本文系简要笔记,作者李宏毅,原地址:https://www.youtube.com/watch?v=ugWDIIOHtPA&list=PLJV_el3uVTsOK_ZK5L0Iv_EQoL1JefRL4&index=61
1 背景
RNN
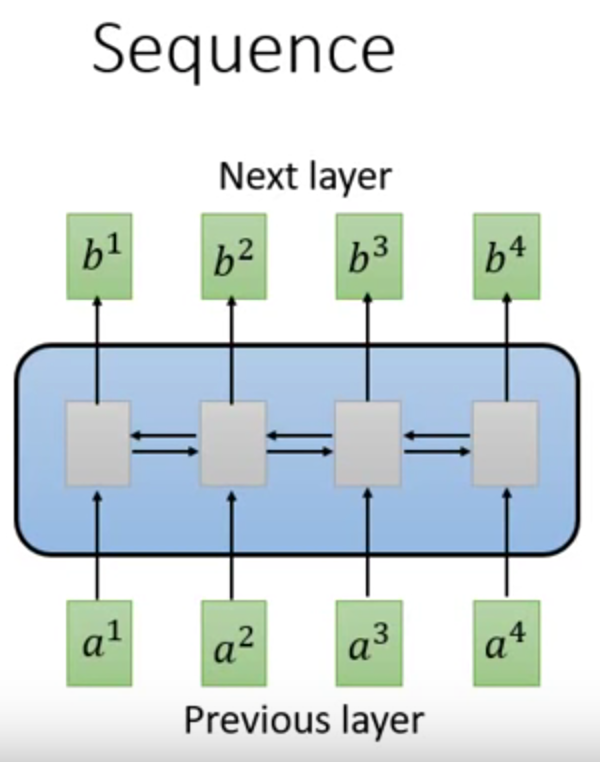
↑在seq2seq任务中,多使用RNN结构。
RNN可以是单向的,也可以是双向的。
它可以实现时间序列的记忆功能,但是缺点是难以并行计算,导致计算成本很高。
原因是t时刻的输出,依赖于t-1时刻的输出。
CNN
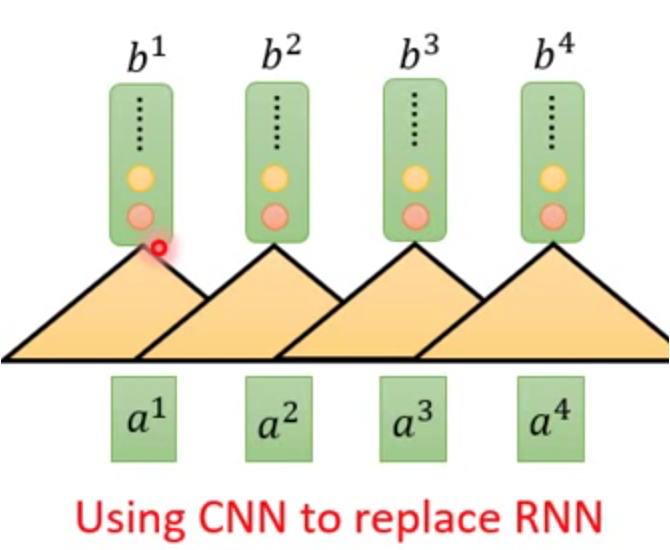
↑因此,有人提出了用CNN代替RNN,达到增强并行计算的目的。
CNN采用过滤器机制,可以缩小依赖的范围。同样,缺点是看得范围太窄,导致全局信息丢失。
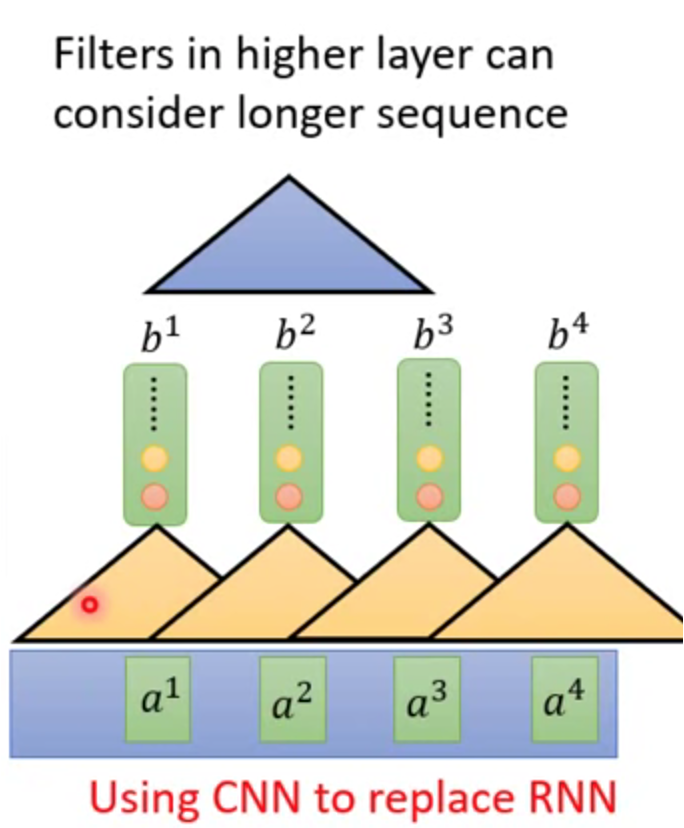
↑也可以通过叠加的方式,使得网络能够感知到全局信息。但是模型会变得很深,算起来很慢。
2 Self Attention 主要思路
Self Attention
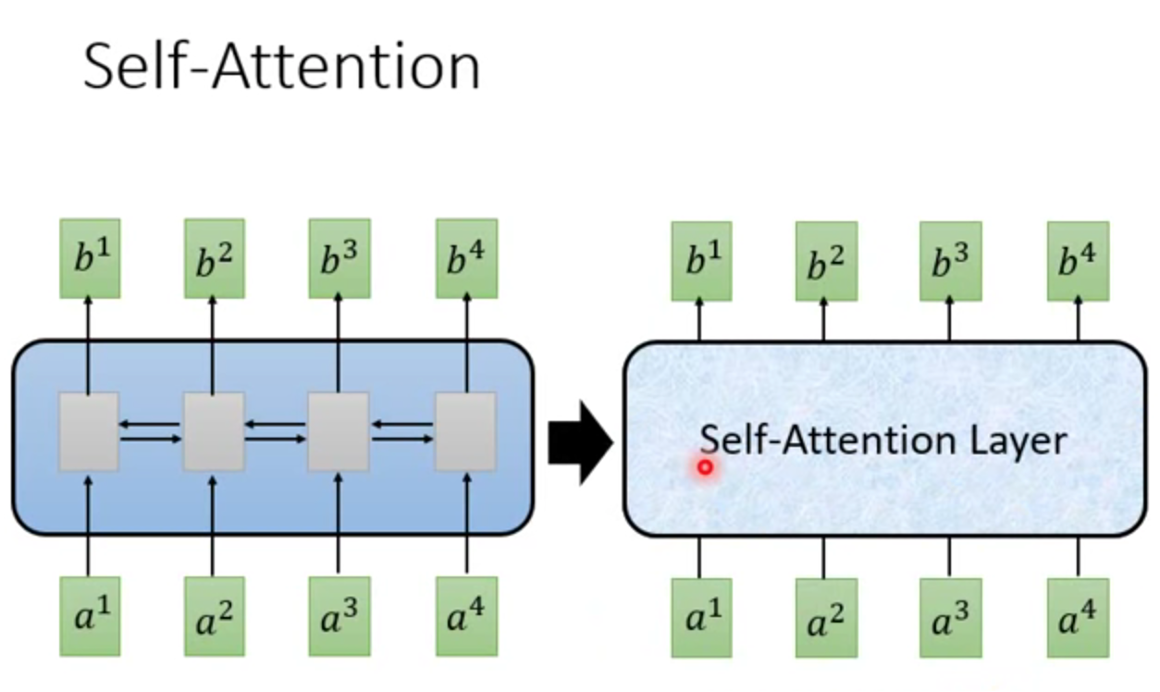
↑Self Attention是替换了seq2seq中的RNN部分。
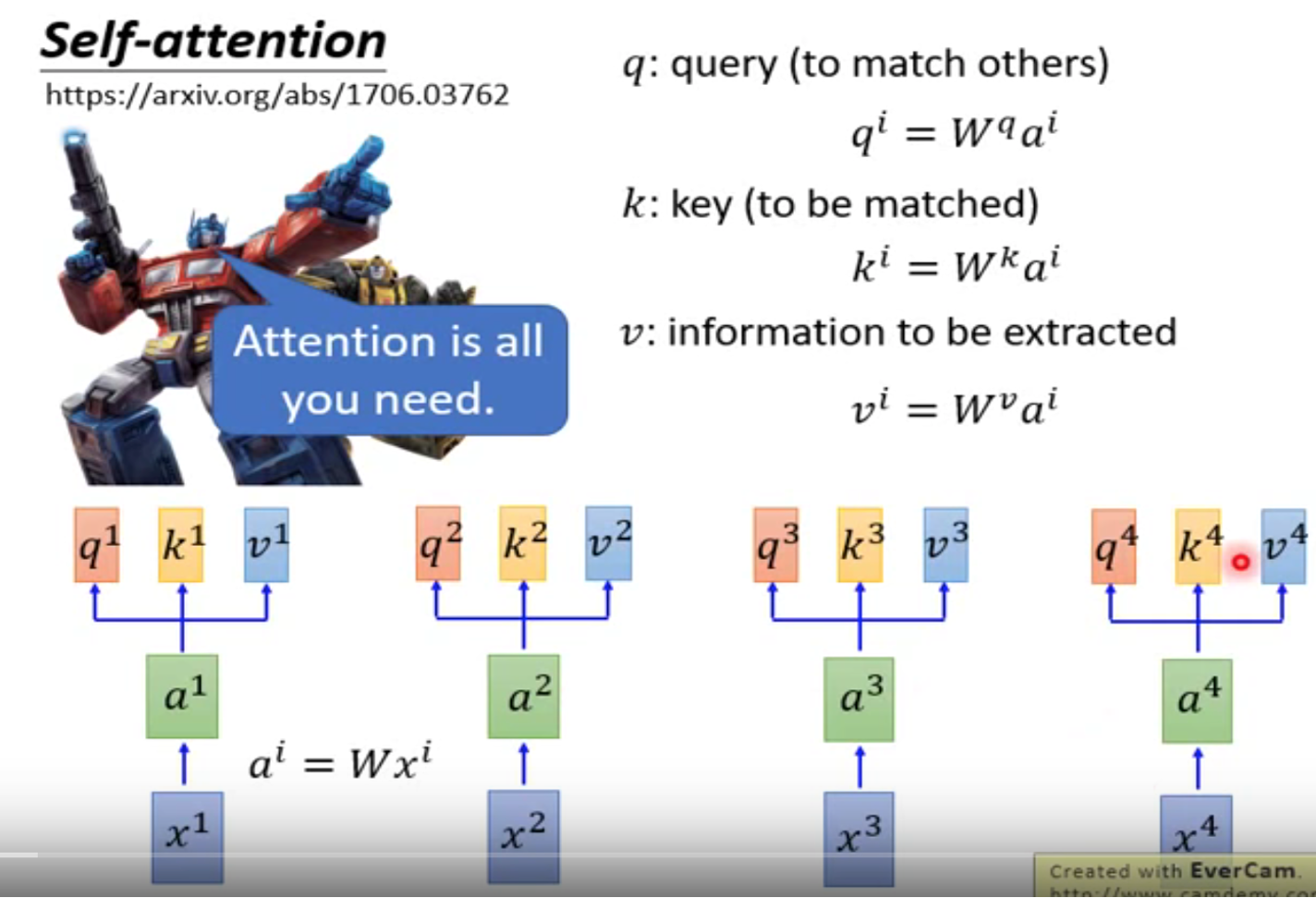
↑它引入了3个向量:q、k、v。不需要RNN,也不需要CNN。

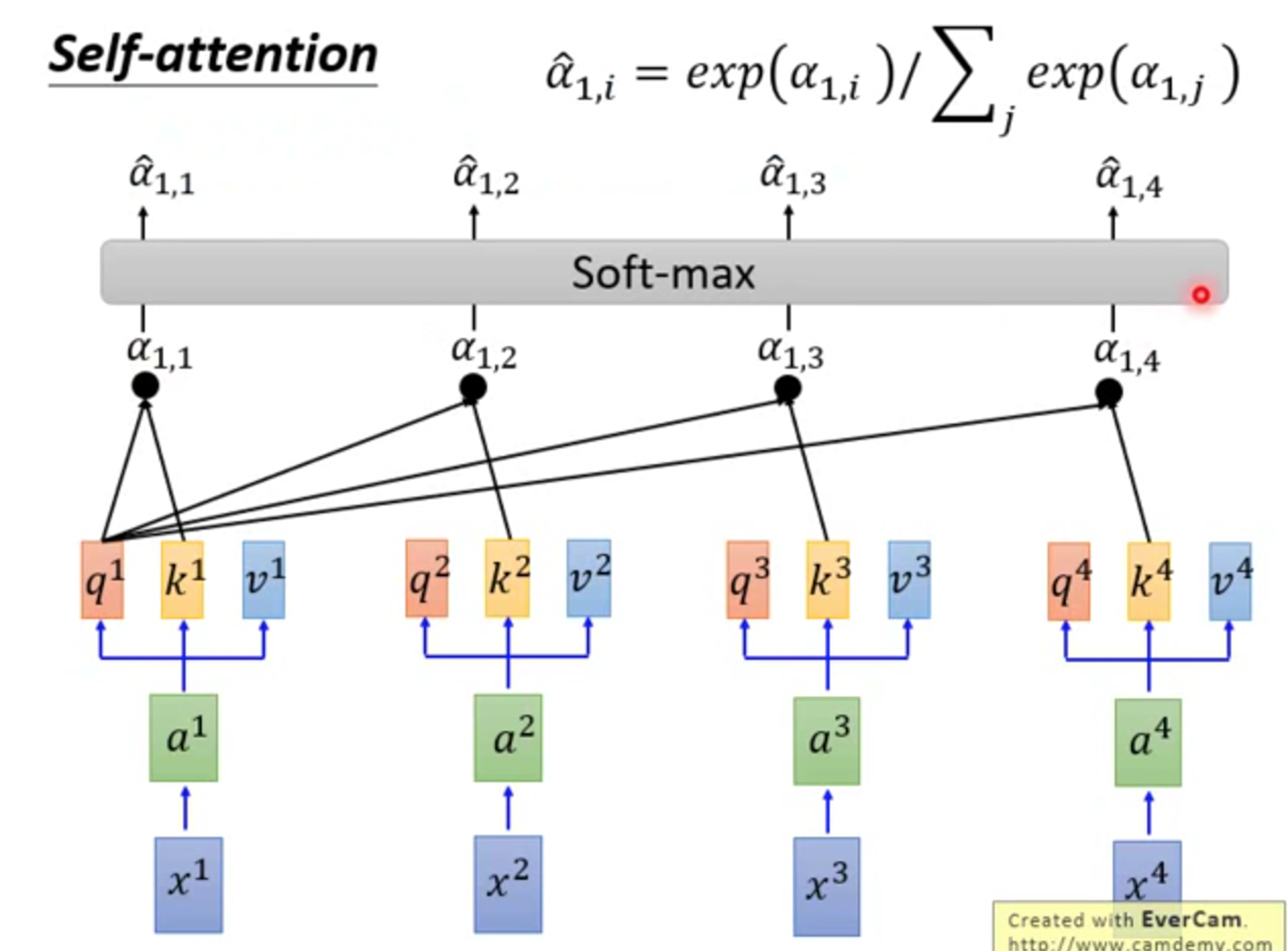
↑简单来讲:
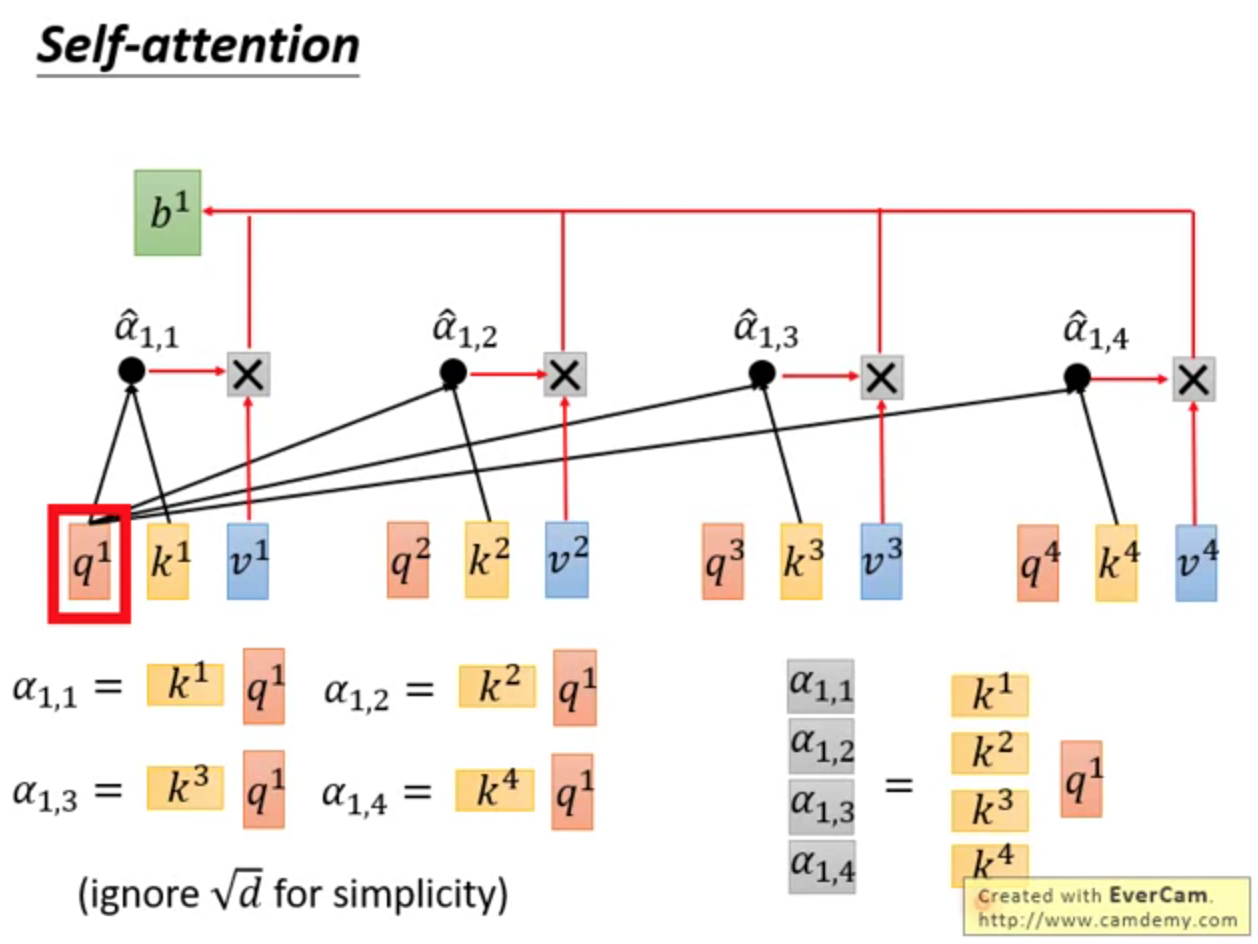
第一步:q和k相乘,得到α
第二步:α经过softmax,得到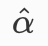
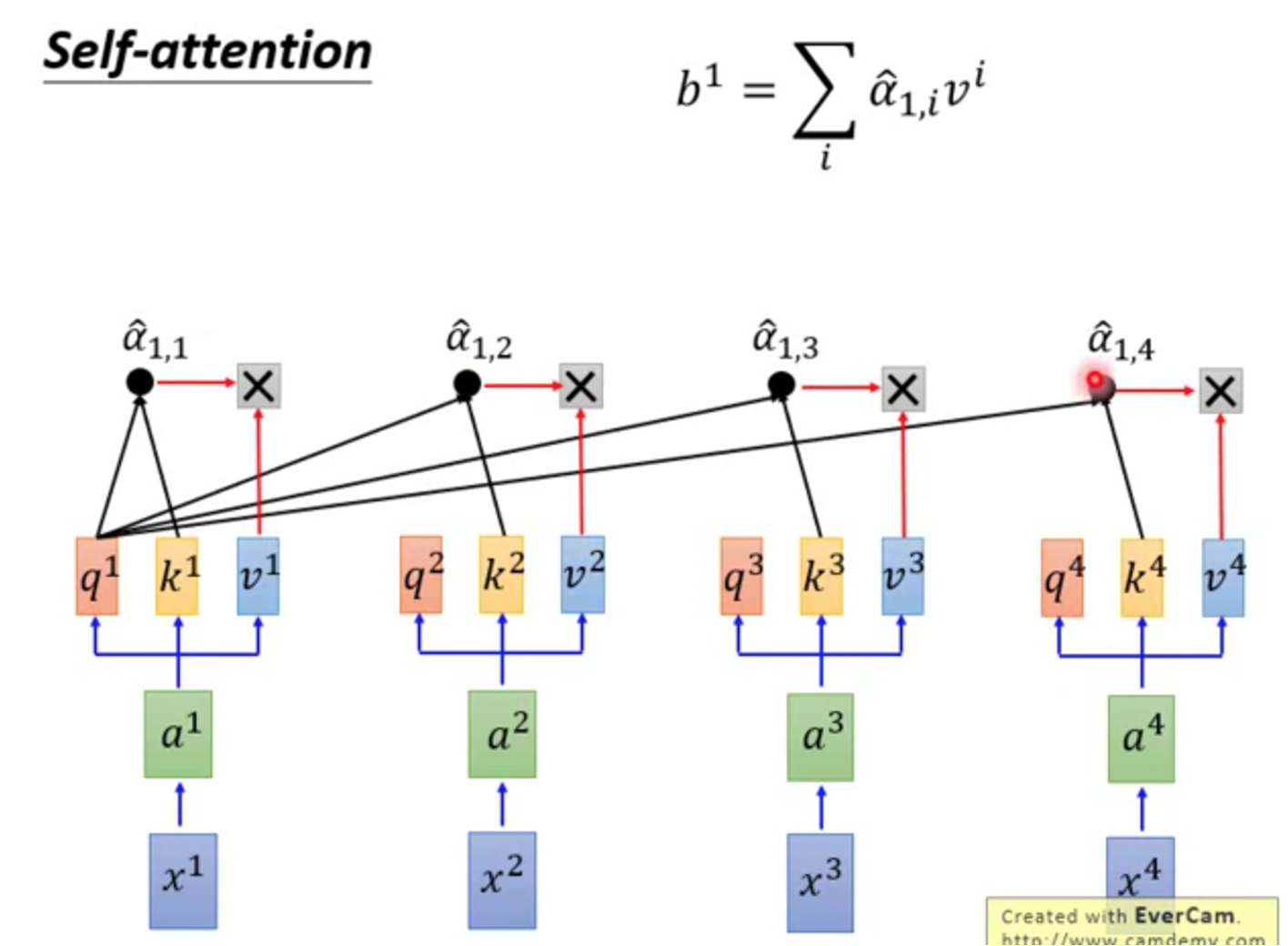
第三步,和v相乘,得到b
综上,
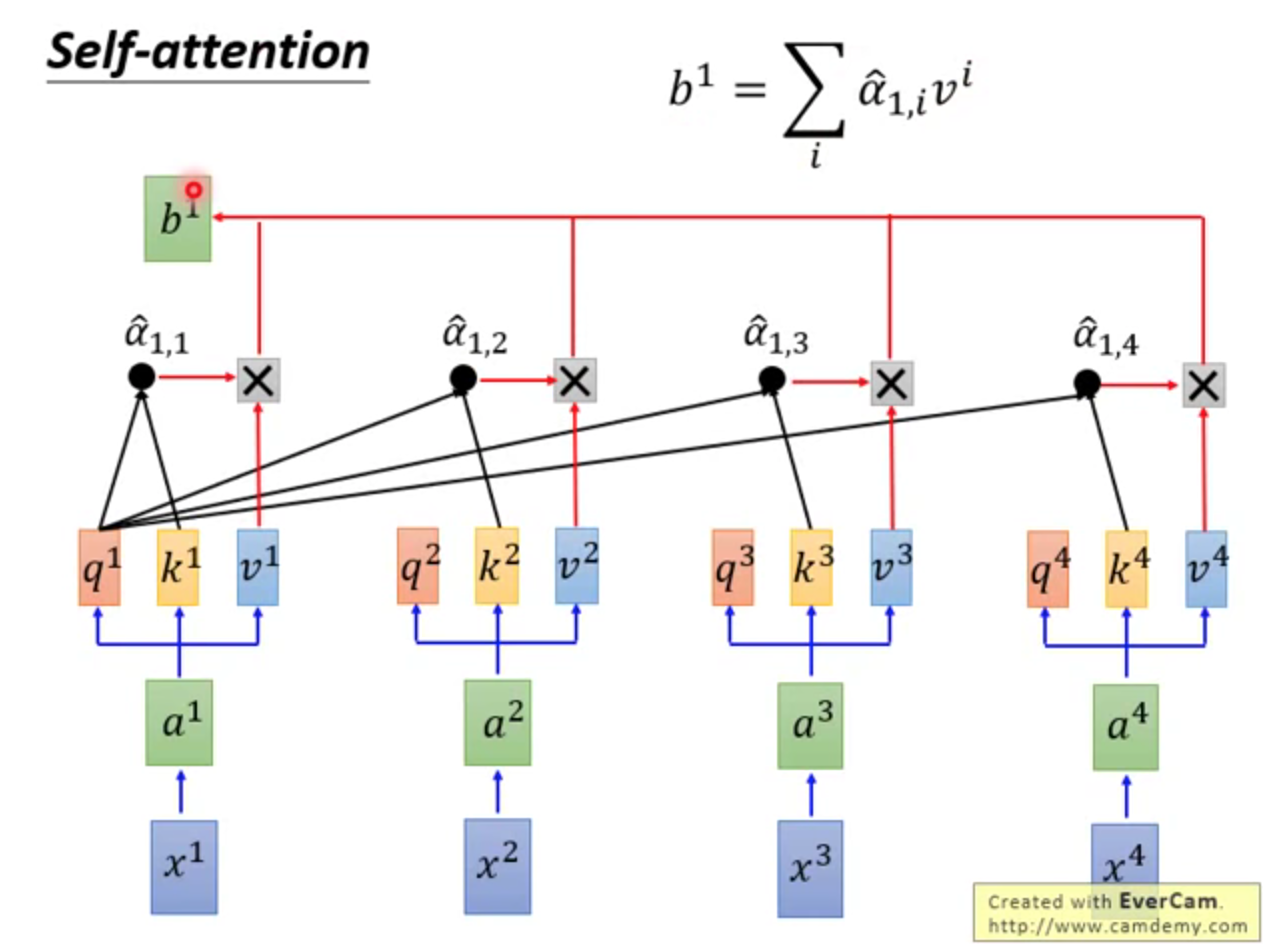
q、k、v,都用到了;
可全局、可局部;
可远、可近
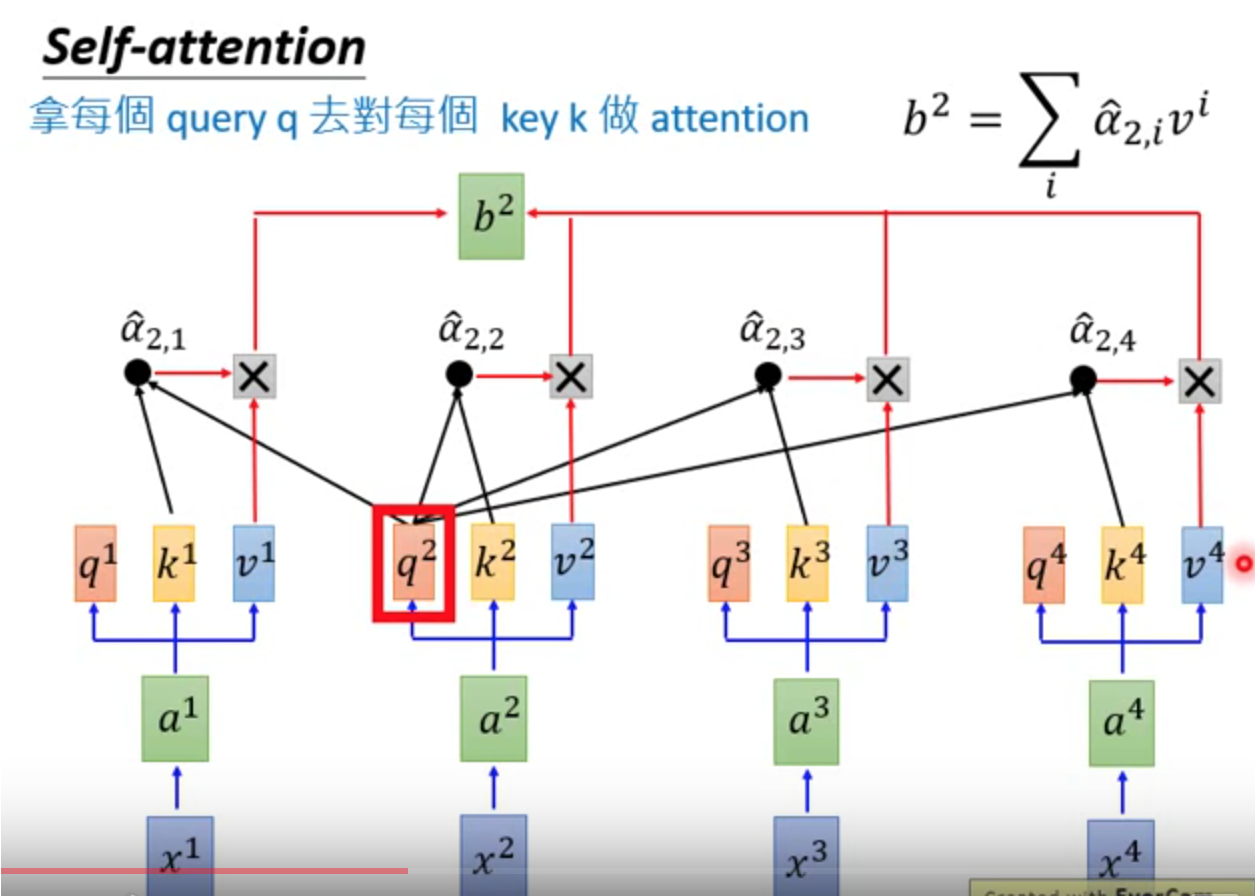
同理,得到b2,b3,……
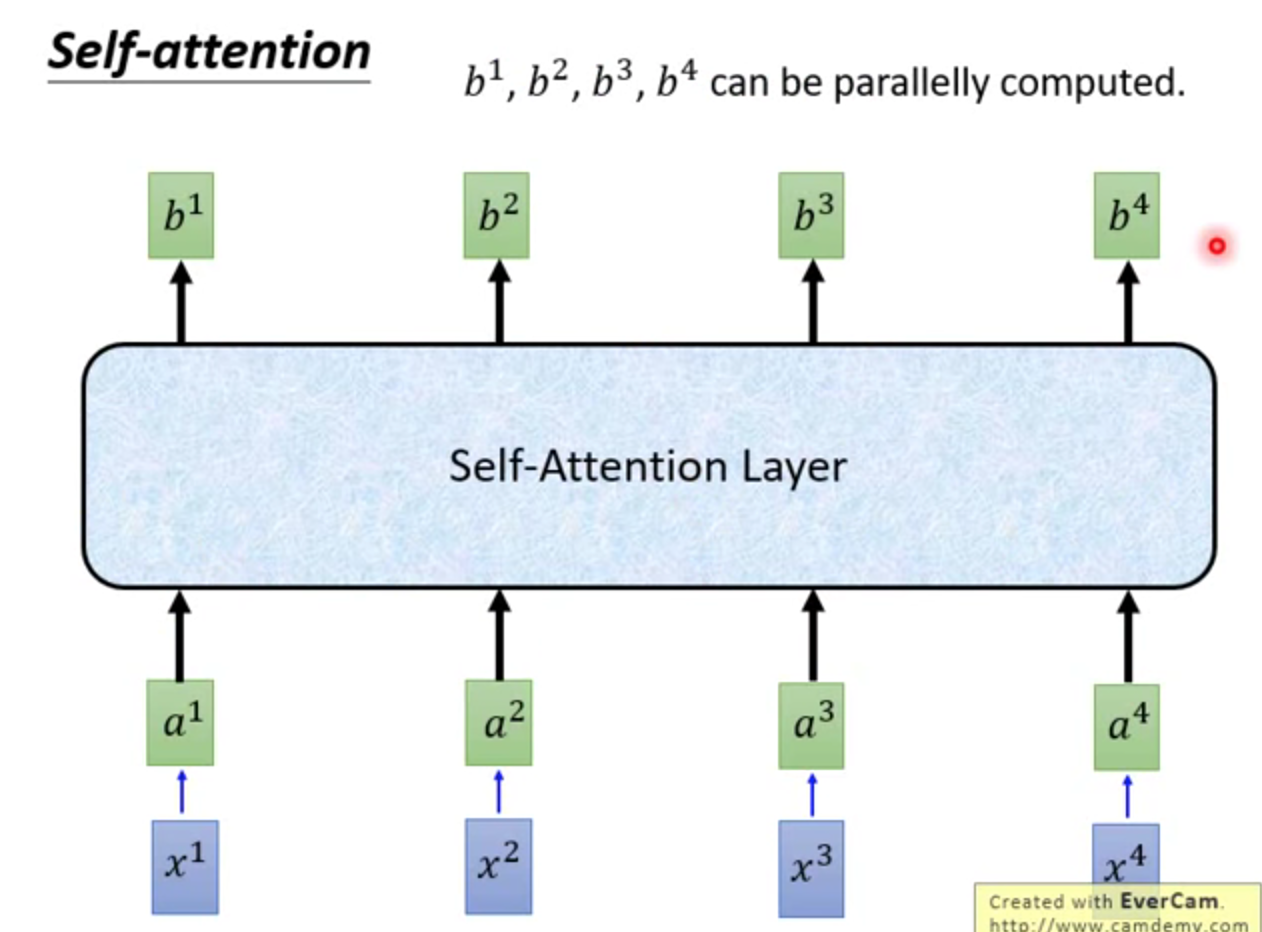
整体来讲,
矩阵推理
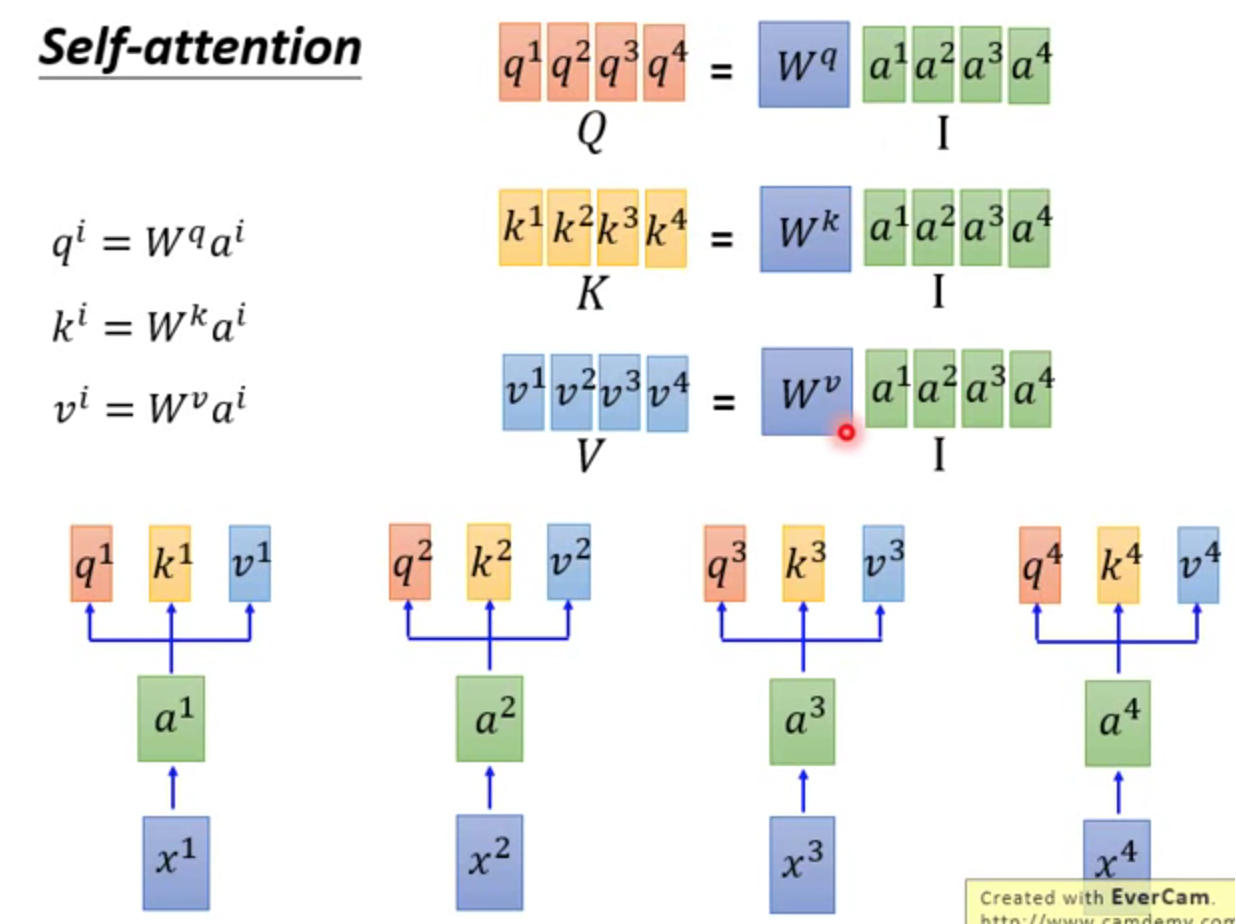
↑(1)权重矩阵W共3个
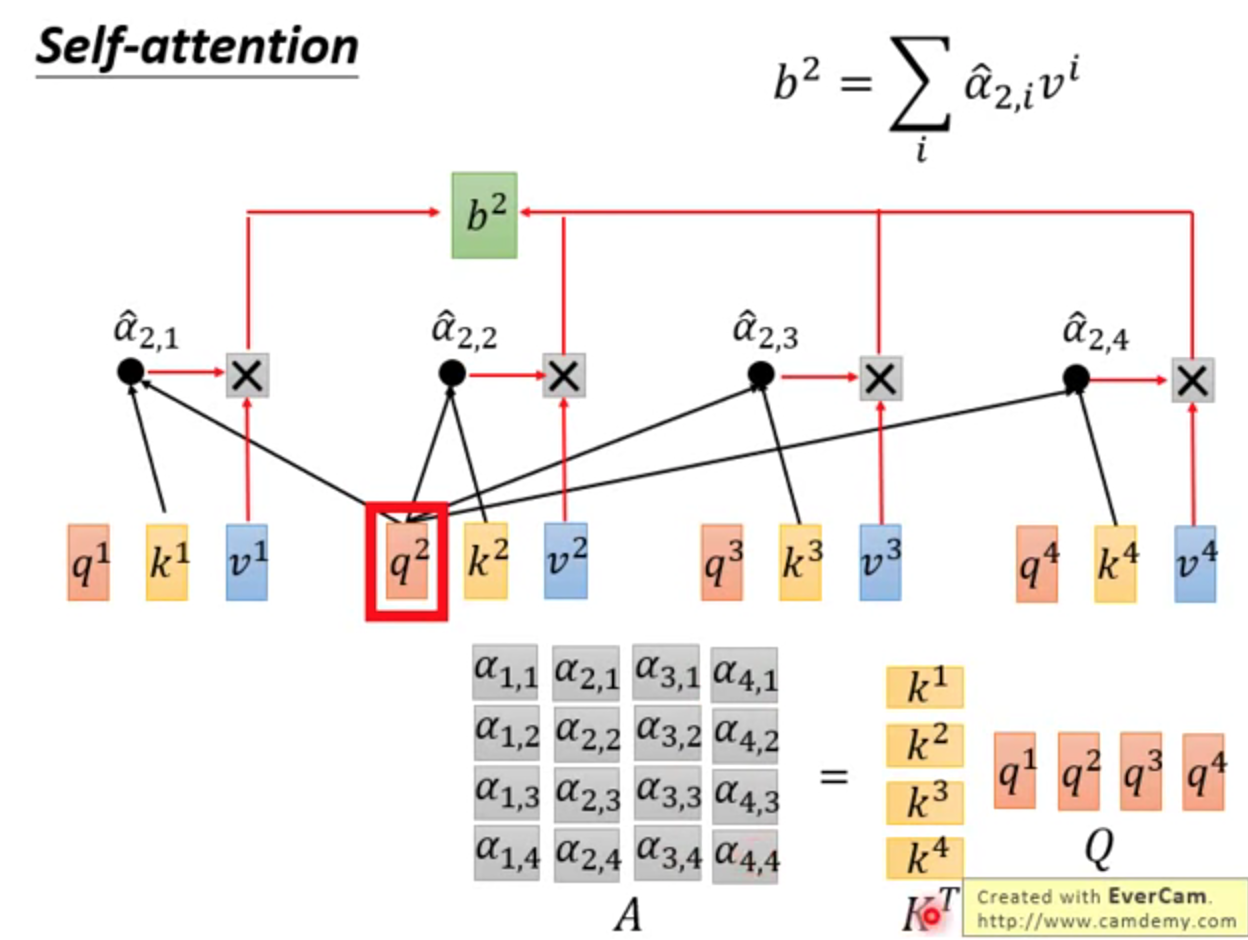
↑(2)通过矩阵计算得到α。这个步骤可并行
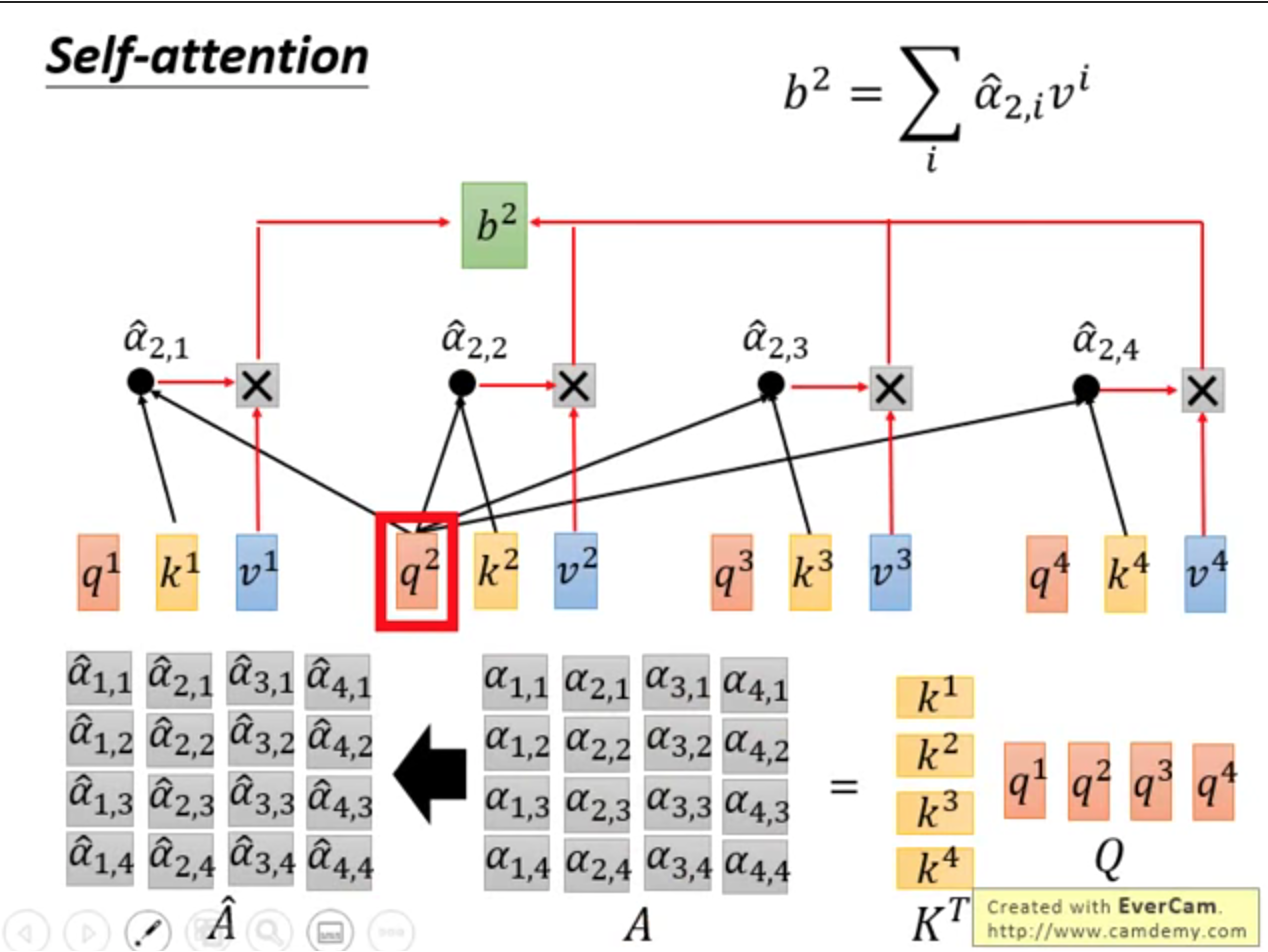
↑(3)α经过softmax,得到
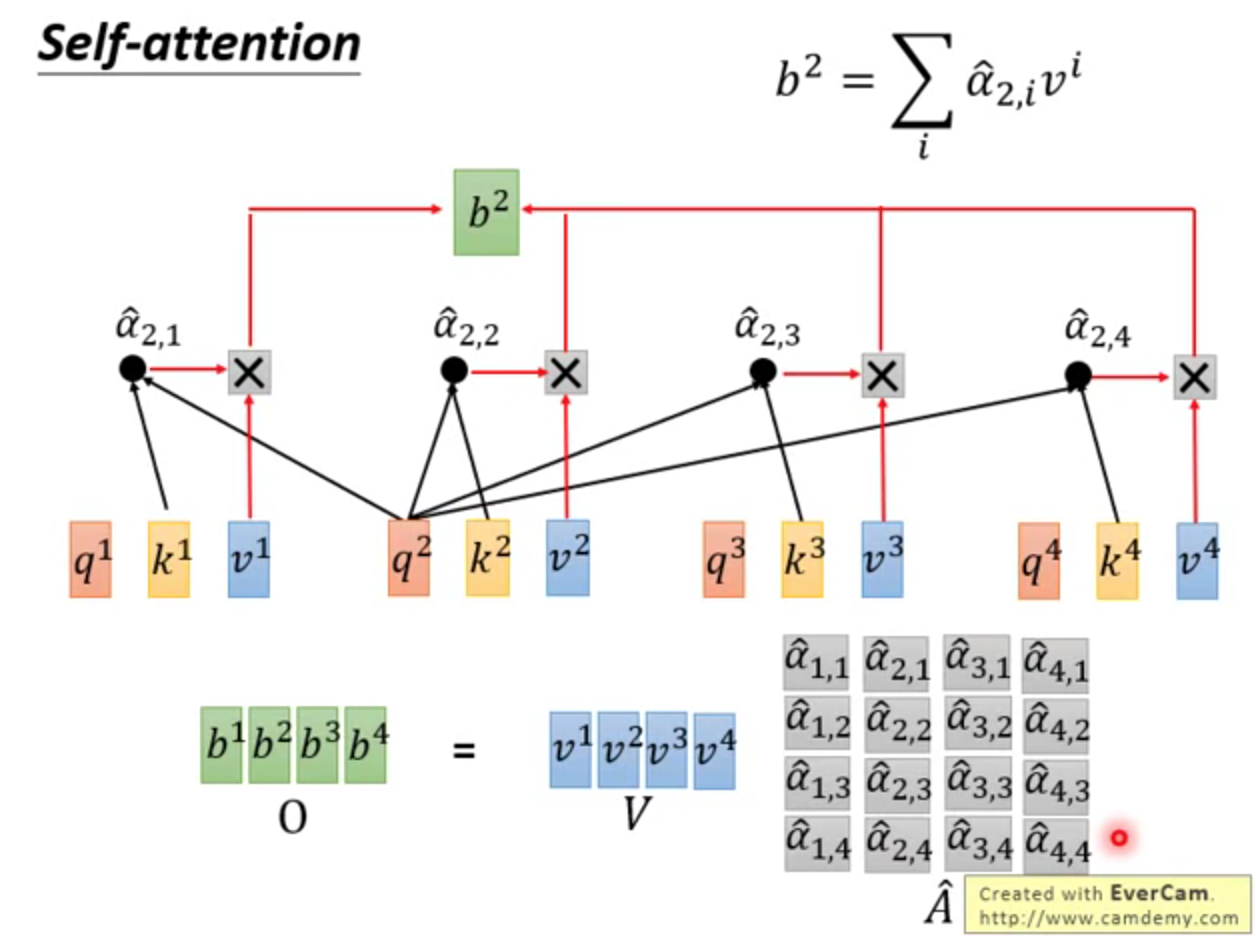
↑(4)和v相乘,得到b
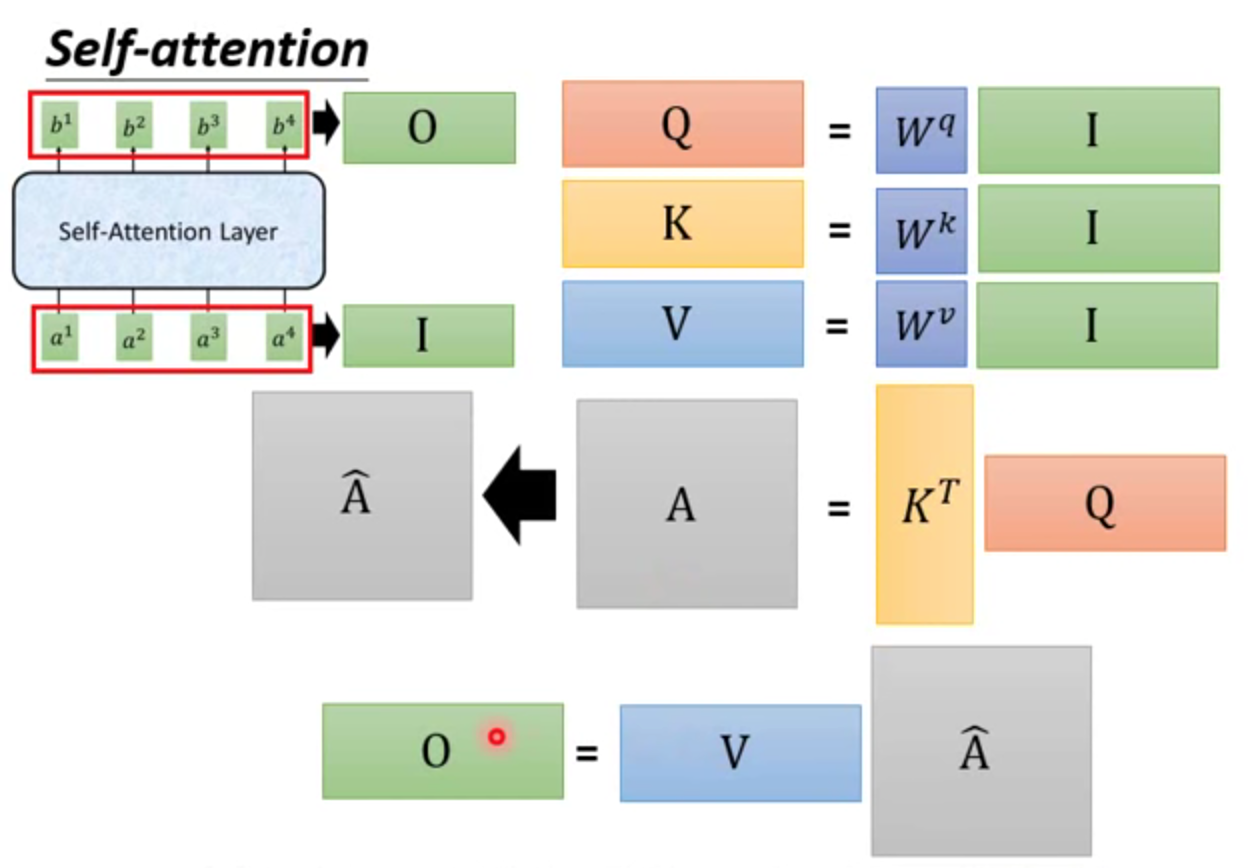
↑整体过程。本质是矩阵相乘,GPU可以并行加速
3 多头注意力
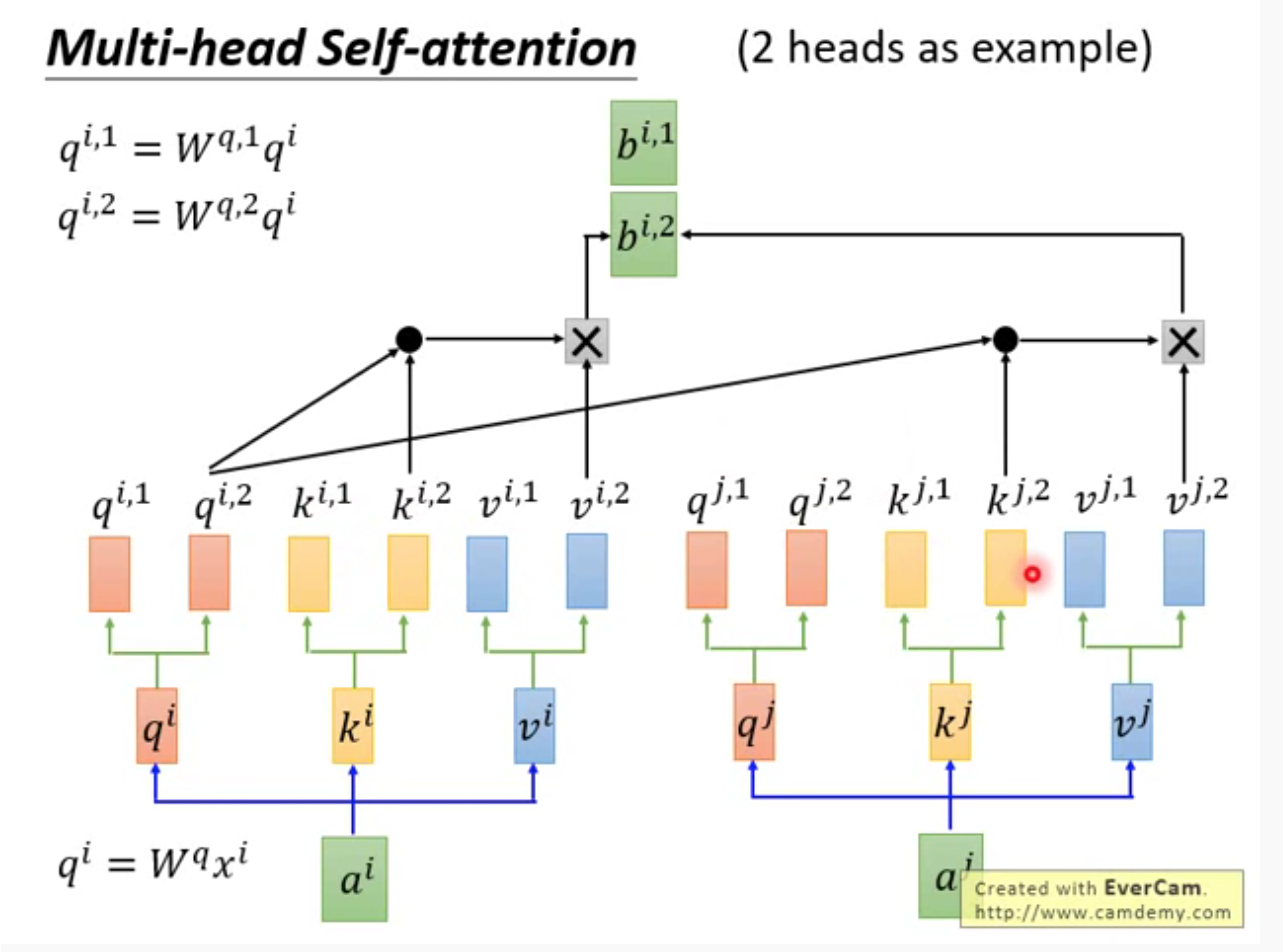
多个q,多个k,多个v。最终也会得到多个b
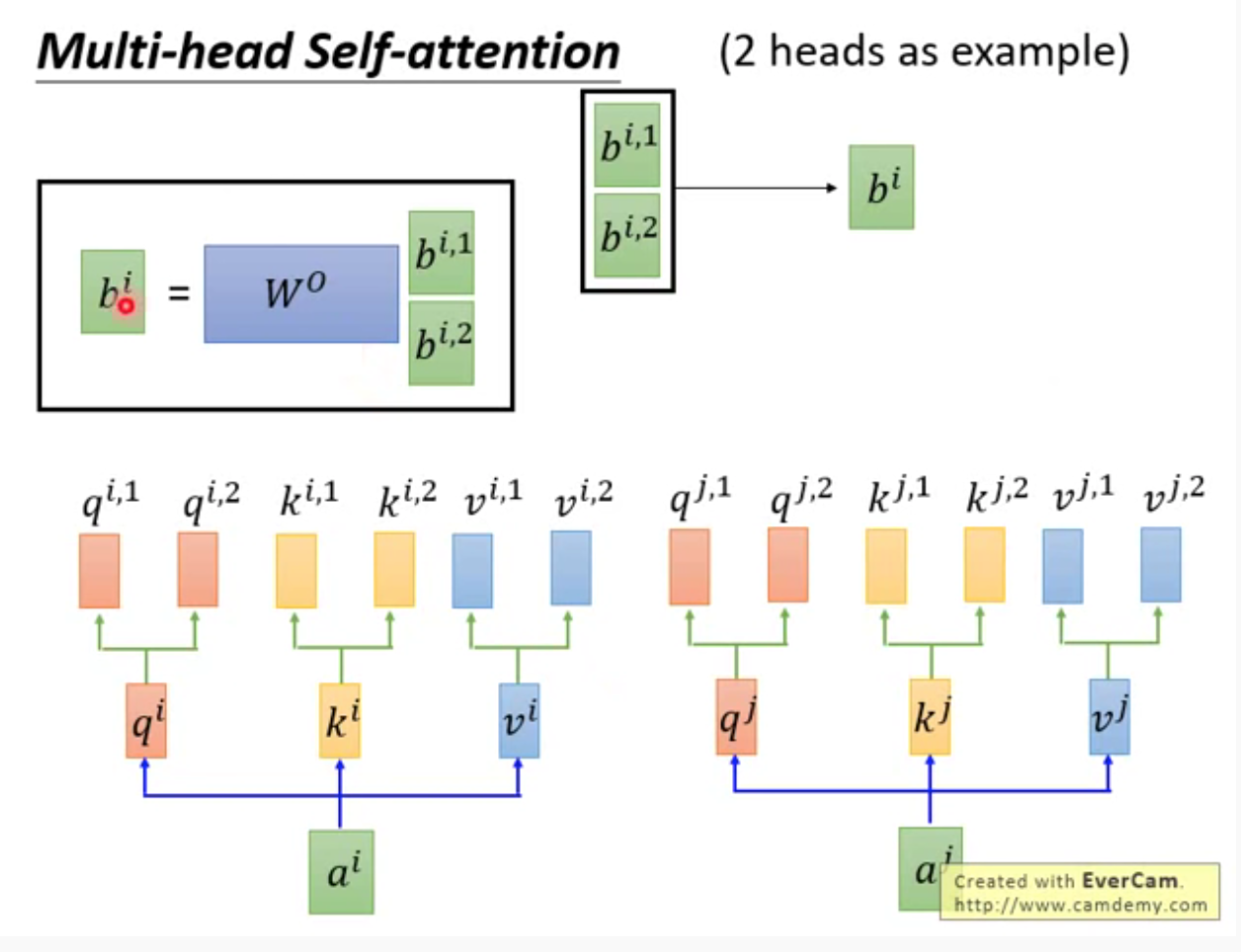
多个b先连接,再经过矩阵相乘,通过降维,得到一个b,即为网络输出。
多头的好处:不同head,关注的点不同;各司其职
4 位置编码

位置信息直接编码,然后累加。
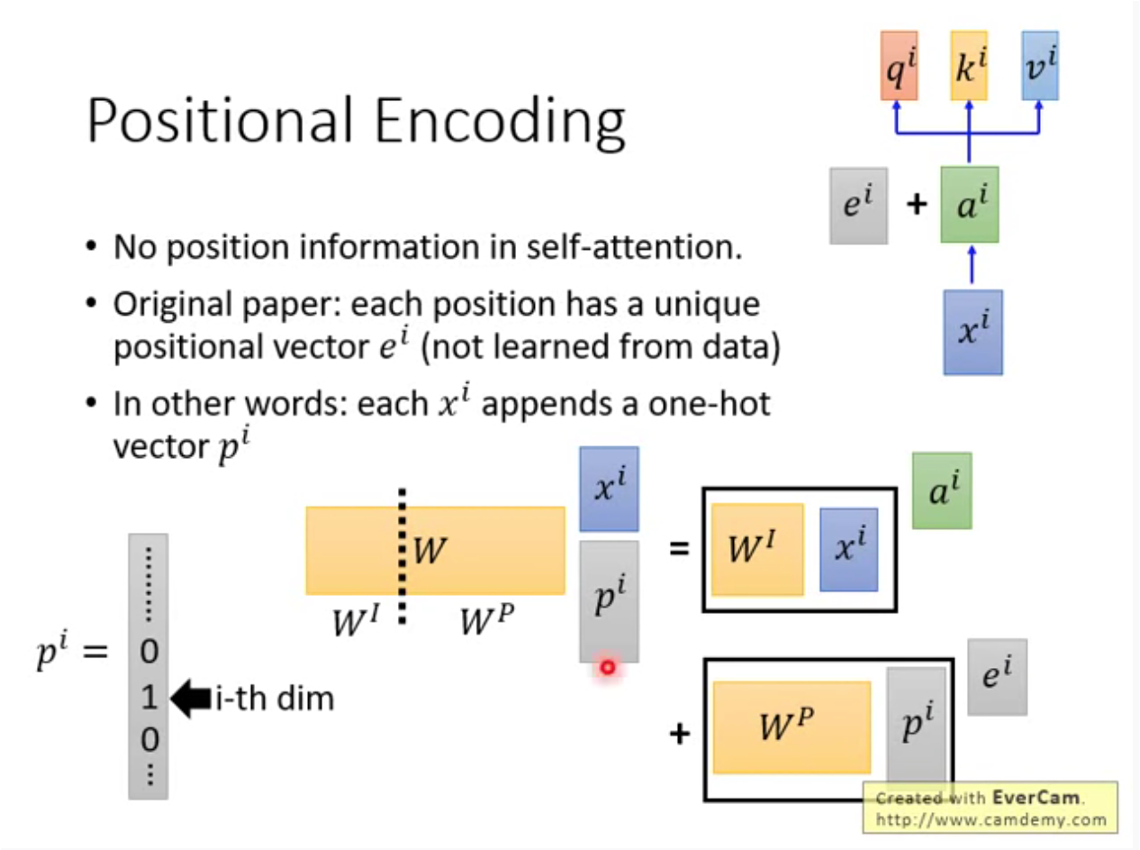
↑追加和累加,本质是一样的。黄色的W可通过矩阵分割,分为(W^{I})和(W^{P})
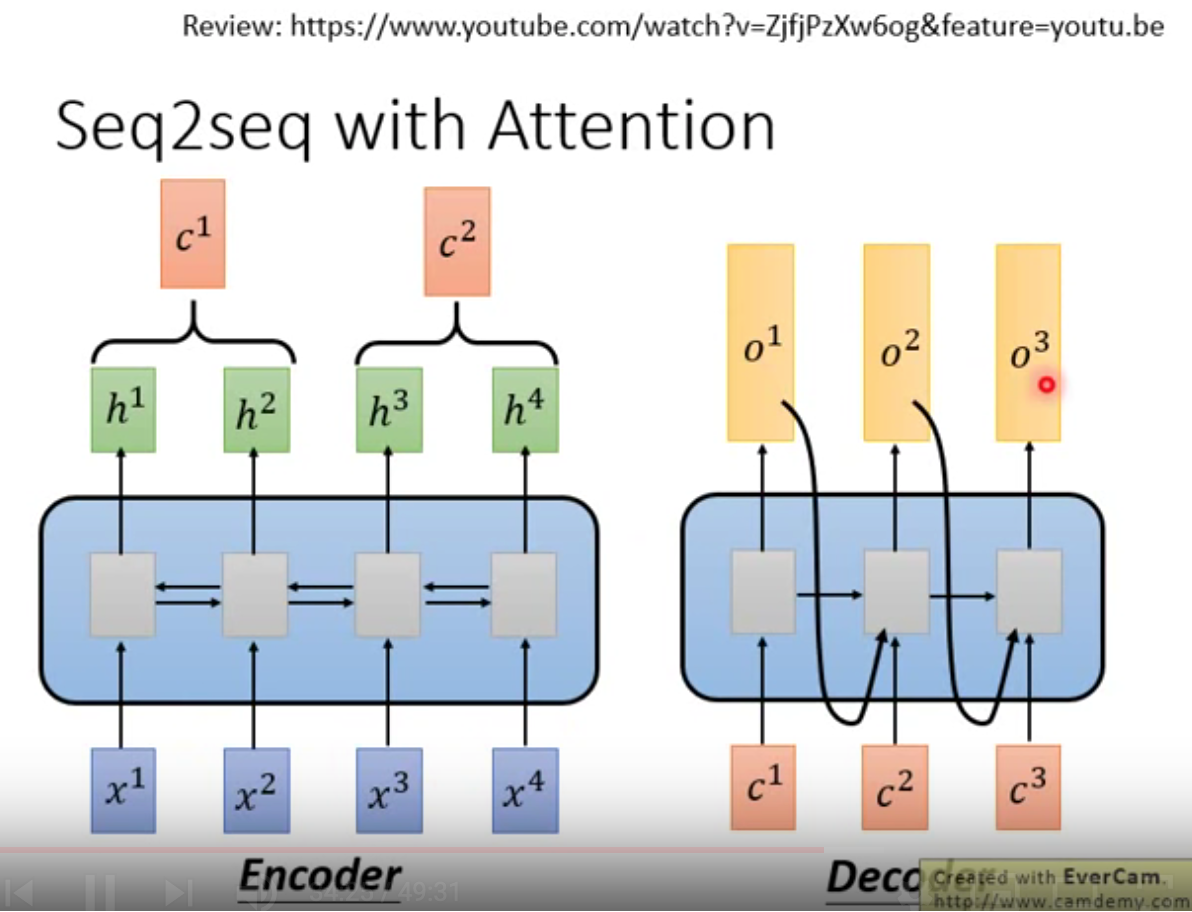
5 Seq2Seq with Attention
把Attention用到seq2seq任务中
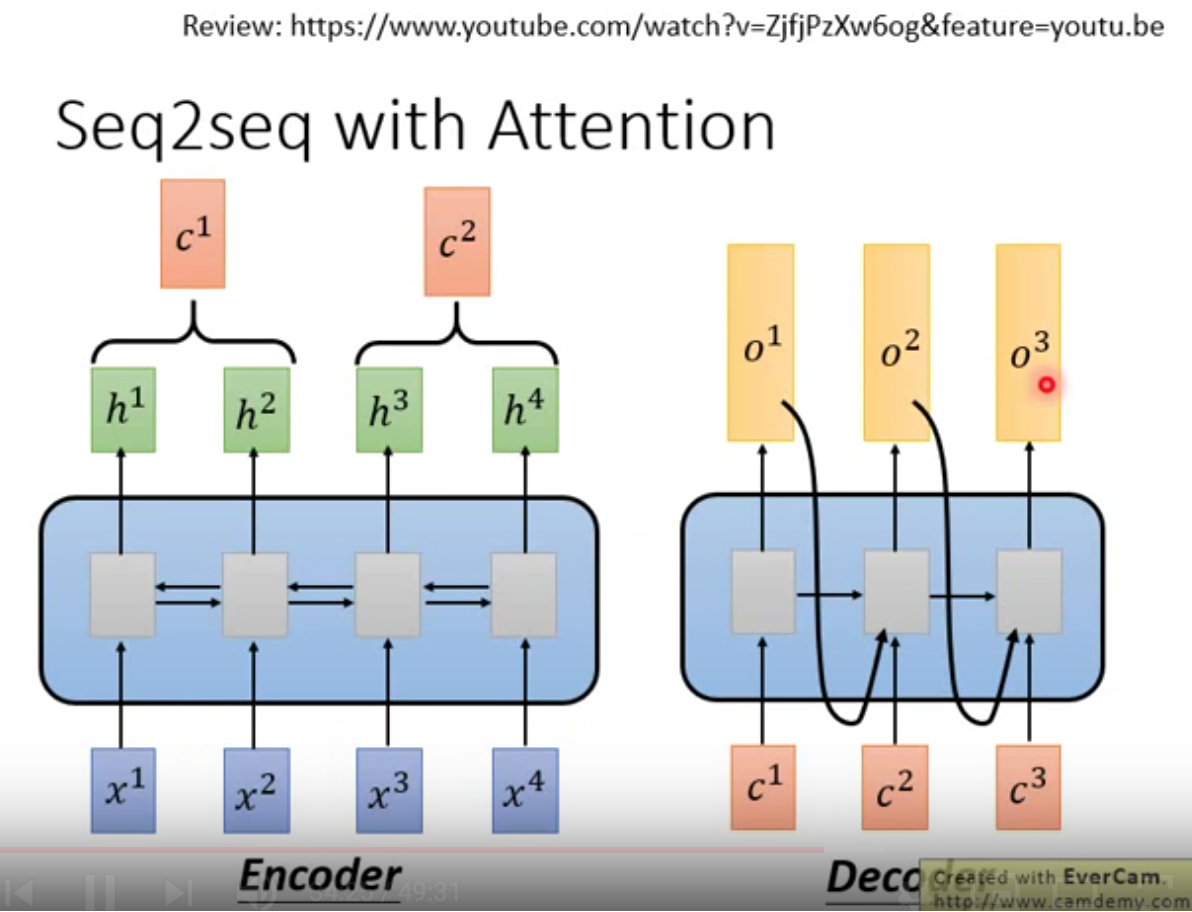
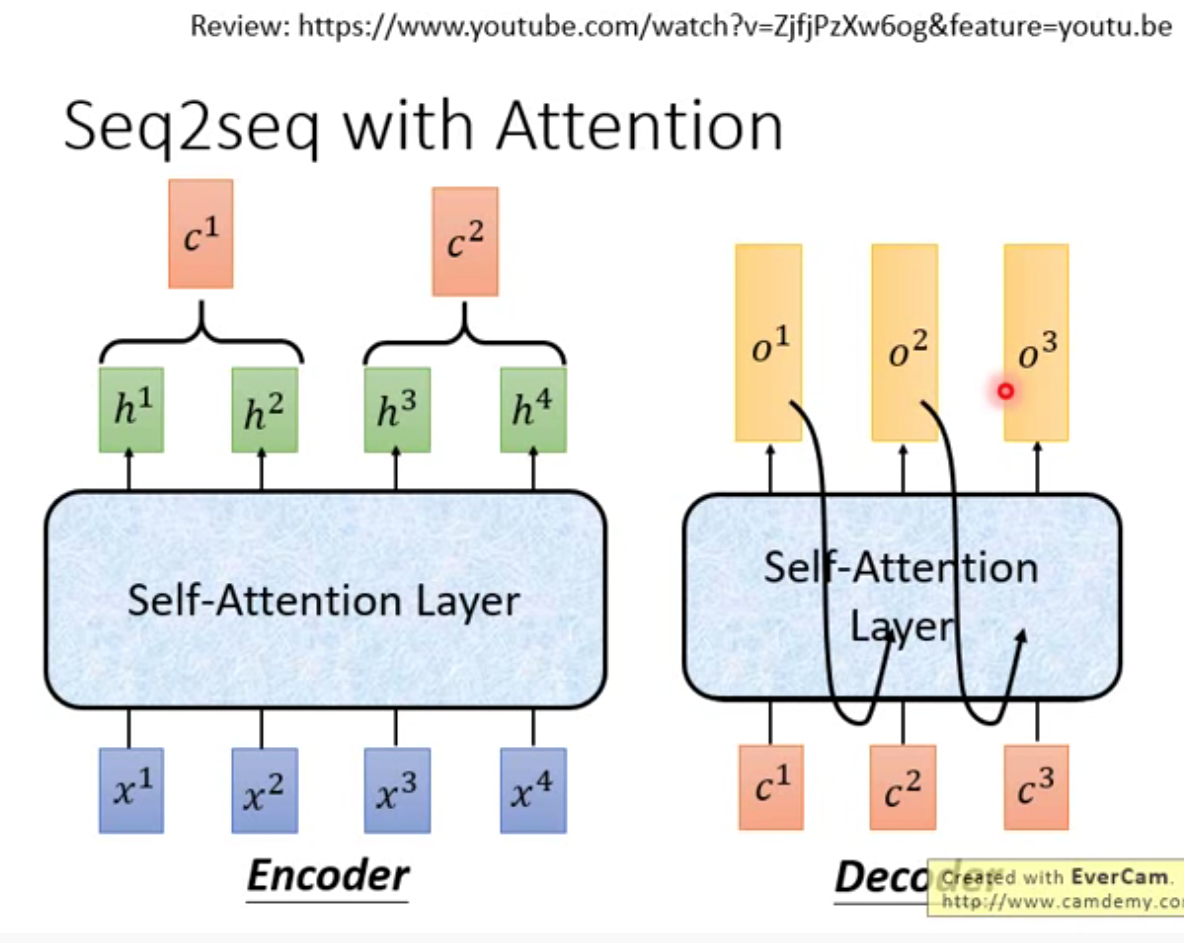
在encoder和decoder中,分别替换原来的rnn部分。
5 transformer
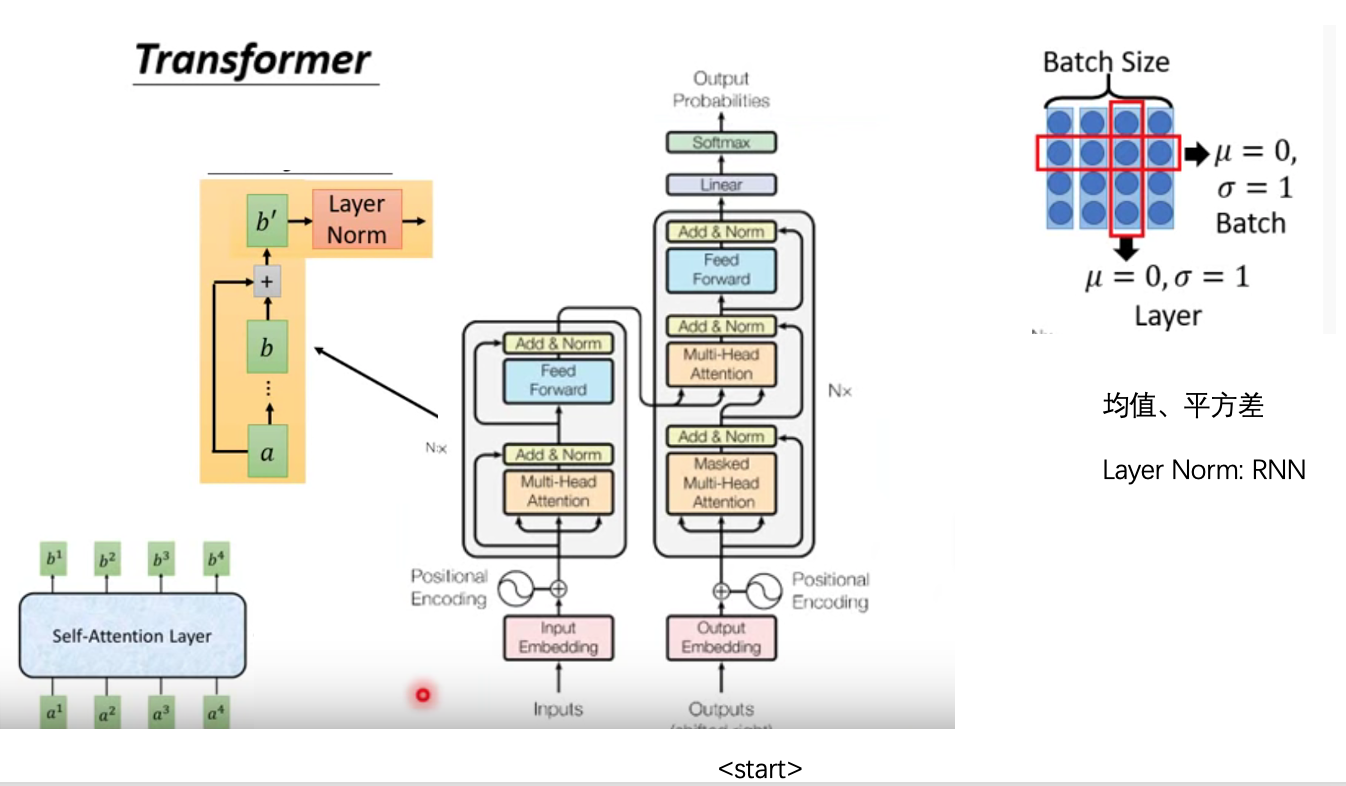
左边encoder,右边decoder。
注意橙色部分为Attention,即上文所述。
6 用处


同seq2seq。在摘要任务中,可处理更长的原文档。