LLVM Overview
LLVM是一系列编译技术和工具链技术的集合,主要的subprojects有:
- LLVM Core: source and target-independent optimizer, code generation for many CPUs
- Clang: LLVM native C/C++/Obj-C编译器;Clang Static Analyzer, ;clang-tidy
- LLDB: native debugger
- libc++,libc++ ABI: c++标准库,包括c++11和c++14
- compiler-rt: low-level code generator; dynamic testing tools: AddressSanitizer, ThreadSanitizer, MemorySanitizer, DataFlowSanitizer..
- MLIR: compiler infrastructure
- OpenMP: OpenMP
- polly: cache-locailty optimization, auto parallelism, vectorization, polyhedral model
- libclc: OpenCL
- klee
- LLD: 替换系统Linker,而且比较快
Introduction to the LLVM Compiler
https://llvm.org/pubs/2008-10-04-ACAT-LLVM-Intro.pdf


- 加入新特性: 在文件间进行优化,-O4
- 有兼容新语言的潜力
- 允许JIT优化和编译
- 通过动态信息在运行时对代码进行优化
- easy to retarget existing bytecode interpreter to LLVM JIT
- LLVM支持llvm-gcc和Clang
LLVM: Chris Lattner
1. A Quick Introduction to Classical Compiler Design
传统编译器使用3-phase设计,即将编译器区分为front end, optimizer和backend三部分。
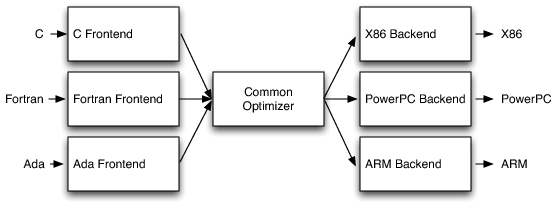
- front end: 解析源代码,检查基本错误,建立AST(有时还会为了优化进一步转为IR)
- optimizer: 一系列优化(这些优化相对语言本身或者平台本身稍微独立),通常包括避免冗余计算。
- backend: map the code onto the target instructions set. 这一步也有一些针对平台的优化,比如instruction selection, register allocation, instruction scheduling.
三相设计减少了开发成本,但是完全实现也面临诸多挑战。Java字节码虽然能够运行在诸多设备上而且很好地支持了JIT编译,但是使用这种字节码后都需要JIT编译,垃圾回收等,让大量CPU计算的项目性能下降;将源码转化为C代码的方法虽然能够重用优化器,却会干扰异常处理;GCC4比较成功,但是JIT等功能无法使用GCC片段,这主要是由于全局变量,weak enforced invariants, 设计有局限的数据结构和宏。
3. LLVM IR
该IR的设计目的是支持轻量运行时优化,跨函数/跨进程优化,whole program分析,激进的重组变形(aggressive restructuring transformations)
define i32 @add1(i32 %a, i32 %b) {
entry:
%tmp1 = add i32 %a, %b
ret i32 %tmp1
}
define i32 @add2(i32 %a, i32 %b) {
entry:
%tmp1 = icmp eq i32 %a, 0
br i1 %tmp1, label %done, label %recurse
recurse:
%tmp2 = sub i32 %a, 1
%tmp3 = add i32 %b, 1
%tmp4 = call i32 @add2(i32 %tmp2, i32 %tmp3)
ret i32 %tmp4
done:
ret i32 %b
}
LLVM IR相当于低层次的RISC语言,使用三地址码。与机器码的主要区别是,LLVM IR的寄存器数量可以是无限的。
LLVM IR实际上有三种形式:
- 文本形式(the textual format)(.ll)
- 数据结构(主要为了优化设计, an in-memory date structure)
- on-disk binary bitcode format(.bc)
可以用llvm-as将.ll转化为.bc,也可以用llvm-dis将.bc转化为.ll文件
IR作为中间层,一方面可以让Optimizzer在没有前后端干扰的情况下工作,一方面在设计的时候也需要考虑到前后端。
一般来说,大多数发生在IR上的优化都遵照以下格式:
- 寻找需要被转化的基本模式
- 确定对要应用的情况该transformation is safe or correct
- 做转化,更新代码
以最简单的优化-计算优化为例,对X-X, X-0, (X*2)-X,明显都能化简,这三种情况分别对应以下IR:
⋮ ⋮ ⋮
%example1 = sub i32 %a, %a
⋮ ⋮ ⋮
%example2 = sub i32 %b, 0
⋮ ⋮ ⋮
%tmp = mul i32 %c, 2
%example3 = sub i32 %tmp, %c
⋮ ⋮ ⋮
简化可以直接用LLVM的simplification interface,比如SimplifySubInst,
// X - 0 -> X
if (match(Op1, m_Zero()))
return Op0;
// X - X -> 0
if (Op0 == Op1)
return Constant::getNullValue(Op0->getType());
// (X*2) - X -> X
if (match(Op0, m_Mul(m_Specific(Op1), m_ConstantInt<2>())))
return Op1;
…
return 0; // Nothing matched, return null to indicate no transformation.
for (BasicBlock::iterator I = BB->begin(), E = BB->end(); I != E; ++I)
if (Value *V = SimplifyInstruction(I))
I->replaceAllUsesWith(V);
4. LLVM's implementation of 3-Phase Design
4.1
LLVM IR是优化程序的唯一输入,因此基本设计方案是构造一个frontend输出LLVM IR,再使用Unix pipes发送给选定的optimizer序列和code generator。
优点:GCC的GIMPLE中间表示不是self-contained representation,当GCC code generator释放DWARF debug information时,需要重新从source level tree上面再遍历。这里操作或许用了tuple形式表示,但是operands还是用的source level tree form,这最终导致GCC doesn't have a way to dump out "everything representing my code",也无法独立地读写GIMPLE。
4.2
LLVM被设计为一组库,或者也可以说LLVM是infrastructure。LLVM库具有许多功能,但是它们实际上并不自己做任何事情。库的客户端(例如Clang C编译器)的设计者应决定如何充分利用这些内容。这种仔细的分层,分解和对子集能力的关注也是为什么LLVM优化器可以在不同环境中用于如此广泛的不同应用程序的原因。另外,仅因为LLVM提供了JIT编译功能,并不意味着每个客户端都使用它。
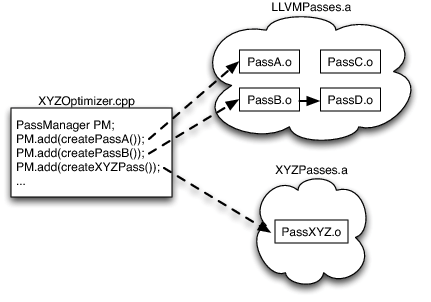
以优化器为例,根据不同优化级别,会选择不同的pass,每个pass中包括inliner, expression reassociation, loop invariant code motion等。每个LLVM pass都被实现为C++类Pass class的派生类。
如果给定一系列要去运行的passes,LLVM PassManager用显式依赖信息来满足不同passes之间的执行。
namespace {
class Hello : public FunctionPass {
public:
// Print out the names of functions in the LLVM IR being optimized.
virtual bool runOnFunction(Function &F) {
cerr << "Hello: " << F.getName() << "
";
return false;
}
};
}
FunctionPass *createHelloPass() { return new Hello(); }
对于JIT编译器等工具,用户可以指定执行的pass和顺序,而且也可以自由实现自己基于特定语言的pass。此外,LLVM只会链接需要使用的代码,如果某个Pass没有被使用,也就不会被链接。
5. Design of the Retargetable LLVM Code Generator
代码生成器虽然是针对Target定制的代码,但是有一些算法是共通的,比如在某些Target上寄存器分配策略可以一样。LLVM code generator也将该问题化为多个独立的passes,比如instruction selection, register allocation, scheduling, code layout optimization, assembly emission。
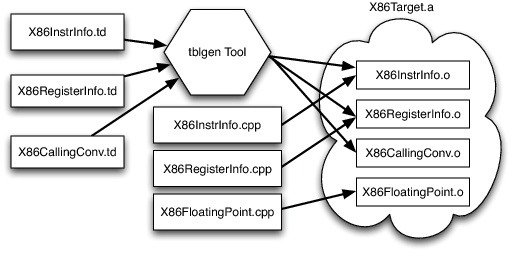
5.1 LLVM Target Description Files
每个shared组件需要知道target specific properties,而且提供这些信息的方式应该是general的。LLVM对此的解决方法是使用一种declarative domain-specific language来为来描述target,具体来说,就是用一系列tblgen工具生成的.td文件来描述。
def GR32 : RegisterClass<[i32], 32,
[EAX, ECX, EDX, ESI, EDI, EBX, EBP, ESP,
R8D, R9D, R10D, R11D, R14D, R15D, R12D, R13D]> { … }
let Constraints = "$src = $dst" in
def NOT32r : I<0xF7, MRM2r,
(outs GR32:$dst), (ins GR32:$src),
"not{l} $dst",
[(set GR32:$dst, (not GR32:$src))]>;
This definition says that NOT32r is an instruction (it uses the I tblgen class), specifies encoding information (0xF7, MRM2r), specifies that it defines an "output" 32-bit register $dst and has a 32-bit register "input" named $src (the GR32 register class defined above defines which registers are valid for the operand), specifies the assembly syntax for the instruction (using the {} syntax to handle both AT&T and Intel syntax), specifies the effect of the instruction and provides the pattern that it should match on the last line. The "let" constraint on the first line tells the register allocator that the input and output register must be allocated to the same physical register.
6. Capabilities provided by a Modular Design
LTO
Link-Time Optimization (LTO) :当LLVM发现.o文件中是LLVMbitcode之后,会执行链接,然后运行LTO

Install-time optimization
Install-time optimization: 延迟代码生成,可以延迟到link time之后。
By delaying instruction choice, scheduling, and other aspects of code generation, you can pick the best answers for the specific hardware an application ends up running on.

Unit test
能直接用LLVM IR来写单元测试,这样不必用.c来写进而避免编译带来的影响,也不必直接生成可能不符合规则的.o。
; RUN: opt < %s -constprop -S | FileCheck %s
define i32 @test() {
%A = add i32 4, 5
ret i32 %A
; CHECK: @test()
; CHECK: ret i32 9
}
BugPoint
能做test case Reduction