redis的五种数据类型和使用场景
string类型
string类型多用于缓存
set key value(value可以为json字符串)
setnx多用于分布式锁(后面详细整理)
计数器
incr article:{文章id}:readcount
get article:{文章id}:readcount
web集群session共享
redis实现session共享
https://www.cnblogs.com/cxx8181602/p/9759645.html
分布式系统全局序列号(分库分表的主键可以使用此方法 批量生成id会提升性能)
incrby orderid 1000
setbit的位运算
https://www.jianshu.com/p/3a30f58ba62c
hash类型
对象存储
mset user {user_id}:name test {user_id}:age 12
hget user {user_id}:name {user_id}:age
因为redis是单线程操作,有一个非常大的忌讳就是不要让key太大,会导致执行该命令时间非常长,会阻塞线程,所以hash不要当作数据库来用,只是存储一些热数据就行
在实际应用中,可以给hash的key来分段,有一点类似于数据库分表那种思路,把数据存储在不同的key中,切记,千万不要让一个key过大
可以用来实现购物车功能
实现方式如下图
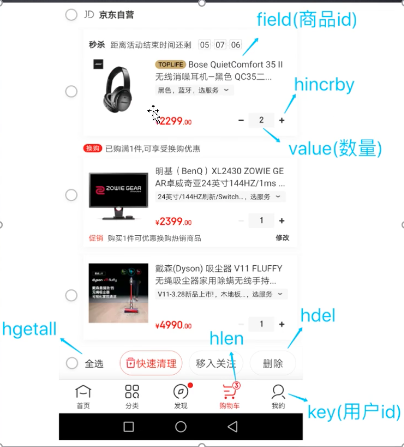
- 以用户id为key
- 以商品id为field
- 商品数量为value
购物车操作流程 - 添加商品 hset cart:123 10010 1(123为user_id 10010为商品id)
- 增加数量 hincrby cart:123 10010 1
- 商品总数 hlen cart:123
- 删除商品 hdel cart:123 10010
- 获取购物车所有商品 hgetall cart:123
和string相比的优缺点
优点
- 同类数据归档,存储比较方便
- 比string消耗的cpu更小
- 比string更节省存储空间
缺点
- 过期功能不能用在field上,只能用在key上
- 不适合在集群架构下大规模使用(集群数据都是分片处理的,目的是让数据分段均匀的存储,比如把user表的信息都存在hash中,就会导致那个key非常大,这样就会导致某一个redis机器上的数据非常大,导致了数据倾斜)
list类型
可以实现常见的栈和队列的数据结构,如下图
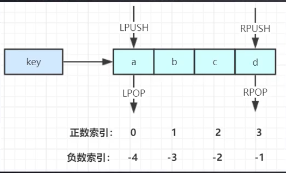
阻塞队列
Blocking MQ(阻塞队列) = LPUSH + BRPOP( BRPOP会一直等待)
微信,微博消息流
博主发消息直接发到粉丝的信息list中,粉丝直接读取即可,但是这种只适合粉丝比较少的情况
set类型应用场景
微信抽奖活动
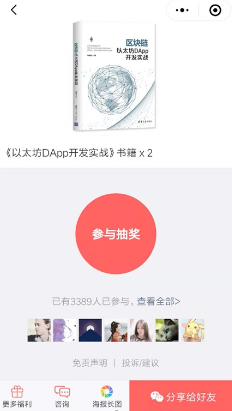
- 点击参与抽奖 sadd key {user_id}
- 查看所有抽奖用户 smambers key
- 抽取count名中奖者 srandmember key count 或者 spop key count(spop从集合中取出数据后会删除掉 适合不能重复抽奖的场景)
** 微信微博点赞的实现**
- msg_id为朋友圈id user_id为点赞操作的用户的id
- 点赞: sadd like:{msg_id} {user_id}
- 取消点赞: srem like:{msg_id} {user_id}
- 检查用户是否点过赞 : sismember like:{msg_id} {user_id}
- 获取点赞用户列表: smembers like:{msg_id}
- 获取点赞用户数: scard like:{msg_id}
可以做一些简单的推荐
用交集 差集等功能,做一些比较简单的推荐
- sinter
- sunion
- sdiff
注意 交集 差集运算速度比较慢,如果使用的话 最好用单独的实例
zset
实现新闻排行榜
- 点击新闻 zincrby news:date 1 news_id
- 展示当日排行前10 zrevrange news:date 0 9 withscores
- 展示7天排行榜
- datalist为7天的日期 逐个枚举
- zunionstore news:datelist 7 news:date1 news:date2 。。。。news:date7
- 展示7日排行前10
- ZRANGE news:datelist 0 9 WITHSCORES
关注我的技术公众号,每周都有优质技术文章推送。
微信扫一扫下方二维码即可关注:
