论文题目Finding Action Tubes, 论文链接
该篇论文是CVPR 2015的, 主要讲述了action tube的localization.
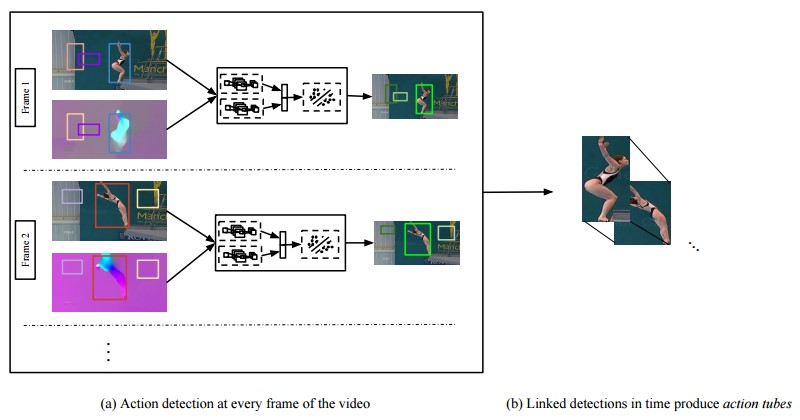
直接看图说话, 该论文的核心思想/步骤可以分为两个components:
1 Action detection at every frame of the video
2 Linked detection in time produce action tubes
下面就分开来说每个component.
1 Action detection at every frame of the video
大概思想就是: 训练Spatial-CNN和Motion-CNN来提feature, 在feature上为每个类别训练线性svm. 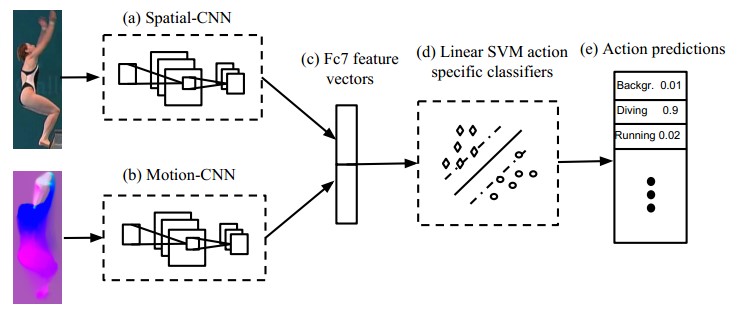

具体步骤如下:
a. 找出each frame的interesting regions. 基于ground-truth的region及action label, 构建正负样本.
这里用IoU的方法: >0.5 为positive region, <0.3为negative region.
为什么要这样做呢? 个人觉得论文里面的action tube是针对里面的actor来弄的,
也就是对视频里面的某个actor进行action的跟踪和action 分类.
必然数据集会给出视频的每一帧的action类别和对应的actor.
那么怎么找出这些regions? 以及怎么消除不必要的regions?
对于proposals的产生会有很多方法, 论文里面采用了selective search的方法来产生视频里每帧的proposals(大约2K)
显然这些proposals很大一部分是non-discriminative的, 而且会造成计算上严重的消耗, 不利于实时检测.
论文里面用了一种很简单的方法来消去这些not descriptive的regions:

需要注意的是, rgb和motion images的regions是一样的,
也就是prososals是用上述方法在rgb上提取到, 然后直接用到motion上的.
b. 训练Spatial-CNN和Motion-CNN
这里就展开说这两个CNN模型的framework了, 具体看论文.
个人觉的该训练的要点有两个:
i. 在单帧上训练的.
ii. CNN模型的初始化.
众所周知, deep model的初始化很重要.
Spatial-CNN是用在Pascal Voc 2012的detection task上训练好的CNN模型来初始化.
Motion-CNN则是在UCF101 Motion数据集上训练好的CNN模型来初始化.
至于训练时的一些细节问题, 如学习率, 数据argumentation等, 请各位看官自己看论文哈.
c. 提取训练Spatial-CNN和Motion-CNN的FC7特征
这里只是将CNNs的fc7特征拼接起来, 简单暴力.
d. 训练actions的linear svms.
2 Linked detection in time produce action tubes
这一步是基于component 1来弄的.
a. 对每帧提取相应的regions, 每个region过Spatial-CNN和Motion-CNN, 来提取fc7特征,
后经svms, 来获取对应的action scores.
b. 对每个类别, 每个视频, 利用下图的公式来找出linked-action tubes.
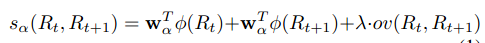
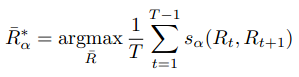
即通过找出相邻两帧之间属于某个action类别的得分最高(score+IoU)的两个regions(一帧一个)
然后将这些regions串联起来形成action tube.
那么怎么计算一个action tube的action acore?
当然论文没有这么就完事了, 基于action tube的基础上, 进行了video的action classification.
这个非常简单, 请看公式:

至于效果嘛, 肯定是state-of-art的说说.


该篇论文的main contributions, 个人觉有以下几点:
a. 结合了Appearance和Motion signals.
b. 证实了Appearance和Motion signals是complementary的.
c. 用Motion signal来消去那些non-discriminative的regions, 这个比较新颖.
当然也有不足:
a. dataset大部分是针对一个actor的, 该方法会在多个actor的情况下效果是非常poor的.
b. Motion是事先算好的, 而不是学习的.
c. 整个framework非常pipeline.
好吧, 不会吐槽, 莫怪, 莫怪.
欢迎前来骚扰...