很多人都会MySQL主从框架的搭建,但很多人没有真正理解同步基本用途、同步的基本原理,还有当Master和Slave同步断开后的处理以及导致Master和slave不同步的原因等等,当你对这些都了如指掌的时候,对于MySQL主从出现的一些常见问题,也能很轻松的解决它,而且对数据库架构的优化及改造都会有很大的帮助。下面我们一起来学习下MySQL Replication吧,^0^
Replication的用途:
1、数据分发,scale out,sacle up,垂直划分,水平划分
2、负载均衡 load balance
3、备份,一般不会用作备份,一旦执行delete操作,replication也不会保留
4、实现数据的高可用
5、可以在不同的主从库上使用不同的存储引擎
6、测试MySQL的升级
常见的MySQL Replication的架构有:

MySQL一主多从,实现读写分离的框架图:

常见的负载均衡架构:
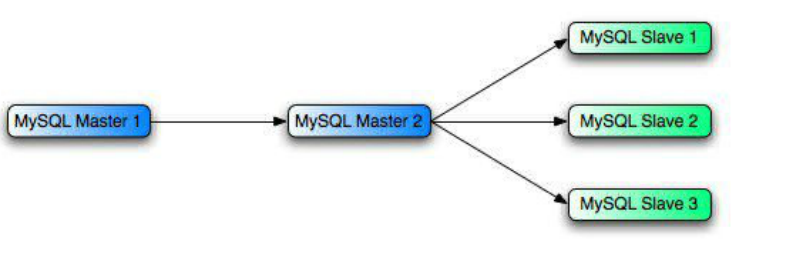
当使用的slave过多,减轻Mater压力的级联架构,Master2打开log-slave-updates配置
一台Master down时候的冗余架构:

Replication不同的库到不同的主机:

原理:
1、三个进程:
MySQL的复制(relication)是一个异步的复制,从一个Master复制到另一个Slave。实现整个复制操作主要由三个进程完成的,其中两个进程在Slave上(Sql进程和IO进程),另外一个进程在Master上(IO进程),如果replication在进行的话,在Master上可以通过运行show processlist查看,在Slave上可以执行show slave status进行查看,里面的Slave_IO_Running:No
Slave_SQL_Running:No
是两个进程的状态是否运行。
2、三个log文件和两个info文件:
复制进行时,在Master上执行的语句会记录到bin.log里面,日志的位置和数字,当有变化发生时,slave会通过现代战争io进程读取master的二进制log,发现有变化时,会把新的变化复制到它的relay.log(中继日志),会记录行的位置和数据到一个新的文件叫master.info,继续检查master的二进制log,当slave的sql进程发现在relay.log里有变化时候会执行,同时slave也会通过sql进程去对比Master和Slave的变化,如果对比发现不一致,复制进程会停止并把错误信息计入slave的error.log,如果结果对得上,一个新的日志的位置和数字会记录到relay-log.info文件,slave会等另一个变化到relay.log文件。


3、复制的基本过程如下:
简单的讲就是Mster记录其变化到binlog,Slave接收到的变化会记录到他的Relay log,slave通过重放relay log,然后写进自己的log
1)、Slave上面的IO进程连接上Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
2)、Master接收到来自Slave的IO进程的请求后,通过负责复制的IO进程根据请求信息读取指定日志的指定位置之后的日志信息,返回给Slave的IO进程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息已经到Master端的bin-log文件的名称以及bin-log的位置;
3)、Slave的IO进程接收到信息后,将接收到的日志内容依次添加到Slave端的relay-log文件的最末端,并将读取到的Master端的bin-log的文件名和位置记录到master-info文件中,以便在下次读取的时候能够清楚的告诉Master"我需要从某个bin-log的哪个位置开始往后的日志内容,请发给我";
4)、Slave的Sql进程检测到relay-log中新增加了内容后,会马上解析relay-log的内容成为在Master端真实执行时的那些可执行的内容,并在自身执行;
4、Replication的两种复制级别:
Statement level级别 MySQL 3.23后:
每一条修改数据的query都会记录到master的binary log中,slave复制时候sql线程会解析成合原来的master端执行过的相同的query。
优点是:不需记录每条变化,减少log,节省IO。
缺点是:必须每条语句相关信息,即上下文信息。
Row level级别5.1以后:
Binaty log会记录成每一行数据被修改的形式,然后在slave端口对相同的数据进行修改,锁表操作会大量减少。
优点:不需要记录执行query语句的上下文信息,只需要记录那条被修改了,修改了什么了。
缺点是:产生的log记录比较大
还有一种不常用的mixed级别。
5、导致master和slave不同步的原因
1)、delete update 改变行的时候不使用limit语句,没有order by
2)、一些函数在使用statements based replication 时候如下:
Load_file,User,Found_rows,UUID,UUID_SHORT,SYSDATE()
3)、不用使用临时表,当slave crash掉或者重启后,后丢失信息
4)、slave down掉
5)、使用replicate-ignore-db 和 binlog-ignore-db
6)、错误的binlog执行sql导致binlog堵上,具体详细内容可以参考:http://dev.mysql.com/doc/refman/5.0/en/replication.html
6、MySQL replication的历史
mysql版本的4.0-5.0:

MySQL 5.1


总结:
一、通过MySQL Replication原理的学习,可以清楚理解到数据是怎么从Master库同步到Slave库的,什么情况会导致同步断开等。
二、通过MySQL Replication架构的学习,可以根据线上及业务需要选择合适自己业务的架构,提高数据的安全性及访问的效率。
详细内容可以参考大牛的博客: http://ourmysql.com/archives/876
|
作者:陆炫志 出处:xuanzhi的博客 http://www.cnblogs.com/xuanzhi201111 您的支持是对博主最大的鼓励,感谢您的认真阅读。本文版权归作者所有,欢迎转载,但请保留该声明。 |