概要
前面,我们已经学习了ArrayList。这一章我们接着学习List的实现类——LinkedList。和学习ArrayList一样,接下来呢,我们先对LinkedList有个整体认识,然后再学习它的源码;最后再通过实例来学会使用LinkedList。内容包括
1、LinkedList介绍
1、LinkedList介绍
LinkedList 类的集成关系:
1 public class LinkedList<E> 2 extends AbstractSequentialList<E> 3 implements List<E>, Deque<E>, Cloneable, java.io.Serializable 4 {
由此可知:
LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
LinkedList 实现 List 接口,能对它进行队列操作。
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
LinkedList 是非同步的。
既然LinkedList是基于链表结构的一种List,在分析LinkedList源码前有必要对链表结构进行说明。
链表结构说明:
简单来说,链接就是不使用数组,将元素想项链一样串起来。每一个元素包含集合中下一个元素的引用变量
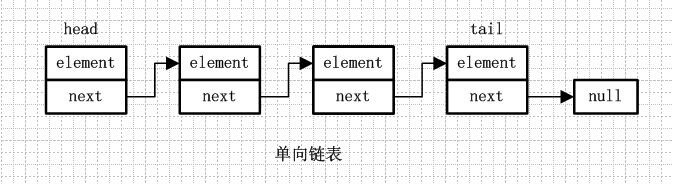
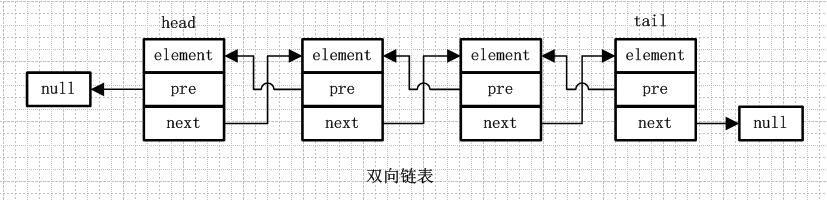
2、LinkedList数据结构
LinkedList一共有三个成员变量,分别为。
1 transient int size = 0; 2 3 transient Node<E> first; 4 5 transient Node<E> last;
size和ArrayList一样,用来记录集合所包含的元素数量。first用来记录集合的第一个元素,last用来记录集合的最后一个元素。而我们可以看到,first和last的数据类型都是Node<E>,Node是LinkedList的一个内部类,其代码如下:
1 private static class Node<E> { 2 E item; 3 Node<E> next; 4 Node<E> prev; 5 6 Node(Node<E> prev, E element, Node<E> next) { 7 this.item = element; 8 this.next = next; 9 this.prev = prev; 10 } 11 }
而内部类Node中的item元素,就是用来记录集合的元素,next用来记录下一个元素,prev用来记录上一个元素。
由此可见:LinkedList是一个双向链表。
3、LinkedList源码方法解析
3.1构造器方法
LinkedList一个有两个构造器方法,分别为:
1 /** 2 * 创建一个空的集合 3 */ 4 public LinkedList() { 5 } 6 /** 7 * 先创建一个空的集合,然后将c中的元素全部添加到集合中 8 */ 9 public LinkedList(Collection<? extends E> c) { 10 this(); 11 addAll(c); 12 }
两个构造方法都很简单,这里就不啰嗦了。而addAll如何实现,我们在后面会讲到。
3.2LinkedLisk的关键私有方法
在讲LinkedList的增删改查之前,我们先讲几个LinkedLisk的私有方法。
1 private void linkFirst(E e) { 2 final Node<E> f = first; 3 final Node<E> newNode = new Node<>(null, e, f); 4 first = newNode; 5 if (f == null) 6 last = newNode; 7 else 8 f.prev = newNode; 9 size++; 10 modCount++; 11 }
该私有方法用来将元素e放置在链表的第一位。先用变量f提取原链表的第一个元素first,如果f为空,则原链表为空链表,那么新链表就只有一个元素e。也就是新链表的first和last都为元素e。如果f不为空,则新链表的first=e,f。prev = newNode。从此方法,就可以看出,LinkedList为双向不循环链表。
1 void linkLast(E e) { 2 final Node<E> l = last; 3 final Node<E> newNode = new Node<>(l, e, null); 4 last = newNode; 5 if (l == null) 6 first = newNode; 7 else 8 l.next = newNode; 9 size++; 10 modCount++; 11 }
该私有方法用来将元素e放置在链表的最后一位。处理思想与linkFirst相同。
1 void linkBefore(E e, Node<E> succ) { 2 // assert succ != null; 3 final Node<E> pred = succ.prev; 4 final Node<E> newNode = new Node<>(pred, e, succ); 5 succ.prev = newNode; 6 if (pred == null) 7 first = newNode; 8 else 9 pred.next = newNode; 10 size++; 11 modCount++; 12 }
该方法用来将元素e放置在节点succ之前。处理思想:先提取succ.prev元素,然后将pred设为secc.prev,如果pred为空,则first=newNode,否则pred.next=newNode,也就是将新元素e放置在pred和secc之间。
1 private E unlinkFirst(Node<E> f) { 2 // assert f == first && f != null; 3 final E element = f.item; 4 final Node<E> next = f.next; 5 f.item = null; 6 f.next = null; // help GC 7 first = next; 8 if (next == null) 9 last = null; 10 else 11 next.prev = null; 12 size--; 13 modCount++; 14 return element; 15 }
1 private E unlinkLast(Node<E> l) { 2 // assert l == last && l != null; 3 final E element = l.item; 4 final Node<E> prev = l.prev; 5 l.item = null; 6 l.prev = null; // help GC 7 last = prev; 8 if (prev == null) 9 first = null; 10 else 11 prev.next = null; 12 size--; 13 modCount++; 14 return element; 15 }
这两个方法分别用来删除第一个元素和最后一个元素。
1 E unlink(Node<E> x) { 2 // assert x != null; 3 final E element = x.item; 4 final Node<E> next = x.next; 5 final Node<E> prev = x.prev; 6 7 if (prev == null) { 8 first = next; 9 } else { 10 prev.next = next; 11 x.prev = null; 12 } 13 14 if (next == null) { 15 last = prev; 16 } else { 17 next.prev = prev; 18 x.next = null; 19 } 20 21 x.item = null; 22 size--; 23 modCount++; 24 return element; 25 }
该方法用来删除一个非空元素。
1 Node<E> node(int index) { 2 // assert isElementIndex(index); 3 4 if (index < (size >> 1)) { 5 Node<E> x = first; 6 for (int i = 0; i < index; i++) 7 x = x.next; 8 return x; 9 } else { 10 Node<E> x = last; 11 for (int i = size - 1; i > index; i--) 12 x = x.prev; 13 return x; 14 } 15 }
该方法用来获取下标为index的节点。由方法可以看出当index小于size/2时,从first开始遍历,否则从last开始遍历。
也就是当index越靠近size/2的位置时,在获取节点时需要遍历的次数越多。
3.3LinkedList增加元素的方法
1 public void addFirst(E e) { 2 linkFirst(e); 3 }
1 public void addLast(E e) { 2 linkLast(e); 3 }
这两个方法分别调用linkFirst(e)和linkeLast(e)来在第一位和最后一位增加元素。
1 public boolean add(E e) { 2 linkLast(e); 3 return true; 4 }
由此方法可以看出,linkedList增加元素默认在链表的最后一位增加元素。
1 public boolean addAll(Collection<? extends E> c) { 2 return addAll(size, c); 3 } 4 public boolean addAll(int index, Collection<? extends E> c) { 5 checkPositionIndex(index); 6 7 Object[] a = c.toArray(); 8 int numNew = a.length; 9 if (numNew == 0) 10 return false; 11 12 Node<E> pred, succ; 13 if (index == size) { 14 succ = null; 15 pred = last; 16 } else { 17 succ = node(index); 18 pred = succ.prev; 19 } 20 21 for (Object o : a) { 22 @SuppressWarnings("unchecked") E e = (E) o; 23 Node<E> newNode = new Node<>(pred, e, null); 24 if (pred == null) 25 first = newNode; 26 else 27 pred.next = newNode; 28 pred = newNode; 29 } 30 31 if (succ == null) { 32 last = pred; 33 } else { 34 pred.next = succ; 35 succ.prev = pred; 36 } 37 38 size += numNew; 39 modCount++; 40 return true; 41 }
可以看出,该方法就是循环遍历集合c,然后依次插入到链表的最后。而前面的构造器LinkedList(Collection<? extends E> c),所调用的addAll(c)方法,实际上也是调用的addAll(size, c)方法,而当时size等于0,则也就是从元素的第一位依次遍历集合c插入到链表中。
1 public void add(int index, E element) { 2 checkPositionIndex(index); 3 4 if (index == size) 5 linkLast(element); 6 else 7 linkBefore(element, node(index)); 8 }
该方法用来在插入元素到链表的固定位置。如果index == size,则直接在链表的最后插入元素,否则调用linkBefore(E e,Node node),在节点之前插入元素。
1 public boolean offer(E e) { 2 return add(e); 3 } 4 public boolean offerFirst(E e) { 5 addFirst(e); 6 return true; 7 } 8 public boolean offerLast(E e) { 9 addLast(e); 10 return true; 11 } 12 public void push(E e) { 13 addFirst(e); 14 }
这四个方法都是由接口Deque所提供的,其实现直接调用了原有的add方法和addFirst、addList方法。
3.4LinkedList删除元素的方法
1 public E removeFirst() { 2 final Node<E> f = first; 3 if (f == null) 4 throw new NoSuchElementException(); 5 return unlinkFirst(f); 6 } 7 public E removeLast() { 8 final Node<E> l = last; 9 if (l == null) 10 throw new NoSuchElementException(); 11 return unlinkLast(l); 12 }
两个方法分别用来删除第一个和最后一个元素。分别调用了私有方法unlinkFirst(f) 和unlinkLast(l)来处理删除元素。
1 public boolean remove(Object o) { 2 if (o == null) { 3 for (Node<E> x = first; x != null; x = x.next) { 4 if (x.item == null) { 5 unlink(x); 6 return true; 7 } 8 } 9 } else { 10 for (Node<E> x = first; x != null; x = x.next) { 11 if (o.equals(x.item)) { 12 unlink(x); 13 return true; 14 } 15 } 16 } 17 return false; 18 }
该方法用来删除元素o。从first开始遍历链表,如果有第一个等于o的元素,则删除并返回true。
1 public void clear() { 2 // Clearing all of the links between nodes is "unnecessary", but: 3 // - helps a generational GC if the discarded nodes inhabit 4 // more than one generation 5 // - is sure to free memory even if there is a reachable Iterator 6 for (Node<E> x = first; x != null; ) { 7 Node<E> next = x.next; 8 x.item = null; 9 x.next = null; 10 x.prev = null; 11 x = next; 12 } 13 first = last = null; 14 size = 0; 15 modCount++; 16 }
该方法用来删除链表的所有元素。从first开始遍历链表,将所有节点都设置为null。其实本可以直接将first和last设置为null就可以了,但是为了垃圾回收机制,还是将所有的节点都清空了。
1 public E remove(int index) { 2 checkElementIndex(index); 3 return unlink(node(index)); 4 }
该方法用来删除下标为index的节点元素。其处理方法时先用node(index)获取该下标的节点,然后调用私有方法unlink(Node node)删除该节点。
public E poll() { final Node<E> f = first; return (f == null) ? null : unlinkFirst(f); }
1 public E pollFirst() { 2 final Node<E> f = first; 3 return (f == null) ? null : unlinkFirst(f); 4 }
1 public E pollLast() { 2 final Node<E> l = last; 3 return (l == null) ? null : unlinkLast(l); 4 }
这三方法分别用来删除并返回第一个元素和删除并返回最后一个元素。
public E remove() { return removeFirst(); }
该方法用来删除第一个元素,由此方法可以看出,LinkedList是默认从第一个元素开始删除的。由此可以看出LinkedList是符合队列的先进先出原则的。
1 public E pop() { 2 return removeFirst(); 3 }
该方法用来删除并返回最后一个元素。
public boolean removeFirstOccurrence(Object o) { return remove(o); }
该方法用来删除第一次出现的o元素。
1 public boolean removeLastOccurrence(Object o) { 2 if (o == null) { 3 for (Node<E> x = last; x != null; x = x.prev) { 4 if (x.item == null) { 5 unlink(x); 6 return true; 7 } 8 } 9 } else { 10 for (Node<E> x = last; x != null; x = x.prev) { 11 if (o.equals(x.item)) { 12 unlink(x); 13 return true; 14 } 15 } 16 } 17 return false; 18 }
该方法用来删除最后一次出现的o元素。
3.5LinkedList的修改元素方法
1 public E set(int index, E element) { 2 checkElementIndex(index); 3 Node<E> x = node(index); 4 E oldVal = x.item; 5 x.item = element; 6 return oldVal; 7 }
LinkedList用来修改元素的方法只有一个,set(int index, E element),设置下标为index的元素为element.处理逻辑为先提取原位置的元素x,然后用新元素element替换旧元素。
3.6 LinkedList的获取元素方法
public E getFirst() { final Node<E> f = first; if (f == null) throw new NoSuchElementException(); return f.item; } public E getLast() { final Node<E> l = last; if (l == null) throw new NoSuchElementException(); return l.item; } public E peek() { final Node<E> f = first; return (f == null) ? null : f.item; } public E element() { return getFirst(); } public E peekLast() { final Node<E> l = last; return (l == null) ? null : l.item; }
这五个方法处理逻辑都非常简单,分别是获取第一个或者获取最后一个元素。都是直接获取链表第一个或者最后一个节点,然后获取节点中的元素。
public int indexOf(Object o) { int index = 0; if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) return index; index++; } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) return index; index++; } } return -1; } public boolean contains(Object o) { return indexOf(o) != -1; }
public int lastIndexOf(Object o) {
int index = size;
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
}
这三个方法时用来查询元素中是否含有元素o。都是通过遍历的方式,来查找链表中是否有元素o。indexOf方法,如果含有元素o返回o的下标,contains方法则是如果含有元素o返回true。lastIndexOf用来返回链表中元素最后出现的位置的下标。
1 public int size() { 2 return size; 3 }
该方法用来查看链表中元素的个数。
1 public E get(int index) { 2 checkElementIndex(index); 3 return node(index).item; 4 }
该方法用来返回下标为index的元素。处理逻辑是先通过下标获取该下标的节点,然后获取节点中的元素。
3.7LinkedList的其他常用方法
1 public Object clone() { 2 LinkedList<E> clone = superClone(); 3 4 // Put clone into "virgin" state 5 clone.first = clone.last = null; 6 clone.size = 0; 7 clone.modCount = 0; 8 9 // Initialize clone with our elements 10 for (Node<E> x = first; x != null; x = x.next) 11 clone.add(x.item); 12 13 return clone; 14 }
该方法用来复制链表。通过遍历链表中的节点,然后一次将节点中的元素加入到新的链表中。由方法可以看出,新链表中的元素为就链表中元素的引用,并没有将元素也进行复制,所以LinkedList的clone方法也为潜复制。
LinkedList的迭代器
LinkedList的iterator方法由其集成的父类AbstractSequentialList实现,其代码如下。
1 public Iterator<E> iterator() { 2 return listIterator(); 3 } 4 public abstract ListIterator<E> listIterator(int index);
而LinkedList实现了listIterator方法,并有一个内部类实现了ListIterator<E>接口。
1 private class ListItr implements ListIterator<E> { 2 //最近一次返回的节点,也就是当前的节点 3 private Node<E> lastReturned; 4 //下一个节点 5 private Node<E> next; 6 //下一个节点的下标 7 private int nextIndex; 8 private int expectedModCount = modCount; 9 // 构造方法,接收一个index参数,返回一个ListItr对象 10 ListItr(int index) { 11 // assert isPositionIndex(index); 12 next = (index == size) ? null : node(index); 13 nextIndex = index; 14 } 15 // 根据nextIndex是否等于size判断时候还有下一个节点(也可以理解为是否遍历完了LinkedList) 16 public boolean hasNext() { 17 return nextIndex < size; 18 } 19 //获取下一个元素 20 public E next() { 21 checkForComodification(); 22 if (!hasNext()) 23 throw new NoSuchElementException(); 24 25 lastReturned = next; 26 next = next.next; 27 nextIndex++; 28 return lastReturned.item; 29 } 30 //根据nextIndex判断是否有上一个节点 31 public boolean hasPrevious() { 32 return nextIndex > 0; 33 } 34 //获取上一个节点的元素 35 public E previous() { 36 checkForComodification(); 37 if (!hasPrevious()) 38 throw new NoSuchElementException(); 39 40 lastReturned = next = (next == null) ? last : next.prev; 41 nextIndex--; 42 return lastReturned.item; 43 } 44 //获取当前节点的下标 45 public int nextIndex() { 46 return nextIndex; 47 } 48 //获取上一个节点的坐标 49 public int previousIndex() { 50 return nextIndex - 1; 51 } 52 //删除当前节点 53 public void remove() { 54 checkForComodification(); 55 if (lastReturned == null) 56 throw new IllegalStateException(); 57 58 Node<E> lastNext = lastReturned.next; 59 unlink(lastReturned); 60 if (next == lastReturned) 61 next = lastNext; 62 else 63 nextIndex--; 64 lastReturned = null; 65 expectedModCount++; 66 } 67 //修改当前节点的元素 68 public void set(E e) { 69 if (lastReturned == null) 70 throw new IllegalStateException(); 71 checkForComodification(); 72 lastReturned.item = e; 73 } 74 //在当前节点添加元素 75 public void add(E e) { 76 checkForComodification(); 77 lastReturned = null; 78 if (next == null) 79 linkLast(e); 80 else 81 linkBefore(e, next); 82 nextIndex++; 83 expectedModCount++; 84 } 85 86 //通过lambda表达式遍历 87 public void forEachRemaining(Consumer<? super E> action) { 88 Objects.requireNonNull(action); 89 while (modCount == expectedModCount && nextIndex < size) { 90 action.accept(next.item); 91 lastReturned = next; 92 next = next.next; 93 nextIndex++; 94 } 95 checkForComodification(); 96 } 97 // 判断expectedModCount和modCount是否一致,以确保通过ListItr的修改操作正确的反映在LinkedList中 98 final void checkForComodification() { 99 if (modCount != expectedModCount) 100 throw new ConcurrentModificationException(); 101 } 102 }
在使用迭代器遍历时,我们是不断的改变当前的节点,并通过当前节点来获取下一个节点来获取元素的。
这样在使用Iterator遍历时,就不需要像for循环里get方法一样,每次获取元素,都要对链表进行循环。由此可以看出,LinkedList使用Iterator进行遍历要比使用for循环进行遍历效率要高。
测试代码如下:
1 public static void main(String[] args) { 2 //创建一个集合并添加100000个元素 3 List<String> list = new LinkedList<String>(); 4 for (int i = 0; i < 100000; i++) { 5 list.add(i+""); 6 } 7 //使用for循环遍历 8 long startTime1 = System.currentTimeMillis(); 9 for (int i = 0; i < list.size(); i++) { 10 System.out.println(list.get(i)); 11 } 12 long endTime1 = System.currentTimeMillis(); 13 //使用iterator遍历 14 long startTime2 = System.currentTimeMillis(); 15 Iterator<String> itr = list.iterator(); 16 while(itr.hasNext()){ 17 System.out.println(itr.next()); 18 } 19 long endTime2 = System.currentTimeMillis(); 20 System.out.println("========================="); 21 System.out.println("使用for循环遍历时间:"+(endTime1-startTime1)); 22 System.out.println("使用iterator遍历时间:"+(endTime2-startTime2)); 23 }
运行结果:
使用for循环遍历时间:31086 使用iterator遍历时间:987
LinkedList还提供了一个获取迭代器的方法:descendingIterator();
public Iterator<E> descendingIterator() { return new DescendingIterator(); }
而DescendingIterator是LinkedList的一个内部类,其代码如下:
1 private class DescendingIterator implements Iterator<E> { 2 private final ListItr itr = new ListItr(size()); 3 public boolean hasNext() { 4 return itr.hasPrevious(); 5 } 6 public E next() { 7 return itr.previous(); 8 } 9 public void remove() { 10 itr.remove(); 11 } 12 }
从类名和上面的代码可以看出这是一个反向的Iterator,代码很简单,都是调用的ListItr类中的方法。
写在最后:
此篇随笔仅用来记录我的学习内容,如有错误,欢迎指正。谢谢!!!