Abstract
DBMS往往要求输入符合语法和语义规范,这导致传统fuzzer效率很低。
本文:
提出工具Squirrel
特点:
- 同时考虑language validity和coverage feedback
- 设计IR(Intermediate Representation)
- dependency graph
实验:
- 对象: SQLite, MySQL, PostgreSQL, MariaDB
- 效果:
1. 51bugs in SQLite, 7 MySQL, 5 MariaDB, 52 fixed, 12 CVE assigned
2. 2.4-243.9倍语义正确性
3. 能够有效找到memory errors
1. Intro
P1: 介绍DBMSs的重要性,bugs可能导致什么样的后果或者招致什么攻击
P2: 基于生成的测试基本方法(着重于需要建立SQL model),局限(没有针对性地对所有潜在Query一视同仁导致低效,为什么低效)
P3: fuzzing(注意这里强调了fuzzing能用来处理memory error),基本方法,特点(利用feedback,记录code path informations),
P4 + P5: fuzzing局限(syntactic check, semantic check),列举具体数据佐证(AFL)
P6: 本文工作Squirrel
特点:
- syntac preserving mutation + semantic-guided instantiation
- 设计IR(Intermediate Representation)
- 3种mutation: 插入,删除,替换
- query analysis:获取IR数据之间的Expected dependencies,再将没有填入具体语义元素的stripped IR填入具体数据。
P7: 介绍了本文写了很多行代码,代码中重用了AFL,重用的目的是收集coverage和为种子排序(特别指明主体算法再很多行代码里,不是这些重用的AFL代码);此外,介绍了本文有潜力和其他fuzzer一起用
P8: 实验,基本内容如abstract
P9: 实验,补充了竞品软件(AFL, Angora, SQLsmith, GRIMOIRE, QSYM),每个软件的特点或者至少是基本方法分类,实验运行时间,找到更多edges
P10: major contributions
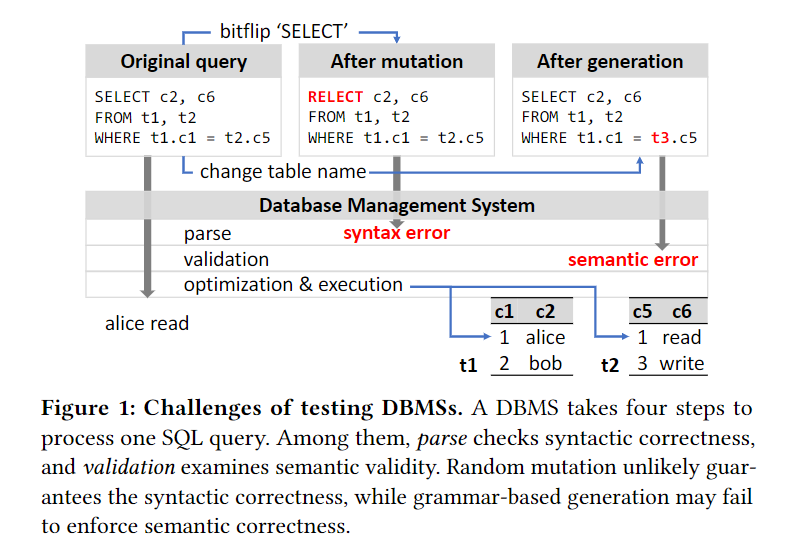
2. Problem Definition
介绍了本节的内容,先描述DBMS基本过程-然后...
2.1 Query Processing in DBMS
DBMS分为parse, validation, optimization ,execution,介绍每节功能和前后联系,描述了如果不通过validation就测不到后面optimization和execution这两个主要步骤
2.2 Challenges of DBMS Testing
生成SQL queries的主要方法有model based generation和random mutation。
model based generation:
特点:需要建立grammar model
示例工具: SQLsmith
缺点:
- cannot efficiently explore the program's state space since many queires are handled in the same way by DBMSs
- 不能确保语义正确
random mutation
基本步骤,如何利用feedback,在许多feedback-driven上有效例如
缺点:容易通不过检查例如,+ 使用AFL来做小型实验验证
2.3 Our Approach
再次强调syntax-correct和semantics-aware这两点。
Generatiing Syntax-Correct Queries
- 使用IR来表示SQL queries
- 好处: structual and informative way; 每个IR只有两个operands,操作起来简易
- 每个IR statement都有一个grammar type,比如SelectStmt
- 剥离每个IR上面的具体数值,比如table names,聚焦于变异语法骨架
- 基于IR statement grammar type来mutate
- insert type-matched operands
- delete optional operands
- replace operands with type-matched ones
为什么不基于AST变异?
变异AST过于复杂
Improving semantic correctness
背景:
彻底确定SQL正确性也是NP-hard问题。现有工具大多会直接定义一些query template,每个template = complete query + static constraints between operands
然而这些frameworkds不能保证the expressiveness,也就是不能够确保能够用来形容全部合法queries。
本文处理的方式: dynamic query instantiation
- 根据已有的basic rules来定义data dependency graph,比如select的operand可能是from中a column name of table。
- 试图用具体的operands来填补语法骨架(stripped IR)
3 Overview of Squirrel
Figure2展示整体framework过程。

这里强调了Squirrel的目标:找到令DBMSs crash的query,这里一个query包含多个SQL statements,相当于一个testcase(这里的定义声明很好的解决了为什么每个query之后要清理一次数据库,即start with an empty database,数据库历史影响怎么办之类的疑惑)
描述Squirrel的四大组件:1. Translator 2. Mutator 3. Instantiator 4. SQL Fuzzer
描述了Squirrel的具体步骤:
- 从队列中选取一个query I
- Translator将I翻译为IR列表V,同时抹掉其中的具体数据元素
- Mutator通过增/删/替换来从V变异出一个新的IR列表V'
- Instantiator分析V'的data dependency并建立data dependency graph
- Instantiator根据data dependency graph挑选能够满足语义正确性的具体值
- 将V'翻译回SQL query I'
- 运行DBMS on I',如果出现crash或者找到新路径,就认为这个input interesting,将它加入队列
4 Intermediate Representation
IR的意义和重要性,设计原则(expressive, general, simple)
遵从SSA form,每个statement都是赋值语句,左值是destination variable,右值是literal或者operator with operands。
IR fields:
- ir_type: 与AST的node type基本保持一致,此外,还有一个Unknown来对应AST中找不到的node
- operator: SQL keywords或者数学运算符号。Q: It indicates the operation the IR performs and includes three parts: the prefix op_prefix, the interfix op_mid and the suffix op_suffix.For example,the IR of "CREATE trigger BEGIN list END" has prefix CREATE, interfix BEGIN and suffix END.
- left_operand, right_operand: operand依然是IR statement或者NULL
- data_value: the concrete data
- data_type: e.g: ColumnName
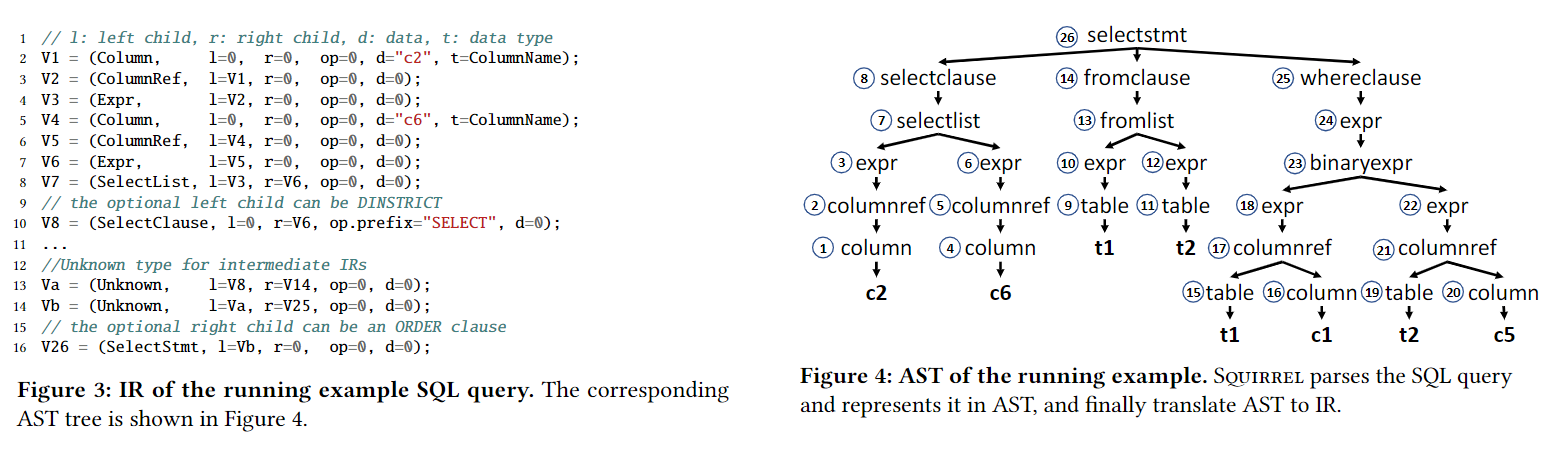
用实际例子Figure 3,4举例IR到底长什么样,以及和AST的对应关系。
5 Syntax-Preserving Mutation
本文将SQL query中的tokens根据作用分为两组。
- structure token: SQL keywords和数学操作符这种决定操作的token
- data这种是操作对象的
我们通过观察得知structure tokens一般在DBMS执行上影响更大。
原因:
- 更改structure tokens能够改变query的operation,进而能够引发不同的functions
- 随意更改与语义相联系的数据可能会导致语义不正确进而无法接收
为此我们采取措施: strip + 主要在structure上做变异
5.1 Structure-Data Separation
- 将所有的concrete data都替换为对应data_type的默认值:
- semantic data: x:例如表x
- constant numbers: 1或者1.0
- string: a
- 按照IR type将IR存在Library中,会删掉structure已经出现过了的query。当然,每个IR Library容量是有限的,防止溢出。
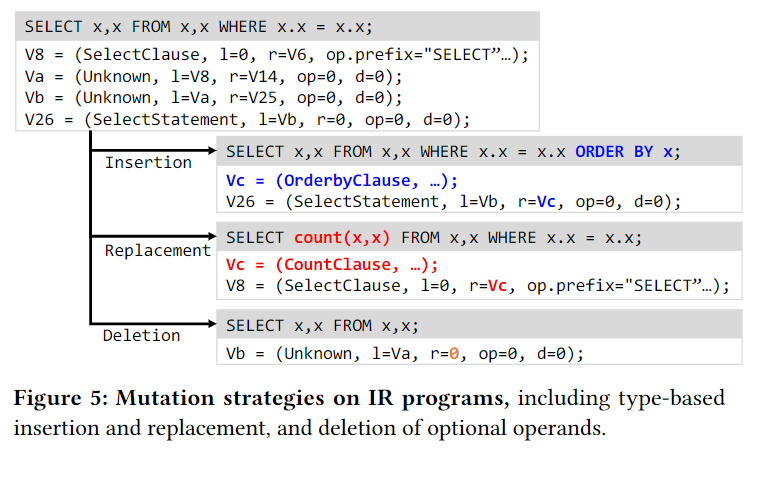
5.2 Type-based mutation
删/替换/添加
在变异之后,会把IRs转化为SQL query,然后做syntax validation,如果不行就会丢弃这个变异
使用Unknown type来做fuzzy type-matching的时候就不搜索concrete types直接进行潜在的mutations,这可能会导致一些invalid queries
6 Semantics-Guided Instantiation
Semantics-correct的好处,挑战,在一个js fuzzer上面test cases不满足semantics-correct的概率
基本方法重述
6.1 Data Dependency Inference
Data dependency示例
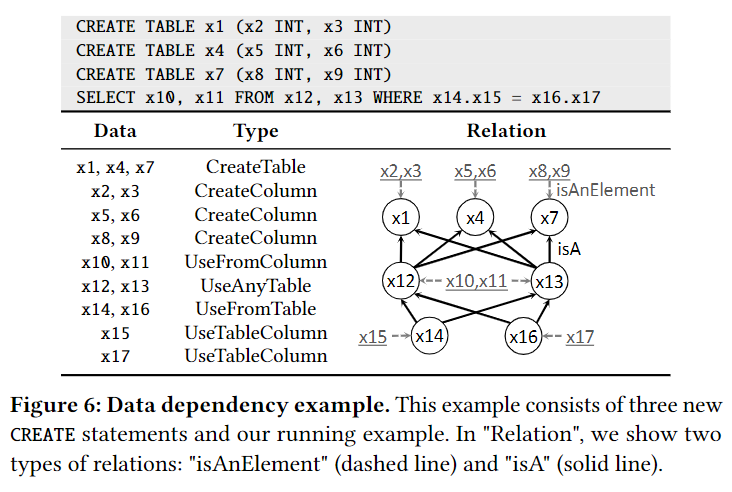
本文手动设计了一系列规则用来推测数据之间的依赖性,这些规则主要依据两个原则:
- lifetime: 在使用SQL variable之前创建这个variables,并且在删除一个变量之前不再使用一个变量
- customization: 根据data types, scopes和operations来决定relationship
Data type
本文设计datatype以使其能够反映上下文环境。根据lifetime原则,需要区分元素是第一次倍定义还是只是使用,如CreateTable, UseTable;根据数据使用的scope,例如UseAnyTable和UseFromTable(意指这里出现的只能是use table,而且必须是from中已经声明过的)
接下来的一段使用Fig6重新说明了Data type的设计原则
Data Relation Rule
定义data relation rule为(α,β,γ,S),α是relation target, β是relation source,γ是relationship,S是scope:intraStmt, interStmt, any(any instance while nearest for the element with the shortest path according to the Define-Use chain)
我们为全部DBMS定义8个rules,SQLite 1 extra rule,MySQL 2 extra rules, Maria DB 2 extra rules, PostgreSQL 1 extra rule。
还是需要用Fig6做说明
Dependency Graph
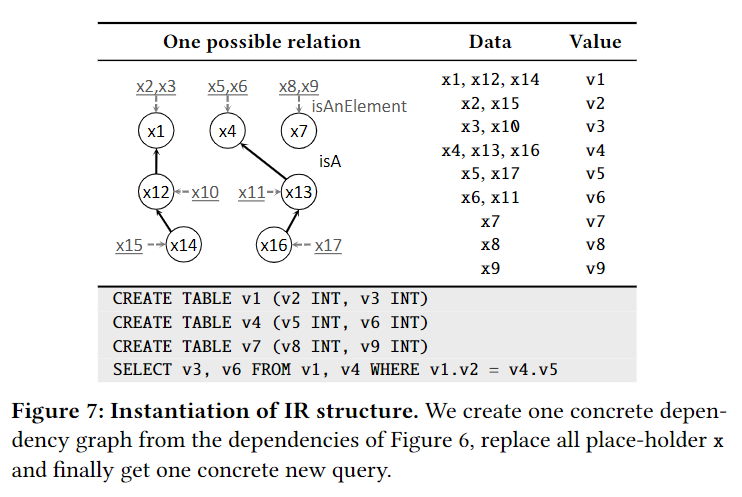
Squirrel会根据data types和relations来构建dependency graph G = <V, E>。
V中每个节点代表一个IR data和其data type。
E中每条边代表从edge source到edge target的relationship。
如果a data type依赖于多个data types,那就随机从这些data types中抽取一个以避免circular dependency。(Q:为什么是data type之间的dependency而不是data之间的?)
如果dependent type有多个候选,也是随机只取一个(示例?)
最终,整张图是森林或者树,不会存在任何环
6.2 IR Instantiation

说明算法1:
基于语句顺序使用深度优先将nodes排序,以保证lifetime correctness,对于literal data比如integers,随机生成或者从预先定义的集合中直接取值。对semantic binding data,填入具有意义的names。
根据Figure 7来形容从data dependency 如何填入数据生成SQL。
7 Implementation
再次说了代码量,并且用table1说了每个模块的代码量
AST parser
设计了general AST parser之后,再为每个DBMS定制。Bison + Flex。没有定义和权限相关的。
Fuzzer
AFL2.56b,每次查询之后drop database。
Effort of Adoption
- customize the general parser
- 写semantic relation rules according to the grammar
- client-server mode则需要一个client
本文认为熟悉系统的人能在一天之内做完adaption
8 Evaluation
要回答的问题:
- Can Squirrel detect memory errors from real-world production-level DBMSs?(§8.1) 能否找到memory error
- Can Sqirrel outperform state-of-the-art testing tools? (§8.2) 竞品对比
- What are the contributions of language correctness and coverage-based feedback in DBMS testing? (§8.3) Squirrel在语言正确性和coverage-based feedback的优势
Benchmark

选取哪些数据库,选取哪些竞品,兼容性问题-具体哪些竞品不能测哪些数据库+We are actively seeking potential solution
Seed Corpus
Github获数据库,单元测试取种子
Setup
机器环境,afl-clang+llvm插桩,edge-coverage做feedback,bitmap大小,Angora的参数1024k bitmap,运行时间,运行方式(docker + 10Gmemory),结果是平均值,附录有p值
8.1 DBMS Bugs
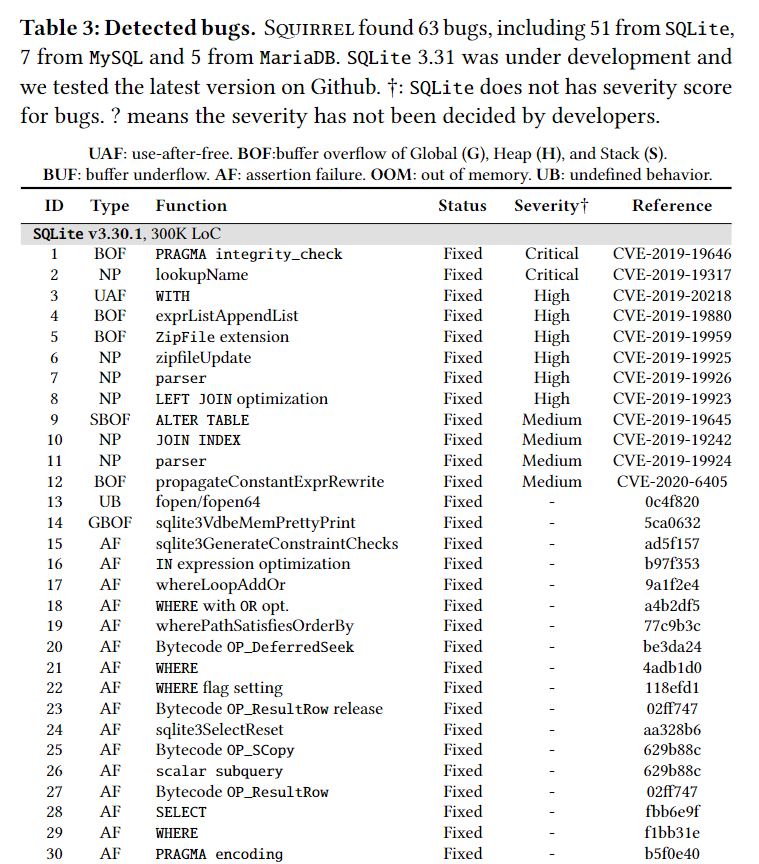
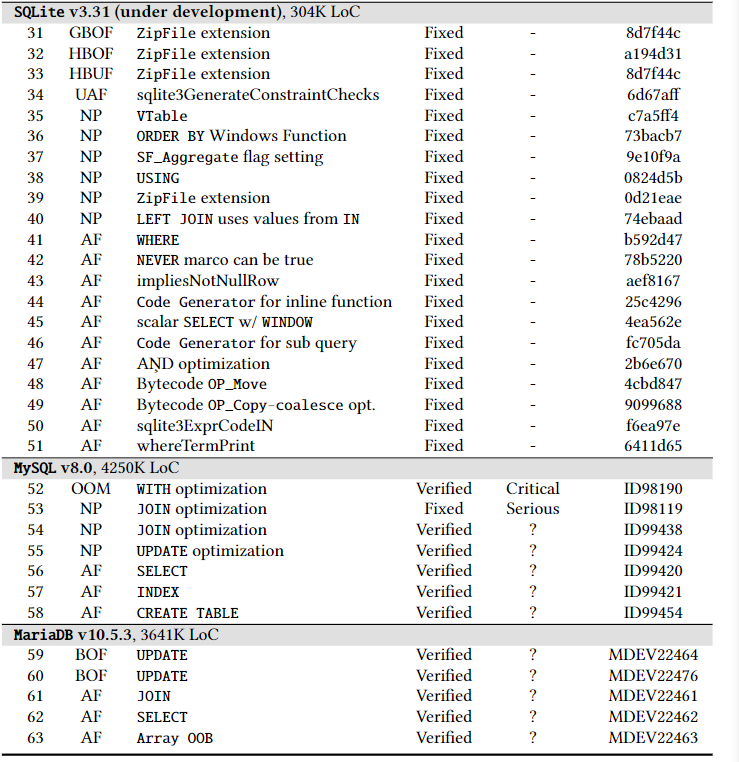
共检查到了多少个bugs,列表介绍了是否fixed,具体位于哪个function,严重程度,CVE编号或者fixed git commit hash值。
与google的OSS-Fuzzer进行对比。bug的不同种类,如memory errors,assertion failures(因为release版本去除了assertion,所以会带来更大安全隐患)
case study4个,每个都介绍对应ID,为止,产生原因,造成后果,发现的时间,发现的query,在query上再说一遍产生原因
8.2 Comparison with Existing Tools
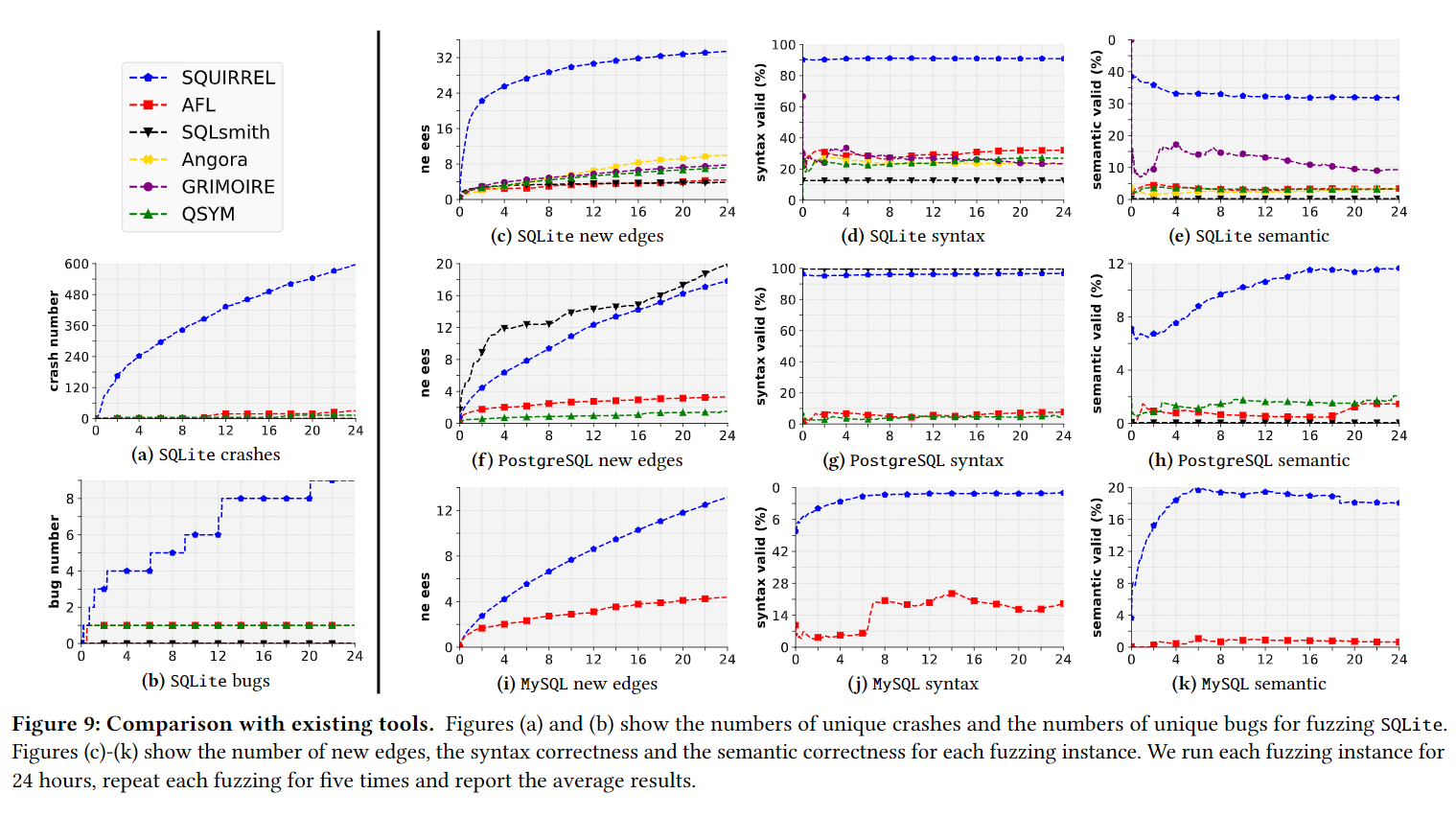
先做同意介绍,介绍Fig9中有哪些信息,pvalue在附录,大多数pvalue<0.05及含义,
Unqiue Crashes
介绍对应Fig9(a)。分析时间趋势(包括竞品),发现现象: recent tools do not significantly outperform AFL和原因。
Unique Bugs
注意这里和Unique Crashes分开了。并说明了Squirrel的600次crashes都只和两个bugs相关等类似的,Since the small number of bugs is not statistically useful,会把现有crash与已有的bugs联系起来,成为9(b)图像的结果,用这个策略所以bugs也最高。Table4显示了detected bugs类别覆盖到的比较多。

New Edges
多识别的new edges倍数2.0-10.9x,achieves a comparable result to SQLsmith.
分别介绍Fig 9 c)f)i)的内容。比每个竞品多鉴定到的倍数,唯一比其更少的是SQLsmith+原因
Syntax Validity
syntax-correctness种子倍数2.0-10.9x,achieves a comparable result to SQLsmith.
分别介绍Fig 9 c)f)i)的内容。比每个竞品多鉴定到的倍数,唯一例外是SQLsmith...
Semantic Validity
同上,现象:AFL实际上发现了更多correct inputs,但是并没有获得更多edge coverage,这说明大量correct queries并不意味着高覆盖度。
8.3 Contributions of Validity and Feedback
目的:为了理解factors,尤其是XX方面的
实验设计: we perform unit tests by disabling ..
为每个更改了参数(disable某功能)的结果给了一个代号比如Squirrel_!feedback+
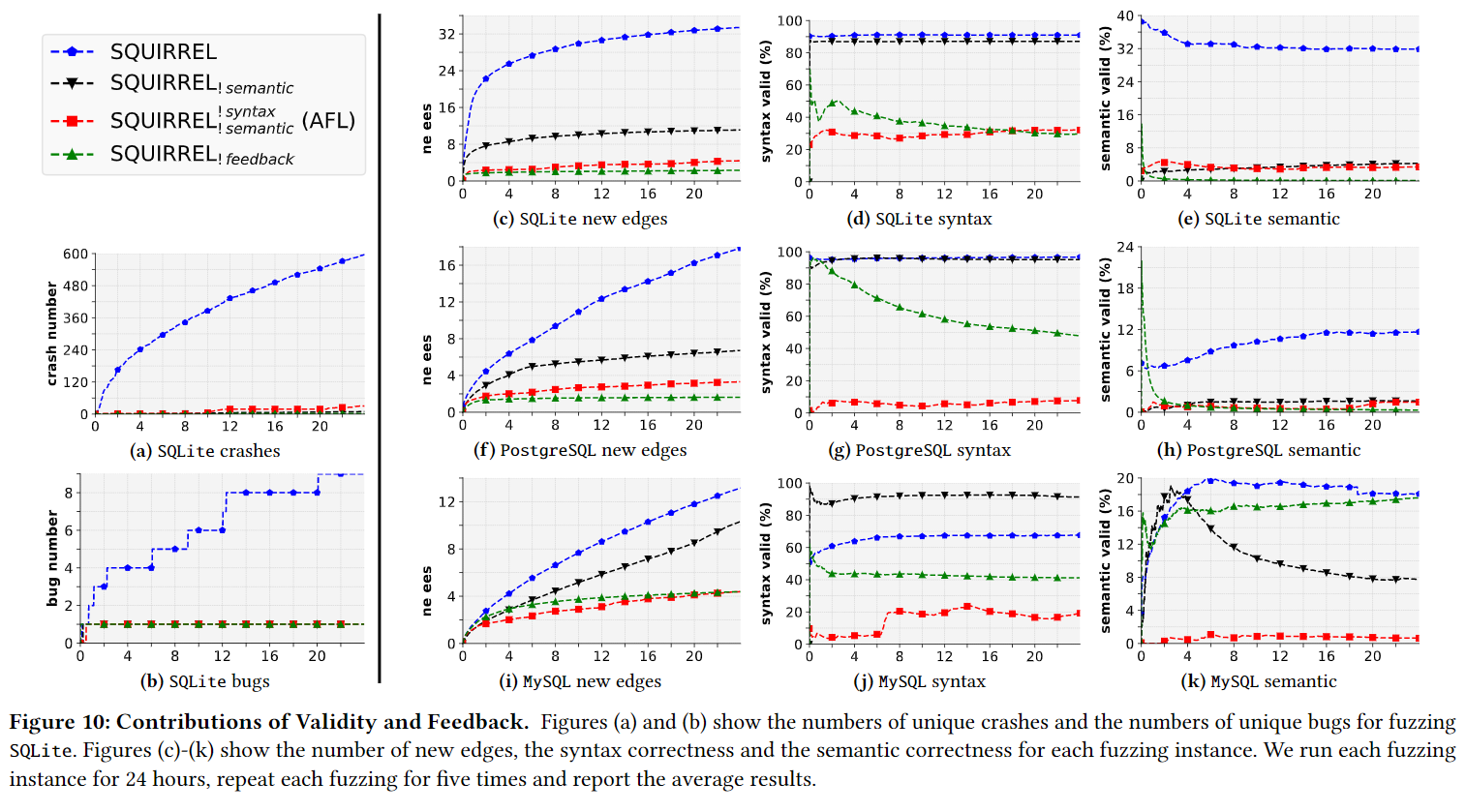
Unqiue Crashes
同上,上面的结果标明,XXfactors对崩溃检测起到关键作用
Unique Bugs
同上
New Edges
同上,说明了Fig10 c,f,i
Syntax Validity & Semantic Validity
在大多数情况下都是Squirrel更优,为什么,但是,异常,提高语义正确性不会提升语法正确性,例如Fig.10 j移除的short queries实际上语法一般都更优,语义正确性差异大+原因,但是查询结构更加多样化+原因(发现了更多具有相似语义正确性的执行路径)
9 Discussion
DBMS-Specific Logic
结合程序特有的功能测试往往能更好。尽管所有DBMS都应该实现SQL方言,但有些DBMS,比如PostgreSQL与标准SQL的区别较大,这也导致Squirrel效果不是特别好。此外,PostgreSQL还要求额外的type correctness,不允许浮点数和整数比较。
Relation-Rule Construction
将来可能可以通过数据流或者机器学习来从正常执行中自动捕捉data type relationship
Collisions in Code-Coverage
AFL的默认插桩方式存在collsion问题,本文将默认的64K entries改为了256k,不过下一步打算改到CollAFL上来彻底解决这个问题
Alternative Feedback Mechanism
本文发现,聚焦于code coverage可能反而影响语料的进一步生成。尤其是,一开始grammar-incorrect queires会发现新的程序path,那么squirrel就会聚焦在这些inputs上面,导致影响之后的进一步mutate-fuzzing。我们可能会考虑删掉只引起特别短暂的执行的输入(dropping inputs that trigger new branches in short execution)。
10 Related Work
Detecting Logic and Performance Bugs in DBMSs
RAGS-不同DBMSs之间差分测试, SQLancer-逻辑bugs,必然包含的row,空集补集, QTune-深度reinforcement learning用来学习最佳配置, Apollo不同版本之间差分测试, BmPad运行实现定义好的testsuites以发现超时问题。
Generation-based DBMS Testing
QAGen显示perfectly resuring semantic correctness是NP hard的。
一些工作用SAT solver来生成SQL
Bikash等提出了一种新方法来产生能够覆盖大多数SQL种类的initial databases
SQLsmith从initial databases来获取schemas,生成limited tyopes of queries,确保database本身不会改动。
Mutation-based DBMS Testing
taint analysis, symbolic execution
Tim blazytko等人提出了一种方式来生成highly structured inputs,不过还是难以通过语义检查。Hardik bati等人提出了通过添加/移除grammar components的方式来mutate SQL。