github
https://github.com/sslab-gatech/qsym
Sym-CC用了QSYM的solver内核
Abstract
背景:符号执行能够测出复杂真实的程序中的bug,但是只能应用于小规模程序
本文:QSYM
方法:结合符号模拟和动态二进制翻译的执行(native execution using dynamic binary translation);放松了传统符号执行的严格soundness要求
效果:粒度更好的,更快的,指令等级的符号执行
实验:
数据集LAVA-M
- outperforms
- 能找到14倍于VUzzer的bugs数
- 在DAPRA CGC中126个程序中的104个上比Driller更好
8个真实程序: Dropbox Lepton, ffmpeg, OpenJPEG, objdump, audiofile, libarchive, tcpdump
找到13个bugs
1. Intro
P1: 介绍fuzzing和symbolic execution两种技术,各自的优点
P2: 介绍hybrid fuzzing:fuzzing用于快速探索容易到达的input spaces,符号执行用来解决复杂的分支。例子: Driller在DARPA CGC上找到了6个独特的bugs
P3: hybrid fuzzing仍然无法应用于真实大规模程序,原因:1. 太慢 2. 环境模型不完整或者错误,因此无法生成约束
P4: 本文中系统分析了hybrid fuzzing所遇到的瓶颈问题;key idea: tightly integrate the symbolic emulation to the native execution using dynamic binary translation; 效果: fine-grained, instruction-level symbolic emulation, 区别于目前的方法: coarse-grained, basic-block-level
P5: 放松了strict soundness requirements;主动解决一些constraints;去掉不感兴趣的basic blocks
P6: 实验:
- QSYM outperforms AFL, Driller, Vuzzer
- 在DAPRA CGC中126个程序中的104个上比Driller更好
- 找到LAVA-M中的1368个bugs
P7:
找到13个真实bugs
本文贡献:
- Fast concolic execution through efficient emulation
- efficient repetitive testing and concrete env
- New heuristic for hybrid fuzzing
- Real-world bugs
2. Motivation: Performance Bottlenecks
2.1 P1. Slow Symbolic Emulation
concolic testing速度非常慢的原因主要是因为emulation layer。
本文认为:
存在误区-路径爆炸和解决约束是导致concolic execution速度慢的原因是一种误区
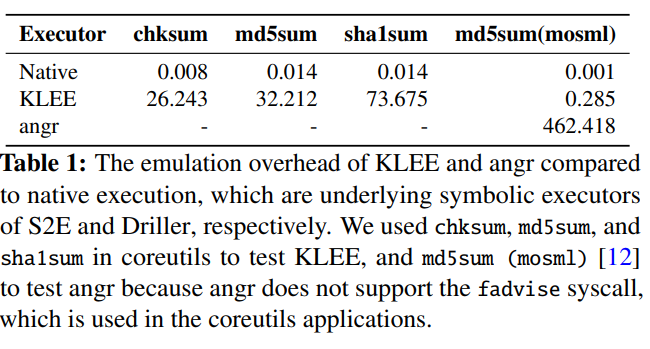
本文在不做path分支和解决约束的情况下,用KLEE和angr对chksum, md5sum, sha1sum和md5sum(mosml)做了实验,发现比直接运行分别慢了3k倍和321k倍
结论:符号模拟层emulation layer严重拖慢了concolic execution的速度
Why is symbolic emulation so slow?
本文认为是因为在symbolic execution中采用了IR导致非常慢
Q: 使用IR的加速优化策略会阻挡进一步优化
- 比如会使得我们无法跳过与符号执行无关的指令
Why IR: IR makes emulator implementation easy
符号模拟器一般都需要把机器指令翻译为一到多个IR指令,这主要是因为符号模拟必须要知道程序机器码中指令和对应操作符是如何影响符号执行相关的memory status,这一步适配需要耗费很大人力。比如amd64 ISA包括1795个指令,manual有2k页。采用IR能够减少这种适配的成本。
KLEE使用了LLVM IR(大概有62个指令),而angr使用了VEX IR。
Why not: IR incurs additional overhead
会带来overhead,会极大地增加指令数目。例如: angr使用的VEX IR在CGC binaries上使得操作数增加了4.69倍
Why not: IR blocks further optimization
使用IR的加速优化策略会阻挡进一步优化:
- 已有策略:如果某个basic block与symbolic variables无关,那么就不去模拟执行这个basic blocks
- 已有策略还能继续优化,例如libjpeg, libpng, libtiff和file中只有30%被选为symbolic basic blocks的基本块真的需要符号执行
- 还有优化余地说明instruction-level的优化还是可行的
- IR caching,也即将机器码都翻译为IR的操作,使得symbolic emulators只能做basic blocks层级的优化,这会阻碍instruction-level优化
本文解决方法
移除了IR translation layer,承担手工在机器码层级上实现emulator的人力代价,以便进一步减少symbolic execution的使用
2.2 P2. Ineffective snapshot
Why snapshot: eliminating re-execution overhead
Why not: fuzzing input does not share a common branch
Why not: snapshot cannot reflect external status
Full system concolic execution
External environment modeling
本文解决方法
2.3 P3. Slow and Inflexible Sound Analysis
Why sound analysis?
Why not: never-ending analysis for complex logic
Why not: sound analysis could over-constraint a path
本文解决方法
3 Design
3.1 Taming Concolic Executor
Instruction-level symbolic execution
Solving only relevant constraints
Preferring re-execution to snapshoting
Concrete external environment
3.2 Optimistic Solving
3.3 Basic Block Pruning
4 Implementation
5 Evaluation
5.1 Scaling to Real-world Software
5.2 Code Coverage Effectiveness
5.3 Fast Symbolic Emulation
5.4 Optimistic Solving
5.5 Pruning Basic Blocks
6 Analysis of New Bugs Found
6.1 ffmpeg
6.2 file
7. Discussion
Adoption beyond fuzzing
Complementing each other with other fuzzers
Limitations
8. Related Work
8.1 Coverage-Guided Fuzzing
AFL, AFLFast, CollAFL, VUzzer, Steelix, FairFuzz, Angora, T-Fuzz
8.2 Concolic Execution
SAGE, Dowser, Mayhem
8.3 Hybrid Fuzzing
2007, Hybrid Concolic Testing提出了Concolic Testing这个概念
Driller
Pak等,2012