Spider-02-使用urlopen
做一个最简单的python爬虫,使用爬虫爬取:智联招聘某招聘信息的DOM
urllib
- 包含模块
- urllib.request:打开和读取urls
- urllib.error:包含urllib.request产生的常见错误,使用try捕捉
- urllib.parse:包含解析url的方法
- urllib.robotparse:解析robots.txt文件
robots:机器人协议,放在网站的开头,供给爬虫读取,当爬虫读到robots之后,就知道那些是允许爬取的数据,哪些是禁止爬取的数据
(爬虫道德问题:1.不许过频繁爬取 2.不许爬取禁止内容) - 案例v1 (使用PyCharm开发工具,配置python解释器,创建python文件)
- 我把代码放在github了,可以直接下载,地址:
- py01v1.py文件:https://xpwi.github.io/py/py爬虫/py01v1.py
- request.py文档文件:https://xpwi.github.io/py/py爬虫/request.py
# py01v1.py
from urllib import request
# 使用urllib.request请求一个网页的内容,并把内容打印出来
if __name__ == '__main__':
# 定义需要爬的页面
url = "https://jobs.zhaopin.com/CC375882789J00033399409.htm"
# 打开相应url并把页面作为返回
rsp = request.urlopen(url)
# 按住Ctrl键不送,同时点击urlopen,可以查看文档,有函数的具体参数和使用方法
# 把返回结果读取出来
html = rsp.read()
print(html)
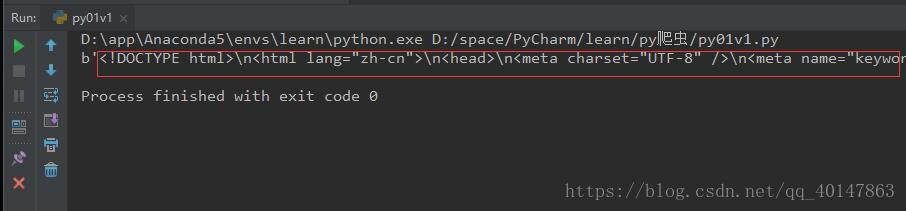
上面简单几行代码就可以爬取页面的HTML代码了
右键运行,截图如下
但是,我们爬取到的代码是不能自行显示中文的,需要解码处理
py02v1.py文件:https://xpwi.github.io/py/py爬虫/py02v1.py
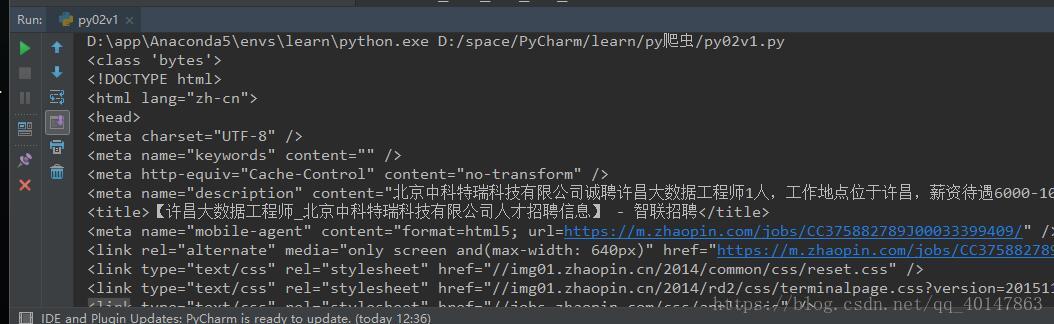
# py02v1.py
from urllib import request
if __name__ == '__main__':
url = "https://jobs.zhaopin.com/CC375882789J00033399409.htm"
rsp = request.urlopen(url)
# 按住Ctrl键不送,同时点击urlopen,可以查看文档,有函数的具体参数和使用方法
html = rsp.read()
# 解码
html = html.decode()
print(html)
解码后效果:
恭喜你,最简单的爬虫就已经学会啦!
如果运行失败,可能是
1.【爬取的连接失效】,更换最新的地址就可以了
2.【Python环境问题】,这里不做仔细介绍,请自行【百度】解决,也可联系博主
QQ:1370911284
微信:18322295195
更多文章链接:Python 爬虫随笔
- 本笔记学习于图灵学院python全栈课程 - 本笔记不允许任何个人和组织转载