当我们在写MapReduce程序的时候,通常,在main函数里,我们会像下面这样做。建立一个Job对象,设置它的JobName,然后配置输入输出路径,设置我们的Mapper类和Reducer类,设置InputFormat和正确的输出类型等等。然后我们会使用job.waitForCompletion()提交到JobTracker,等待job运行并返回,这就是一般的Job设置过程。JobTracker会初始化这个Job,获取输入分片,然后将一个一个的task任务分配给TaskTrackers执行。TaskTracker获取task是通过心跳的返回值得到的,然后TaskTracker就会为收到的task启动一个JVM来运行。
- Configuration conf = getConf();
- Job job = new Job(conf, "SelectGradeDriver");
- job.setJarByClass(SelectGradeDriver.class);
- Path in = new Path(args[0]);
- Path out = new Path(args[1]);
- FileInputFormat.setInputPaths(job, in);
- FileOutputFormat.setOutputPath(job, out);
- job.setMapperClass(SelectGradeMapper.class);
- job.setReducerClass(SelectGradeReducer.class);
- job.setInputFormatClass(TextInputFormat.class);
- job.setOutputFormatClass(TextOutputFormat.class);
- job.setMapOutputKeyClass(InstituteAndGradeWritable.class);
- job.setMapOutputValueClass(Text.class);
- job.setOutputKeyClass(InstituteAndGradeWritable.class);
- job.setOutputValueClass(Text.class);
- System.exit(job.waitForCompletion(true)? 0 : 1);
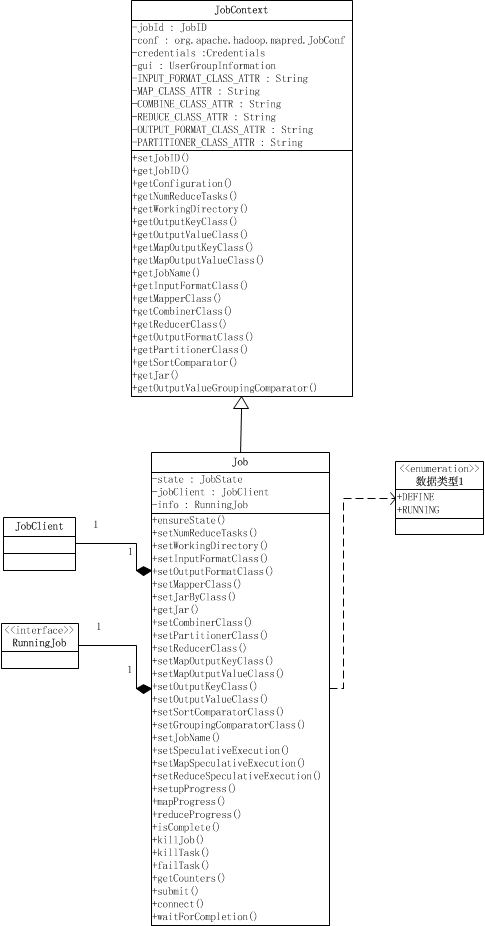
Job其实就是提供配置作业、获取作业配置、以及提交作业的功能,以及跟踪作业进度和控制作业。Job类继承于JobContext类。JobContext提供了获取作业配置的功能,如作业ID,作业的Mapper类,Reducer类,输入格式,输出格式等等,它们除了作业ID之外,都是只读的。 Job类在JobContext的基础上,提供了设置作业配置信息的功能、跟踪进度,以及提交作业的接口和控制作业的方法。
- public class Job extends JobContext {
- public static enum JobState {DEFINE, RUNNING};
- private JobState state = JobState.DEFINE;
- private JobClient jobClient;
- private RunningJob info;
- public float setupProgress() throws IOException {
- ensureState(JobState.RUNNING);
- return info.setupProgress();
- }
- public float mapProgress() throws IOException {
- ensureState(JobState.RUNNING);
- return info.mapProgress();
- }
- public float reduceProgress() throws IOException {
- ensureState(JobState.RUNNING);
- return info.reduceProgress();
- }
- public boolean isComplete() throws IOException {
- ensureState(JobState.RUNNING);
- return info.isComplete();
- }
- public boolean isSuccessful() throws IOException {
- ensureState(JobState.RUNNING);
- return info.isSuccessful();
- }
- public void killJob() throws IOException {
- ensureState(JobState.RUNNING);
- info.killJob();
- }
- public TaskCompletionEvent[] getTaskCompletionEvents(int startFrom
- ) throws IOException {
- ensureState(JobState.RUNNING);
- return info.getTaskCompletionEvents(startFrom);
- }
- public void killTask(TaskAttemptID taskId) throws IOException {
- ensureState(JobState.RUNNING);
- info.killTask(org.apache.hadoop.mapred.TaskAttemptID.downgrade(taskId),
- false);
- }
- public void failTask(TaskAttemptID taskId) throws IOException {
- ensureState(JobState.RUNNING);
- info.killTask(org.apache.hadoop.mapred.TaskAttemptID.downgrade(taskId),
- true);
- }
- public Counters getCounters() throws IOException {
- ensureState(JobState.RUNNING);
- return new Counters(info.getCounters());
- }
- public void submit() throws IOException, InterruptedException,
- ClassNotFoundException {
- ensureState(JobState.DEFINE);
- setUseNewAPI();
- // Connect to the JobTracker and submit the job
- connect();
- info = jobClient.submitJobInternal(conf);
- super.setJobID(info.getID());
- state = JobState.RUNNING;
- }
- private void connect() throws IOException, InterruptedException {
- ugi.doAs(new PrivilegedExceptionAction<Object>() {
- public Object run() throws IOException {
- jobClient = new JobClient((JobConf) getConfiguration());
- return null;
- }
- });
- }
- public boolean waitForCompletion(boolean verbose
- ) throws IOException, InterruptedException,
- ClassNotFoundException {
- if (state == JobState.DEFINE) {
- submit();
- }
- if (verbose) {
- jobClient.monitorAndPrintJob(conf, info);
- } else {
- info.waitForCompletion();
- }
- return isSuccessful();
- }
- //lots of setters and others
- }
一个Job对象有两种状态,DEFINE和RUNNING,Job对象被创建时的状态时DEFINE,当且仅当Job对象处于DEFINE状态,才可以用来设置作业的一些配置,如Reduce task的数量、InputFormat类、工作的Mapper类,Partitioner类等等,这些设置是通过设置配置信息conf来实现的;当作业通过submit()被提交,就会将这个Job对象的状态设置为RUNNING,这时候作业以及提交了,就不能再设置上面那些参数了,作业处于调度运行阶段。处于RUNNING状态的作业我们可以获取作业、map task和reduce task的进度,通过代码中的*Progress()获得,这些函数是通过info来获取的,info是RunningJob对象,它是实际在运行的作业的一组获取作业情况的接口,如Progress。
在waitForCompletion()中,首先用submit()提交作业,然后等待info.waitForCompletion()返回作业执行完毕。verbose参数用来决定是否将运行进度等信息输出给用户。submit()首先会检查是否正确使用了new API,这通过setUseNewAPI()检查旧版本的属性是否被设置来实现的,接着就connect()连接JobTracker并提交。实际提交作业的是一个JobClient对象,提交作业后返回一个RunningJob对象,这个对象可以跟踪作业的进度以及含有由JobTracker设置的作业ID。
getCounter()函数是用来返回这个作业的计数器列表的,计数器被用来收集作业的统计信息,比如失败的map task数量,reduce输出的记录数等等。它包括内置计数器和用户定义的计数器,用户自定义的计数器可以用来收集用户需要的特定信息。计数器首先被每个task定期传输到TaskTracker,最后TaskTracker再传到JobTracker收集起来。这就意味着,计数器是全局的。
转自: