Python爬虫教程-34-分布式爬虫介绍
- 分布式爬虫在实际应用中还算是多的,本篇简单介绍一下分布式爬虫
什么是分布式爬虫
-
分布式爬虫就是多台计算机上都安装爬虫程序,重点是联合采集。单机爬虫就是只在一台计算机上的爬虫。
-
其实搜索引擎都是爬虫,负责从世界各地的网站上爬取内容,当你搜索关键词时就把相关的内容展示给你,只不过他们那都是灰常大的爬虫,爬的内容量也超乎想象,也就无法再用单机爬虫去实现,而是使用分布式了,一台服务器不行,我来1000台。我这么多分布在各地的服务器都是为了完成爬虫工作,彼此得通力协作才行啊,于是就有了分布式爬虫
-
单机爬虫的问题:
- 一台计算机的效率问题
- IO 的吞吐量,传输速率也有限
-
多爬虫问题
- 多爬虫要实现数据共享
- 比如说一个爬取了某个网站,下载了哪些内容,其他爬虫要知道,以避免重复爬取等很多问题,所以要实现数据共享
- 在空间上不同的多台机器,可以成为分布式
- 多爬虫要实现数据共享
-
多爬虫条件:
- 需要共享队列
- 去重,让多个爬虫不爬取其他爬虫爬取过的爬虫
-
理解分布式爬虫:
- 假设上万的 url 需要爬取,有 100 多个爬虫,分布在全国不同的城市
- url 被分给不同的爬虫,但是不同爬虫的效率又是不一样的,所以说共享队列,共享数据,让效率高的爬虫多去做任务,而不是等着效率低的爬虫
-
Redis
- Redis 是完全开源免费的,遵守BSD协议,是一个高性能的 key-value 数据库
- 内存数据库,数据存放在内存
- 同时可以落地保存到硬盘
- 可以去重
- 可以把 Redis 理解成一共 dict,set,list 的集合体
- Redis 可以对保存的内容进行生命周期
- Redis 教程:Redis 教程 - 菜鸟教程
-
内容保存数据库
- MongoDB,运行在内存,数据保存在硬盘
- MySQL
- 等等
安装 scrapy_redis
- 1.打开【cmd】
- 2.进入使用的 Anaconda 环境
- 3.使用 pip 安装
- 4.操作截图
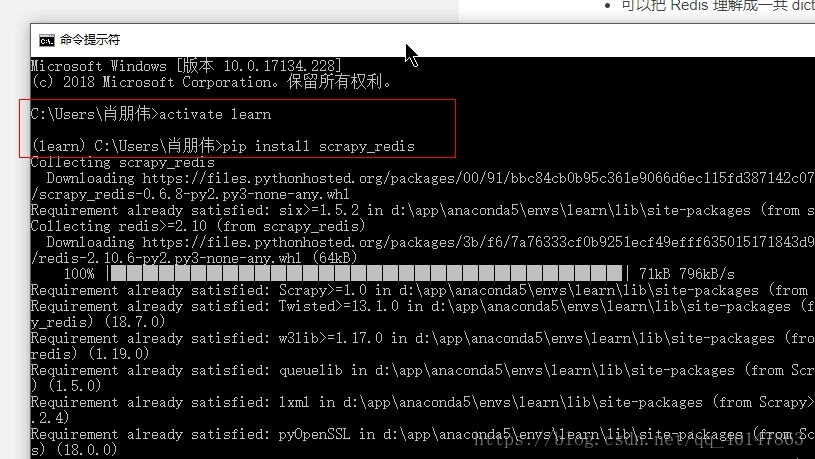
分布式爬虫的结构
主从分布式爬虫
- 所谓主从模式,就是由一台服务器充当 master,若干台服务器充当 slave,master 负责管理所有连接上来的 slave,包括管理 slave 连接、任务调度与分发、结果回收并汇总等;每个 slave 只需要从 master 那里领取任务并独自完成任务最后上传结果即可,期间不需要与其他 slave 进行交流。这种方式简单易于管理,但是很明显 master 需要与所有 slave 进行交流,那么 master 的性能就成了制约整个系统的瓶颈,特别是当连接上的slave数量庞大的时候,很容易导致整个爬虫系统性能下降
- 主从分布式爬虫结构图:
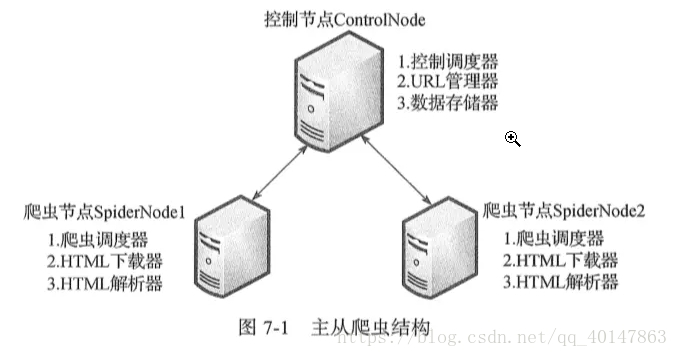
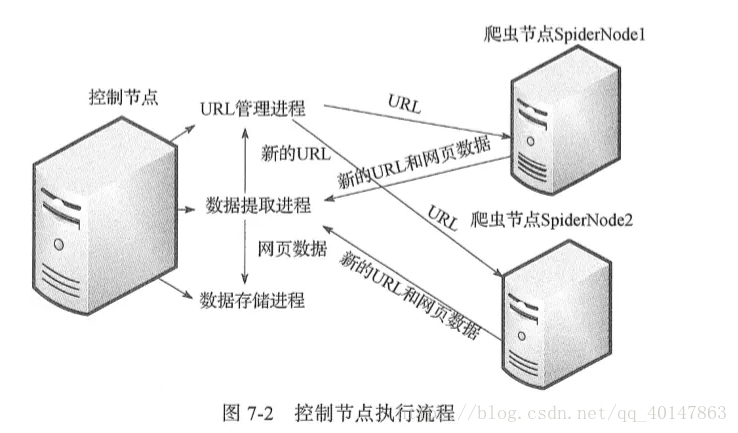
这是经典的主从分布式爬虫结构图,图中的控制节点ControlNode就是上面提到的master,爬虫节点SpiderNode就是上面提到的slave。下面这张图展示了爬虫节点slave的执行任务示意图 - 控制节点执行流程图:
- 这两张图很明了地介绍了整个爬虫框架,我们在这里梳理一下:
- 1.整个分布式爬虫系统由两部分组成:master控制节点和slave爬虫节点
- 2.master控制节点负责:slave节点任务调度、url管理、结果处理
- 3.slave爬虫节点负责:本节点爬虫调度、HTML下载管理、HTML内容解析管理
- 4.系统工作流程:master将任务(未爬取的url)分发下去,slave通过master的URL管理器领取任务(url)并独自完成对应任务(url)的HTML内容下载、内容解析,解析出来的内容包含目标数据和新的url,这个工作完成后slave将结果(目标数据+新url)提交给master的数据提取进程(属于master的结果处理),该进程完成两个任务:提取出新的url交于url管理器、提取目标数据交于数据存储进程,master的url管理进程收到url后进行验证(是否已爬取过)并处理(未爬取的添加进待爬url集合,爬过的添加进已爬url集合),然后slave循环从url管理器获取任务、执行任务、提交结果......
- 本篇就介绍到这里了
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载