Abstract
本文: FuzzGen
方法: whole system analysis
特点:无需人力
数据集: Debian, AOSP中的7个库
效果: 17个已有的bugs,6个CVEs
+54.94 code coverage,比较人工写的fuzzers+6.94%
1. Intro
在生成driver这方面,程序内部的隐式依赖所导致的难点,有些状态必须依靠复杂的逻辑来建构,不应该使用fuzzer的随机输入。举例:encode
libfuzzer有个用来生成driver的功能,人工需要提供一个fuzzer stub。这个fuzzer sub需要:
- 调用目标库函数以设置正确状态
- 恰当地使用随机输入来探索程序状态空间
本文:FuzzGen
直觉: - 对库依赖建图应该能够允许我们生成更复杂的API调用
- 单元测试通常都太简单了
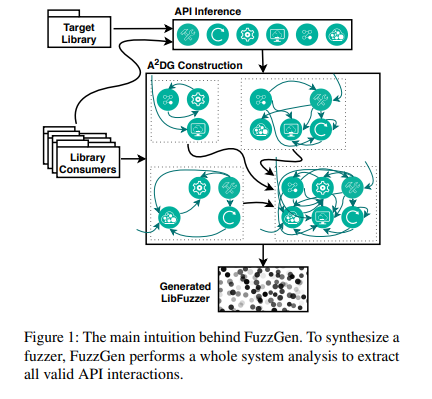
组件:
- API推测
- Abstract API Dependence Graph(A2DG)构建机制
- 这里A2DG是一个记录了所有API交互操作的图,也记录了参数值的区间和可能的交互
- fuzzer generator
特点:无需人力,能够产生各种复杂度的driver
效果: - 在Debian和Android两种系统上执行了测试
- 17个bugs,6个CVEs
2. Case of construction

P1: 解释库功能,说明完成测试必须完成的简单流程
P2: 以对单个帧解码为例,要求必须提供一个参数,这个参数提供一块已经分配的内存,还会告诉valid length
P3: 如何利用控制流信息和共享参数来生成这个参数
3. Background and Related Work
4. Design
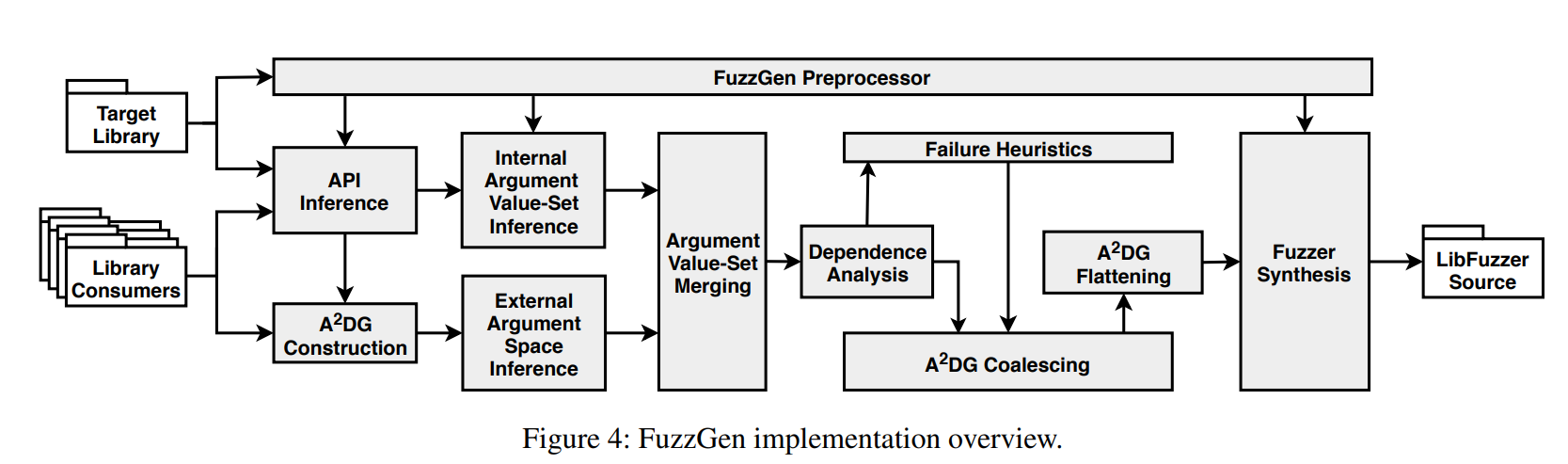
4.1 Infer the lib API
他们收集了所有使用到这个库的项目中包含这个库的头文件中的所有函数,来推测目标库暴露在外的API,这样会造成over approximation
为了处理这个over approximation,他们对这些函数签名一个个试着链接,如果在测试程序上使用这个函数链接时出现错误,就认为这个函数签名不在某个库中
4.2 Constructing a basic A2DG
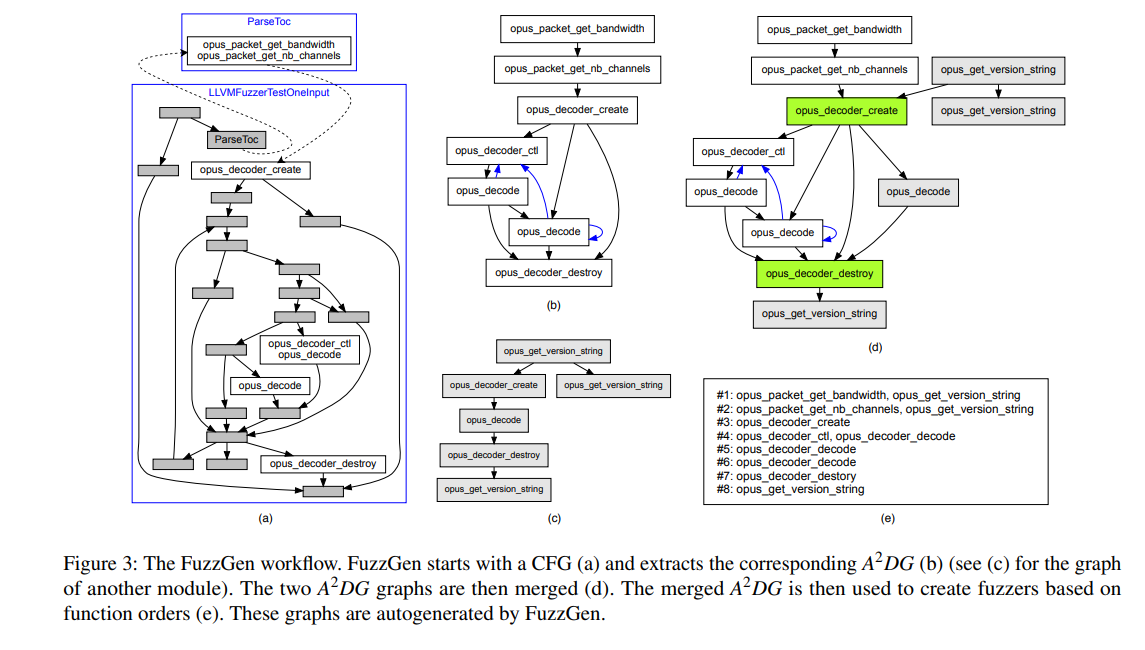
Constructing a basic A2DG
- 在call graph上面,删掉不包含API call 指令的basic block
- 相同的non-API function会被合并在一起来节约复杂度
LTO pass
Coalescing A2DG graphs
合并两个 A2DGs 他们必须至少有一个节点共同点。 如果两个节点使用相同类型的相同参数调用相同的 API 调用,则它们被认为是“公共的”。 FuzzGen 从根开始,选择第一个公共节点。 FuzzGen 然后从一个图中删除节点并迁移所有子节点及其子树,到另一个 A2DG
Precision of A2DG construction
4.3 Argument flow analysis
Argument value-set inference
回答了两个问题:要模糊的参数以及如何模糊这些参数。
根据参数类型将参数分为两类:原始参数(例如,char、int、float 或 double)和复合参数(例如,指针、数组或结构)。
Argument dependence analysis
使用库、跟踪参数和跨 API 调用的返回值对代码进行静态每函数别名分析来识别数据依赖关系。利用向后和向前切片来减少由于基本别名分析引起的不精确
对于 A2DG 中的每条边,FuzzGen 对每对参数和返回值执行另一次数据流分析(???复杂度是否过高),以推断它们是否相互依赖。两种替代方法可以(i)利用示例代码的具体runtime执行(将导致under-approximation),或者(ii)利用将出现的函数间别名分析(分析成本高)。
4.4 Fuzzer stub synthesis
平衡 A2DG 探索的深度和广度
FuzzGen 仅通过位对 API 调用序列进行编码,而不是通过库函数本身对完整的控制流进行编码。 (假设一旦路径被充分探索,模糊器将翻转位以遵循备用路径。)
5. Implementation
6. Evaluation
5x24hr
实验: 2 libs from debian, 5 from AOSP(all codec libs)
对比对象:人工driver
为何codec: 1. 能作为Stage-Fright攻击的对象 2. 需要支持很多种编码格式,更可能有bugs
表中:
人工、自动driver的edge coverage, bugs, 每秒执行次数,总行数