分类
- 艺人:选取08月总值较高的14个艺人作为研究对象
- 用户:根据袁光浩PPT中对第11个线路画的每个用户刷卡次数的统计表
我们以用户user_id=b15e8846dc61824c1242a6b36796117b(播放量最高的艺人)为例,画出该艺人的用户183的播放量图像:
(127135*0.995=126499.3)如下是将用户总小到大取前126499个用户的图像:横轴是用户按播放量从小到大的编号,纵轴是用户总播放量。

可以看到用户两级分化,一部分用户的播放量特别的小,不到50;另一部分特点的大,甚至超高150。对此考虑对艺人的用户分类为粉丝用户和随机用户2类。
经过摸索,分类标准可以定义为使粉丝用户的总播放量和随机用户的总播放量尽可能对等。例如:
计算改艺人183天的总播放量是:115,3409,设n=35,一般用户a(a=users[users$play<n])总播放量:61,7199;此时粉丝用户b总播放量为:53,6210,人数;
此时总用户人数是12,7135,一般用户a有12,0375,粉丝用户b有6760个。
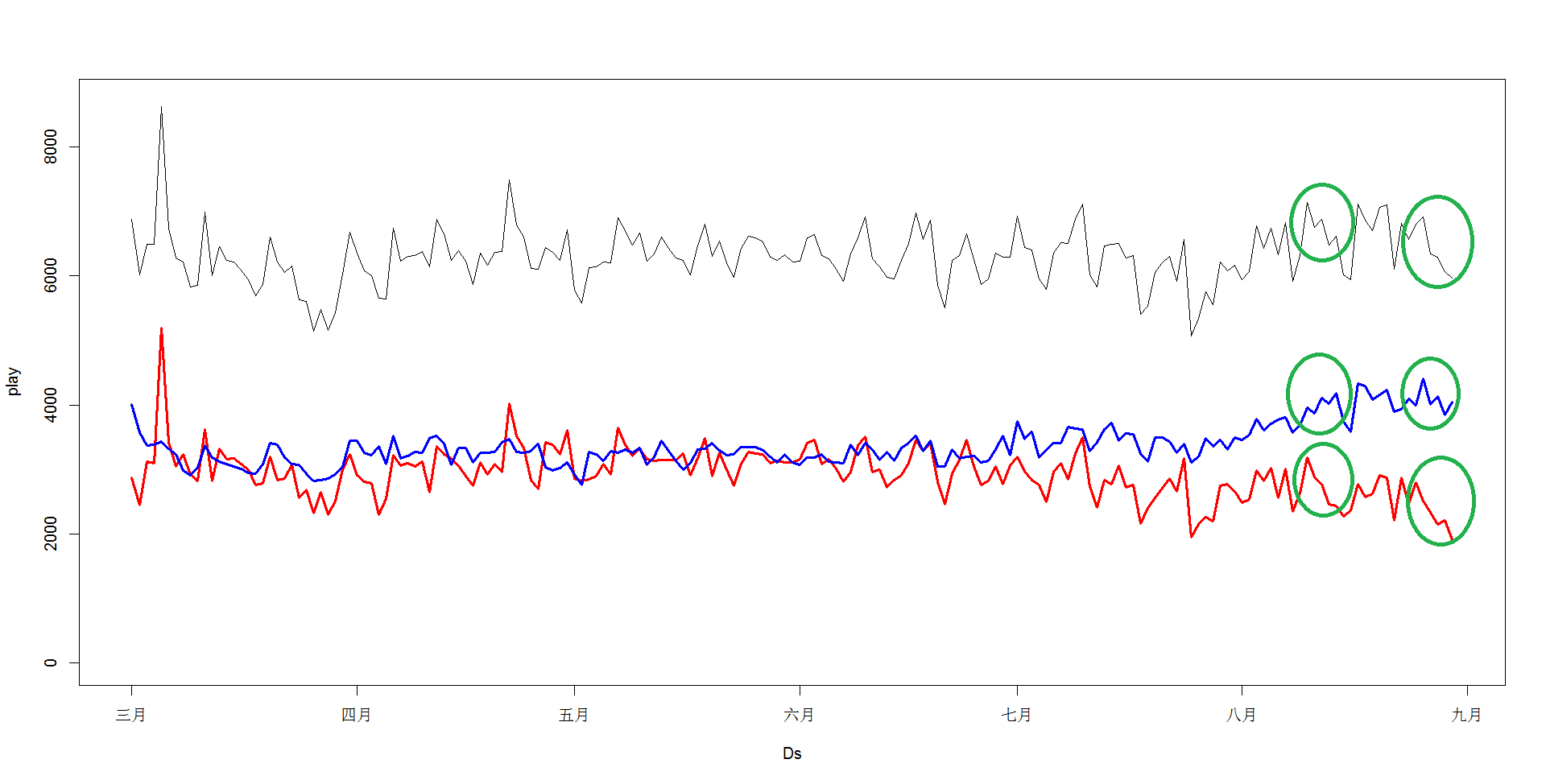
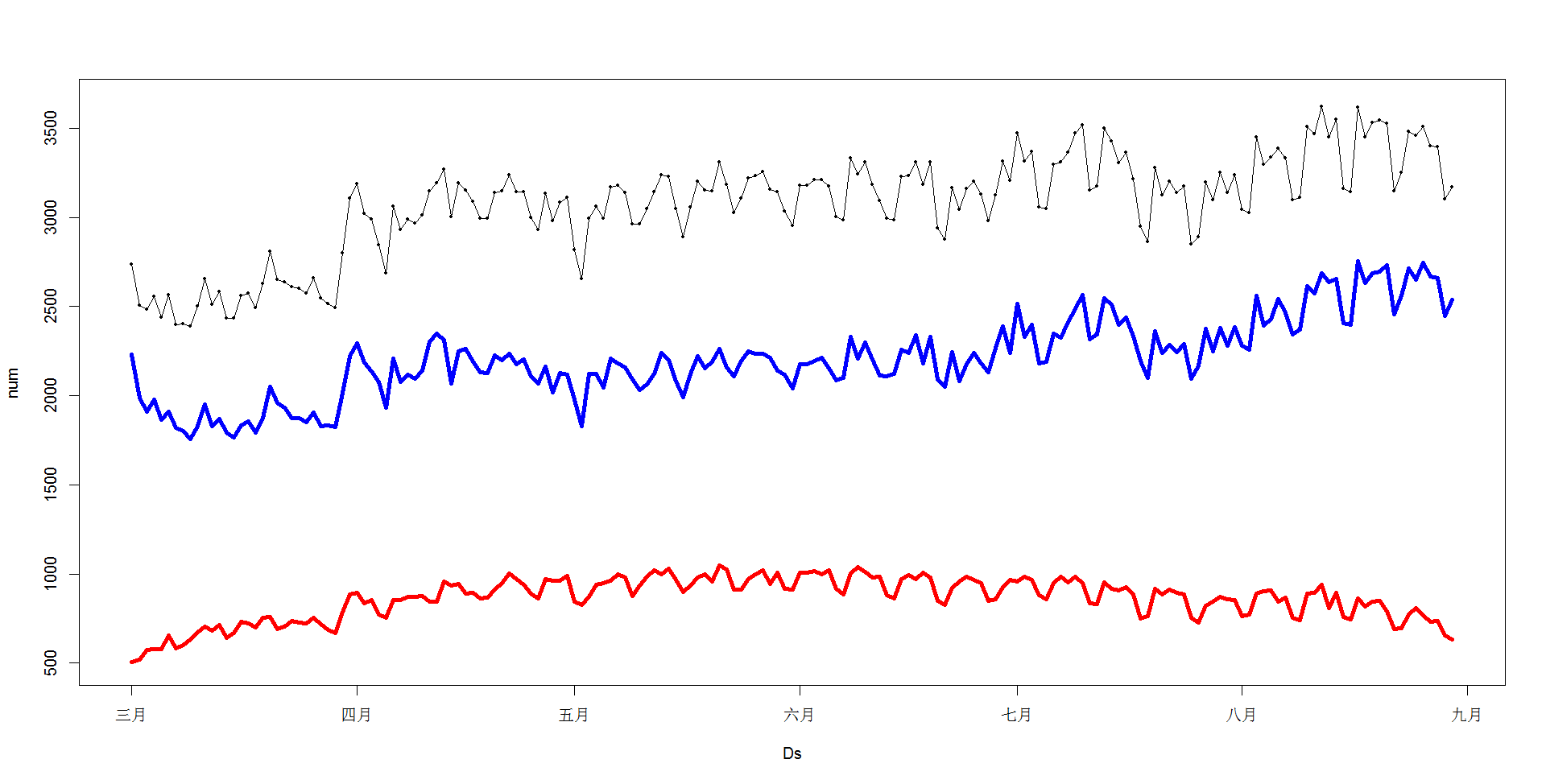
按用户划分后艺人每日的播放量(黑),一般用户a(蓝色)和粉丝用户b(红色)的点播量如下,以下绿色圈圈可以看出分类把两类用户按日不同的播放行为较好的显示出来。
从图中可以看出不同的用户点播趋势是不同的!一般用户上升,粉丝用户下降!为什么会是这样的趋势呢?
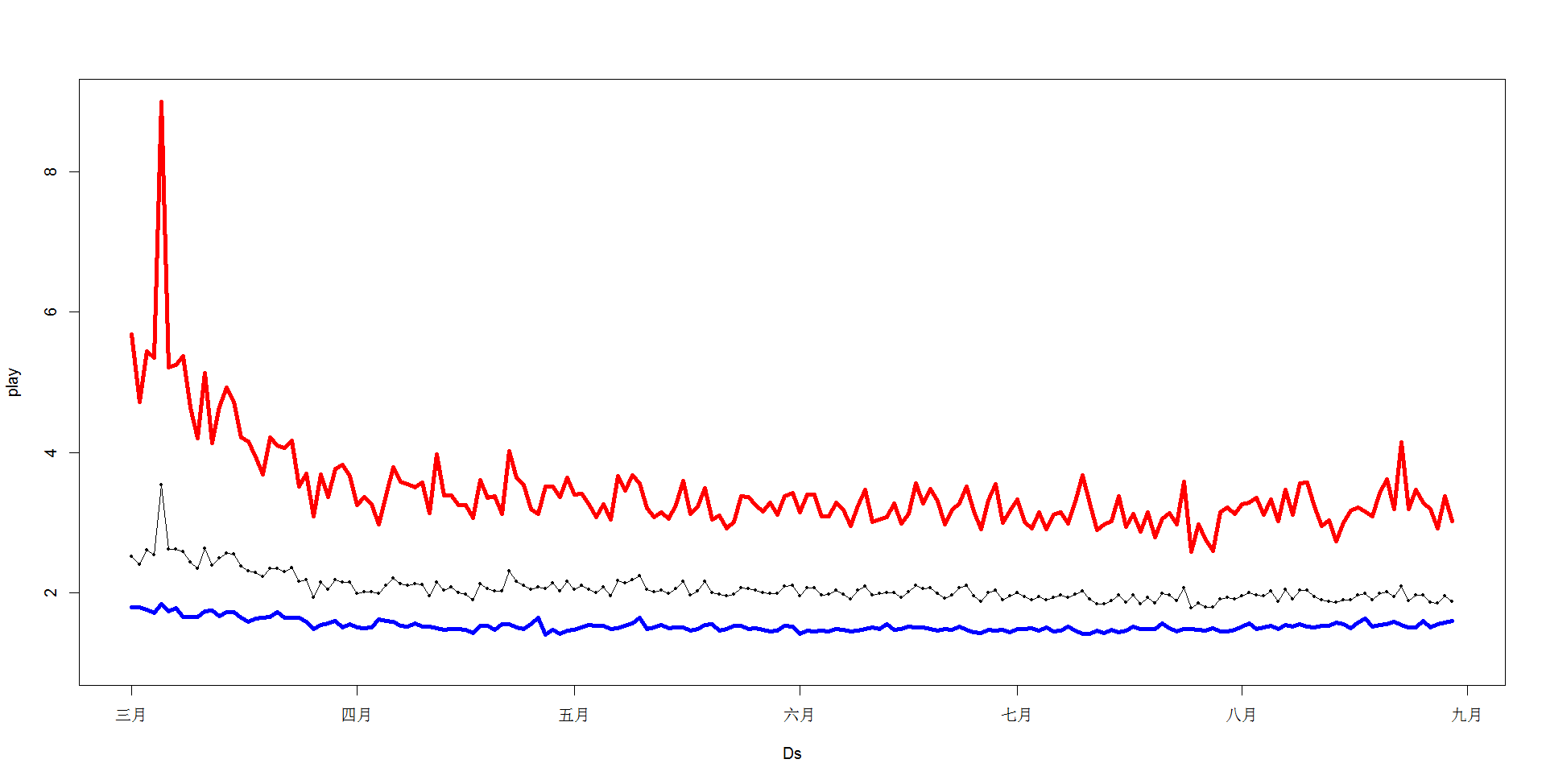
分析原因:由于 艺人当日播放量=艺人当日用户数*当日用户平均点播量,分别统计2类用户的每日平均点播量和每日用户人数,作图如下
1、每日平均点播量:
可以看出粉丝用户(红)每日平均播放量呈现趋势,大概是个二次多项式的下降趋势,越到后下降越缓慢;这可以解释总播放量那张图粉丝用户是下降的
一般用户(蓝)相比于粉丝用户每日平均播放量基本就是一个平稳的正态序列!
2、每日用户人数:
可以看出所有序列都呈现出较强的周期性(一周7天的特征)
一般用户(蓝)每日用户数呈上升趋势,这就是为什么总播放量那张图一般用户是上升的
粉丝用户(红)每日用户人数先增多后减少;相比于一般用户,人数趋于平稳序列(极差大概是500)
在观察前14个艺人的分类用户可以总结如下:
1、原先艺人每天的总播放量可以分解为2类用户每日播放量和:粉丝用户和一般用户的分类标准是尽量使2类用户的各自的总播放量相等,也就是播放量是对半的,但粉丝用户人数远小于一般用户。目前前14个艺人用到的播放量分界点有15,20,35,100,150。具体计算分界点可以写一个函数:(计算累加用户播放量与总用户播放放量一半的差值,去最小差值处播放量作为分界点值)先按用户播放量从大到小排序,然后循环累加用户播放量(比如设定播放量为15、20,35,100,150之类的),计算目前累加值与用户总播放量的一半的差值并记录,每次循环记录,取最小差值。(还没有实现!)
如下横轴是2类用户的每日的用户数,纵轴是每日的点播量,可以看出分类基本是正确的!
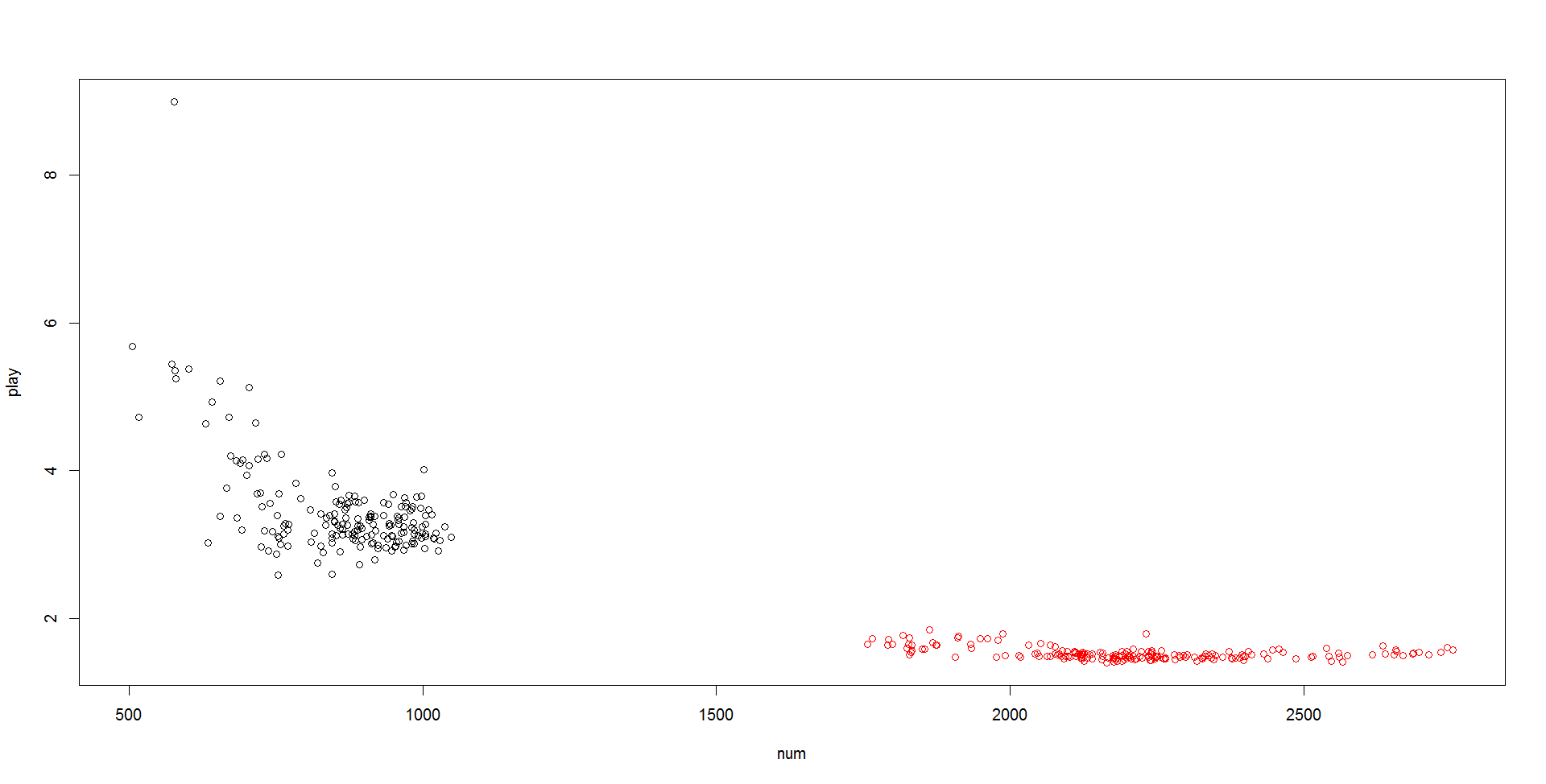
2、2类用户的每日播放量又可以分解为每日平均用户点播量和每日用户人数的乘积,并且大致符合以下规律:
- 每日平均点播量(无周期)
1、粉丝用户序列b1:有趋势2、一般用户序列a1:平稳
- 每日用户人数(有周期,7天)
1、粉丝用户序列b2:平稳2、一般用户序列a2:有趋势
因此我们主要的预测对象就是:
1、粉丝用户的每日平均点播量(b1)和一般用户的每日用户人数(a2),把2个时序分开做线性回归,a1和b2用均值代替(平稳序列),再代入公式:该play=a1*a2+b1*b2
2、周期,从每日用户人数中获取。
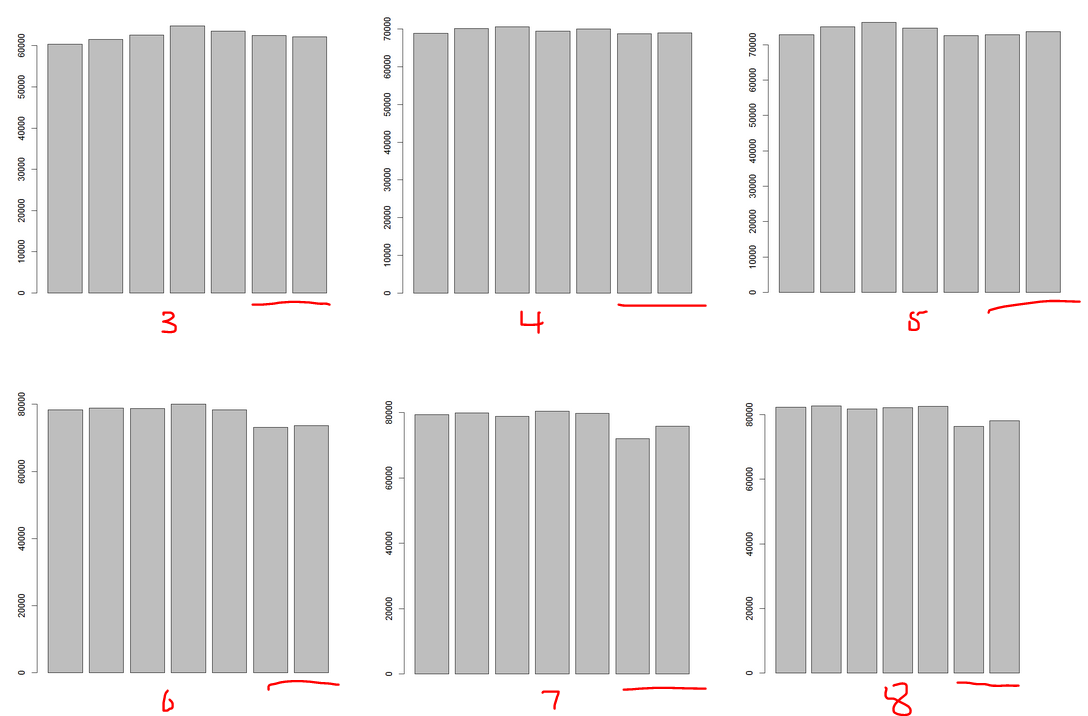
2.1以下是所有艺人的每月每周总播放量统计,趋势不是明显,但可以看出节假日(6、7天)与工作日(1~5天)有区别,节假日在最后三个月明显播放量变低!(明天再看)
2.2袁光浩PPT展示的2个线路每天刷卡人数按一周七天的的变化规律,建模方法是节假日、工作日单独建模,建立的自回归AR模型(时序模型,把(t-1天)因变量作为第t天的自变量带入计算) 之前理解有误,补充学习了时序模型知识之后才发现AR模型在实际运用中是在回归模型的基础上对残差建模预测平稳序列的,而袁光浩PPT右侧图中的模型并不是AR模型,这里指的是将客户分类,分为常客(Yfreq)和随机客(Yrand),分别建立线性回归模型做预测再叠加!还有一点要注意的剔除异常数据,发现规律,简化特征!我们目前特征有点多!


补充:
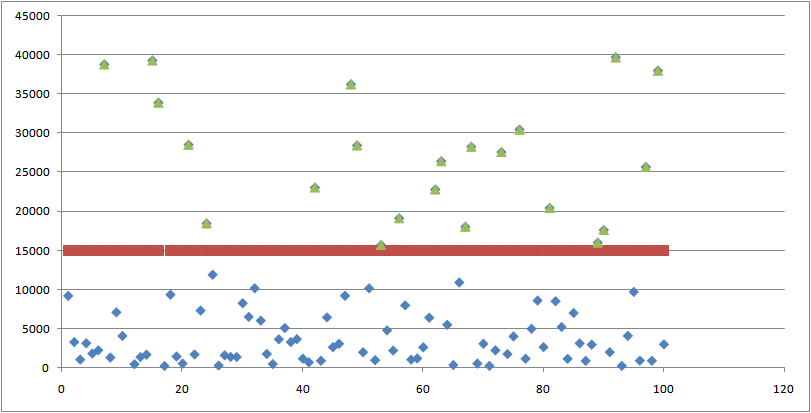
关于艺人分类:如下图所示用复赛数据每个艺人8月播放量均值画出散点图,可以很清晰的发现分类分界线是15000,将其分为2类:高播放量艺人和低播放量艺人,同时以8月均值作为60天每天的播放量,用评分公式计算完全预测准确时F值为64296.57135,其中高播放量艺人F总和为31413.58217,低播放量艺人F为32882.98918,恰巧是总F值的一半,说明这个分组群体是正确的,且2类艺人的评分都不可忽略!