平时我们写MapReduce程序的时候,在设置输入格式的时候,总会调用形如job.setInputFormatClass(KeyValueTextInputFormat.class);来保证输入文件按照我们想要的格式被读取。所有的输入格式都继承于InputFormat,这是一个抽象类,其子类有专门用于读取普通文件的FileInputFormat,用来读取数据库的DBInputFormat等等。
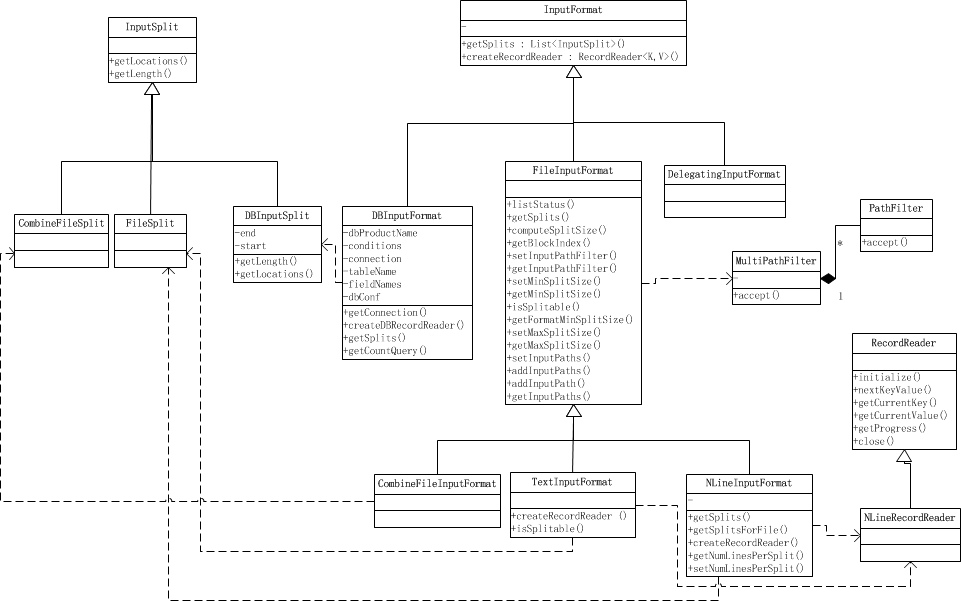
不同的InputFormat都会按自己的实现来读取输入数据并产生输入分片,一个输入分片会被单独的map task作为数据源。下面我们先看看这些输入分片(inputSplit)是什么样的。
InputSplit:
我们知道Mappers的输入是一个一个的输入分片,称InputSplit。InputSplit是一个抽象类,它在逻辑上包含了提供给处理这个InputSplit的Mapper的所有K-V对。
- public abstract class InputSplit {
- public abstract long getLength() throws IOException, InterruptedException;
- public abstract
- String[] getLocations() throws IOException, InterruptedException;
- }
getLength()用来获取InputSplit的大小,以支持对InputSplits进行排序,而getLocations()则用来获取存储分片的位置列表。
我们来看一个简单InputSplit子类:FileSplit。
- public class FileSplit extends InputSplit implements Writable {
- private Path file;
- private long start;
- private long length;
- private String[] hosts;
- FileSplit() {}
- public FileSplit(Path file, long start, long length, String[] hosts) {
- this.file = file;
- this.start = start;
- this.length = length;
- this.hosts = hosts;
- }
- //序列化、反序列化方法,获得hosts等等……
- }
从上面的源码我们可以看到,一个FileSplit是由文件路径,分片开始位置,分片大小和存储分片数据的hosts列表组成,由这些信息我们就可以从输入文件中切分出提供给单个Mapper的输入数据。这些属性会在Constructor设置,我们在后面会看到这会在InputFormat的getSplits()中构造这些分片。
我们再看CombineFileSplit:
- public class CombineFileSplit extends InputSplit implements Writable {
- private Path[] paths;
- private long[] startoffset;
- private long[] lengths;
- private String[] locations;
- private long totLength;
- public CombineFileSplit() {}
- public CombineFileSplit(Path[] files, long[] start,
- long[] lengths, String[] locations) {
- initSplit(files, start, lengths, locations);
- }
- public CombineFileSplit(Path[] files, long[] lengths) {
- long[] startoffset = new long[files.length];
- for (int i = 0; i < startoffset.length; i++) {
- startoffset[i] = 0;
- }
- String[] locations = new String[files.length];
- for (int i = 0; i < locations.length; i++) {
- locations[i] = "";
- }
- initSplit(files, startoffset, lengths, locations);
- }
- private void initSplit(Path[] files, long[] start,
- long[] lengths, String[] locations) {
- this.startoffset = start;
- this.lengths = lengths;
- this.paths = files;
- this.totLength = 0;
- this.locations = locations;
- for(long length : lengths) {
- totLength += length;
- }
- }
- //一些getter和setter方法,和序列化方法
- }
与FileSplit类似,CombineFileSplit同样包含文件路径,分片起始位置,分片大小和存储分片数据的host列表,由于CombineFileSplit是针对小文件的,它把很多小文件包在一个InputSplit内,这样一个Mapper就可以处理很多小文件。要知道我们上面的FileSplit是对应一个输入文件的,也就是说如果用FileSplit对应的FileInputFormat来作为输入格式,那么即使文件特别小,也是单独计算成一个输入分片来处理的。当我们的输入是由大量小文件组成的,就会导致有同样大量的InputSplit,从而需要同样大量的Mapper来处理,这将很慢,想想有一堆map task要运行!!这是不符合Hadoop的设计理念的,Hadoop是为处理大文件优化的。
最后介绍TagInputSplit,这个类就是封装了一个InputSplit,然后加了一些tags在里面满足我们需要这些tags数据的情况,我们从下面就可以一目了然。
- class TaggedInputSplit extends InputSplit implements Configurable, Writable {
- private Class<? extends InputSplit> inputSplitClass;
- private InputSplit inputSplit;
- @SuppressWarnings("unchecked")
- private Class<? extends InputFormat> inputFormatClass;
- @SuppressWarnings("unchecked")
- private Class<? extends Mapper> mapperClass;
- private Configuration conf;
- //getters and setters,序列化方法,getLocations()、getLength()等
- }
现在我们对InputSplit的概念有了一些了解,我们继续看它是怎么被使用和计算出来的。
InputFormat:
通过使用InputFormat,MapReduce框架可以做到:
1、验证作业的输入的正确性
2、将输入文件切分成逻辑的InputSplits,一个InputSplit将被分配给一个单独的Mapper task
3、提供RecordReader的实现,这个RecordReader会从InputSplit中正确读出一条一条的K-V对供Mapper使用。
- public abstract class InputFormat<K, V> {
- public abstract
- List<InputSplit> getSplits(JobContext context
- ) throws IOException, InterruptedException;
- public abstract
- RecordReader<K,V> createRecordReader(InputSplit split,
- TaskAttemptContext context
- ) throws IOException,
- InterruptedException;
- }
上面是InputFormat的源码,getSplits用来获取由输入文件计算出来的InputSplits,我们在后面会看到计算InputSplits的时候会考虑到输入文件是否可分割、文件存储时分块的大小和文件大小等因素;而createRecordReader()提供了前面第三点所说的RecordReader的实现,以将K-V对从InputSplit中正确读出来,比如LineRecordReader就以偏移值为key,一行的数据为value,这就使得所有其createRecordReader()返回了LineRecordReader的InputFormat都是以偏移值为key,一行数据为value的形式读取输入分片的。
FileInputFormat:
PathFilter被用来进行文件筛选,这样我们就可以控制哪些文件要作为输入,哪些不作为输入。PathFilter有一个accept(Path)方法,当接收的Path要被包含进来,就返回true,否则返回false。可以通过设置mapred.input.pathFilter.class来设置用户自定义的PathFilter。
- public interface PathFilter {
- boolean accept(Path path);
- }
FileInputFormat是InputFormat的子类,它包含了一个MultiPathFilter,这个MultiPathFilter由一个过滤隐藏文件(名字前缀为'-'或'.')的PathFilter和一些可能存在的用户自定义的PathFilters组成,MultiPathFilter会在listStatus()方法中使用,而listStatus()方法又被getSplits()方法用来获取输入文件,也就是说实现了在获取输入分片前先进行文件过滤。
- private static class MultiPathFilter implements PathFilter {
- private List<PathFilter> filters;
- public MultiPathFilter(List<PathFilter> filters) {
- this.filters = filters;
- }
- public boolean accept(Path path) {
- for (PathFilter filter : filters) {
- if (!filter.accept(path)) {
- return false;
- }
- }
- return true;
- }
- }
这些PathFilter会在listStatus()方法中用到,listStatus()是用来获取输入数据列表的。
下面是FileInputFormat的getSplits()方法,它首先得到分片的最小值minSize和最大值maxSize,它们会被用来计算分片大小。可以通过设置mapred.min.split.size和mapred.max.split.size来设置。splits链表用来存储计算得到的输入分片,files则存储作为由listStatus()获取的输入文件列表。然后对于每个输入文件,判断是否可以分割,通过computeSplitSize计算出分片大小splitSize,计算方法是:Math.max(minSize, Math.min(maxSize, blockSize));也就是保证在minSize和maxSize之间,且如果minSize<=blockSize<=maxSize,则设为blockSize。然后我们根据这个splitSize计算出每个文件的inputSplits集合,然后加入分片列表splits中。注意到我们生成InputSplit的时候按上面说的使用文件路径,分片起始位置,分片大小和存放这个文件的hosts列表来创建。最后我们还设置了输入文件数量:mapreduce.input.num.files。
- public List<InputSplit> getSplits(JobContext job
- ) throws IOException {
- long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
- long maxSize = getMaxSplitSize(job);
- // generate splits
- List<InputSplit> splits = new ArrayList<InputSplit>();
- List<FileStatus>files = listStatus(job);
- for (FileStatus file: files) {
- Path path = file.getPath();
- FileSystem fs = path.getFileSystem(job.getConfiguration());
- long length = file.getLen();
- BlockLocation[] blkLocations = fs.getFileBlockLocations(file, 0, length);
- if ((length != 0) && isSplitable(job, path)) {
- long blockSize = file.getBlockSize();
- long splitSize = computeSplitSize(blockSize, minSize, maxSize);
- long bytesRemaining = length;
- while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
- int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
- splits.add(new FileSplit(path, length-bytesRemaining, splitSize,
- blkLocations[blkIndex].getHosts()));
- bytesRemaining -= splitSize;
- }
- if (bytesRemaining != 0) {
- splits.add(new FileSplit(path, length-bytesRemaining, bytesRemaining,
- blkLocations[blkLocations.length-1].getHosts()));
- }
- } else if (length != 0) {
- splits.add(new FileSplit(path, 0, length, blkLocations[0].getHosts()));
- } else {
- //Create empty hosts array for zero length files
- splits.add(new FileSplit(path, 0, length, new String[0]));
- }
- }
- // Save the number of input files in the job-conf
- job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
- LOG.debug("Total # of splits: " + splits.size());
- return splits;
- }
- //……setters and getters
就这样,利用FileInputFormat 的getSplits方法,我们就计算出了我们的作业的所有输入分片了。
那这些计算出来的分片是怎么被map读取出来的呢?就是InputFormat中的另一个方法createRecordReader(),FileInputFormat并没有对这个方法做具体的要求,而是交给子类自行去实现它。
RecordReader:
RecordReader是用来从一个输入分片中读取一个一个的K -V 对的抽象类,我们可以将其看作是在InputSplit上的迭代器。我们从类图中可以看到它的一些方法,最主要的方法就是nextKeyvalue()方法,由它获取分片上的下一个K-V 对。
我们再深入看看上面提到的RecordReader的一个子类:LineRecordReader。
LineRecordReader由一个FileSplit构造出来,start是这个FileSplit的起始位置,pos是当前读取分片的位置,end是分片结束位置,in是打开的一个读取这个分片的输入流,它是使用这个FileSplit对应的文件名来打开的。key和value则分别是每次读取的K-V对。然后我们还看到可以利用getProgress()来跟踪读取分片的进度,这个函数就是根据已经读取的K-V对占总K-V对的比例来显示进度的。
- public class LineRecordReader extends RecordReader<LongWritable, Text> {
- private static final Log LOG = LogFactory.getLog(LineRecordReader.class);
- private CompressionCodecFactory compressionCodecs = null;
- private long start;
- private long pos;
- private long end;
- private LineReader in;
- private int maxLineLength;
- private LongWritable key = null;
- private Text value = null;
- //我们知道LineRecordReader是读取一个InputSplit的,它从InputSplit中不断以其定义的格式读取K-V对
- //initialize函数主要是计算分片的始末位置,以及打开想要的输入流以供读取K-V对,输入流另外处理分片经过压缩的情况
- public void initialize(InputSplit genericSplit,
- TaskAttemptContext context) throws IOException {
- FileSplit split = (FileSplit) genericSplit;
- Configuration job = context.getConfiguration();
- this.maxLineLength = job.getInt("mapred.linerecordreader.maxlength",
- Integer.MAX_VALUE);
- start = split.getStart();
- end = start + split.getLength();
- final Path file = split.getPath();
- compressionCodecs = new CompressionCodecFactory(job);
- final CompressionCodec codec = compressionCodecs.getCodec(file);
- // open the file and seek to the start of the split
- FileSystem fs = file.getFileSystem(job);
- FSDataInputStream fileIn = fs.open(split.getPath());
- boolean skipFirstLine = false;
- if (codec != null) {
- in = new LineReader(codec.createInputStream(fileIn), job);
- end = Long.MAX_VALUE;
- } else {
- if (start != 0) {
- skipFirstLine = true;
- --start;
- fileIn.seek(start);
- }
- in = new LineReader(fileIn, job);
- }
- if (skipFirstLine) { // skip first line and re-establish "start".
- start += in.readLine(new Text(), 0,
- (int)Math.min((long)Integer.MAX_VALUE, end - start));
- }
- this.pos = start;
- }
- public boolean nextKeyValue() throws IOException {
- if (key == null) {
- key = new LongWritable();
- }
- key.set(pos); //对于LineRecordReader来说,它以偏移值为key,以一行为value
- if (value == null) {
- value = new Text();
- }
- int newSize = 0;
- while (pos < end) {
- newSize = in.readLine(value, maxLineLength,
- Math.max((int)Math.min(Integer.MAX_VALUE, end-pos),
- maxLineLength));
- if (newSize == 0) {
- break;
- }
- pos += newSize;
- if (newSize < maxLineLength) {
- break;
- }
- // line too long. try again
- LOG.info("Skipped line of size " + newSize + " at pos " +
- (pos - newSize));
- }
- if (newSize == 0) {
- key = null;
- value = null;
- return false;
- } else {
- return true;
- }
- }
- @Override
- public LongWritable getCurrentKey() {
- return key;
- }
- @Override
- public Text getCurrentValue() {
- return value;
- }
- /**
- * Get the progress within the split
- */
- public float getProgress() {
- if (start == end) {
- return 0.0f;
- } else {
- return Math.min(1.0f, (pos - start) / (float)(end - start));//读取进度由已读取InputSplit大小比总InputSplit大小
- }
- }
- public synchronized void close() throws IOException {
- if (in != null) {
- in.close();
- }
- }
- }
其它的一些RecordReader如SequenceFileRecordReader,CombineFileRecordReader.java等则对应不同的InputFormat。
下面继续看看这些RecordReader是如何被MapReduce框架使用的。
我们先看看Mapper.class是什么样的:
- public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
- public class Context
- extends MapContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
- public Context(Configuration conf, TaskAttemptID taskid,
- RecordReader<KEYIN,VALUEIN> reader,
- RecordWriter<KEYOUT,VALUEOUT> writer,
- OutputCommitter committer,
- StatusReporter reporter,
- InputSplit split) throws IOException, InterruptedException {
- super(conf, taskid, reader, writer, committer, reporter, split);
- }
- }
- /**
- * Called once at the beginning of the task.
- */
- protected void setup(Context context
- ) throws IOException, InterruptedException {
- // NOTHING
- }
- /**
- * Called once for each key/value pair in the input split. Most applications
- * should override this, but the default is the identity function.
- */
- @SuppressWarnings("unchecked")
- protected void map(KEYIN key, VALUEIN value,
- Context context) throws IOException, InterruptedException {
- context.write((KEYOUT) key, (VALUEOUT) value);
- }
- /**
- * Called once at the end of the task.
- */
- protected void cleanup(Context context
- ) throws IOException, InterruptedException {
- // NOTHING
- }
- /**
- * Expert users can override this method for more complete control over the
- * execution of the Mapper.
- * @param context
- * @throws IOException
- */
- public void run(Context context) throws IOException, InterruptedException {
- setup(context);
- while (context.nextKeyValue()) {
- map(context.getCurrentKey(), context.getCurrentValue(), context);
- }
- cleanup(context);
- }
我们写MapReduce程序的时候,我们写的mapper都要继承这个Mapper.class,通常我们会重写map()方法,map()每次接受一个K-V对,然后我们对这个K-V对进行处理,再分发出处理后的数据。我们也可能重写setup()以对这个map task进行一些预处理,比如创建一个List之类的;我们也可能重写cleanup()方法对做一些处理后的工作,当然我们也可能在cleanup()中写出K-V对。举个例子就是:InputSplit的数据是一些整数,然后我们要在mapper中算出它们的和。我们就可以在先设置个sum属性,然后map()函数处理一个K-V对就是将其加到sum上,最后在cleanup()函数中调用context.write(key,value);
最后我们看看Mapper.class中的run()方法,它相当于map task的驱动,我们可以看到run()方法首先调用setup()进行初始操作,然后对每个context.nextKeyValue()获取的K-V对,就调用map()函数进行处理,最后调用cleanup()做最后的处理。事实上,从text他.nextKeyValue()就是使用了相应的RecordReader来获取K-V对的。
我们看看Mapper.class中的Context类,它继承与MapContext,使用了一个RecordReader进行构造。下面我们再看这个MapContext。
- public class MapContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT>
- extends TaskInputOutputContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
- private RecordReader<KEYIN,VALUEIN> reader;
- private InputSplit split;
- public MapContext(Configuration conf, TaskAttemptID taskid,
- RecordReader<KEYIN,VALUEIN> reader,
- RecordWriter<KEYOUT,VALUEOUT> writer,
- OutputCommitter committer,
- StatusReporter reporter,
- InputSplit split) {
- super(conf, taskid, writer, committer, reporter);
- this.reader = reader;
- this.split = split;
- }
- /**
- * Get the input split for this map.
- */
- public InputSplit getInputSplit() {
- return split;
- }
- @Override
- public KEYIN getCurrentKey() throws IOException, InterruptedException {
- return reader.getCurrentKey();
- }
- @Override
- public VALUEIN getCurrentValue() throws IOException, InterruptedException {
- return reader.getCurrentValue();
- }
- @Override
- public boolean nextKeyValue() throws IOException, InterruptedException {
- return reader.nextKeyValue();
- }
- }
我们可以看到MapContext直接是使用传入的RecordReader来进行K-V对的读取了。
到现在,我们已经知道输入文件是如何被读取、过滤、分片、读出K-V对,然后交给我们的Mapper类来处理的了。
最后,我们来看看FileInputFormat的几个子类。
TextInputFormat:
TextInputFormat是FileInputFormat的子类,其createRecordReader()方法返回的就是LineRecordReader。
- public class TextInputFormat extends FileInputFormat<LongWritable, Text> {
- @Override
- public RecordReader<LongWritable, Text>
- createRecordReader(InputSplit split,
- TaskAttemptContext context) {
- return new LineRecordReader();
- }
- @Override
- protected boolean isSplitable(JobContext context, Path file) {
- CompressionCodec codec =
- new CompressionCodecFactory(context.getConfiguration()).getCodec(file);
- return codec == null;
- }
- }
我们还看到isSplitable()方法,当文件使用压缩的形式,这个文件就不可分割,否则就读取不到正确的数据了。这从某种程度上将影响分片的计算。有时我们希望一个文件只被一个Mapper处理的时候,我们就可以重写isSplitable()方法,告诉MapReduce框架,我哪些文件可以分割,哪些文件不能分割而只能作为一个分片。
NLineInputFormat;
- public class NLineInputFormat extends FileInputFormat<LongWritable, Text> {
- public static final String LINES_PER_MAP =
- "mapreduce.input.lineinputformat.linespermap";
- public RecordReader<LongWritable, Text> createRecordReader(
- InputSplit genericSplit, TaskAttemptContext context)
- throws IOException {
- context.setStatus(genericSplit.toString());
- return new LineRecordReader();
- }
- /**
- * Logically splits the set of input files for the job, splits N lines
- * of the input as one split.
- *
- * @see FileInputFormat#getSplits(JobContext)
- */
- public List<InputSplit> getSplits(JobContext job)
- throws IOException {
- List<InputSplit> splits = new ArrayList<InputSplit>();
- int numLinesPerSplit = getNumLinesPerSplit(job);
- for (FileStatus status : listStatus(job)) {
- splits.addAll(getSplitsForFile(status,
- job.getConfiguration(), numLinesPerSplit));
- }
- return splits;
- }
- public static List<FileSplit> getSplitsForFile(FileStatus status,
- Configuration conf, int numLinesPerSplit) throws IOException {
- List<FileSplit> splits = new ArrayList<FileSplit> ();
- Path fileName = status.getPath();
- if (status.isDir()) {
- throw new IOException("Not a file: " + fileName);
- }
- FileSystem fs = fileName.getFileSystem(conf);
- LineReader lr = null;
- try {
- FSDataInputStream in = fs.open(fileName);
- lr = new LineReader(in, conf);
- Text line = new Text();
- int numLines = 0;
- long begin = 0;
- long length = 0;
- int num = -1;
- while ((num = lr.readLine(line)) > 0) {
- numLines++;
- length += num;
- if (numLines == numLinesPerSplit) {
- // NLineInputFormat uses LineRecordReader, which always reads
- // (and consumes) at least one character out of its upper split
- // boundary. So to make sure that each mapper gets N lines, we
- // move back the upper split limits of each split
- // by one character here.
- if (begin == 0) {
- splits.add(new FileSplit(fileName, begin, length - 1,
- new String[] {}));
- } else {
- splits.add(new FileSplit(fileName, begin - 1, length,
- new String[] {}));
- }
- begin += length;
- length = 0;
- numLines = 0;
- }
- }
- if (numLines != 0) {
- splits.add(new FileSplit(fileName, begin, length, new String[]{}));
- }
- } finally {
- if (lr != null) {
- lr.close();
- }
- }
- return splits;
- }
- /**
- * Set the number of lines per split
- * @param job the job to modify
- * @param numLines the number of lines per split
- */
- public static void setNumLinesPerSplit(Job job, int numLines) {
- job.getConfiguration().setInt(LINES_PER_MAP, numLines);
- }
- /**
- * Get the number of lines per split
- * @param job the job
- * @return the number of lines per split
- */
- public static int getNumLinesPerSplit(JobContext job) {
- return job.getConfiguration().getInt(LINES_PER_MAP, 1);
- }