转载自:https://www.cnblogs.com/Yemilice/p/6201224.html
今天群里有个人反映某个网址爬出来的网页源代码出现中文乱码,我研究了半天,终于找到了解决方法。
一开始,我是这样做的:

import requests url = 'http://search.51job.com/jobsearch/search_result.php?fromJs=1&jobarea=090200%2C00&funtype=0000&industrytype=00&keyword=python&keywordtype=2&lang=c&stype=2&postchannel=0000&fromType=1&confirmdate=9' print requests.get(url).content
这样做,如果用命令行去运行,得到的内容中文显示正常,但如果用pycharm运行得到的确实乱码。
这个问题我一时半会还不知道是为什么,如果有人知道,请告诉我,谢谢!
后来,我在网上查阅资料,发现可以通过下面这种方式解决中文乱码问题:
首先,我们在浏览器中打开网址,通过查看源代码可以发现这个网址采用的编码是GBK:
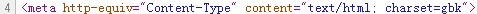
然后我们通过下面这段代码发现通过requests获取的编码不是GBK,而是ISO-8859-1。
import requests url = 'http://search.51job.com/jobsearch/search_result.php?fromJs=1&jobarea=090200%2C00&funtype=0000&industrytype=00&keyword=python&keywordtype=2&lang=c&stype=2&postchannel=0000&fromType=1&confirmdate=9' print requests.get(url).encoding
所以打印出来的就是乱码,我们需要将编码改为GBK才可以:
import requests url = 'http://search.51job.com/jobsearch/search_result.php?fromJs=1&jobarea=090200%2C00&funtype=0000&industrytype=00&keyword=python&keywordtype=2&lang=c&stype=2&postchannel=0000&fromType=1&confirmdate=9' r = requests.get(url) r.encoding = 'GBK' print r.text
这样做,无论你是用pycharm还是命令行去运行,得到的都是正常的中文了