hadoop版本:hadoop-2.8.2.tar.gz
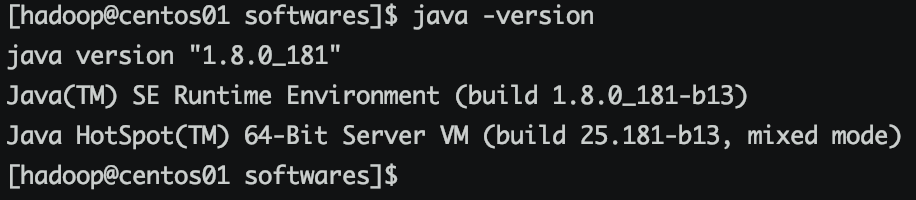
服务器已安装java
服务器已关闭防火墙

已创建用户hadoop,并赋予sudo权限,以下操作均已hadoop用户
虚拟机3台 192.168.0.171~173 (centos01~03)
一、上传hadoop,并解压,先在centos01节点上操作
1、创建文件夹 /opt/software /opt/modules
sudo mkdir /opt/software
sudo mkdir /opt/modules
2、设置新建2个目录的所有者和组为用hadoop和组hadoop
sudo chmod -R hadoop:hadoop /opt/software
sudo chmod -R hadoop:hadoop /opt/modules

3、将hadoop-2.8.2.tar.gz 上传到 /opt/softwares目录,并解压
cd /opt/softwares tar -zxf hadoop-2.8.2.tar.gz -C /opt/modules

二、配置系统环境变量
修改/etc/profile文件
sudo vi /etc/profile
文件末尾加入
export HADOOP_HOME=/opt/modules/hadoop-2.8.2 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
刷新profile,使配置生效
source /etc/profile
执行hadoop
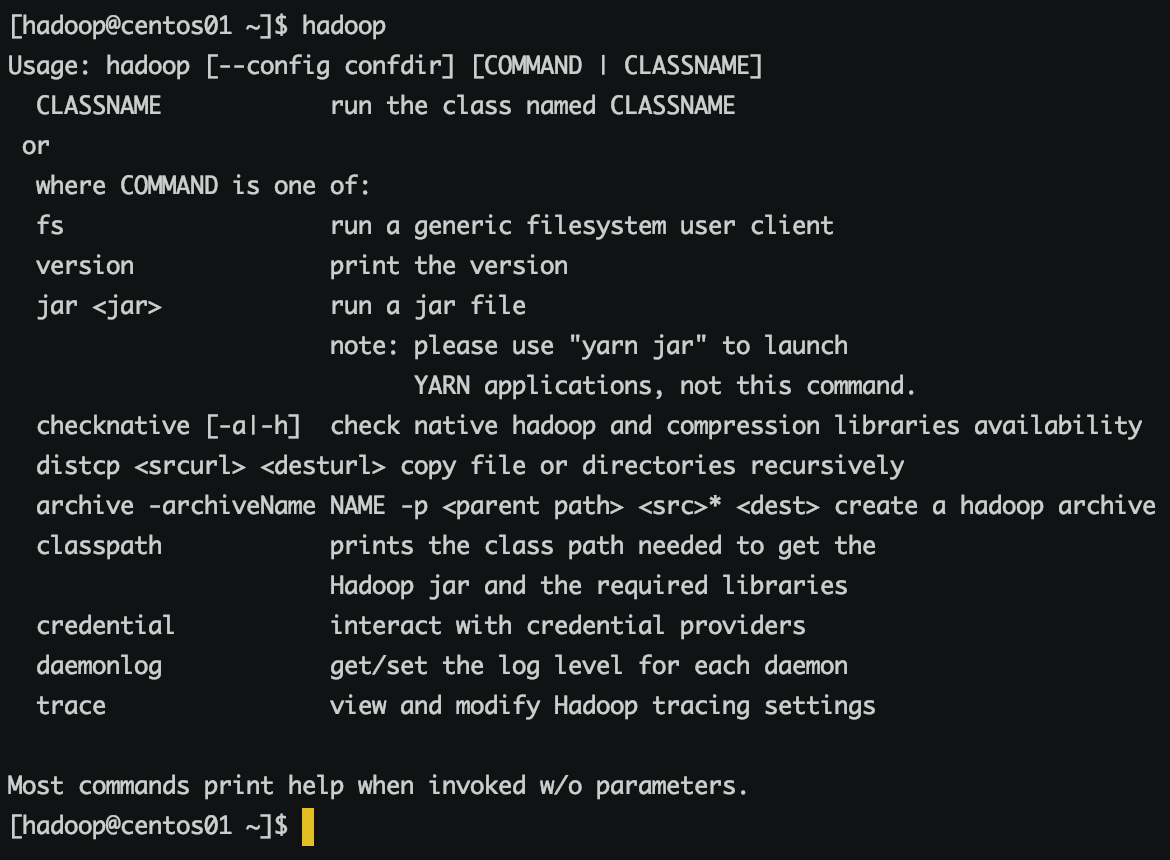
三、配置hadoop环境变量
所有hadoop配置文件都在安目录的 etc/hadoop中
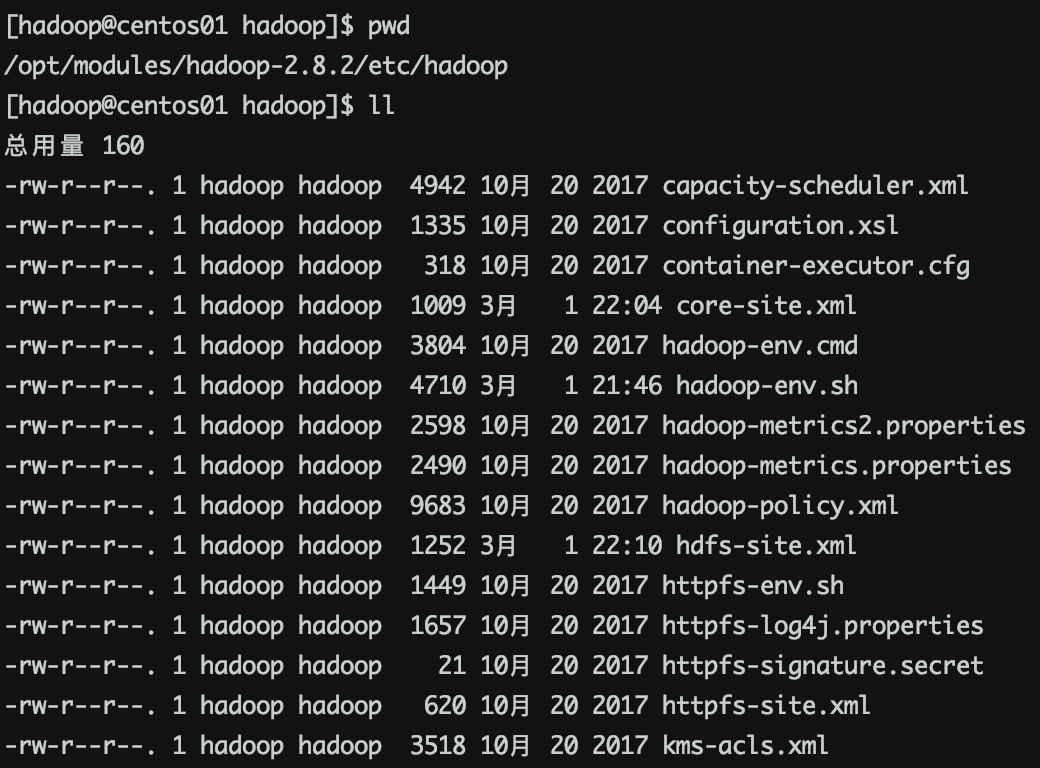
修改以下三个文件
hadoop-env.sh mapred-env.sh yarn-env.sh
加入java路径
export JAVA_HOME=/opt/modules/jdk1.8.0_181
四、配置HDFS
1、修改 core-site.xml 加入
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos01:9000</value>
</property>
<property>
<name>hadoop.temp.dir</name>
<value>file:/opt/modules/hadoop-2.8.2/tmp</value>
</property>
</configuration>
fs.defaultFS HDFS默认访问路径
hadoop.temp.dir Hadoop数据缓存路径
2、修改 hdfs-site.xml 加入
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/modules/hadoop-2.8.2/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/modules/hadoop-2.8.2/tmp/dfs/data</value>
</property>
</configuration>
dfs.replication 文件在hdfs系统中的副本数
dfs.permissions.enabled 是否检查用户权限
dfs.namenode.name.dir NameNode节点数据在本地文件系统存放位置
dfs.datanode.data.dir DataNode节点数据在本地文件系统存放位置
3、修改 slaves 文件 ,将3个主机名添加进去(也能将IP放入,没有测试),一个一行
centos01
centos02
centos03
五、配置YARN
1、复制 mapred-site.xml.template 名字为 mapred-site.xml,添加内容,指定任务执行框架为YARN
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2、修改 yarn-site.xml 加入
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
yarn.nodemanager.aux-services 在NodeManager上运行附属服务,需要配置成mapreduce_shuffle才能运行MapReduce
六、复制hadoop安装文件到其它主机
在一个节点上安装后,复制到其他节点, 在centos01 /opt/modules/ 位置上执行
scp -r ./hadoop-2.8.2/ hadoop@centos02:/opt/modules/ scp -r ./hadoop-2.8.2/ hadoop@centos03:/opt/modules/
七、格式化NameNode
hadoop启动前需要格式化namenode,格式化namenode可以初始化HDFS文件系统和目录
在centos01上执行 *在namenade所在的节点上处理
hadoop namenode -format
执行后存在这句话,执行成功
common.Storage: Storage directory /opt/modules/hadoop-2.8.2/tmp/dfs/name has been successfully formatted.

八、启动hadoop
在centos01上启动集群
sh /opt/modules/hadoop-2.8.2/sbin/start-all.sh
日志文件 /opt/modules/hadoop-2.8.2/logs/ sh脚本命令位置 /opt/modules/hadoop-2.8.2/sbin 启动hadoop集群 start-all.sh 单独启动HDFS集群 start-dfs.sh 单独启动YARN集群 start-yarn.sh
单独启动NameNode进程
hadoop-daemon.sh start namenode
hadoop-daemon.sh stop namenode
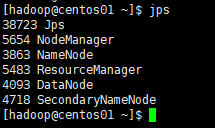
九、查看各节点启动进程
jps