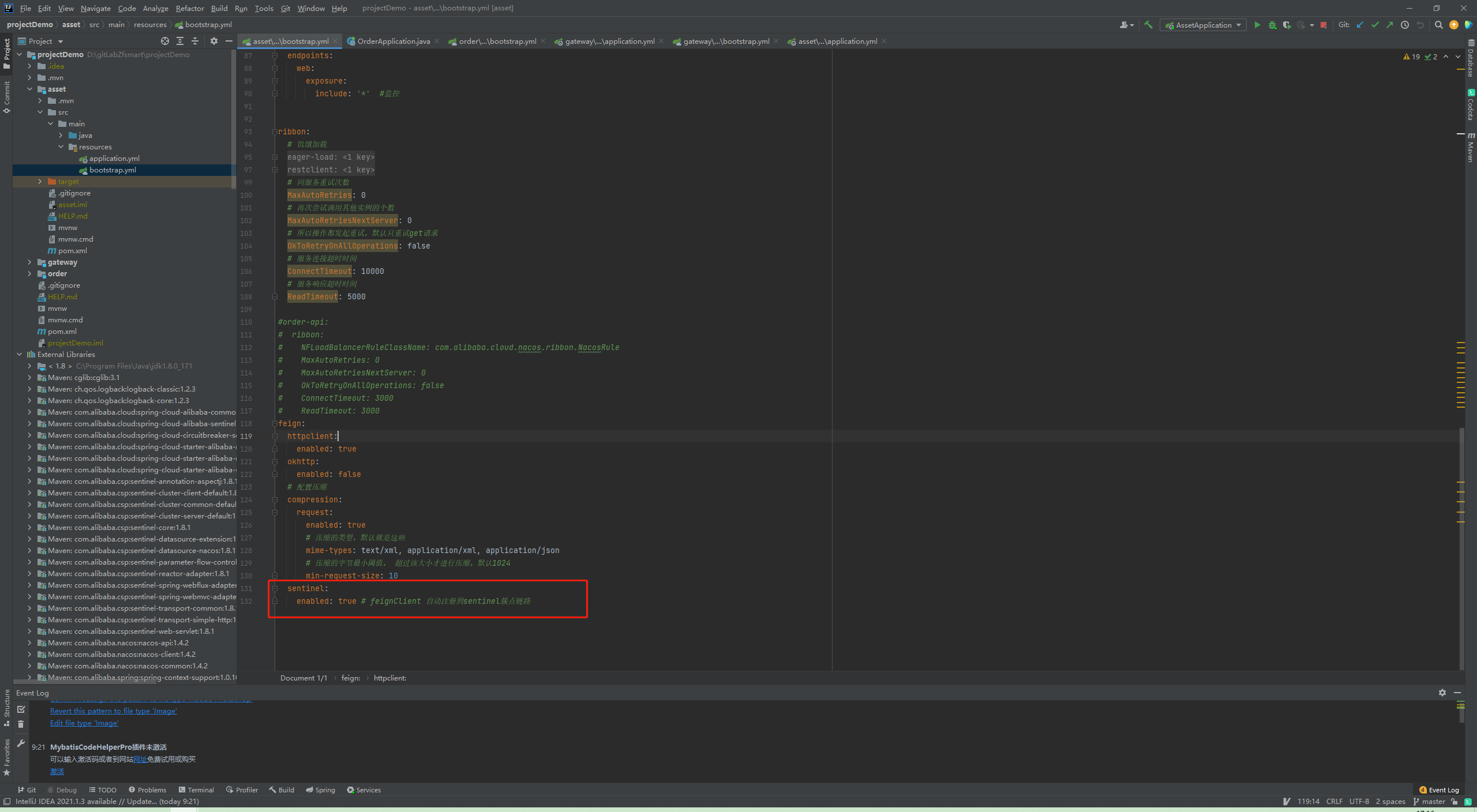
5.3 对feignClient资源的sentinel使用
a. 开启feign对sentinel的支持,此时将会扫描所有feignClinet并将特定规则的资源命名加到簇点链路同步到sentinel,不需要手动声明@SentinelResource
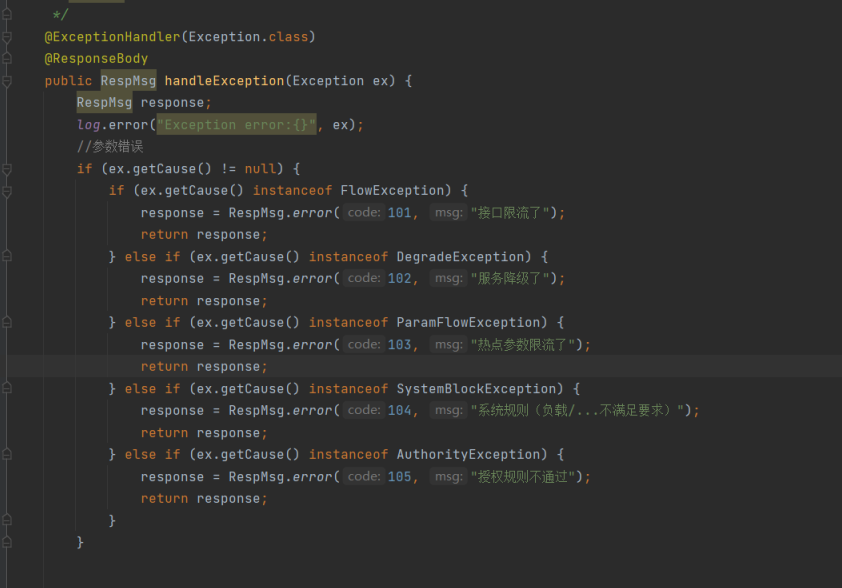
5.4 sentinel异常统一拦截处理(不再增加冗余的fallbackHandler和blockHandler),同学们只要声明@SentinelResource即可(静态资源手动声明,feign资源自动已经声明全部在sentinel簇点链路下可以查看然后增加配置)
5.5 ps因为绝大部分的feignClient基本都要加一次熔断规则,每次在sentinel里面的簇点节点增加貌似也有点不方便。希望可以启动时默认扫描所有feignClient根据上面提到的资源命名规则自动推送一份默认的限流熔断规则到sentinel。那么同学们就只需要关注到本身业务的限流熔断。
未完待续