一:selenium 库
selenium 每次模拟浏览器打开页面,xpath 匹配需要抓取的内容。可以,但是特别慢,相当慢。作为一个对技术有追求的爬虫菜鸡,狂补了一些爬虫知识。甚至看了 scrapy 框架,惊呆了,真棒!
网上很多关于 selenium 库的详细介绍,这里略过此方法。
二: requests 库
编写一个爬虫小脚本,requests 库极为方便。接下来进入正题,如何抓取 MOOC 中国上课程的讨论内容!
1. 分析网页数据
打开你需要抓取数据的课程页面,点击讨论区之后页面加载讨论的主题内容。F12 ---> Network ---> 刷新页面。会看到里面有很多请求的内容,讨论区内容肯定是数据包,类型的话 json 文件或 xhr 文件等。
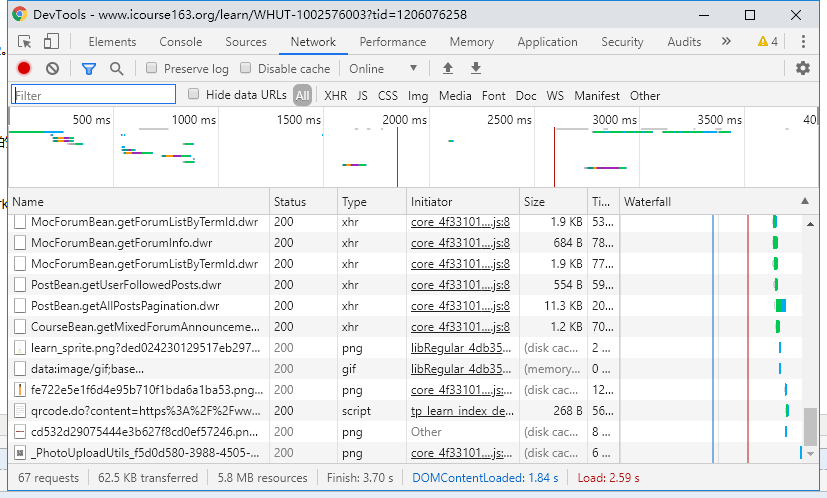
2. 找到讨论区内容的包
按名称分析 xhr 文件,很快就会发现跟讨论区相关的文件:PostBean.getAllPostsPagination.dwr,鼠标点击文件看到该文件的详细情况。

点击 Preview ,看到的是一大段 JS 代码,是否是我们需要的内容呢,得进行验证才可以得知。
3. 分析内容包 URL进行请求
阅读里面的内容,发现 .title .nickname 等字段信息,但是都是 Unicode 编码的。试着把 .title="" 的内容复制出来直接粘贴在 python 解释器里面就会出现该编码的中文字。
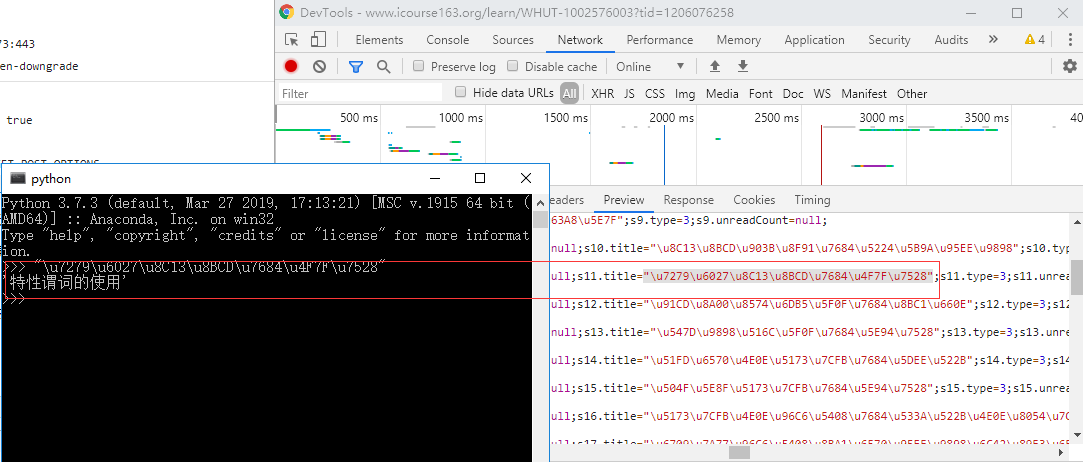
对比讨论区主题,发现是我们需要抓取的内容,
但是当我们复制 Request URL 到浏览器中进行访问时,是得不到需要的内容的,怎么办呢?
4. 根据响应去匹配需要的内容进行保存
继续分析请求头部的信息,最下面是 Request Payload , 存放了一些看不懂的数据内容,它的作用是浏览器发送请求时发送到服务器端的数据信息,和 Data Form 有些区别。但我们撸代码的时候一概作为附带的数据包发送给服务器就行了。其中几个关键的字段在代码里都会有注释信息理解,包括页码,每页数据的大小等。
5. 代码实现


1 import requests 2 import json 3 import time 4 import re 5 import random 6 7 def get_title_reply(uid, fi, http): 8 url = 'https://www.icourse163.org/dwr/call/plaincall/PostBean.getPaginationReplys.dwr' 9 headers = { 10 'accept': '*/*', 11 'accept-encoding': 'gzip, deflate, br', 12 'accept-language': 'zh-CN,zh;q=0.9', 13 'content-length': '249', 14 'content-type': 'text/plain', 15 'cookie': '', 16 'origin': 'https://www.icourse163.org', 17 'referer': 'https://www.icourse163.org/learn/WHUT-1002576003?tid=1206076258', 18 'sec-fetch-mode': 'cors', 19 'sec-fetch-site': 'same-origin', 20 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36', 21 } 22 data = { 23 'httpSessionId': '611437146dd0453d8a7093bfe8f44f17', 24 'scriptSessionId': '${scriptSessionId}190', 25 'c0-scriptName': 'PostBean', 26 'c0-methodName': 'getPaginationReplys', 27 'c0-id': 0, 28 'callCount': 1, 29 # 根据主题楼主的 id 检索回复内容 30 'c0-param0': 'number:' + str(uid), 31 'c0-param1': 'string:2', 32 'c0-param2': 'number:1', 33 'batchId': round(time.time() * 1000), 34 } 35 res = requests.post(url, data=data, headers=headers, proxies=http) 36 # js 代码末尾给出回复总数,当前页码等信息。 37 totle_count = int(re.findall("totalCount:(.*?)}", res.text)[0]) 38 try: 39 if totle_count: 40 begin_reply = int(re.findall("list:(.*?),", res.text)[0][1:]) + 1 41 for i in range(begin_reply, begin_reply + totle_count): 42 content_re ='s{}.content="(.*?)";'.format(i) 43 content = re.findall(content_re, res.text)[0] 44 # print(content.encode().decode('unicode-escape')) 45 fi.write(' ' + content.encode().decode('unicode-escape') + ' ') 46 # time.sleep(1) 47 except Exception: 48 print('回复内容写入错误!') 49 50 51 52 def get_response(course_name, url, page_index): 53 54 headers = { 55 'accept': '*/*', 56 'accept-encoding': 'gzip, deflate, br', 57 'accept-language': 'zh-CN,zh;q=0.9', 58 'content-length': '333', 59 'content-type': 'text/plain', 60 'cookie': '', 61 'origin': 'https://www.icourse163.org', 62 'referer': 'https://www.icourse163.org/learn/WHUT-1002576003?tid=1206076258', 63 'sec-fetch-mode': 'cors', 64 'sec-fetch-site': 'same-origin', 65 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36', 66 67 } 68 data = { 69 'httpSessionId': '611437146dd0453d8a7093bfe8f44f17', 70 'scriptSessionId': '${scriptSessionId}190', 71 'c0-scriptName': 'PostBean', 72 'c0-methodName': 'getAllPostsPagination', 73 'c0-id': 0, 74 'callCount': 1, 75 # 课程 id 76 'c0-param0': 'number:1206076258', 77 'c0-param1': 'string:', 78 'c0-param2': 'number:1', 79 # 当前页码 80 'c0-param3': 'string:' + str(page_index), 81 # 页码内容量 82 'c0-param4': 'number:20', 83 'c0-param5': 'boolean:false', 84 'c0-param6': 'null:null', 85 # 毫秒级时间戳 86 'batchId': round(time.time() * 1000), 87 } 88 # 代理 IP 89 proxy = [ 90 { 91 'http': 'http://119.179.132.94:8060', 92 'https': 'https://221.178.232.130:8080', 93 }, 94 { 95 'http': 'http://111.29.3.220:8080', 96 'https': 'https://47.110.130.152:8080', 97 }, 98 { 99 'http': 'http://111.29.3.185:8080', 100 'https': 'https://47.110.130.152:8080', 101 }, 102 { 103 'http': 'http://111.29.3.193:8080', 104 'https': 'https://47.110.130.152:8080', 105 }, 106 { 107 'http': 'http://39.137.69.10:8080', 108 'https': 'https://47.110.130.152:8080', 109 }, 110 ] 111 http = random.choice(proxy) 112 is_end = False 113 try: 114 res = requests.post(url, data=data, headers=headers, proxies=http) 115 # 评论从 S** 开始,js 代码末尾信息分析 116 response_result = re.findall("results:(.*?)}", res.text)[0] 117 except Exception: 118 print('开头就错,干啥!') 119 if response_result == 'null': 120 is_end = True 121 else: 122 try: 123 begin_title = int(response_result[1:]) + 1 124 with open(course_name+'.txt', 'a', encoding='utf-8') as fi: 125 for i in range(begin_title, begin_title + 21): 126 user_id_re = 's{}.id=([0-9]*?);'.format(str(i)) 127 title_re = 's{}.title="(.*?)";'.format(str(i)) 128 title_introduction_re = 's{}.shortIntroduction="(.*?)"'.format(str(i)) 129 title = re.findall(title_re, res.text) 130 if len(title): 131 user_id = re.findall(user_id_re, res.text) 132 title_introduction = re.findall(title_introduction_re, res.text) 133 # print(f'user_id={user_id[0]},title={(title[0]).encode().decode("unicode-escape")}') 134 fi.write((title[0]).encode().decode("unicode-escape") + ' ') 135 # 主题可能未进行描述 136 if len(title_introduction): 137 # print(title_introduction[0].encode().decode("unicode-escape")) 138 fi.write(' ' + (title_introduction[0]).encode().decode("unicode-escape") + ' ') 139 get_title_reply(user_id[0], fi, random.choice(proxy)) 140 except Exception: 141 print('主题写入错误!') 142 return is_end 143 144 def get_pages_comments(): 145 url = 'https://www.icourse163.org/dwr/call/plaincall/PostBean.getAllPostsPagination.dwr' 146 page_index = 1 147 course_name = "lisanjiegou" 148 while(True): 149 # time.sleep(1) 150 is_end = get_response(course_name, url, page_index) 151 if is_end: 152 break 153 else: 154 print('第{}页写入完成!'.format(page_index)) 155 page_index += 1 156 157 if __name__ == '__main__': 158 start_time = time.time() 159 print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(start_time))) 160 get_pages_comments() 161 end_time = time.time() 162 print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(end_time))) 163 print('用时{}秒!'.format(end_time - start_time))
1 from selenium import webdriver 2 from bs4 import BeautifulSoup 3 import time 4 from selenium.webdriver.chrome.options import Options 5 import requests 6 7 def get_connect(): 8 chrome_driver = 'C:/Program Files (x86)/Google/Chrome/Application/chromedriver.exe' 9 browser = webdriver.Chrome(executable_path=chrome_driver) 10 url_head = 'https://www.icourse163.org/learn/WHUT-1002576003#/learn/forumindex' 11 # 加载网页 12 browser.get(url_head) 13 # 获取课程标题 14 title_link = browser.find_element_by_class_name('courseTxt') 15 # 模拟点击进入详情页 16 title_link.click() 17 content = browser.page_source 18 soup = BeautifulSoup(content, 'lxml') 19 print(soup.text) 20 def get_connect_slow(): 21 chrome_driver = 'C:/Program Files (x86)/Google/Chrome/Application/chromedriver.exe' 22 browser = webdriver.Chrome(executable_path=chrome_driver) 23 url_head = 'https://www.icourse163.org/learn/WHUT-1002576003#/learn/forumindex' 24 # 加载网页 25 browser.get(url_head) 26 pages = browser.find_elements_by_class_name('zpgi') 27 totle_page = int(pages[-1].text) + 1 28 browser.close() 29 with open('comments.txt', 'w', encoding='utf-8') as fi: 30 for i in range(1, 2): 31 browser = webdriver.Chrome(executable_path=chrome_driver) 32 url = url_head + '?t=0&p=' + str(i) 33 browser.get(url) 34 # 多条内容 35 comments = browser.find_elements_by_class_name('j-link') 36 for comment in comments: 37 fi.write(comment.text + ' ') 38 print('第{}页评论写入成功!'.format(i)) 39 browser.close() 40 def get_connect_slow_1(course_url, course_name): 41 chrome_driver = 'C:/Program Files (x86)/Google/Chrome/Application/chromedriver.exe' 42 browser_1 = webdriver.Chrome(executable_path=chrome_driver) 43 url_head = course_url 44 # 加载网页 45 browser_1.implicitly_wait(3) 46 browser_1.get(url_head) 47 pages = browser_1.find_elements_by_class_name('zpgi') 48 totle_page = 0 49 if pages: 50 for pg in range(len(pages)-1, 0, -1): 51 if pages[pg].text.isdigit(): 52 totle_page = int(pages[pg].text) + 1 53 break 54 55 print('评论主题共{}页!'.format(totle_page)) 56 with open(course_name + '.txt', 'w', encoding='utf-8') as fi: 57 for i in range(1, totle_page): 58 try: 59 browser = webdriver.Chrome(executable_path=chrome_driver) 60 browser.implicitly_wait(3) 61 url = url_head + str(i) 62 browser.get(url) 63 content = browser.page_source 64 soup = BeautifulSoup(content, 'lxml') 65 # course_title = soup.find('h4', class_='courseTxt') 66 # fi.write(course_title.text + ' ') 67 comment_lists = soup.find_all('li', class_='u-forumli') 68 for comment in comment_lists: 69 reply_num = comment.find('p', class_='reply') 70 reply_num = int(reply_num.text[3:]) 71 if reply_num > 0: 72 try: 73 comment_detail = comment.find('a', class_='j-link') 74 fi.write(comment_detail.text + ' ') 75 a_link = comment_detail.get('href') 76 reply_link = url.split('#')[0] + a_link 77 browser_reply = webdriver.Chrome(executable_path=chrome_driver) 78 browser_reply.implicitly_wait(3) #隐式等待 3 秒 79 browser_reply.get(reply_link) 80 test_ = browser_reply.find_element_by_class_name('m-detailInfoItem') 81 reply_soup = BeautifulSoup(browser_reply.page_source, 'lxml') 82 # 楼主对主题的描述 83 own_reply = reply_soup.find('div', class_='j-post') 84 own_reply = own_reply.find('div', class_='j-content') 85 # 有楼主对主题省去描述 86 if own_reply.text: 87 fi.write(' ' + own_reply.text + ' ') 88 89 # 别人对该主题的评论回复 90 reply_list = reply_soup.find_all('div', class_='m-detailInfoItem') 91 for reply_item in reply_list: 92 write_text = reply_item.find('div', class_='j-content') 93 fi.write(' ' + write_text.text + ' ') 94 browser_reply.close() 95 except Exception : 96 print('评论回复抓取失败!') 97 else: 98 fi.write(comment.find('a', class_='j-link').text + ' ') 99 print('第{}页评论写入成功!'.format(i)) 100 except Exception: 101 print('第{}页评论抓取失败!'.format(i)) 102 103 def run(): 104 105 print('https://www.icourse163.org/learn/WHUT-1002576003?tid=1206076258#/learn/forumindex?t=0&p=') 106 course_url = input('输入课程地址,输入网址后空格再回车,如上:') 107 course_url = course_url.split(' ')[0] 108 course_name = input('输入课程名:') 109 start_time = time.time() 110 get_connect_slow_1(course_url, course_name) 111 end_time = time.time() 112 print('共用时{}秒!'.format(end_time - start_time)) 113 114 115 116 if __name__ == '__main__': 117 run() 118 # 76 页评论 119 # 75-150页 120 # 共用时13684.964568138123秒!