参考原文:EPUB弹出窗口式脚注
网上搜到一些国学典籍的EPUB版,虽有古人的注解,但正文和注解混排在一起,当我只想迅速读正文的时候比较碍眼。于是研究了一下 EPUB3 中有关脚注(footnote)的规格定义,写了一个 Python 脚本把所有混在正文中的脚注全部改写成了弹出窗口样式,在 iBooks 里测试通过,略记一笔。
什么是EPUB弹出窗口式脚注
弹出式脚注是 EPUB3 推出的,简单的说就是正文中加一个链接锚点,对应一个脚注模块,点击链接的时候,脚注内容会直接以弹出窗口的形式显示出来。这样就省去了页面跳转这个步骤,更加方便阅读。
一图胜千言,下图是脚本处理后的《三国志》(这个还是混排版的)在 iPad 版 iBooks 下的效果。(原本是像日文电子书那样的竖排EPUB,我把 CSS 里和竖排相关的定义注释掉了)

如何实现EPUB弹出窗口式脚注
要实现这种效果,有三个注意点。
1.正文中的链接锚点。
<p>
太祖武皇帝,沛國譙人也,姓曹,諱操,字孟德,漢相國參之後。
<a epub:type="noteref" href="#fn1">
<sup>1</sup>
</a>
桓帝世,曹騰為中常侍大長秋,封費亭侯。
......
</p>
2.脚注aside模块
<aside epub:type="footnote" id="fn1">
〔曹瞞傳曰:太祖一名吉利,小字阿瞞。王沈魏書曰:其先出於黃帝。當高陽世,陸終之子曰安,是為曹姓。周武王克殷,存先世之後,封曹俠於邾。春秋之世,與於盟會,逮至戰國,為楚所滅。子孫分流,或家於沛。漢高祖之起,曹參以功封平陽侯,世襲爵士,絶而復紹,至今適嗣國於容城。〕
</aside>
在 iBooks 下,如果 epub:type 属性的值为 footnote ,这个 aside 会默认隐藏。只有对应的链接被点击时,其内容才会在弹出窗口中显示。
3.epub 命名空间(namespace)。
上面两处都有一个共同的属性名,epub:type。一般 EPUB 文档都没有定义 epub 这个命名空间,所以满足以上两点之后直接打开会提示 epub 命名空间没有定义。EPUB 定义 namespace 有两种方式,一种是在 CSS 里定义,一种是在内容页的HTML标签里定义。我测试过,iBooks 无法识别 CSS 里定义的 namespace,所以我采用了另外一种方式。
<html xml:lang="zh-CN" xmlns="http://www.w3.org/1999/xhtml" xmlns:xml="http://www.w3.org/XML/1998/namespace" xmlns:epub="http://www.idpf.org/2007/ops">
用Python脚本处理EPUB的HTML文档
了解了这些基本概念之后,再来看要处理的对象。原EPUB文档中注解夹杂在正文中,以span标签标记,所以 Python 脚本的基本流程就比较清楚了,这里使用 BeautifulSoup 来解析并更改 HTML 文档树。
- 循环读入所有 EPUB 内容文档并解析
- 给
html标签加上 epub 命名空间定义 - 获取
p标签下的 所有span标签 - 遍历获取的
span标签,取出文本,并以此创建aside模块 - 清除
span标签的内容,更改为链接锚点
原 EPUB 中的 HTML 文档节选 :
<p>太祖武皇帝,沛國譙人也,姓曹,諱操,字孟德,漢相國參之後。
<span class="zhushi">
〔曹瞞傳曰:太祖一名吉利,小字阿瞞。王沈魏書曰:其先出於黃帝。當高陽世,陸終之子曰安,是為曹姓。周武王克殷,存先世之後,封曹俠於邾。春秋之世,與於盟會,逮至戰國,為楚所滅。子孫分流,或家於沛。漢高祖之起,曹參以功封平陽侯,世襲爵士,絶而復紹,至今適嗣國於容城。〕
</span>
桓帝世,曹騰為中常侍大長秋,封費亭侯。
......
</p>
在 OS X 版 iBooks 中的显示效果,正文注释混排。

详细处理方式见下面的 Python 代码 :
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import os epub_content_path = 'E:MachineLearningsanguozhi_bak.epubOEBPSText' #zizhitongjian_path='E:MachineLearningzizhitongjian.epubOEBPSText' #for f in os.listdir(zizhitongjian_path): for f in os.listdir(epub_content_path): #html = os.path.join(zizhitongjian_path,f) html = os.path.join(epub_content_path,f) print html doc = open(html,'rb') soup = BeautifulSoup(doc) #如果没有HTML标签里没有定义epub namespace,则加上 if not 'xmlns:epub' in soup.html.attrs: soup.html['xmlns:epub'] = "http://www.idpf.org/2007/ops" #没有使用soup.find_all('span')是为了略过<span>中内嵌<span>的情况 #???假如有嵌套的怎么办呢? #因为原文里面是每一句话后面都有一个注释(zhushi) notes = soup.select('p > span') #如果没有找到span标签,进入下一个循环,也就是进入下一个html文件 if not notes: continue #反序循环notes 列表 #len(notes)统计有多少个zhushi(note) for n in range(len(notes)-1, -1, -1): #n是列表index,number是实际注释序号 note = notes[n] number = n+1 footnote = soup.new_tag('aside') footnote['epub:type'] = 'footnote' footnote['id'] = 'fn%d' % number footnote.string = note.get_text() #-----------------------change by cici------------------------------------------------- #-----------------------add a new tag:脚注前缀标识---------------------------------- ##需要在脚注前面加上这句话,可以跳转到原文里面去<a href="#fns1">[1]</a> ##<a href="#fns1">[1]</a> #change by cici footnotesup = soup.new_tag('a') footnotesup['href'] = '#fns%d' % number footnotesup.string = '['+str(number)+']' #--------------------------------------------------------------------------------------- #---------------------------在注释的前边假如数字[1]-------------------------------- #下面这句是在footnote的string前面加入一个tag footnotesup footnote.string.insert_before(footnotesup); #--------------------------------------------------------------------------------------- #为了保证aside模块是按数字顺序逐一插入到段落之后,所以反序读取notes列表 note.parent.insert_after(footnote) #--------------------------------------------------------------------------------------- #note.parent.insert_after(footnotesup) #--------------------------------------------------------------------------------------- note.clear() note.name = "a" del note['class'] note['epub:type'] = 'noteref' note['href'] = '#fn%d' % number #自己修改对上标假如id note['id'] = 'fns%d' % number sup = soup.new_tag('sup') sup.string = str(number) note.append(sup) #print soup.prettify() doc.close() doc = open(html,'wb') doc.write(str(soup)) doc.close()
注释锚点的美化
为了让链接锚点看起来美观一点,我顺手在CSS里给sup添加了几个定义。其中 text-indent是为了重置原CSS代码中 p 标签中的定义,其他的就没什么好说的了。
sup { font-family: Arial; font-size: 0.5em; color:#FFF; background-color: #333; display: inline-block; border-radius:0.25em; /* reset text-indent */ text-indent: 0; padding:0 0.5em; box-shadow: 0px 1px 1px #333; text-shadow: 0 -1px 0 #333; }
其实在 epub 的 CSS 里定义颜色是一件不太好的事,以 iBooks 为例,主题分纯白、棕褐、夜间三种模式,如果 hardcode 颜色,主题变更时颜色不随之变化就会很难看。不过 iBooks 也似乎没有提供一个办法来解决这种矛盾,所以作罢。
iBooks 对 EPUB3 标准的支持
iBooks 对 EPUB3 的支持也并不完全,除了上文提到的CSS命名空间之外,aside的 CSS 样式 iBooks 也不支持,此外还有很多槽点。好像这也是苹果的一贯风格——把现有的处于上升趋势的技术拿来为我所用,然后搞一个私有的变种出来,至于标准,就随便随便啦。
苹果现在对 iBooks 似乎也不是很上心了,可能在电子出版方面遇到的阻力很大,没有帮主的现实扭曲立场,在可见的未来也不太可能复制当年在音乐出版上的成功,于是 iBooks 的臭虫一堆也没人修复,新功能也不见有什么添加,似乎已经很久没有更新了。
可惜现在网上流传的四书五经、二十四史之类的 EPUB 制作良莠不齐,HTML定义也不尽相同,所以没法弄一个通用的脚本出来,只能见招拆招。
注意事项:
- 在制作这个之前要求电脑上已经安装了Python2.6(或2.7),没有测试Python3.4版本,并且已经安装了BeautifulSoup库。
- 因为EPUB属于一种压缩文件,需要先将EPUB文件加上".zip"后缀,然后用Winrar或7zip将其解压成***.epub文件夹,再进行代码里面的操作,不然的话,Python程序不能打开EPUB压缩文件。最后用Python程序处理完成之后,同样的过程用7zip将几个文件夹打包压缩成zip压缩包(EPUB阅读器不识别rar压缩的格式),然后将后缀“.zip”去掉就可以了。
对于原作者提供的代码和文件做了一定的修改,现在讲修改的部分贴出来。
1.第43-55行,在脚注的文本前面加上了<a href="#fns1">[1]</a>,实际显示为[1]。点击可以跳转到脚注对应的原文。
#-----------------------change by cici------------------------------------------------- #-----------------------add a new tag:脚注前缀标识---------------------------------- ##需要在脚注前面加上这句话,可以跳转到原文里面去<a href="#fns1">[1]</a> ##<a href="#fns1">[1]</a> #change by cici footnotesup = soup.new_tag('a') footnotesup['href'] = '#fns%d' % number footnotesup.string = '['+str(number)+']' #--------------------------------------------------------------------------------------- #---------------------------在注释的前边假如数字[1]-------------------------------- #下面这句是在footnote的string前面加入一个tag footnotesup footnote.string.insert_before(footnotesup);
2.第70-71行,加上了上标的id,脚注可以通过这个id跳转到原文中。
#自己修改对上标假如id note['id'] = 'fns%d' % number
参考文章:
后记:效果图
最后修改完成图书《三國志-陳壽》(共享密码:17ib),下图是在Windows+Calibre上现实的效果图。
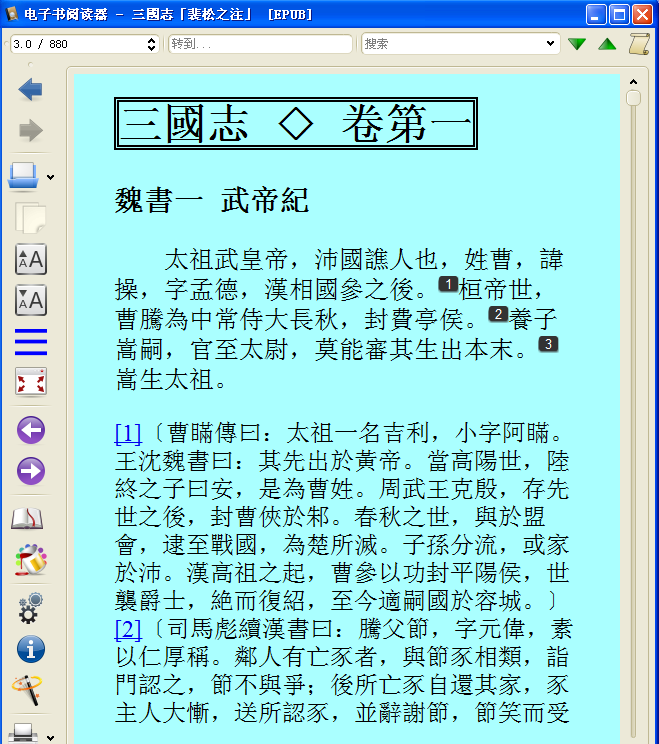
后续增加:
发现多看的手机和Kindle版本的多看是可以显示脚注的,可能和EPUB3.0的实现方式不同,就跟iBOOKS是类似的,不过这样的确是增加了一个选择的机会。
在博客园非官方月刊这篇文章中作者制作的电子书的确是可以显示脚注的,而且显示的效果还是不错的,多看是目前在国内发现的性能和体验最好的电子书阅读器APP。
多看也在自己的官方论坛贴出了关于如何制作带有脚注EPUB电子书的方法:多看电子书规范扩展开放计划
显示效果如下图(在Android手机平台):
