Kaggle(一) 房价预测 (随机森林、岭回归、集成学习)
代码有不明白的 欢迎来微信公众号“他她自由行”找我,回复任何话都可以 我都会回你哒~
项目介绍:通过79个解释变量描述爱荷华州艾姆斯的住宅的各个方面,然后通过这些变量训练模型,
来预测房价。
kaggle项目链接:https://www.kaggle.com/c/house-prices-advanced-regression-techniques
数据描述:
train.csv - 训练集
test.csv - 测试集
一.加载数据
#加载必要库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
#读取数据集
df_train=pd.read_csv('train.csv')
df_test=pd.read_csv('test.csv')
二.数据清洗
把train与test两个数据集合并到一起来处理79个解释变量,等用test来进行预测时就不需再次处理了。
df_train.shape,df_test.shape
y_train=df_train.pop('SalePrice') #删除并返回数据集中SalePrice标签列
all_df=pd.concat((df_train,df_test),axis=0) #要处理的整体数据集
total=all_df.isnull().sum().sort_values(ascending=False) #每列缺失数量
percent=(all_df.isnull().sum()/len(all_df)).sort_values(ascending=False) #每列缺失率
miss_data=pd.concat([total,percent],axis=1,keys=['total','percent'])
miss_data #显示每个列及其对应的缺失率
1.除去缺失率达40%以上的 (不除去的话,补齐数据误差偏大)
all_df=all_df.drop(miss_data[miss_data['percent']>0.4].index,axis=1) #去除了percent>0.4的列
2. 由于有些房子没有车库,造成车库相关的属性缺失,对于这种情况,我们有missing填充,同时对于车库建造时间的缺失,我们用1900填充,表示车库是年久的,使其变得不重要。
garage_obj=['GarageType','GarageFinish','GarageQual','GarageCond'] #列出车库这一类
for garage in garage_obj:
all_df[garage].fillna('missing',inplace=True)
#把1900标签填入空缺处表示年代久远
all_df['GarageYrBlt'].fillna(1900.,inplace=True)
3.装修类中,装修类型为空的表示没装修过,用missing表示;装修面积为0;
all_df['MasVnrType'].fillna('missing',inplace=True) #用missing标签表示没装修过
all_df['MasVnrArea'].fillna(0,inplace=True) #用0表示没装修过的装修面积
#再次查看数据缺失率,最高为0.16,是LotFrontage列
(all_df.isnull().sum()/len(all_df)).sort_values(ascending=False)
#从图中看出LotFrontage分布较均匀,可以用均值补齐缺失值
plt.figure(figsize=(16,6))
plt.plot(all_df['Id'],all_df['LotFrontage'])
图一:
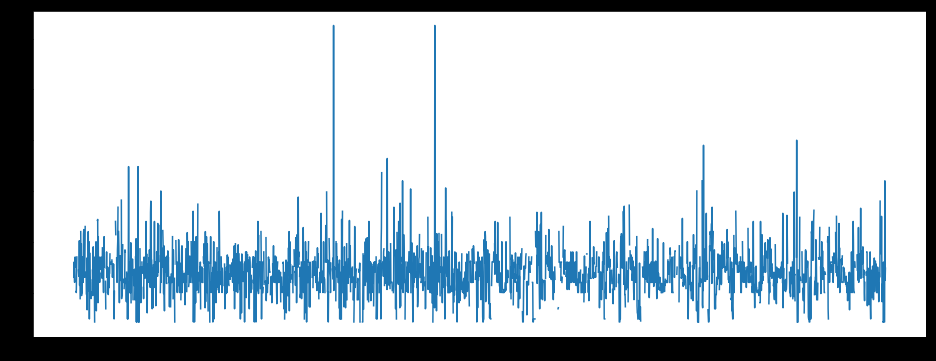
#均值补齐LotFrontage列
all_df['LotFrontage'].fillna(all_df['LotFrontage'].mean(),inplace=True)
4.离散值进行one-hot处理
#还有部分少量的缺失值,不是很重要,可以用one-hotd转变离散值,然后均值补齐
all_dummies_df=pd.get_dummies(all_df)
mean_col=all_dummies_df.mean()
all_dummies_df.fillna(mean_col,inplace=True)
三.数值转换
找出类型为数值的所有列,进行标准化处理
#数据集中数值类型为int和float
all_dummies_df['Id']=all_dummies_df['Id'].astype(str) #先排除ID列,不对Id列进行处理
a=all_dummies_df.columns[all_dummies_df.dtypes=='int64'] #数值为int型
b=all_dummies_df.columns[all_dummies_df.dtypes=='float64'] #数值为float型
#进行标准化处理,符合0-1分布
a_mean=all_dummies_df.loc[:,a].mean()
a_std=all_dummies_df.loc[:,a].std()
all_dummies_df.loc[:,a]=(all_dummies_df.loc[:,a]-a_mean)/a_std #使数值型为int的所有列标准化
b_mean=all_dummies_df.loc[:,b].mean()
b_std=all_dummies_df.loc[:,b].std()
all_dummies_df.loc[:,b]=(all_dummies_df.loc[:,b]-b_mean)/b_std #使数值型为float的所有列标准化
最终处理完的数据集:
其中包含自己把train数据集中按0.8:0.2分为train_train和train_test俩数据集,来比较哪个模型能更好预测数据,然后再用来预测最终的test数据集。
#处理后的训练集(不含Saleprice)
df_train1=all_dummies_df.iloc[:1460,:]
df_train_train=df_train1.iloc[0:int(0.8*len(df_train1)),:] #train中的训练集(不含Saleprice)
df_train_test=df_train1.iloc[int(0.8*len(df_train1)):,:] #train中的测试集(不含Saleprice)
df_train_train_y=y_train.iloc[0:int(0.8*len(y_train))] #train中训练集的target
df_train_test_y=y_train.iloc[int(0.8*len(df_train1)):] #train中测试集的target
#处理后的测试集
df_test1=all_dummies_df.iloc[1460:,:]
四.建模
分析,显然是回归问题,本项目中解决回归问题的方法:岭回归、随机森林、集成学习
1.岭回归
这里要用的特征较多,适合岭回归进行建模,把所有特征放进去就行,无需进行特征选取
#加载相关库
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
#对岭回归的正则化度进行调参,用到k折交叉验证
alphas=np.logspace(-2,2,50)
test_scores1=[]
test_scores2=[]
for alpha in alphas:
clf=Ridge(alpha)
scores1=np.sqrt(cross_val_score(clf,df_train_train,df_train_train_y,cv=5))
scores2=np.sqrt(cross_val_score(clf,df_train_train,df_train_train_y,cv=10))
test_scores1.append(1-np.mean(scores1))
test_scores2.append(1-np.mean(scores2))
#从图中找出当正则化参数alpha为多少时,误差最小
%matplotlib inline
plt.plot(alphas,test_scores1,color='red') #交叉验证k为5时,误差最小
plt.plot(alphas,test_scores2,color='green')
图二
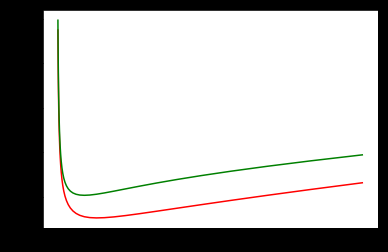
当alpha在0~10之间时,整体结构风险最小。(猜测可能在alpha=5时最小
训练好的岭回归对train_test进行预测,用误差平方和来衡量模型好坏
ridge=Ridge(alpha=5)
ridge.fit(df_train_train,df_train_train_y)
#用均方误差来判断模型好坏,结果越小越好
(((df_train_test_y-ridge.predict(df_train_test))**2).sum())/len(df_train_test_y)
Out[ ]:
1983899445.438339
2.随机森林
随机森林也可预测回归,对处理高维度效果较好,不要特征选择
#调参,对随机森林的最大特征选择进行调试 ,也需要用到交叉验证
from sklearn.ensemble import RandomForestRegressor
max_features=[.1,.2,.3,.4,.5,.6,.7,.8,.9]
test_score=[]
for max_feature in max_features:
clf=RandomForestRegressor(max_features=max_feature,n_estimators=100)
score=np.sqrt(cross_val_score(clf,df_train_train,df_train_train_y,cv=5))
test_score.append(1-np.mean(score))
plt.plot(max_features,test_score) #得出误差得分图
图三
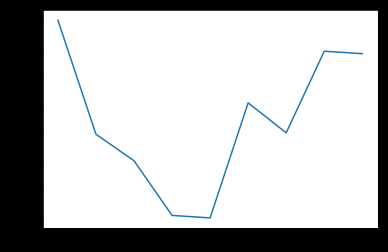
通过图可知,当max_features最大特征数为0.5时,误差最小,所以代入max_feature=0.5
训练好的随机森林对train_test进行预测,用误差平方和来衡量模型好坏
rf=RandomForestRegressor(max_features=0.5,n_estimators=100)
rf.fit(df_train_train,df_train_train_y)
#用均方误差来判断模型好坏,结果越小越好
(((df_train_test_y-rf.predict(df_train_test))**2).sum())/len(df_train_test_y)
Out[ ]:
1108361750.5652797
集成学习
用Bagging(bootstrap aggregatin)集成框架来对岭回归进行融合计算
调参1:寻找合适子模型数量
#加载相关库
from sklearn.ensemble import BaggingRegressor
#调参,寻找合适子模型数量
ridge=Ridge(5)
params=[10,20,30,40,50,60,70,80,90,100]
test_scores=[]
for param in params:
clf=BaggingRegressor(n_estimators=param,base_estimator=ridge)
score=np.sqrt(cross_val_score(clf,df_train_train,df_train_train_y,cv=5))
test_scores.append(1-np.mean(score))
plt.plot(params,test_scores)
图四
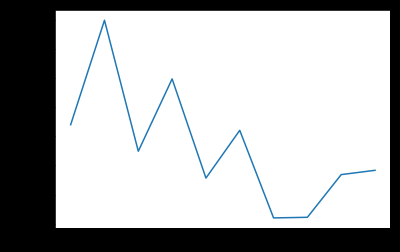
当训练的模型个数为70时,数据误差最小
调参2:寻找合适最大特征数
max_features=[.1,.2,.3,.4,.5,.6,.7,.8,.9]
test_scores=[]
for max_feature in max_features:
clf=BaggingRegressor(n_estimators=70,base_estimator=ridge,max_features=max_feature)
score=np.sqrt(cross_val_score(clf,df_train_train,df_train_train_y,cv=5))
test_scores.append(1-np.mean(score))
plt.plot(max_features,test_scores)
图五
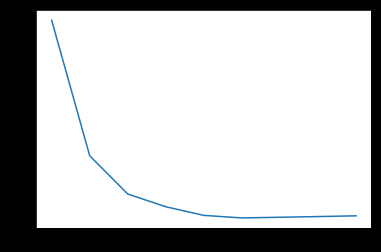
最大特征数为0.6时,误差最小
调参结束,进行模型检验
Bagging=BaggingRegressor(n_estimators=70,base_estimator=ridge,max_features=0.6)
Bagging.fit(df_train_train,df_train_train_y)
#用均方误差来判断模型好坏,结果越小越好
(((df_train_test_y-Bagging.predict(df_train_test))**2).sum())/len(df_train_test_y)
Out[ ]:
1960180964.6378567
结果:
分析结果:三个结果,取均方误差最小的,即 随机森林 算法
提交后,误差为0.1485
四千多中排名50%。还有很多可以优化的地方,等过段时间继续优化~
更详细代码:github https://github.com/xubin97/Data-Mining_exp2/tree/master