元组
什么是元组: 元组就是一个不可变的列表
===============================基本使用==============================
1、用途: 用于存放多个值,当存放的多个值只有读的需求没有改的需求时用元组最合适
2、定义方式:在()内用逗号分隔开多个任意类型的值
t=(1,3.1,'aaa',(1,2,3),['a','b']) # t=tuple(...)
print(type(t)) #tuple
res=tuple('hello') #('h', 'e', 'l', 'l', 'o') #相当于列表的list(),底层是进行for循环
res=tuple({'x':1,'y':2})
print(res) #('x', 'y') 只有key
3、常用操作+内置的方法
优先掌握的操作:
1、按索引取值(正向取+反向取):只能取
t=('a','b',1)
t[0]=111 #报错,不可改变类型
2、切片(顾头不顾尾,步长)
t=('h','e','l','l','o')
res=t[1:3]
print(res)
print(t)
3、长度
t=('h','e','l','l','o')
print(len(t))
4、成员运算in和not in
t=('h','e','l','l','o')
print('h' in t)
5、循环
t=('h','e','l','l','o')
for item in t:
print(item)
===============================该类型总结================================
存多个值
有序
不可变(1、可变:值变,id不变。可变==不可hash 2、不可变:值变,id就变。不可变==可hash)
不可变类型拓展:
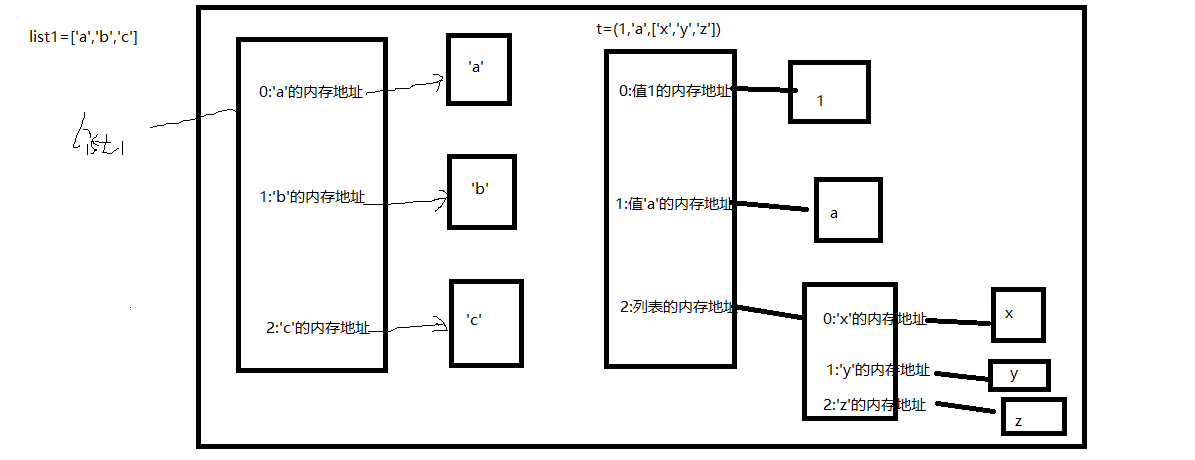
t=(1,'a',['x','y','z'])
print(id(t[2])) #34878344
print(id(t)) #41422136
t[2][0]='X' #结合元组配图理解
print(t)
print(id(t)) #41422136 改变元祖内部的列表的元素值,列表的id不会改变,只有列表内元素的地址改变了,列表本身的id并不会改变
print(id(t[2])) #34878344 列表本身的id并不会改变
内存图解:
定义一个元素的元组
t=(1,) #必须加逗号,不然会变成字符串类型
print(t,type(t))
列表的id:
list1=['a','b','c']
print(id(list1[0]))
print(id(list1[1]))
print(id(list1[2])) #id各不一样
print('='*50)
list1[1]='B'
print(id(list1[0]))
print(id(list1[1])) #列表元素被改变,所以id改变
print(id(list1[2]))
掌握的方法
t=('a','b','a')
print(t.index('a')) #找到第一个a的索引
t.index('xxx') #元素不存在,报错
print(t.count('a')) #记a出现的次数
字典类型:
==============================基本使用======================================
1、用途: 用来存方多个(不同种类的)值
2、定义方式: 在{}内用逗号分隔开多个key:value的元素,其中value可以是任意数据类型,而key的功能通常是用来
描述value的,所以key通常是字符串类型,但其实key必须是不可变的类型(intfloatstr uple)
d={0:'x',1.3:'y','k1':'z',(1,2,3):'aaa'} # d=dict(....) print(d[(1, 2, 3)]) #aaa d1={[1,2,3]:'aaaaa'} #报错,字典的key必须是不可变类型
d=dict([('k1',1),('k2',2),('k3',3)])
print(d) #{'k1': 1, 'k2': 2, 'k3': 3}
将列表l以字典的形式打印出来,key和value一一对应
l = [('k1', 1), ('k2', 2), ('k3', 3)]
复杂方法
d={}
for t in l: #t=('k1',1)
k,v=t
# print(k,v) #k1 1
d[k]=v #如果key不在字典中,就会加入字典中
print(d) #{'k1': 1, 'k2': 2, 'k3': 3}
简单方法
d=dict(l)
print(d)
同理
d=dict(x=1,y=2,z=3)
print(d)
3、常用操作+内置的方法
优先掌握的操作:
1、按key存取值:可存可取
d={'x':1}
print(d['x']) #1
print(id(d))
d['x']=1111
print(d) #{'x':1111},可变类型,会改变
print(id(d)) #id不会改变
d['y']=2222 #key y不在字典中,就会将y:2222加入到字典中
print(d) #{'x': 1111, 'y': 2222}
2、长度len
d={'x':1,'y':2,'z':3}
print(len(d))
3、成员运算in和not in
d={'x':1,'y':2,'z':3}
print(1 in d)
print('x' in d) #成员运算看的是key,不是value
4、删除
d = {'x': 1, 'y': 2, 'z': 3}
del d['y']
print(d) #删除key为y的元素
res=d.pop('y')
print(d)
print(res) #pop方法的删除会有返回值,返回value的值
d = {'x': 1, 's': 2, 'a': 3}
res = d.popitem() # 随机返回并删除字典中的一对键和值.有返回值
print(res)
5、键keys(),值values(),键值对items()
d = {'name': 'egon', 'age': 18, 'sex': 'male', 'hobbies': [1, 2, 3]}
print(d.keys()) # dict_keys(['name', 'age', 'sex', 'hobbies'])
print(list(d.keys())) # ['name', 'age', 'sex', 'hobbies']
print(d.values()) # dict_values(['egon', 18, 'male', [1, 2, 3]])
print(list(d.values())) # ['egon', 18, 'male', [1, 2, 3]]
print(d.items()) # dict_items([('name', 'egon'), ('age', 18), ('sex', 'male'), ('hobbies', [1, 2, 3])])
print(list(d.items())) # [('name', 'egon'), ('age', 18), ('sex', 'male'), ('hobbies', [1, 2, 3])]
6、循环
for k in d.keys():
print(k)
for k in d: #默认遍历key,所以可以省略key()方法
print(k)
for v in d.values():
print(v)
for k,v in d.items(): #k,v=('name', 'egon')
print(k,v)
========================该类型总结========================
存多个值
无序
可变(1、可变:值变,id不变。可变==不可hash 2、不可变:值变,id就变。不可变==可hash
需要掌握的操作
get方法:
d={'name':'egon','age':18,'sex':'male','hobbies':[1,2,3]}
v=d.get('namexxxxxxx') #如果key不存在,返回None,不会报错
print(v) #None
v1=d['namexxxxxxxxxxx'] #如果key不存在,会报错
print(v1)
update方法:
d={'name':'egon','age':18,'sex':'male','hobbies':[1,2,3]}
d.update({'x':1,'name':"EGON"}) #如果key存在的话,更新,如果key不存在的话,添加进去
print(d)
fromkeys:需求是快速新造出一个字典,value的初始值全都为None,而key是来自于一个列表
复杂方法
keys=['name','age','sex']
d={}
for k in keys:
d[k]=None #字典中不存在该key,直接添加
print(d)
简单方法
d={}.fromkeys(keys,None)
print(d)
setdefault方法:
d = {"x": 1, "y": 2}
print(d.setdefault("s")) #如果key不存在于字典中,将会添加键并将值设为默认值:None
print(d) #{'x': 1, 'y': 2, 's': None}
按照默认的操作形式:
d['x']=1111 # key存在则修改
d['z']=1111 # key不存在则新增
按照setdefault的形式:
d={"x":1,"y":2}
res=d.setdefault('x',11111) # 在key存在的情况下不修改值,会返回原值
res=d.setdefault('s',11111) #{'x': 1, 'y': 2, 's': 11111},key不存在,添加
print(d) #{'x': 1, 'y': 2},setdefault方法,key存在,不会修改key对应的值,即什么也不做
print(res)
#1,是key'x'对应的value,为1
练习:用字典的形式表示出各个元素出现的次数
s = 'hello alex alex say hello sb sb'
d = {}
words = s.split()
words=['hello', 'alex', 'alex', 'say', 'hello', 'sb', 'sb']
for word in words: # word= 'alex'
# d[word]=words.count(word) #d['alex']=words.count('alex')
d.setdefault(word, words.count(word)) #用setdefault方法,第二次出现的元素不会加入字典,什么也不会做。
print(d) # {'hello': 2, 'alex': 2, 'say': 1, 'sb': 2}
集合类型:
用循环求出两个列表的交集:
1 pythons=['egon','张铁蛋','李铜蛋','赵银弹','王金蛋','艾里克斯']
2 linuxs=['欧德博爱','李铜蛋','艾里克斯','lsb','ysb','wsb']
3 l=[]
4 for stu in pythons:
5 if stu in linuxs:
6 l.append(stu)
7 print(l)
1. 什么是集合
在{}内用逗号分隔开多个值,集合的特点:
1. 每个值必须是不可变类型
2. 集合无序
3. 集合内元素不能重复
2. 为何要用集合
1. 用于做关系运算
2. 去重
3. 如何用集合
s={1,1.3,'aa',[1,2,]} #报错,不能存放可变类型[1,2,]是可变类型
s={1,1.3,'aa'}
print(s)
s={1,1,1,1,1,1,1,2} #s=set(....)
print(type(s))
print(s)
d={'x':1,'x':2,'x':3} #字典无序,后面的会将前面的覆盖
print(d)
res=set('hello')
res=set([1,2,['a','b']]) #报错,集合不能存放可变类型
print(res) #{'h', 'e', 'o', 'l'}for循环遍历之后,去重
集合的第一大用途: 关系运算
pythons={'egon','张铁蛋','李铜蛋','赵银弹','王金蛋','艾里克斯'}
linuxs={'欧德博爱','李铜蛋','艾里克斯','lsb','ysb','wsb'}
1 .求同时报名两门课程的学生姓名:交集
print(pythons & linuxs)
2 求报名老男孩学校课程的所有学生姓名:并集
print(pythons | linuxs)
3 求只报名python课程的学生姓名: 差集
print(pythons - linuxs)
print(linuxs - pythons) #求只报名linux课程的学生姓名
4 求没有同时报名两门课程的学生姓名: 对称差集
print((pythons - linuxs) | (linuxs - pythons))
print(pythons ^ linuxs)
5 父子集:指的是一种包含与被包含的关系
s1={1,2,3}
s2={1,2}
print(s1 >= s2)
情况一:
print(s1 > s2) #>号代表s1是包含s2的,称之为s1为s2的父集
print(s2 < s1)
情况二:
s1={1,2,3}
s2={1,2,3}
print(s1 == s2) #s1如果等于s2,也可以称为s1是s2的父集合
综上:
s1 >= s2 就可以称为s1是s2的父集
s3={1,2,3}
s4={3,2,1}
print(s3 == s4)
s5={1,2,3}
s6={1,2,3}
print(s5 >= s6)
print(s6 >= s5)
集合的第二大用途:去重
集合去重的局限性:
1. 会打乱原值的顺序
2. 只能针对不可变的值去重
stus=['egon','lxx','lxx','alex','alex','yxx']
new_l=list(set(stus)) #先生成字典,再转换成列表,去重,打乱顺序
print(new_l)
old_l=[1,[1,2],[1,2]] #报错,不能存储可变类型,应该将列表改为元组
set(old_l)
去重:
l=[ {'name':'egon','age':18,'sex':'male'}, {'name':'alex','age':73,'sex':'male'}, {'name':'egon','age':20,'sex':'female'}, {'name':'egon','age':18,'sex':'male'}, {'name':'egon','age':18,'sex':'male'}, ] new_l=[] for dic in l: if dic not in new_l: new_l.append(dic) print(new_l)
需要掌握的操作:
s1={1,2,3} s1.update({3,4,5}) #合并去重 print(s1) print(s1.pop()) #随机去除并返回 print(s1)
s1.remove(2) #从集合中删除2
s1={1,2,3}
print(id(s1))
s1.add(4) #添加元素
print(s1)
rint(id(s1)) #id不会发生改变
s1={1,2,3}
s1.discard(4) #删除一个集合中存在的元素,如果不存在,什么也不做
s1.remove(4) #报错,因为不存在,所以不能删除
print(s1)
s1={1,2,3}
s2={4,5}
print(s1.isdisjoint(s2)) #如果没有交集返回True
总结
存多个值
无序
set可变