模型文件
tensorflow 训练保存的模型注意包含两个部分:网络结构和参数值。
.meta
.meta 文件以 “protocol buffer”格式保存了整个模型的结构图,模型上定义的操作等信息。
查看 meta 文件中所有的操作信息:


# ================================================================ # # 列出 meta 中所有操作 # # ================================================================ # saver = tf.train.import_meta_graph('./my_model_final.ckpt.meta') for op in tf.get_default_graph().get_operations(): print("oprator_name: ", op.name) """ oprator_name: input/X oprator_name: input/y oprator_name: input/is_training oprator_name: hidden1/kernel/Initializer/truncated_normal/shape oprator_name: hidden1/kernel/Initializer/truncated_normal/mean oprator_name: hidden1/kernel/Initializer/truncated_normal/stddev oprator_name: hidden1/kernel/Initializer/truncated_normal/TruncatedNormal oprator_name: hidden1/kernel/Initializer/truncated_normal/mul oprator_name: hidden1/kernel/Initializer/truncated_normal oprator_name: hidden1/kernel oprator_name: hidden1/kernel/Assign oprator_name: hidden1/kernel/read oprator_name: hidden1/bias/Initializer/zeros oprator_name: hidden1/bias oprator_name: hidden1/bias/Assign oprator_name: hidden1/bias/read oprator_name: dnn/hidden1/MatMul oprator_name: dnn/hidden1/BiasAdd oprator_name: batch_normalization/gamma/Initializer/ones oprator_name: batch_normalization/gamma oprator_name: batch_normalization/gamma/Assign oprator_name: batch_normalization/gamma/read oprator_name: batch_normalization/beta/Initializer/zeros oprator_name: batch_normalization/beta oprator_name: batch_normalization/beta/Assign oprator_name: batch_normalization/beta/read oprator_name: batch_normalization/moving_mean/Initializer/zeros oprator_name: batch_normalization/moving_mean oprator_name: batch_normalization/moving_mean/Assign oprator_name: batch_normalization/moving_mean/read oprator_name: batch_normalization/moving_variance/Initializer/ones oprator_name: batch_normalization/moving_variance oprator_name: batch_normalization/moving_variance/Assign oprator_name: batch_normalization/moving_variance/read oprator_name: dnn/batch_normalization/batchnorm/add/y oprator_name: dnn/batch_normalization/batchnorm/add oprator_name: dnn/batch_normalization/batchnorm/Rsqrt oprator_name: dnn/batch_normalization/batchnorm/mul oprator_name: dnn/batch_normalization/batchnorm/mul_1 oprator_name: dnn/batch_normalization/batchnorm/mul_2 oprator_name: dnn/batch_normalization/batchnorm/sub oprator_name: dnn/batch_normalization/batchnorm/add_1 oprator_name: dnn/swish_f32 oprator_name: hidden2/kernel/Initializer/truncated_normal/shape oprator_name: hidden2/kernel/Initializer/truncated_normal/mean oprator_name: hidden2/kernel/Initializer/truncated_normal/stddev oprator_name: hidden2/kernel/Initializer/truncated_normal/TruncatedNormal oprator_name: hidden2/kernel/Initializer/truncated_normal/mul oprator_name: hidden2/kernel/Initializer/truncated_normal oprator_name: hidden2/kernel oprator_name: hidden2/kernel/Assign oprator_name: hidden2/kernel/read oprator_name: hidden2/bias/Initializer/zeros oprator_name: hidden2/bias oprator_name: hidden2/bias/Assign oprator_name: hidden2/bias/read oprator_name: dnn/hidden2/MatMul oprator_name: dnn/hidden2/BiasAdd oprator_name: batch_normalization_1/gamma/Initializer/ones oprator_name: batch_normalization_1/gamma oprator_name: batch_normalization_1/gamma/Assign oprator_name: batch_normalization_1/gamma/read oprator_name: batch_normalization_1/beta/Initializer/zeros oprator_name: batch_normalization_1/beta oprator_name: batch_normalization_1/beta/Assign oprator_name: batch_normalization_1/beta/read oprator_name: batch_normalization_1/moving_mean/Initializer/zeros oprator_name: batch_normalization_1/moving_mean oprator_name: batch_normalization_1/moving_mean/Assign oprator_name: batch_normalization_1/moving_mean/read oprator_name: batch_normalization_1/moving_variance/Initializer/ones oprator_name: batch_normalization_1/moving_variance oprator_name: batch_normalization_1/moving_variance/Assign oprator_name: batch_normalization_1/moving_variance/read oprator_name: dnn/batch_normalization_1/moments/mean/reduction_indices oprator_name: dnn/batch_normalization_1/moments/mean oprator_name: dnn/batch_normalization_1/moments/StopGradient oprator_name: dnn/batch_normalization_1/moments/SquaredDifference oprator_name: dnn/batch_normalization_1/moments/variance/reduction_indices oprator_name: dnn/batch_normalization_1/moments/variance oprator_name: dnn/batch_normalization_1/moments/Squeeze oprator_name: dnn/batch_normalization_1/moments/Squeeze_1 oprator_name: dnn/batch_normalization_1/cond/Switch oprator_name: dnn/batch_normalization_1/cond/switch_t oprator_name: dnn/batch_normalization_1/cond/switch_f oprator_name: dnn/batch_normalization_1/cond/pred_id oprator_name: dnn/batch_normalization_1/cond/Switch_1 oprator_name: dnn/batch_normalization_1/cond/Switch_2 oprator_name: dnn/batch_normalization_1/cond/Merge oprator_name: dnn/batch_normalization_1/cond_1/Switch oprator_name: dnn/batch_normalization_1/cond_1/switch_t oprator_name: dnn/batch_normalization_1/cond_1/switch_f oprator_name: dnn/batch_normalization_1/cond_1/pred_id oprator_name: dnn/batch_normalization_1/cond_1/Switch_1 oprator_name: dnn/batch_normalization_1/cond_1/Switch_2 oprator_name: dnn/batch_normalization_1/cond_1/Merge oprator_name: dnn/batch_normalization_1/cond_2/Switch oprator_name: dnn/batch_normalization_1/cond_2/switch_t oprator_name: dnn/batch_normalization_1/cond_2/switch_f oprator_name: dnn/batch_normalization_1/cond_2/pred_id oprator_name: dnn/batch_normalization_1/cond_2/AssignMovingAvg/decay oprator_name: dnn/batch_normalization_1/cond_2/AssignMovingAvg/sub/Switch oprator_name: dnn/batch_normalization_1/cond_2/AssignMovingAvg/sub/Switch_1 oprator_name: dnn/batch_normalization_1/cond_2/AssignMovingAvg/sub oprator_name: dnn/batch_normalization_1/cond_2/AssignMovingAvg/mul oprator_name: dnn/batch_normalization_1/cond_2/AssignMovingAvg/Switch oprator_name: dnn/batch_normalization_1/cond_2/AssignMovingAvg oprator_name: dnn/batch_normalization_1/cond_2/Switch_1 oprator_name: dnn/batch_normalization_1/cond_2/Merge oprator_name: dnn/batch_normalization_1/cond_3/Switch oprator_name: dnn/batch_normalization_1/cond_3/switch_t oprator_name: dnn/batch_normalization_1/cond_3/switch_f oprator_name: dnn/batch_normalization_1/cond_3/pred_id oprator_name: dnn/batch_normalization_1/cond_3/AssignMovingAvg/decay oprator_name: dnn/batch_normalization_1/cond_3/AssignMovingAvg/sub/Switch oprator_name: dnn/batch_normalization_1/cond_3/AssignMovingAvg/sub/Switch_1 oprator_name: dnn/batch_normalization_1/cond_3/AssignMovingAvg/sub oprator_name: dnn/batch_normalization_1/cond_3/AssignMovingAvg/mul oprator_name: dnn/batch_normalization_1/cond_3/AssignMovingAvg/Switch oprator_name: dnn/batch_normalization_1/cond_3/AssignMovingAvg oprator_name: dnn/batch_normalization_1/cond_3/Switch_1 oprator_name: dnn/batch_normalization_1/cond_3/Merge oprator_name: dnn/batch_normalization_1/batchnorm/add/y oprator_name: dnn/batch_normalization_1/batchnorm/add oprator_name: dnn/batch_normalization_1/batchnorm/Rsqrt oprator_name: dnn/batch_normalization_1/batchnorm/mul oprator_name: dnn/batch_normalization_1/batchnorm/mul_1 oprator_name: dnn/batch_normalization_1/batchnorm/mul_2 oprator_name: dnn/batch_normalization_1/batchnorm/sub oprator_name: dnn/batch_normalization_1/batchnorm/add_1 oprator_name: dnn/Relu oprator_name: output/kernel/Initializer/truncated_normal/shape oprator_name: output/kernel/Initializer/truncated_normal/mean oprator_name: output/kernel/Initializer/truncated_normal/stddev oprator_name: output/kernel/Initializer/truncated_normal/TruncatedNormal oprator_name: output/kernel/Initializer/truncated_normal/mul oprator_name: output/kernel/Initializer/truncated_normal oprator_name: output/kernel oprator_name: output/kernel/Assign oprator_name: output/kernel/read oprator_name: output/bias/Initializer/zeros oprator_name: output/bias oprator_name: output/bias/Assign oprator_name: output/bias/read oprator_name: dnn/output/MatMul oprator_name: dnn/output/BiasAdd oprator_name: loss/softmax_cross_entropy_loss/labels_stop_gradient oprator_name: loss/softmax_cross_entropy_loss/xentropy/Rank oprator_name: loss/softmax_cross_entropy_loss/xentropy/Shape oprator_name: loss/softmax_cross_entropy_loss/xentropy/Rank_1 oprator_name: loss/softmax_cross_entropy_loss/xentropy/Shape_1 oprator_name: loss/softmax_cross_entropy_loss/xentropy/Sub/y oprator_name: loss/softmax_cross_entropy_loss/xentropy/Sub oprator_name: loss/softmax_cross_entropy_loss/xentropy/Slice/begin oprator_name: loss/softmax_cross_entropy_loss/xentropy/Slice/size oprator_name: loss/softmax_cross_entropy_loss/xentropy/Slice oprator_name: loss/softmax_cross_entropy_loss/xentropy/concat/values_0 oprator_name: loss/softmax_cross_entropy_loss/xentropy/concat/axis oprator_name: loss/softmax_cross_entropy_loss/xentropy/concat oprator_name: loss/softmax_cross_entropy_loss/xentropy/Reshape oprator_name: loss/softmax_cross_entropy_loss/xentropy/Rank_2 oprator_name: loss/softmax_cross_entropy_loss/xentropy/Shape_2 oprator_name: loss/softmax_cross_entropy_loss/xentropy/Sub_1/y oprator_name: loss/softmax_cross_entropy_loss/xentropy/Sub_1 oprator_name: loss/softmax_cross_entropy_loss/xentropy/Slice_1/begin oprator_name: loss/softmax_cross_entropy_loss/xentropy/Slice_1/size oprator_name: loss/softmax_cross_entropy_loss/xentropy/Slice_1 oprator_name: loss/softmax_cross_entropy_loss/xentropy/concat_1/values_0 oprator_name: loss/softmax_cross_entropy_loss/xentropy/concat_1/axis oprator_name: loss/softmax_cross_entropy_loss/xentropy/concat_1 oprator_name: loss/softmax_cross_entropy_loss/xentropy/Reshape_1 oprator_name: loss/softmax_cross_entropy_loss/xentropy oprator_name: loss/softmax_cross_entropy_loss/xentropy/Sub_2/y oprator_name: loss/softmax_cross_entropy_loss/xentropy/Sub_2 oprator_name: loss/softmax_cross_entropy_loss/xentropy/Slice_2/begin oprator_name: loss/softmax_cross_entropy_loss/xentropy/Slice_2/size oprator_name: loss/softmax_cross_entropy_loss/xentropy/Slice_2 oprator_name: loss/softmax_cross_entropy_loss/xentropy/Reshape_2 oprator_name: loss/softmax_cross_entropy_loss/assert_broadcastable/weights oprator_name: loss/softmax_cross_entropy_loss/assert_broadcastable/weights/shape oprator_name: loss/softmax_cross_entropy_loss/assert_broadcastable/weights/rank oprator_name: loss/softmax_cross_entropy_loss/assert_broadcastable/values/shape oprator_name: loss/softmax_cross_entropy_loss/assert_broadcastable/values/rank oprator_name: loss/softmax_cross_entropy_loss/assert_broadcastable/static_scalar_check_success oprator_name: loss/softmax_cross_entropy_loss/Cast/x oprator_name: loss/softmax_cross_entropy_loss/Mul oprator_name: loss/softmax_cross_entropy_loss/Const oprator_name: loss/softmax_cross_entropy_loss/Sum oprator_name: loss/softmax_cross_entropy_loss/num_present/Equal/y oprator_name: loss/softmax_cross_entropy_loss/num_present/Equal oprator_name: loss/softmax_cross_entropy_loss/num_present/zeros_like oprator_name: loss/softmax_cross_entropy_loss/num_present/ones_like/Shape oprator_name: loss/softmax_cross_entropy_loss/num_present/ones_like/Const oprator_name: loss/softmax_cross_entropy_loss/num_present/ones_like oprator_name: loss/softmax_cross_entropy_loss/num_present/Select oprator_name: loss/softmax_cross_entropy_loss/num_present/broadcast_weights/assert_broadcastable/weights/shape oprator_name: loss/softmax_cross_entropy_loss/num_present/broadcast_weights/assert_broadcastable/weights/rank oprator_name: loss/softmax_cross_entropy_loss/num_present/broadcast_weights/assert_broadcastable/values/shape oprator_name: loss/softmax_cross_entropy_loss/num_present/broadcast_weights/assert_broadcastable/values/rank oprator_name: loss/softmax_cross_entropy_loss/num_present/broadcast_weights/assert_broadcastable/static_scalar_check_success oprator_name: loss/softmax_cross_entropy_loss/num_present/broadcast_weights/ones_like/Shape oprator_name: loss/softmax_cross_entropy_loss/num_present/broadcast_weights/ones_like/Const oprator_name: loss/softmax_cross_entropy_loss/num_present/broadcast_weights/ones_like oprator_name: loss/softmax_cross_entropy_loss/num_present/broadcast_weights oprator_name: loss/softmax_cross_entropy_loss/num_present/Const oprator_name: loss/softmax_cross_entropy_loss/num_present oprator_name: loss/softmax_cross_entropy_loss/Const_1 oprator_name: loss/softmax_cross_entropy_loss/Sum_1 oprator_name: loss/softmax_cross_entropy_loss/value oprator_name: train/gradients/Shape oprator_name: train/gradients/grad_ys_0 oprator_name: train/gradients/Fill oprator_name: train/gradients/loss/softmax_cross_entropy_loss/value_grad/Shape oprator_name: train/gradients/loss/softmax_cross_entropy_loss/value_grad/Shape_1 oprator_name: train/gradients/loss/softmax_cross_entropy_loss/value_grad/BroadcastGradientArgs oprator_name: train/gradients/loss/softmax_cross_entropy_loss/value_grad/div_no_nan oprator_name: train/gradients/loss/softmax_cross_entropy_loss/value_grad/Sum oprator_name: train/gradients/loss/softmax_cross_entropy_loss/value_grad/Reshape oprator_name: train/gradients/loss/softmax_cross_entropy_loss/value_grad/Neg oprator_name: train/gradients/loss/softmax_cross_entropy_loss/value_grad/div_no_nan_1 oprator_name: train/gradients/loss/softmax_cross_entropy_loss/value_grad/div_no_nan_2 oprator_name: train/gradients/loss/softmax_cross_entropy_loss/value_grad/mul oprator_name: train/gradients/loss/softmax_cross_entropy_loss/value_grad/Sum_1 oprator_name: train/gradients/loss/softmax_cross_entropy_loss/value_grad/Reshape_1 oprator_name: train/gradients/loss/softmax_cross_entropy_loss/value_grad/tuple/group_deps oprator_name: train/gradients/loss/softmax_cross_entropy_loss/value_grad/tuple/control_dependency oprator_name: train/gradients/loss/softmax_cross_entropy_loss/value_grad/tuple/control_dependency_1 oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Sum_1_grad/Reshape/shape oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Sum_1_grad/Reshape oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Sum_1_grad/Const oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Sum_1_grad/Tile oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Sum_grad/Reshape/shape oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Sum_grad/Reshape oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Sum_grad/Shape oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Sum_grad/Tile oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Mul_grad/Shape oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Mul_grad/Shape_1 oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Mul_grad/BroadcastGradientArgs oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Mul_grad/Mul oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Mul_grad/Sum oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Mul_grad/Reshape oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Mul_grad/Mul_1 oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Mul_grad/Sum_1 oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Mul_grad/Reshape_1 oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Mul_grad/tuple/group_deps oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Mul_grad/tuple/control_dependency oprator_name: train/gradients/loss/softmax_cross_entropy_loss/Mul_grad/tuple/control_dependency_1 oprator_name: train/gradients/loss/softmax_cross_entropy_loss/xentropy/Reshape_2_grad/Shape oprator_name: train/gradients/loss/softmax_cross_entropy_loss/xentropy/Reshape_2_grad/Reshape oprator_name: train/gradients/zeros_like oprator_name: train/gradients/loss/softmax_cross_entropy_loss/xentropy_grad/ExpandDims/dim oprator_name: train/gradients/loss/softmax_cross_entropy_loss/xentropy_grad/ExpandDims oprator_name: train/gradients/loss/softmax_cross_entropy_loss/xentropy_grad/mul oprator_name: train/gradients/loss/softmax_cross_entropy_loss/xentropy_grad/LogSoftmax oprator_name: train/gradients/loss/softmax_cross_entropy_loss/xentropy_grad/Neg oprator_name: train/gradients/loss/softmax_cross_entropy_loss/xentropy_grad/ExpandDims_1/dim oprator_name: train/gradients/loss/softmax_cross_entropy_loss/xentropy_grad/ExpandDims_1 oprator_name: train/gradients/loss/softmax_cross_entropy_loss/xentropy_grad/mul_1 oprator_name: train/gradients/loss/softmax_cross_entropy_loss/xentropy_grad/tuple/group_deps oprator_name: train/gradients/loss/softmax_cross_entropy_loss/xentropy_grad/tuple/control_dependency oprator_name: train/gradients/loss/softmax_cross_entropy_loss/xentropy_grad/tuple/control_dependency_1 oprator_name: train/gradients/loss/softmax_cross_entropy_loss/xentropy/Reshape_grad/Shape oprator_name: train/gradients/loss/softmax_cross_entropy_loss/xentropy/Reshape_grad/Reshape oprator_name: train/gradients/dnn/output/BiasAdd_grad/BiasAddGrad oprator_name: train/gradients/dnn/output/BiasAdd_grad/tuple/group_deps oprator_name: train/gradients/dnn/output/BiasAdd_grad/tuple/control_dependency oprator_name: train/gradients/dnn/output/BiasAdd_grad/tuple/control_dependency_1 oprator_name: train/gradients/dnn/output/MatMul_grad/MatMul oprator_name: train/gradients/dnn/output/MatMul_grad/MatMul_1 oprator_name: train/gradients/dnn/output/MatMul_grad/tuple/group_deps oprator_name: train/gradients/dnn/output/MatMul_grad/tuple/control_dependency oprator_name: train/gradients/dnn/output/MatMul_grad/tuple/control_dependency_1 oprator_name: train/gradients/dnn/Relu_grad/ReluGrad oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_1_grad/Shape oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_1_grad/Shape_1 oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_1_grad/BroadcastGradientArgs oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_1_grad/Sum oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_1_grad/Reshape oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_1_grad/Sum_1 oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_1_grad/Reshape_1 oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_1_grad/tuple/group_deps oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_1_grad/tuple/control_dependency oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_1_grad/tuple/control_dependency_1 oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_1_grad/Shape oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_1_grad/Shape_1 oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_1_grad/BroadcastGradientArgs oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_1_grad/Mul oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_1_grad/Sum oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_1_grad/Reshape oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_1_grad/Mul_1 oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_1_grad/Sum_1 oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_1_grad/Reshape_1 oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_1_grad/tuple/group_deps oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_1_grad/tuple/control_dependency oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_1_grad/tuple/control_dependency_1 oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/sub_grad/Neg oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/sub_grad/tuple/group_deps oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/sub_grad/tuple/control_dependency oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/sub_grad/tuple/control_dependency_1 oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_2_grad/Mul oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_2_grad/Mul_1 oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_2_grad/tuple/group_deps oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_2_grad/tuple/control_dependency oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_2_grad/tuple/control_dependency_1 oprator_name: train/gradients/dnn/batch_normalization_1/cond/Merge_grad/cond_grad oprator_name: train/gradients/dnn/batch_normalization_1/cond/Merge_grad/tuple/group_deps oprator_name: train/gradients/dnn/batch_normalization_1/cond/Merge_grad/tuple/control_dependency oprator_name: train/gradients/dnn/batch_normalization_1/cond/Merge_grad/tuple/control_dependency_1 oprator_name: train/gradients/AddN oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_grad/Mul oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_grad/Mul_1 oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_grad/tuple/group_deps oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_grad/tuple/control_dependency oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/mul_grad/tuple/control_dependency_1 oprator_name: train/gradients/Switch oprator_name: train/gradients/Identity oprator_name: train/gradients/Shape_1 oprator_name: train/gradients/zeros/Const oprator_name: train/gradients/zeros oprator_name: train/gradients/dnn/batch_normalization_1/cond/Switch_1_grad/cond_grad oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/Rsqrt_grad/RsqrtGrad oprator_name: train/gradients/dnn/batch_normalization_1/moments/Squeeze_grad/Shape oprator_name: train/gradients/dnn/batch_normalization_1/moments/Squeeze_grad/Reshape oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_grad/Shape oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_grad/Shape_1 oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_grad/BroadcastGradientArgs oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_grad/Sum oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_grad/Reshape oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_grad/Sum_1 oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_grad/Reshape_1 oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_grad/tuple/group_deps oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_grad/tuple/control_dependency oprator_name: train/gradients/dnn/batch_normalization_1/batchnorm/add_grad/tuple/control_dependency_1 oprator_name: train/gradients/dnn/batch_normalization_1/cond_1/Merge_grad/cond_grad oprator_name: train/gradients/dnn/batch_normalization_1/cond_1/Merge_grad/tuple/group_deps oprator_name: train/gradients/dnn/batch_normalization_1/cond_1/Merge_grad/tuple/control_dependency oprator_name: train/gradients/dnn/batch_normalization_1/cond_1/Merge_grad/tuple/control_dependency_1 oprator_name: train/gradients/Switch_1 oprator_name: train/gradients/Identity_1 oprator_name: train/gradients/Shape_2 oprator_name: train/gradients/zeros_1/Const oprator_name: train/gradients/zeros_1 oprator_name: train/gradients/dnn/batch_normalization_1/cond_1/Switch_1_grad/cond_grad oprator_name: train/gradients/dnn/batch_normalization_1/moments/Squeeze_1_grad/Shape oprator_name: train/gradients/dnn/batch_normalization_1/moments/Squeeze_1_grad/Reshape oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Shape oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Size oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/add oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/mod oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Shape_1 oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/range/start oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/range/delta oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/range oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Fill/value oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Fill oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/DynamicStitch oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Maximum/y oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Maximum oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/floordiv oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Reshape oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Tile oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Shape_2 oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Shape_3 oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Const oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Prod oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Const_1 oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Prod_1 oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Maximum_1/y oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Maximum_1 oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/floordiv_1 oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/Cast oprator_name: train/gradients/dnn/batch_normalization_1/moments/variance_grad/truediv oprator_name: train/gradients/dnn/batch_normalization_1/moments/SquaredDifference_grad/Shape oprator_name: train/gradients/dnn/batch_normalization_1/moments/SquaredDifference_grad/Shape_1 oprator_name: train/gradients/dnn/batch_normalization_1/moments/SquaredDifference_grad/BroadcastGradientArgs oprator_name: train/gradients/dnn/batch_normalization_1/moments/SquaredDifference_grad/scalar oprator_name: train/gradients/dnn/batch_normalization_1/moments/SquaredDifference_grad/Mul oprator_name: train/gradients/dnn/batch_normalization_1/moments/SquaredDifference_grad/sub oprator_name: train/gradients/dnn/batch_normalization_1/moments/SquaredDifference_grad/mul_1 oprator_name: train/gradients/dnn/batch_normalization_1/moments/SquaredDifference_grad/Sum oprator_name: train/gradients/dnn/batch_normalization_1/moments/SquaredDifference_grad/Reshape oprator_name: train/gradients/dnn/batch_normalization_1/moments/SquaredDifference_grad/Sum_1 oprator_name: train/gradients/dnn/batch_normalization_1/moments/SquaredDifference_grad/Reshape_1 oprator_name: train/gradients/dnn/batch_normalization_1/moments/SquaredDifference_grad/Neg oprator_name: train/gradients/dnn/batch_normalization_1/moments/SquaredDifference_grad/tuple/group_deps oprator_name: train/gradients/dnn/batch_normalization_1/moments/SquaredDifference_grad/tuple/control_dependency oprator_name: train/gradients/dnn/batch_normalization_1/moments/SquaredDifference_grad/tuple/control_dependency_1 oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Shape oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Size oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/add oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/mod oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Shape_1 oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/range/start oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/range/delta oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/range oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Fill/value oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Fill oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/DynamicStitch oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Maximum/y oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Maximum oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/floordiv oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Reshape oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Tile oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Shape_2 oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Shape_3 oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Const oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Prod oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Const_1 oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Prod_1 oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Maximum_1/y oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Maximum_1 oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/floordiv_1 oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/Cast oprator_name: train/gradients/dnn/batch_normalization_1/moments/mean_grad/truediv oprator_name: train/gradients/AddN_1 oprator_name: train/gradients/dnn/hidden2/BiasAdd_grad/BiasAddGrad oprator_name: train/gradients/dnn/hidden2/BiasAdd_grad/tuple/group_deps oprator_name: train/gradients/dnn/hidden2/BiasAdd_grad/tuple/control_dependency oprator_name: train/gradients/dnn/hidden2/BiasAdd_grad/tuple/control_dependency_1 oprator_name: train/gradients/dnn/hidden2/MatMul_grad/MatMul oprator_name: train/gradients/dnn/hidden2/MatMul_grad/MatMul_1 oprator_name: train/gradients/dnn/hidden2/MatMul_grad/tuple/group_deps oprator_name: train/gradients/dnn/hidden2/MatMul_grad/tuple/control_dependency oprator_name: train/gradients/dnn/hidden2/MatMul_grad/tuple/control_dependency_1 oprator_name: train/gradients/dnn/swish_f32_grad/SymbolicGradient oprator_name: train/gradients/dnn/batch_normalization/batchnorm/add_1_grad/Shape oprator_name: train/gradients/dnn/batch_normalization/batchnorm/add_1_grad/Shape_1 oprator_name: train/gradients/dnn/batch_normalization/batchnorm/add_1_grad/BroadcastGradientArgs oprator_name: train/gradients/dnn/batch_normalization/batchnorm/add_1_grad/Sum oprator_name: train/gradients/dnn/batch_normalization/batchnorm/add_1_grad/Reshape oprator_name: train/gradients/dnn/batch_normalization/batchnorm/add_1_grad/Sum_1 oprator_name: train/gradients/dnn/batch_normalization/batchnorm/add_1_grad/Reshape_1 oprator_name: train/gradients/dnn/batch_normalization/batchnorm/add_1_grad/tuple/group_deps oprator_name: train/gradients/dnn/batch_normalization/batchnorm/add_1_grad/tuple/control_dependency oprator_name: train/gradients/dnn/batch_normalization/batchnorm/add_1_grad/tuple/control_dependency_1 oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_1_grad/Shape oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_1_grad/Shape_1 oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_1_grad/BroadcastGradientArgs oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_1_grad/Mul oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_1_grad/Sum oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_1_grad/Reshape oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_1_grad/Mul_1 oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_1_grad/Sum_1 oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_1_grad/Reshape_1 oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_1_grad/tuple/group_deps oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_1_grad/tuple/control_dependency oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_1_grad/tuple/control_dependency_1 oprator_name: train/gradients/dnn/batch_normalization/batchnorm/sub_grad/Neg oprator_name: train/gradients/dnn/batch_normalization/batchnorm/sub_grad/tuple/group_deps oprator_name: train/gradients/dnn/batch_normalization/batchnorm/sub_grad/tuple/control_dependency oprator_name: train/gradients/dnn/batch_normalization/batchnorm/sub_grad/tuple/control_dependency_1 oprator_name: train/gradients/dnn/hidden1/BiasAdd_grad/BiasAddGrad oprator_name: train/gradients/dnn/hidden1/BiasAdd_grad/tuple/group_deps oprator_name: train/gradients/dnn/hidden1/BiasAdd_grad/tuple/control_dependency oprator_name: train/gradients/dnn/hidden1/BiasAdd_grad/tuple/control_dependency_1 oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_2_grad/Mul oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_2_grad/Mul_1 oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_2_grad/tuple/group_deps oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_2_grad/tuple/control_dependency oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_2_grad/tuple/control_dependency_1 oprator_name: train/gradients/dnn/hidden1/MatMul_grad/MatMul oprator_name: train/gradients/dnn/hidden1/MatMul_grad/MatMul_1 oprator_name: train/gradients/dnn/hidden1/MatMul_grad/tuple/group_deps oprator_name: train/gradients/dnn/hidden1/MatMul_grad/tuple/control_dependency oprator_name: train/gradients/dnn/hidden1/MatMul_grad/tuple/control_dependency_1 oprator_name: train/gradients/AddN_2 oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_grad/Mul oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_grad/Mul_1 oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_grad/tuple/group_deps oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_grad/tuple/control_dependency oprator_name: train/gradients/dnn/batch_normalization/batchnorm/mul_grad/tuple/control_dependency_1 oprator_name: train/GradientDescent/learning_rate oprator_name: train/GradientDescent/update_hidden1/kernel/ApplyGradientDescent oprator_name: train/GradientDescent/update_hidden1/bias/ApplyGradientDescent oprator_name: train/GradientDescent/update_batch_normalization/gamma/ApplyGradientDescent oprator_name: train/GradientDescent/update_batch_normalization/beta/ApplyGradientDescent oprator_name: train/GradientDescent/update_hidden2/kernel/ApplyGradientDescent oprator_name: train/GradientDescent/update_hidden2/bias/ApplyGradientDescent oprator_name: train/GradientDescent/update_batch_normalization_1/gamma/ApplyGradientDescent oprator_name: train/GradientDescent/update_batch_normalization_1/beta/ApplyGradientDescent oprator_name: train/GradientDescent/update_output/kernel/ApplyGradientDescent oprator_name: train/GradientDescent/update_output/bias/ApplyGradientDescent oprator_name: train/GradientDescent oprator_name: eval/ArgMax/dimension oprator_name: eval/ArgMax oprator_name: eval/in_top_k/InTopKV2/k oprator_name: eval/in_top_k/InTopKV2 oprator_name: eval/Cast oprator_name: eval/Const oprator_name: eval/Mean oprator_name: init oprator_name: init_1 oprator_name: group_deps oprator_name: save/filename/input oprator_name: save/filename oprator_name: save/Const oprator_name: save/SaveV2/tensor_names oprator_name: save/SaveV2/shape_and_slices oprator_name: save/SaveV2 oprator_name: save/control_dependency oprator_name: save/RestoreV2/tensor_names oprator_name: save/RestoreV2/shape_and_slices oprator_name: save/RestoreV2 oprator_name: save/Assign oprator_name: save/Assign_1 oprator_name: save/Assign_2 oprator_name: save/Assign_3 oprator_name: save/Assign_4 oprator_name: save/Assign_5 oprator_name: save/Assign_6 oprator_name: save/Assign_7 oprator_name: save/Assign_8 oprator_name: save/Assign_9 oprator_name: save/Assign_10 oprator_name: save/Assign_11 oprator_name: save/Assign_12 oprator_name: save/Assign_13 oprator_name: save/restore_all """
checkpoint (.data & .index)
.data 和 .index 文件合在一起组成了 ckpt 文件,保存了网络结构中所有 权重和偏置 的数值。
.data文件保存的是变量值,.index文件保存的是.data文件中数据和 .meta文件中结构图之间的对应关系
查看 ckpt 模型文件中保存的 Tensor 参数信息(网络参考后面的完整例子):
import tensorflow as tf # ================================================================ # # 列出 ckpt 中所有变量名 # # ================================================================ # checkpoint_path = 'my_model_final.ckpt' reader = tf.pywrap_tensorflow.NewCheckpointReader(checkpoint_path) var_to_shape_map = reader.get_variable_to_shape_map() # Print tensor name and values for key in var_to_shape_map: print("tensor_name: ", key) # print(reader.get_tensor(key)) """ tensor_name: hidden1/bias tensor_name: batch_normalization_1/beta tensor_name: batch_normalization/beta tensor_name: hidden2/bias tensor_name: batch_normalization_1/gamma tensor_name: batch_normalization/gamma tensor_name: batch_normalization_1/moving_mean tensor_name: batch_normalization/moving_mean tensor_name: batch_normalization_1/moving_variance tensor_name: batch_normalization/moving_variance tensor_name: hidden1/kernel tensor_name: hidden2/kernel tensor_name: output/bias tensor_name: output/kernel """
模型保存 tf.train.Saver
saver = tf.train.Saver() saver.save(sess,"model_test.ckpt")
Saver类的构造函数定义:
def __init__(self, var_list=None, # 指定要保存的变量的序列或字典,默认为None,保存所有变量 reshape=False, sharded=False, max_to_keep=5, # 定义最多保存最近的多少个模型文件 keep_checkpoint_every_n_hours=10000.0, name=None, restore_sequentially=False, saver_def=None, builder=None, defer_build=False, allow_empty=False, write_version=saver_pb2.SaverDef.V2, pad_step_number=False, save_relative_paths=False, filename=None):
saver.save函数定义:
def save(self, sess, # 当前的会话环境 save_path, # 模型保存路径 global_step=None, # 训练轮次,如果添加,会在模型文件名称后加上这个轮次的后缀 latest_filename=None, # checkpoint 文本文件的名称,默认为 'checkpoint' meta_graph_suffix="meta", # 保存的网络图结构文件的后缀 write_meta_graph=True, # 定义是否保存网络结构 .meta write_state=True, strip_default_attrs=False, save_debug_info=False):
下面提供一个完整的 MNIST 训练:
import tensorflow as tf # 1. create data from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('../MNIST_data', one_hot=True) with tf.name_scope('input'): X = tf.placeholder(tf.float32, shape=(None, 784), name='X') y = tf.placeholder(tf.float32, shape=(None, 10), name='y') is_training = tf.placeholder(tf.bool, None, name='is_training') # 2. define network he_init = tf.variance_scaling_initializer(scale=1.0, mode="fan_avg",distribution="truncated_normal") with tf.name_scope('dnn'): hidden1 = tf.layers.dense(X, 300, kernel_initializer=he_init, name='hidden1') hidden1 = tf.layers.batch_normalization(hidden1, momentum=0.9) # gamma beta moving_mean moving_variance hidden1 = tf.nn.swish(hidden1) hidden2 = tf.layers.dense(hidden1, 100, kernel_initializer=he_init, name='hidden2') hidden2 = tf.layers.batch_normalization(hidden2, training=is_training, momentum=0.9) hidden2 = tf.nn.relu(hidden2) logits = tf.layers.dense(hidden2, 10, kernel_initializer=he_init, name='output') # prob = tf.layers.dense(hidden2, 10, activation=tf.nn.softmax, kernel_initializer=he_init, name='prob') # 3. define loss function with tf.name_scope('loss'): # tf.losses.sparse_softmax_cross_entropy() label is not one_hot and dtype is int* # xentropy = tf.losses.sparse_softmax_cross_entropy(labels=tf.argmax(y, axis=1), logits=logits) # tf.nn.sparse_softmax_cross_entropy_with_logits() label is not one_hot and dtype is int* # xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.argmax(y, axis=1), logits=logits) # loss = tf.reduce_mean(xentropy) loss = tf.losses.softmax_cross_entropy(onehot_labels=y, logits=logits) # 4. define optimizer learning_rate_init = 0.01 with tf.name_scope('train'): update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) with tf.control_dependencies(update_ops): train_op = tf.train.GradientDescentOptimizer(learning_rate_init).minimize(loss) with tf.name_scope('eval'): correct = tf.nn.in_top_k(logits, tf.argmax(y, axis=1), 1) # 目标是否在前K个预测中, label's dtype is int* accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) # 5. initialize init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()) saver = tf.train.Saver() # ================= print([v.name for v in tf.trainable_variables()]) print([v.name for v in tf.global_variables()]) # ================= # 6. train & test n_epochs = 20 batch_size = 50 with tf.Session() as sess: sess.run(init_op) for epoch in range(n_epochs): for iteration in range(mnist.train.num_examples // batch_size): X_batch, y_batch = mnist.train.next_batch(batch_size) sess.run(train_op, feed_dict={X: X_batch, y: y_batch, is_training: True}) acc_train = accuracy.eval(feed_dict={X: X_batch, y: y_batch, is_training: False}) # 最后一个 batch 的 accuracy acc_test = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training: False}) loss_test = loss.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training: False}) print(epoch, "Train accuracy:", acc_train, "Test accuracy:", acc_test, "Test loss:", loss_test) save_path = saver.save(sess, "./my_model_final.ckpt") with tf.Session() as sess: sess.run(init_op) saver.restore(sess, "./my_model_final.ckpt") acc_test = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training: False}) loss_test = loss.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training: False}) print("Test accuracy:", acc_test, ", Test loss:", loss_test)
模型加载
场景一
加载模型时候可以先加载图结构,再加载图中的参数(在Session中操作):
saver=tf.train.import_meta_graph('./model_saved/model_test.meta') saver.restore(sess, './model_saved/model_test.ckpt') # or saver.restore(sess, tf.train.latest_checkpoint('./model_saved'))
基于上面的 MNIST 例子来 finetune:
# ================================================================ # # 场景一 # # ================================================================ # # 1. create data from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('../MNIST_data', one_hot=True) restore = tf.train.import_meta_graph('./my_model_final.ckpt.meta') # ================= # for op in tf.get_default_graph().get_operations(): # print(op.name) # ================= X = tf.get_default_graph().get_tensor_by_name('input/X:0') y = tf.get_default_graph().get_tensor_by_name('input/y:0') is_training = tf.get_default_graph().get_tensor_by_name('input/is_training:0') loss = tf.get_default_graph().get_tensor_by_name('loss/softmax_cross_entropy_loss/value:0') accuracy = tf.get_default_graph().get_tensor_by_name('eval/Mean:0') optimizer_op = tf.get_default_graph().get_operation_by_name('train/GradientDescent') # 5. train & test n_epochs = 20 batch_size = 50 saver = tf.train.Saver(tf.global_variables()) with tf.Session() as sess: restore.restore(sess, './my_model_final.ckpt') for epoch in range(n_epochs): for iteration in range(mnist.train.num_examples // batch_size): X_batch, y_batch = mnist.train.next_batch(batch_size) sess.run(optimizer_op, feed_dict={X: X_batch, y: y_batch, is_training:True}) acc_train = accuracy.eval(feed_dict={X: X_batch, y: y_batch, is_training:False}) # 最后一个 batch 的 accuracy acc_test = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training:False}) loss_test = loss.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training:False}) print(epoch, "Train accuracy:", acc_train, "Test accuracy:", acc_test, "Test loss:", loss_test) save_path = saver.save(sess, "./new_my_model_final.ckpt")
如果不确定节点名,可以用下面这个代码来查看 meta
for op in tf.get_default_graph().get_operations(): print(op.name)
=================================================================
场景二
或者一次性加载:
saver = tf.train.Saver() saver.restore(sess, './model_saved/model_test.ckpt') # or saver.restore(sess, tf.train.latest_checkpoint('./model_saved'))
基于上面的 MNIST 例子来 finetune:
import tensorflow as tf # 1. create data from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('../MNIST_data', one_hot=True) X = tf.placeholder(tf.float32, shape=(None, 784), name='X') y = tf.placeholder(tf.int32, shape=(None), name='y') is_training = tf.placeholder(tf.bool, None, name='is_training') # 2. define network he_init = tf.contrib.layers.variance_scaling_initializer() with tf.name_scope('dnn'): hidden1 = tf.layers.dense(X, 300, kernel_initializer=he_init, name='hidden1') hidden1 = tf.layers.batch_normalization(hidden1, momentum=0.9) hidden1 = tf.nn.relu(hidden1) hidden2 = tf.layers.dense(hidden1, 100, kernel_initializer=he_init, name='hidden2') hidden2 = tf.layers.batch_normalization(hidden2, training=is_training, momentum=0.9) hidden2 = tf.nn.relu(hidden2) logits = tf.layers.dense(hidden2, 10, kernel_initializer=he_init, name='output') # 3. define loss with tf.name_scope('loss'): # tf.losses.sparse_softmax_cross_entropy() label is not one_hot and dtype is int* loss = tf.losses.softmax_cross_entropy(onehot_labels=y, logits=logits) # label is one_hot # 4. define optimizer learning_rate = 0.01 with tf.name_scope('train'): update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) # for batch normalization with tf.control_dependencies(update_ops): optimizer_op = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss) with tf.name_scope('eval'): correct = tf.nn.in_top_k(logits, tf.argmax(y, axis=1), 1) # 目标是否在前K个预测中, label's dtype is int* accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) # 5. initialize init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()) saver = tf.train.Saver() # ================= print([v.name for v in tf.trainable_variables()]) print([v.name for v in tf.global_variables()]) # ================= # 5. train & test n_epochs = 20 n_batches = 50 batch_size = 50 with tf.Session() as sess: sess.run(init_op) saver.restore(sess, './my_model_final.ckpt') for epoch in range(n_epochs): for iteration in range(mnist.train.num_examples // batch_size): X_batch, y_batch = mnist.train.next_batch(batch_size) sess.run(optimizer_op, feed_dict={X: X_batch, y: y_batch, is_training:True}) acc_train = accuracy.eval(feed_dict={X: X_batch, y: y_batch, is_training:False}) # 最后一个 batch 的 accuracy acc_test = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training:False}) loss_test = loss.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training:False}) print(epoch, "Train accuracy:", acc_train, "Test accuracy:", acc_test, "Test loss:", loss_test) save_path = saver.save(sess, "./new_my_model_final.ckpt") with tf.Session() as sess: sess.run(init_op) saver.restore(sess, "./my_model_final.ckpt") acc_test = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training:False}) loss_test = loss.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training:False}) print("Test accuracy:", acc_test, ", Test loss:", loss_test)
BUG
但是实际使用时有一个问题,如果你使用某种学习率调整方式来训练,例如:
# 4. define optimizer learning_rate_init = 0.01 global_step = tf.Variable(0, trainable=False) with tf.name_scope('train'): learning_rate = tf.train.polynomial_decay( # 多项式衰减 learning_rate=learning_rate_init, # 初始学习率 global_step=global_step, # 当前迭代次数 decay_steps=22000, # 在迭代到该次数实际,学习率衰减为 learning_rate * dacay_rate end_learning_rate=learning_rate_init / 10, # 最小的学习率 power=0.9, cycle=False ) update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) # for batch normalization with tf.control_dependencies(update_ops): optimizer_op = tf.train.GradientDescentOptimizer( learning_rate=learning_rate).minimize( loss=loss, var_list=tf.trainable_variables(), global_step=global_step )
那么 finetune 时会把 global_step 也继承下来,这就相当于继续训练了。。。因此可以采用部分恢复的方式:
模型部分恢复
为了验证是否部分恢复,下面将 learning_rate 按照多项式衰减形式更新。
场景一
In general you will want to reuse only the lower layers. If you are using
import_meta_graph()it will load the whole graph, but you can simply ignore the parts you do not need. In this example, we add a new 3th hidden layer on top of the pretrained 2rd layer . We also build a new output layer, the loss for this new output, and a new optimizer to minimize it. We also need another saver to save the whole graph (containing both the entire old graph plus the new operations), and an initialization operation to initialize all the new variables:
在之前的 Graph 基础上修改,代码示例:
import tensorflow as tf # 1. create data from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('../MNIST_data', one_hot=True) saver = tf.train.import_meta_graph('./my_model_final.ckpt.meta') # ================= for op in tf.get_default_graph().get_operations(): print(op.name) # ================= X = tf.get_default_graph().get_tensor_by_name('X:0') y = tf.get_default_graph().get_tensor_by_name('y:0') is_training = tf.get_default_graph().get_tensor_by_name('is_training:0') # loss = tf.get_default_graph().get_tensor_by_name('loss/softmax_cross_entropy_loss/value:0') # accuracy = tf.get_default_graph().get_tensor_by_name('eval/Mean:0') # learning_rate = tf.get_default_graph().get_tensor_by_name('train/PolynomialDecay:0') # optimizer_op = tf.get_default_graph().get_operation_by_name('train/GradientDescent') # ================= hidden2 = tf.get_default_graph().get_tensor_by_name("dnn/Relu_1:0") he_init = tf.contrib.layers.variance_scaling_initializer() hidden3 = tf.layers.dense(hidden2, 50, kernel_initializer=he_init, name='hidden3') hidden3 = tf.layers.batch_normalization(hidden2, training=is_training, momentum=0.9) hidden3 = tf.nn.relu(hidden2) new_logits = tf.layers.dense(hidden3, 10, kernel_initializer=he_init, name='output') with tf.name_scope("new_loss"): loss = tf.losses.softmax_cross_entropy(onehot_labels=y, logits=new_logits) # label is one_hot with tf.name_scope("new_eval"): correct = tf.nn.in_top_k(new_logits, tf.argmax(y, axis=1), 1) # 目标是否在前K个预测中, label's dtype is int* accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) # 4. define optimizer learning_rate_init = 0.01 global_step = tf.Variable(0, trainable=False) with tf.name_scope('train'): learning_rate = tf.train.polynomial_decay( # 多项式衰减 learning_rate=learning_rate_init, # 初始学习率 global_step=global_step, # 当前迭代次数 decay_steps=22000, # 在迭代到该次数实际,学习率衰减为 learning_rate * dacay_rate end_learning_rate=learning_rate_init / 10, # 最小的学习率 power=0.9, cycle=False ) update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) # for batch normalization with tf.control_dependencies(update_ops): optimizer_op = tf.train.GradientDescentOptimizer( learning_rate=learning_rate).minimize( loss=loss, var_list=tf.trainable_variables(), global_step=global_step # 不指定的话学习率不更新 ) # ================= # 5. initialize init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()) new_saver = tf.train.Saver() # 5. train & test n_epochs = 20 n_batches = 50 batch_size = 50 with tf.Session() as sess: sess.run(init_op) saver.restore(sess, './my_model_final.ckpt') for epoch in range(n_epochs): for iteration in range(mnist.train.num_examples // batch_size): X_batch, y_batch = mnist.train.next_batch(batch_size) sess.run(optimizer_op, feed_dict={X: X_batch, y: y_batch, is_training:True}) learning_rate_cur = learning_rate.eval() acc_train = accuracy.eval(feed_dict={X: X_batch, y: y_batch, is_training:False}) # 最后一个 batch 的 accuracy acc_test = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training:False}) loss_test = loss.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training:False}) print(epoch, "Current learning rate:", learning_rate_cur, "Train accuracy:", acc_train, "Test accuracy:", acc_test, "Test loss:", loss_test) save_path = new_saver.save(sess, "./new_my_model_final.ckpt")
从这个代码中我们也可以找到上一节的 bug 的解决方案了,即先删除 original_saver 的 global_step 节点值:
variables = tf.contrib.framework.get_variables_to_restore() variables_to_resotre = [v for v in variables if 'Momentum' not in v.name.split('/')[-1]] variables_to_resotre = [v for v in variables_to_resotre if 'Variable' not in v.name.split('/')[-1]] original_saver = tf.train.Saver(variables_to_resotre) new_saver = tf.train.Saver() with tf.Session() as sess: sess.run(init_op) original_saver .restore(sess, './my_model_final.ckpt') ...... save_path = new_saver.save(sess, "./new_my_model_final.ckpt")
当然,这段代码还删除了 Momentum optimizer 部分的节点值。
tf.contrib.framework.get_variables_to_restore()
print([v.name for v in tf.trainable_variables()]) print([v.name for v in tf.contrib.framework.get_variables_to_restore()]) print([v.name for v in tf.all_variables()]) print([v.name for v in tf.global_variables()]) """ ['hidden1/kernel:0', 'hidden1/bias:0', 'batch_normalization/gamma:0', 'batch_normalization/beta:0', 'hidden2/kernel:0', 'hidden2/bias:0', 'batch_normalization_1/gamma:0', 'batch_normalization_1/beta:0', 'output/kernel:0', 'output/bias:0'] ['hidden1/kernel:0', 'hidden1/bias:0', 'batch_normalization/gamma:0', 'batch_normalization/beta:0', 'batch_normalization/moving_mean:0', 'batch_normalization/moving_variance:0', 'hidden2/kernel:0', 'hidden2/bias:0', 'batch_normalization_1/gamma:0', 'batch_normalization_1/beta:0', 'batch_normalization_1/moving_mean:0', 'batch_normalization_1/moving_variance:0', 'output/kernel:0', 'output/bias:0', 'Variable:0'] ['hidden1/kernel:0', 'hidden1/bias:0', 'batch_normalization/gamma:0', 'batch_normalization/beta:0', 'batch_normalization/moving_mean:0', 'batch_normalization/moving_variance:0', 'hidden2/kernel:0', 'hidden2/bias:0', 'batch_normalization_1/gamma:0', 'batch_normalization_1/beta:0', 'batch_normalization_1/moving_mean:0', 'batch_normalization_1/moving_variance:0', 'output/kernel:0', 'output/bias:0', 'Variable:0'] ['hidden1/kernel:0', 'hidden1/bias:0', 'batch_normalization/gamma:0', 'batch_normalization/beta:0', 'batch_normalization/moving_mean:0', 'batch_normalization/moving_variance:0', 'hidden2/kernel:0', 'hidden2/bias:0', 'batch_normalization_1/gamma:0', 'batch_normalization_1/beta:0', 'batch_normalization_1/moving_mean:0', 'batch_normalization_1/moving_variance:0', 'output/kernel:0', 'output/bias:0', 'Variable:0'] """
=================================================================
场景二
If you have access to the Python code that built the original graph, you can just reuse the parts you need and drop the rest:
在新定义的 Graph 基础上,复用之前的部分权重,代码示例:
# 1. create data from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('../MNIST_data', one_hot=True) with tf.name_scope('input'): X = tf.placeholder(tf.float32, shape=(None, 784), name='X') y = tf.placeholder(tf.int32, shape=(None), name='y') is_training = tf.placeholder(tf.bool, None, name='is_training') # 2. define network he_init = tf.contrib.layers.variance_scaling_initializer() with tf.name_scope('dnn'): hidden1 = tf.layers.dense(X, 300, kernel_initializer=he_init, name='hidden1') hidden1 = tf.layers.batch_normalization(hidden1, momentum=0.9) hidden1 = tf.nn.swish(hidden1) hidden2 = tf.layers.dense(hidden1, 100, kernel_initializer=he_init, name='hidden2') hidden2 = tf.layers.batch_normalization(hidden2, training=is_training, momentum=0.9) hidden2 = tf.nn.swish(hidden2) logits = tf.layers.dense(hidden2, 10, kernel_initializer=he_init, name='output') # 3. define loss with tf.name_scope('loss'): loss = tf.losses.softmax_cross_entropy(onehot_labels=y, logits=logits) # label is one_hot # 4. define optimizer learning_rate_init = 0.01 global_step = tf.Variable(0, trainable=False) with tf.name_scope('train'): learning_rate = tf.train.polynomial_decay( # 多项式衰减 learning_rate=learning_rate_init, # 初始学习率 global_step=global_step, # 当前迭代次数 decay_steps=22000, # 在迭代到该次数实际,学习率衰减为 learning_rate * dacay_rate end_learning_rate=learning_rate_init / 10, # 最小的学习率 power=0.9, cycle=False ) update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) # for batch normalization with tf.control_dependencies(update_ops): optimizer_op = tf.train.GradientDescentOptimizer( learning_rate=learning_rate).minimize( loss=loss, var_list=tf.trainable_variables(), global_step=global_step # 不指定的话学习率不更新 ) with tf.name_scope('eval'): correct = tf.nn.in_top_k(logits, tf.argmax(y, axis=1), 1) # 目标是否在前K个预测中, label's dtype is int* accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) # 5. initialize # ================= # 复用隐含层的权重 reuse_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='hidden[12]') # regular expression reuse_vars_dict = dict([(var.op.name, var) for var in reuse_vars]) restore_saver = tf.train.Saver(reuse_vars_dict) # to restore hidden1 & hidden2 # ================= init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()) saver = tf.train.Saver() # ================= print([v.name for v in tf.trainable_variables()]) print([v.name for v in tf.global_variables()]) # ================= # 6. train & test n_epochs = 20 batch_size = 50 with tf.Session() as sess: sess.run(init_op) # ================= restore_saver.restore(sess, './my_model_final.ckpt') # ================= for epoch in range(n_epochs): for iteration in range(mnist.train.num_examples // batch_size): X_batch, y_batch = mnist.train.next_batch(batch_size) sess.run([optimizer_op, learning_rate], feed_dict={X: X_batch, y: y_batch, is_training:True}) learning_rate_cur = learning_rate.eval() acc_train = accuracy.eval(feed_dict={X: X_batch, y: y_batch, is_training:False}) # 最后一个 batch 的 accuracy acc_test = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training:False}) loss_test = loss.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training:False}) print(epoch, "Current learning rate:", learning_rate_cur, "Train accuracy:", acc_train, "Test accuracy:", acc_test, "Test loss:", loss_test) save_path = saver.save(sess, "./new_my_model_final.ckpt")
=================================================================
场景三
If the model was trained using another framework, you will need to load the weights
manually (e.g., using Theano code if it was trained with Theano), then assign them to
the appropriate variables.
示例代码:
简单起见,这里直接保存 hidden1 和 hidden2 的权重作为后续使用:
import tensorflow as tf import numpy as np checkpoint_path = 'my_model_final.ckpt' reader = tf.pywrap_tensorflow.NewCheckpointReader(checkpoint_path) var_to_shape_map = reader.get_variable_to_shape_map() # Savw the part weight weights = dict() for key in var_to_shape_map: print("tensor_name: ", key) if key == 'hidden1/kernel': weights['hidden1/kernel'] = reader.get_tensor(key) elif key == 'hidden2/kernel': weights['hidden2/kernel'] = reader.get_tensor(key) elif key == 'hidden1/bias': weights['hidden1/bias'] = reader.get_tensor(key) elif key == 'hidden2/bias': weights['hidden2/bias'] = reader.get_tensor(key) np.savez('weights',weights=weights)
接下来,我们就可以导入权重并赋值给网络了:
import tensorflow as tf import numpy as np # 1. create data from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('../MNIST_data', one_hot=True) X = tf.placeholder(tf.float32, shape=(None, 784), name='X') y = tf.placeholder(tf.int32, shape=(None), name='y') is_training = tf.placeholder(tf.bool, None, name='is_training') # 2. define network he_init = tf.contrib.layers.variance_scaling_initializer() with tf.name_scope('dnn'): hidden1 = tf.layers.dense(X, 300, kernel_initializer=he_init, name='hidden1') hidden1 = tf.layers.batch_normalization(hidden1, momentum=0.9) hidden1 = tf.nn.relu(hidden1) hidden2 = tf.layers.dense(hidden1, 100, kernel_initializer=he_init, name='hidden2') hidden2 = tf.layers.batch_normalization(hidden2, training=is_training, momentum=0.9) hidden2 = tf.nn.relu(hidden2) logits = tf.layers.dense(hidden2, 10, kernel_initializer=he_init, name='output') # 3. define loss with tf.name_scope('loss'): loss = tf.losses.softmax_cross_entropy(onehot_labels=y, logits=logits) # label is one_hot # 4. define optimizer learning_rate_init = 0.01 global_step = tf.Variable(0, trainable=False) with tf.name_scope('train'): learning_rate = tf.train.polynomial_decay( # 多项式衰减 learning_rate=learning_rate_init, # 初始学习率 global_step=global_step, # 当前迭代次数 decay_steps=22000, # 在迭代到该次数实际,学习率衰减为 learning_rate * dacay_rate end_learning_rate=learning_rate_init / 10, # 最小的学习率 power=0.9, cycle=False ) update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) # for batch normalization with tf.control_dependencies(update_ops): optimizer_op = tf.train.GradientDescentOptimizer( learning_rate=learning_rate).minimize( loss=loss, var_list=tf.trainable_variables(), global_step=global_step # 不指定的话学习率不更新 ) with tf.name_scope('eval'): correct = tf.nn.in_top_k(logits, tf.argmax(y, axis=1), 1) # 目标是否在前K个预测中, label's dtype is int* accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) # 5. initialize # ================= # Get a handle on the assignment nodes for the hidden1 variables graph = tf.get_default_graph() assign_kernel1 = graph.get_operation_by_name("hidden1/kernel/Assign") assign_bias1 = graph.get_operation_by_name("hidden1/bias/Assign") assign_kernel2 = graph.get_operation_by_name("hidden2/kernel/Assign") assign_bias2 = graph.get_operation_by_name("hidden2/bias/Assign") init_kernel1 = assign_kernel1.inputs[1] init_bias1 = assign_bias1.inputs[1] init_kernel2 = assign_kernel2.inputs[1] init_bias2 = assign_bias2.inputs[1] weights = np.load('weights.npz', allow_pickle=True) weights_value = weights['weights'][()] # ================= init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()) saver = tf.train.Saver() # ================= print([v.name for v in tf.trainable_variables()]) print([v.name for v in tf.global_variables()]) # ================= # 6. train & test n_epochs = 20 batch_size = 50 with tf.Session() as sess: sess.run(init_op, feed_dict={init_kernel1: weights_value['hidden1/kernel'], init_bias1: weights_value['hidden1/bias'], init_kernel2: weights_value['hidden2/kernel'], init_bias2: weights_value['hidden2/bias'] } ) for epoch in range(n_epochs): for iteration in range(mnist.train.num_examples // batch_size): X_batch, y_batch = mnist.train.next_batch(batch_size) sess.run([optimizer_op,learning_rate], feed_dict={X: X_batch, y: y_batch, is_training:True}) learning_rate_cur = learning_rate.eval() acc_train = accuracy.eval(feed_dict={X: X_batch, y: y_batch, is_training:False}) # 最后一个 batch 的 accuracy acc_test = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training:False}) loss_test = loss.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training:False}) print(epoch, "Current learning rate:", learning_rate_cur, "Train accuracy:", acc_train, "Test accuracy:", acc_test, "Test loss:", loss_test) save_path = saver.save(sess, "./new_my_model_final.ckpt")
再看另外一种方式:
import tensorflow as tf import numpy as np # 1. create data from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('../MNIST_data', one_hot=True) X = tf.placeholder(tf.float32, shape=(None, 784), name='X') y = tf.placeholder(tf.int32, shape=(None), name='y') is_training = tf.placeholder(tf.bool, None, name='is_training') # 2. define network he_init = tf.contrib.layers.variance_scaling_initializer() with tf.name_scope('dnn'): hidden1 = tf.layers.dense(X, 300, kernel_initializer=he_init, name='hidden1') hidden1 = tf.layers.batch_normalization(hidden1, momentum=0.9) hidden1 = tf.nn.relu(hidden1) hidden2 = tf.layers.dense(hidden1, 100, kernel_initializer=he_init, name='hidden2') hidden2 = tf.layers.batch_normalization(hidden2, training=is_training, momentum=0.9) hidden2 = tf.nn.relu(hidden2) logits = tf.layers.dense(hidden2, 10, kernel_initializer=he_init, name='output') # 3. define loss with tf.name_scope('loss'): loss = tf.losses.softmax_cross_entropy(onehot_labels=y, logits=logits) # label is one_hot # 4. define optimizer learning_rate_init = 0.01 global_step = tf.Variable(0, trainable=False) with tf.name_scope('train'): learning_rate = tf.train.polynomial_decay( # 多项式衰减 learning_rate=learning_rate_init, # 初始学习率 global_step=global_step, # 当前迭代次数 decay_steps=22000, # 在迭代到该次数实际,学习率衰减为 learning_rate * dacay_rate end_learning_rate=learning_rate_init / 10, # 最小的学习率 power=0.9, cycle=False ) update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) # for batch normalization with tf.control_dependencies(update_ops): optimizer_op = tf.train.GradientDescentOptimizer( learning_rate=learning_rate).minimize( loss=loss, var_list=tf.trainable_variables(), global_step=global_step # 不指定的话学习率不更新 ) with tf.name_scope('eval'): correct = tf.nn.in_top_k(logits, tf.argmax(y, axis=1), 1) # 目标是否在前K个预测中, label's dtype is int* accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) # 5. initialize # ================= # Get a handle on the assignment nodes for the hidden variables with tf.variable_scope('', default_name='', reuse=True): hidden1_weights = tf.get_variable("hidden1/kernel") hidden1_biases = tf.get_variable("hidden1/bias") hidden2_weights = tf.get_variable("hidden2/kernel") hidden2_biases = tf.get_variable("hidden2/bias") original_weights1 = tf.placeholder(tf.float32, shape=(784, 300)) original_biases1 = tf.placeholder(tf.float32, shape=300) original_weights2 = tf.placeholder(tf.float32, shape=(300, 100)) original_biases2 = tf.placeholder(tf.float32, shape=100) assign_hidden1_weights = tf.assign(hidden1_weights, original_weights1) assign_hidden1_biases = tf.assign(hidden1_biases, original_biases1) assign_hidden2_weights = tf.assign(hidden2_weights, original_weights2) assign_hidden2_biases = tf.assign(hidden2_biases, original_biases2) weights = np.load('weights.npz', allow_pickle=True) weights_value = weights['weights'][()] # ================= init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()) saver = tf.train.Saver() # ================= print([v.name for v in tf.trainable_variables()]) print([v.name for v in tf.global_variables()]) # ================= # 6. train & test n_epochs = 20 batch_size = 55000 with tf.Session() as sess: sess.run(init_op) sess.run([assign_hidden1_weights, assign_hidden1_biases, assign_hidden2_weights, assign_hidden2_biases], feed_dict={original_weights1: weights_value['hidden1/kernel'], original_biases1: weights_value['hidden1/bias'], original_weights2: weights_value['hidden2/kernel'], original_biases2: weights_value['hidden2/bias'] } ) for epoch in range(n_epochs): for iteration in range(mnist.train.num_examples // batch_size): X_batch, y_batch = mnist.train.next_batch(batch_size) sess.run([optimizer_op, learning_rate], feed_dict={X: X_batch, y: y_batch, is_training:True}) learning_rate_cur = learning_rate.eval() acc_train = accuracy.eval(feed_dict={X: X_batch, y: y_batch, is_training:False}) # 最后一个 batch 的 accuracy acc_test = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training:False}) loss_test = loss.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training:False}) print(epoch, "Current learning rate:", learning_rate_cur, "Train accuracy:", acc_train, "Test accuracy:", acc_test, "Test loss:", loss_test) save_path = saver.save(sess, "./new_my_model_final.ckpt")
等价于:
import tensorflow as tf import numpy as np # 1. create data from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('../MNIST_data', one_hot=True) X = tf.placeholder(tf.float32, shape=(None, 784), name='X') y = tf.placeholder(tf.int32, shape=(None), name='y') is_training = tf.placeholder(tf.bool, None, name='is_training') # 2. define network he_init = tf.contrib.layers.variance_scaling_initializer() with tf.name_scope('dnn'): hidden1 = tf.layers.dense(X, 300, kernel_initializer=he_init, name='hidden1') hidden1 = tf.layers.batch_normalization(hidden1, momentum=0.9) hidden1 = tf.nn.relu(hidden1) hidden2 = tf.layers.dense(hidden1, 100, kernel_initializer=he_init, name='hidden2') hidden2 = tf.layers.batch_normalization(hidden2, training=is_training, momentum=0.9) hidden2 = tf.nn.relu(hidden2) logits = tf.layers.dense(hidden2, 10, kernel_initializer=he_init, name='output') # 3. define loss with tf.name_scope('loss'): loss = tf.losses.softmax_cross_entropy(onehot_labels=y, logits=logits) # label is one_hot # 4. define optimizer learning_rate_init = 0.01 global_step = tf.Variable(0, trainable=False) with tf.name_scope('train'): learning_rate = tf.train.polynomial_decay( # 多项式衰减 learning_rate=learning_rate_init, # 初始学习率 global_step=global_step, # 当前迭代次数 decay_steps=22000, # 在迭代到该次数实际,学习率衰减为 learning_rate * dacay_rate end_learning_rate=learning_rate_init / 10, # 最小的学习率 power=0.9, cycle=False ) update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) # for batch normalization with tf.control_dependencies(update_ops): optimizer_op = tf.train.GradientDescentOptimizer( learning_rate=learning_rate).minimize( loss=loss, var_list=tf.trainable_variables(), global_step=global_step # 不指定的话学习率不更新 ) with tf.name_scope('eval'): correct = tf.nn.in_top_k(logits, tf.argmax(y, axis=1), 1) # 目标是否在前K个预测中, label's dtype is int* accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) # 5. initialize # ================= weights = np.load('weights.npz', allow_pickle=True) weights_value = weights['weights'][()] # Get a handle on the assignment nodes for the hidden variables with tf.variable_scope('', default_name='', reuse=True): hidden1_weights = tf.get_variable("hidden1/kernel") hidden1_biases = tf.get_variable("hidden1/bias") hidden2_weights = tf.get_variable("hidden2/kernel") hidden2_biases = tf.get_variable("hidden2/bias") assign_hidden1_weights = tf.assign(hidden1_weights, weights_value['hidden1/kernel']) assign_hidden1_biases = tf.assign(hidden1_biases, weights_value['hidden1/bias']) assign_hidden2_weights = tf.assign(hidden2_weights, weights_value['hidden2/kernel']) assign_hidden2_biases = tf.assign(hidden2_biases, weights_value['hidden2/bias']) tf.add_to_collection('initilizer',assign_hidden1_weights) tf.add_to_collection('initilizer',assign_hidden1_biases) tf.add_to_collection('initilizer',assign_hidden2_weights) tf.add_to_collection('initilizer',assign_hidden2_biases) weights_ops = tf.get_collection("initilizer") # ================= init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()) saver = tf.train.Saver() # ================= print([v.name for v in tf.trainable_variables()]) print([v.name for v in tf.global_variables()]) # ================= # 6. train & test n_epochs = 20 batch_size = 50 with tf.Session() as sess: sess.run(init_op) sess.run(weights_ops) for epoch in range(n_epochs): for iteration in range(mnist.train.num_examples // batch_size): X_batch, y_batch = mnist.train.next_batch(batch_size) sess.run([optimizer_op, learning_rate], feed_dict={X: X_batch, y: y_batch, is_training:True}) learning_rate_cur = learning_rate.eval() acc_train = accuracy.eval(feed_dict={X: X_batch, y: y_batch, is_training:False}) # 最后一个 batch 的 accuracy acc_test = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training:False}) loss_test = loss.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels, is_training:False}) print(epoch, "Current learning rate:", learning_rate_cur, "Train accuracy:", acc_train, "Test accuracy:", acc_test, "Test loss:", loss_test) save_path = saver.save(sess, "./new_my_model_final.ckpt")
冻结 Low Layers
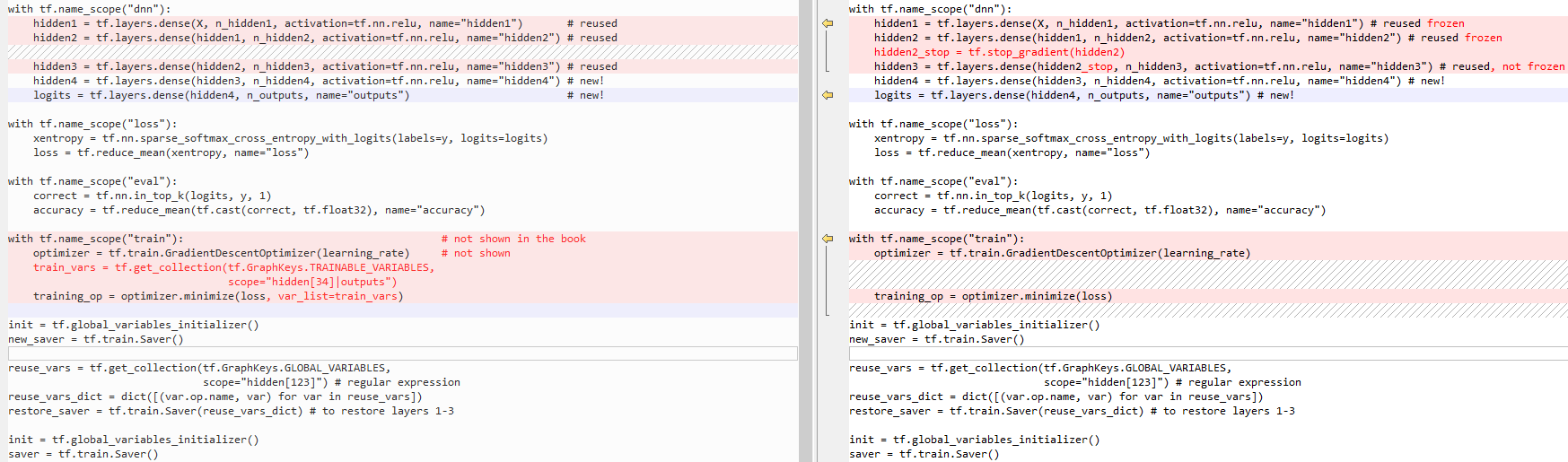
两种方式,如下图所示: