在《DB2数据库查询过程(Query Processing)----简单索引访问(Simple Indexed Access)》一文中已经对索引访问的各种形式作了详细介绍,本文重点讨论匹配索引扫描对于复合索引的种种情况应该如何进行索引的选择。
复合索引(Composite Index)
索引列(搜索码)由多个表列共同组成的索引称为复合索引,相对的,索引列仅是单个表列的索引称为单列索引。
例如语句:CREATE INDEX PHONEBOOK_IDX ONPHONEBOOK ( LASTNAME, FIRSTNME) 创建的索引PHONEBOOK_IDX的索引列由LASTNAME列和FIRSTNME列构成,就是一个复合索引。
复合索引和单列索引在结构上没有什么本质的区别,索引树的构建和扫描也没有什么特别之处。就像是表的主键,不管是单列主键还是多列主键,等同看待就完了。
但是复合索引有一个特性:索引中的索引列(或者说搜索码)是有序的!这个特性非常重要!
复合索引在进行B+树构建时的规则是:首先按照第一个索引列的值进行排序,当第一个索引列的值相同时才按照第二个索引列值进行进一步区分,当第二个索引列值扔相同再参考第三个索引列。。。以此类推。也就是说,第一索引列的值是严格排序的,后面的索引列值只有在前面的索引列都严格排序后才可能进行排序。
那么,进行索引查找的时候,就必须首先参照第一索引列才能进行自根向叶的高效查找,如果没有第一索引列作为筛选条件,就只能对索引的叶结点页进行逐个遍历(因为其他的索引列不能保证在B+树中是有序的),这种情形就是前面介绍的非匹配索引扫描了。
复合索引的第一个索引列就称为主索引列,其他的列称为从索引列。
举个例子:
对于表PHONEBOOK创建了一个LASTNAME,FIRSTNME列上的索引NAME_IDX(LASTNAME,FIRSTNME)。NAME_IDX索引的B+树结构如图:

现在有SQL查询:
Select * From PHONEBOOK Where LASTNAME = 'Smith' and FIRSTNME = 'Steve'
那么查找的过程就如青色箭头所示,根据主索引列LASTNAME的值Smith和根结点页的逻辑指针找到第3个叶结点页(Peters<Smith<Zidler,使用LASTNAME为Smith的索引项在第3个叶结点页上),复合条件的索引项有两个Smith,Stanley和Smith,Steve(这两个索引项上有序的),然后根据从索引列FIRSTNME的值筛选出唯一符合条件的索引项Smith,Steve,继而找到对应的数据页。
而如果没有FIRSTNME = 'Steve'这个条件谓词,还是能够按照上图的路线找到符合条件的两个索引项,继而找到对应数据页。
但是如果没有LASTNAME = 'Smith' 这个谓词,即查询语句改为:
Select * From PHONEBOOK Where FIRSTNME = 'Steve'
就不能根据根结点和FIRSTNME = 'Steve'判断FIRSTNME为Steve的索引项位于哪个叶结点页上,于是只能如下图对叶结点页逐个扫描:
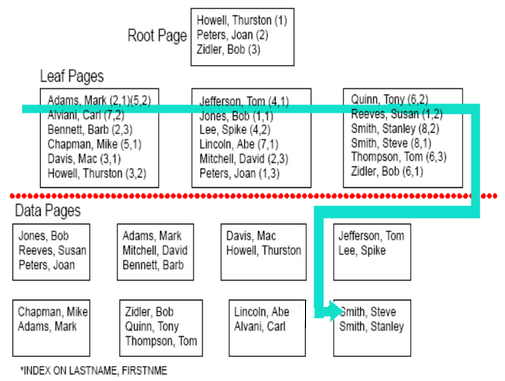
两种方式的效率差距是显而易见的。
匹配谓词和筛选谓词(Matching Predicate and Screening Predicate)
对于上述PHONEBOOK表的例子,查询语句:
Select * From PHONEBOOK Where LASTNAME = 'Smith' and FIRSTNME = 'Steve'
中的LASTNAME = 'Smith' 和FIRSTNME = 'Steve' 就称为匹配谓词。
而查询语句:
Select * From PHONEBOOK Where FIRSTNME = 'Steve'
中的FIRSTNME = 'Steve' 则称为筛选谓词。
一个匹配索引扫描通过匹配一系列的与选定的索引中的列相关的条件谓词来从表中检索数据行,对于索引中的主索引列必须至少对应一个可索引谓词才能使用索引的树结构进行高效查找(否则只能对页结点页进行逐个扫描或者放弃索引使用表扫描)。那么这个可索引的谓词就称为匹配谓词。如果一系列的可索引谓词都能够匹配复合索引中从左到右连续的索引列,那么这些可索引谓词都是匹配谓词。索引中其他索引列对应的出现在查询语句中的条件谓词就称为筛选谓词(对索引项进行逐个筛选)。
以上并不是匹配谓词、筛选谓词的标准定义,事实上这两个概念也不好定义,举个例子来具体说明好了。
表T1上有列C1、C2、C3、C4、C5、C6、C7、C8。其中在C1,C2,C3,C4上有索引C1234X。
A.查询语句:Select * From T1 Where C1=5 And C2=4 And C3=7 And C4=2
该语句使用索引C1234X,匹配谓词为C1=5、C2=4、C3=7、C4=2。使用这些谓词可以直接完成定位,无需进行索引页的逐个扫描。
B.查询语句:Select * From T1 Where C2=4 And C3=7 And C4=2
该语句由于主索引列没有相对应的谓词,因此无法使用索引的树结构进行查找,只能是要么对叶结点页逐个扫描,要么放弃索引进行表扫描。
如果使用索引C1234X,那么没有匹配谓词,C2=4、C3=7、C4=2都是筛选谓词。
C.查询语句:Select * From T1 Where C1<>5 And C2=4 And C3=7
该语句由于主索引列对应非匹配谓词,因此要么对叶结点页逐个扫描,要么放弃索引使用表扫描。
如果使用索引C1234X,那么没有匹配谓词,C1<>5、C2=4、C3=7都是筛选谓词。
D.查询语句:Select * From T1 Where C2=4 And C3=7 And C1=5
该语句使用索引C1234X,匹配谓词为C1=5、C2=4、C3=7。注意,对应Where子句后面的谓词,优化器会根据索引中列的顺序进行重新排序(查询重写)。
E.查询语句:Select * From T1 Where C1=5 And C2=4 And C4=2 And C6=10
该语句使用索引C1234X,匹配谓词为C1=5、C2=4,筛选谓词为C4=2,C6=10为普通谓词(没有索引与之对应)。可以看到,一旦谓词对应的索引列不连续,那么其后的索引列对应的谓词就只能是筛选谓词了。因为一旦不连续,那么该谓词就不能继续使用树结构进行定位了,只能对下层索引页进行逐个扫描。
F.查询语句:Select * From T1 Where C1=5 And C2=4 And C3>7 And C4=2
该语句使用索引C1234X,匹配谓词为C1=5、C2=4、C3>7,筛选谓词为C4=2。一直到C3都能够使用树结构进行定位,但是C4就不行了,因为C3>7给的只是一个范围,该范围内的下层索引页只能由C4谓词进行逐个扫描筛选了。
对应给定的是范围的谓词称为范围谓词,带between、<、>、<=、>=、like等操作符的谓词都是范围谓词,一旦出现范围谓词(索引列对应的),匹配就停止,剩下的索引列对应的谓词只能是筛选谓词了。但是有一个例外,in操作符虽然也是表范围的,但是由于它可以看作是一系列的相等匹配谓词,单独将其称为In-list谓词,它的出现不会导致匹配的终止。
由以上例子可以得出匹配谓词的基本原则:
1.匹配谓词必须是可索引谓词。
2.匹配谓词必须对应选定索引中从左到右连续的索引列,一旦出现不连续或者谓词为范围谓词,匹配终止。
3.选定索引中索引列对应的非匹配谓词仍然可以是筛选谓词,即便该谓词是不可索引谓词。
实例
现在以一个更复杂的例子来说明复合索引下的匹配索引扫描。
表T上有列C1、C2、C3、C4、C5、C6、C7、C8。其中在C1,C2,C3,C4上有索引C1234X;C5、C6上有索引C56X;C7上有唯一索引C7X。
用ACCESSTYPE表示访问类型,ACCESEETYPE=I表示使用索引扫描,ACCESSTYPE=N表示使用带In-list谓词的索引扫描。ACCESSNAME表示使用的索引。MATCHCOLS表示匹配的索引列数。对照上面的规则,不再进行详细解释了。
Select * From T Where C1=5 And C2=7 And C3<>9
ACCESEETYPE=I , ACCESSNAME=C1234X , MATCHCOLS=2
Select * From T Where C1=5 And C2>=7 And C3=9
ACCESEETYPE=I , ACCESSNAME=C1234X , MATCHCOLS=2
Select * From T Where C1=5 And C2=7 And C5=8 And C6=13
ACCESEETYPE=I , ACCESSNAME=C56X , MATCHCOLS=2 //至于为什么使用的是索引C56X而不是C1234X,这是由优化器的成本估算结果决定的。
Select * From T Where C1=5 And C2 in(5,6) And (C3=10 or C4=11)
ACCESEETYPE=N , ACCESSNAME=C1234X , MATCHCOLS=2 //"or"操作符连接的谓词会被当作不可索引谓词,因此不是匹配谓词,但是可以作为筛选谓词。
Select * From T Where C1=5 And C2=7 And C7=101
ACCESEETYPE=I , ACCESSNAME=C7X , MATCHCOLS=1 //通常唯一索引会优于普通索引,但也不是绝对的。
Select * From T Where C2=7 And C3=10 And C4=12 And C5=16
ACCESEETYPE=I , ACCESSNAME=C1234X , MATCHCOLS=0 //虽然C1234X上没有匹配谓词,C56X上有,但是优化器认为使用索引C1234X更优。
特殊谓词(Special Predicates)
有一些特殊的谓词,它们使用的操作符都是可索引谓词的操作符,但是这些谓词却不是可索引谓词,即不可以对该谓词使用相应的索引。
模式匹配搜索(Pattern Match Search)
使用“like”操作符,但是匹配的值是通配符前置的。比如“C1 like '%tion'“,要知道索引是按照字母从左到右排序的,通配符前置自然是不能使用索引进行检索的。因此也就不是可索引谓词了。
当然你可以使用函数得到C1值的倒序,然后使用”like 'noit%'“实现该目的。
表达式(Expressions)
考虑语句:
Select * From T Where 5*C1<=20;
虽然使用的是”<=“操作符,但是由于DB2是不会对谓词去做代数运算的,因此”5*C1<=20“是不可索引谓词。改写为C1<=4就是可索引的了。
另外,不同列之间使用代数表达式同样是不可索引的,比如”C1=C2“(C1、C2均为数据列)是不可索引谓词。
取一次访问(One-Fetch Access)
考虑语句:
Select min(C1) From T ;
假设在C1列上建有索引,那么优化器会直接找到索引叶结点页中最左侧的那个索引也,从中读出最小值即可,其他的页直接忽视。这种没有Where子句的SQL查询语句由于使用了特殊的函数,同样可以使用对应的索引。我们把这种情况称为取一次访问。
另外max函数自然也是能够做取一次访问的了。当然,使用了这样的特殊函数且仍然带有Where子句的,也还是属于取一次访问的范畴。比如:
Select max(C1) From T Where C1 Between 5 And 10;