在GPU加速计算中,矩阵乘法是绕不开的话题,所以笔者就从简单的方阵乘法入手,进行cuda的入门学习
所以就写了一个简单cuda 方阵乘法的内核。
矩阵乘法的原理,我就不在这里赘述了,学过线性代数,都应该比较清楚。直接就上代码:


1 #include "cuda_runtime.h" 2 #include "device_launch_parameters.h" 3 4 #include <stdio.h> 5 #include <iostream> 6 #include<time.h> 7 8 typedef float DataType; 9 10 #define WIDTH 32 11 #define Matrix_h 2 12 #define Matrix_w 2 13 14 #define Arr_Size(arr) (sizeof(arr)/sizeof(arr[0][0])) 15 16 __global__ void MatrixMulKernel(DataType *M, DataType *N, DataType *P, int width) { 17 //calcualte the row index of the P element and M 18 int row = blockIdx.x*blockDim.x + threadIdx.x; 19 //calcualte the col index of the P element and N 20 int col = blockIdx.y*blockDim.y + threadIdx.y; 21 22 if (row < width && col < width) { 23 float pvalue = 0; 24 //each thread computes one element of the block sub-matrix 25 for (int k = 0; k < width; ++k) { 26 pvalue += M[row*width + k] * N[k*width + col]; 27 } 28 P[row*width + col] = pvalue; 29 } 30 } 31 32 void MatrixMulCPU(DataType M[][Matrix_h], DataType N[][Matrix_h], DataType P[][Matrix_h], int width) { 33 34 for (int i = 0; i < width; ++i) { 35 for (int j = 0; j < width; ++j) { 36 DataType pvalue = 0; 37 for (int k = 0; k < width; ++k) { 38 pvalue += M[i][k] * N[k][j]; 39 } 40 P[i][j] = pvalue; 41 } 42 43 } 44 } 45 46 47 int main(void) { 48 49 DataType A[Matrix_w][Matrix_h]={ 50 {1,2}, 51 {3,4} 52 }; 53 54 DataType B[Matrix_w][Matrix_h] = { 55 {5,6}, 56 {7,8} 57 58 }; 59 DataType C[Matrix_w][Matrix_h] = { 0 }; 60 61 DataType*d_A, *d_B, *d_C; 62 63 64 cudaMalloc((void**)&d_A, sizeof(DataType)*Arr_Size(A)); 65 cudaMalloc((void**)&d_B, sizeof(DataType)*Arr_Size(B)); 66 cudaMalloc((void**)&d_C, sizeof(DataType)*Arr_Size(C)); 67 cudaMemcpy(d_A, A, sizeof(DataType)*Arr_Size(A), cudaMemcpyHostToDevice); 68 cudaMemcpy(d_B, B, sizeof(DataType)*Arr_Size(B), cudaMemcpyHostToDevice); 69 70 dim3 Block(WIDTH, WIDTH, 1); 71 dim3 Grid((Matrix_w - 1) / WIDTH + 1, (Matrix_h - 1) / WIDTH + 1, 1); 72 73 clock_t time_start, time_end; 74 time_start = clock(); 75 MatrixMulKernel << <Grid, Block >> > (d_A, d_B, d_C, Matrix_w); 76 cudaThreadSynchronize(); 77 time_end = clock(); 78 cudaMemcpy(C, d_C, sizeof(DataType)*Arr_Size(C), cudaMemcpyDeviceToHost); 79 std::cout << "GPU time=" << (double)(time_end - time_start) / CLOCKS_PER_SEC * 1000 << "ms" << std::endl; 80 std::cout << "GPU_result:" << std::endl; 81 for (int i = 0; i < Matrix_w; ++i) { 82 for (int j = 0; j < Matrix_h; ++j) { 83 printf("C[%d][%d]=%f ", i, j, C[i][j]); 84 } 85 printf(" "); 86 } 87 88 time_start = clock(); 89 MatrixMulCPU(A, B, C, Matrix_w); 90 time_end = clock(); 91 92 std::cout << "CPU time=" << (double)(time_end - time_start) / CLOCKS_PER_SEC * 1000 << "ms" << std::endl; 93 std::cout << "CPU_result:" << std::endl; 94 for (int i = 0; i < Matrix_w; ++i) { 95 for (int j = 0; j < Matrix_h; ++j) { 96 printf("C[%d][%d]=%f ", i, j, C[i][j]); 97 } 98 printf(" "); 99 } 100 101 cudaFree(d_A); 102 cudaFree(d_B); 103 cudaFree(d_C); 104 return 0; 105 }
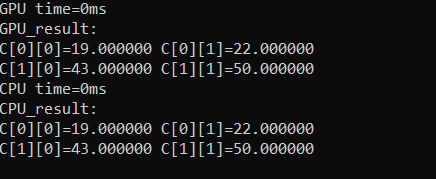
运行结果如下图: