常用命令
# 查看所有数据库
show databases;
# 进入某个数据库 use 数据库; # 展示所有表 show tables; # 显示表结构 desc 表名; # 显示表名的分区 show partitions 表名; # 显示创建表的结构 show create table_name; # 建表语句 # 内部表 use xxdb; create table xxx; # 创建一个表,结构与其他一样 create table xxx like xxx; # 外部表 use xxdb; create external table xxx; # 分区表 use xxdb; create external table xxx (l int) partitoned by (d string) # 内外部表转化 alter table table_name set TBLPROPROTIES ('EXTERNAL'='TRUE'); # 内部表转外部表 alter table table_name set TBLPROPROTIES ('EXTERNAL'='FALSE');# 外部表转内部表 # 表结构修改 # 重命名表 use xxxdb; alter table table_name rename to new_table_name; # 增加字段 alter table table_name add columns (newcol1 int comment ‘新增’); # 修改字段 alter table table_name change col_name new_col_name new_type; # 删除字段(COLUMNS中只放保留的字段) alter table table_name replace columns (col1 int,col2 string,col3 string); # 删除表 use xxxdb; drop table table_name; # 删除分区 # 注意:若是外部表,则还需要删除文件(hadoop fs -rm -r -f hdfspath) alter table table_name drop if exists partitions (d=‘2016-07-01');
#从文件加载数据进表(OVERWRITE覆盖,追加不需要OVERWRITE关键字)
LOAD DATA LOCAL INPATH 'dim_csl_rule_config.txt' OVERWRITE into table dim.dim_csl_rule_config;
#从查询语句给table插入数据
INSERT OVERWRITE TABLE test_h02_click_log PARTITION(dt) select *
from stage.s_h02_click_log where dt='2014-01-22' limit 100;
#使用truncate仅可删除内部表数据,不可删除表结构 (truncate可删除所有的行,但是不能删除外部表)
truncate table 表名
#使用shell命令删除外部表
hdfs -dfs -rm -r 外部表路径
#使用 drop 可删除整个表
drop table 表名
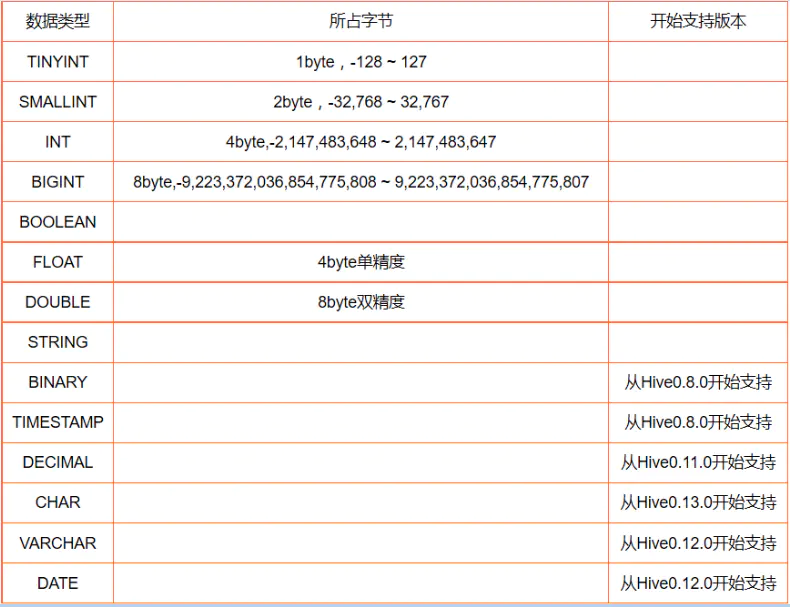
数据类型
1)基础数据类型
注:
binary:二进制类型。
timestamp:带可选的纳秒级精度UNIX timestamp。timestamp与时区无关,存储为UNIX纪元的偏移量。Hive提供了用于 timestamp和时区相互转换的便利UDF:to_utc_timestamp和 from_utc_timestamp。 Timestamp类型可以使用所有的日期时间UDF,如month、day、year等。文本文件中的Timestamp必须使用yyyy-mm-dd hh:mm:ss[.f...]的格式,如果使用其它格式,将它们声明为合适的类型(INT、FLOAT、STRING等)并使用UDF将它们转换为 Timestamp。其支持的类型为:
整数类型:转换为秒级的UNIX时间戳。
浮点数类型:转换为带小数精度的UNIX时间戳。
字符串类型:适合java.sql.Timestamp格式"YYYY-MM-DD HH:MM:SS.fffffffff"(9位小数精度)。
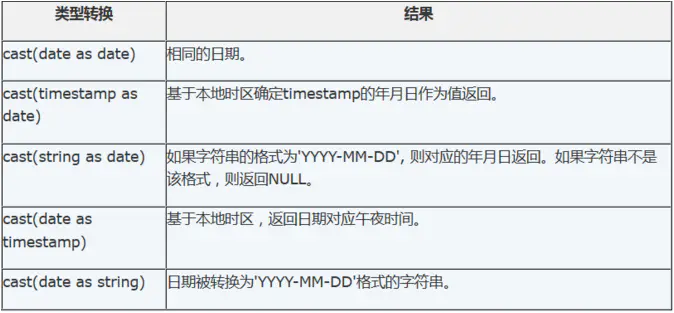
Date:描述了特定的年月日,以YYYY-MM-DD格式表示,例如2014-05-29。仅可与Date、timestamp和String相互转化。
2)复杂数据类型
复杂数据类型包括:ARRAY、Map、struct、union,这些复杂类型是由基础类型构成的
ARRAY:ARRAY类型是由一系列相同数据类型的元素组成,这些元素可以通过下标来访问。比如有一个ARRAY类型的变量fruits,它是由 ['apple','orange','mango']组成,那么我们可以通过fruits[1]来访问元素orange,因为ARRAY类型的下标是从 0开始的;
MAP:MAP包含key->value键值对,可以通过key来访问元素。比如”userlist”是一个map类型,其中username是 key,password是value;那么我们可以通过userlist['username']来得到这个用户对应的password;
STRUCT:STRUCT可以包含不同数据类型的元素。这些元素可以通过”点语法”的方式来得到所需要的元素,比如user是一个STRUCT类型,那么可以通过user.address得到这个用户的地址。
UNION:UNIONTYPE,他是从Hive 0.7.0开始支持的。
Hive实现update和delete
Hive自0.14版本开始支持update和delete,要执行update和delete的表必须支持ACID
一个表要实现update和delete功能,该表就必须支持ACID,而支持ACID,就必须满足以下条件:
1、表的存储格式必须是ORC(STORED AS ORC);
2、表必须进行分桶(CLUSTERED BY (col_name, col_name, ...) INTO num_buckets BUCKETS);
3、Table property中参数transactional必须设定为True(tblproperties('transactional'='true'));
4、以下配置项必须被设定:
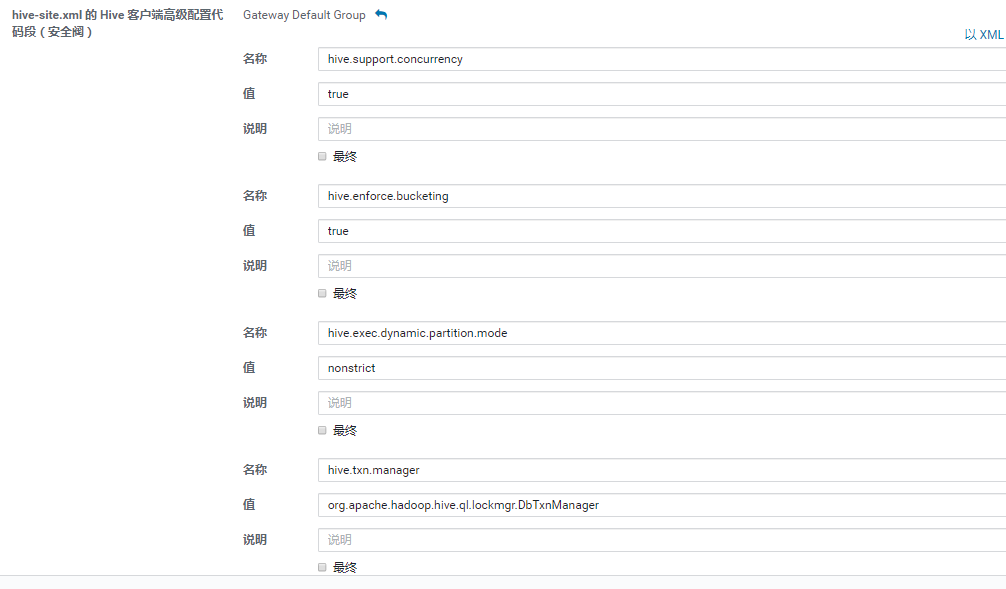
Client端:
- hive.support.concurrency – true
- hive.enforce.bucketing – true
- hive.exec.dynamic.partition.mode – nonstrict
- hive.txn.manager – org.apache.hadoop.hive.ql.lockmgr.DbTxnManager
服务端:
- hive.compactor.initiator.on – true
- hive.compactor.worker.threads – 1
- hive.txn.manager – org.apache.hadoop.hive.ql.lockmgr.DbTxnManager(经过测试,服务端也需要设定该配置项)
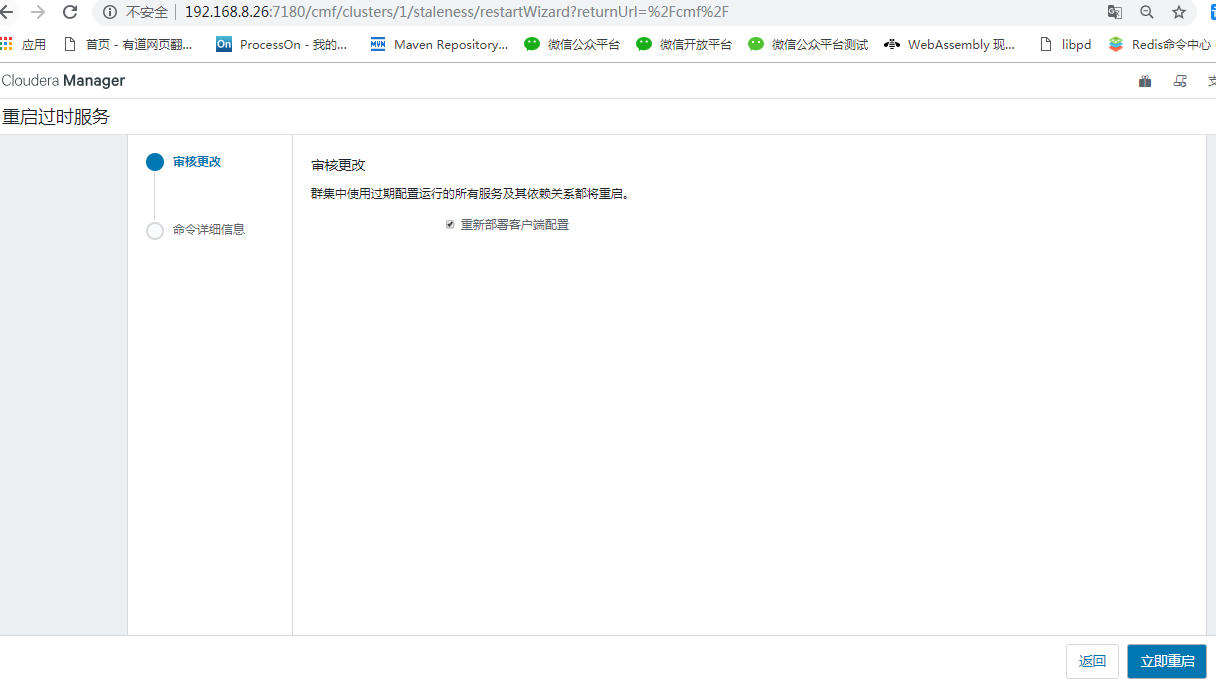
注意:上述配置项必须区分Client端和服务端。在Cloudera Manager上可以分别添加(hive—>配置—>高级),在更新部署配置信息的时候需要勾选部署客户端配置(默认是勾选的)。


保存修改后