重现基线模型
我们选择了 code2vec 模型进行复现。该模型由 Uri Alon 等作者于 2018 年提出。
模型思路:
从代码与普通语言相比的特殊性入手,首先,对于输入的代码段,作者考虑到尽管很多 NLP 任务中都是将输入的文本作为序列处理的,但是代码段中代码的先后顺序和自然语言中文字的先后顺序的重要性是不同的,代码中更讲究结构,而先后顺序不一定有很大作用。所以作者通过构建抽象代码树来利用代码段语法的结构信息。抽象代码树是编译原理中非常重要的一种结构,将代码中的元素用边连为一棵语法树。在编译代码时,要先将代码转换为对应的代码树,明晰代码各元素的关系,然后才能在代码树上继续编译。将代码树作为输入比直接拿代码作为输入能得到更多更深层的信息。这样,一个代码段就可以用它对应的代码树中的 paths 和 names 来表示了。将代码树中每个 path 做 embedding 并利用一个全连接层进行压缩,并经过一个非线性激活函数后,利用 attention 机制将各个 path 做一个加权求和,得到这个代码段的 embedding,利用这个 embedding 去做一些数学运算就可以去做预测等任务了。下面对各个阶段的操作做简单说明:
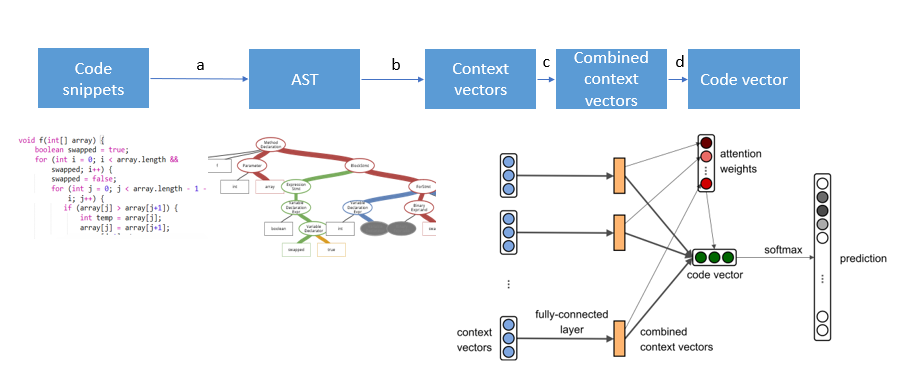
a. 利用antlr 4通过遍历parse tree建立代码树,代码树中每个路径<x1, p, x2>视为一个context,其中x1,x2表示终止符,p表示路径。
b. 将代码树中每个context做embedding,也就是对<x1,p,x2>的embedding做一个拼接。这三个元素的embedding是随机初始化后在网络中训练得到的。
c. 通过一个全连接层对b中三个embedding拼接得到的结果通过一个3d * d的权重矩阵做压缩,这个权重矩阵是在网络中学习的。
d. 给每个context不同的attention,加权求和后得到整个代码段的embedding。attention也是在网络中学习的。
训练网络中,我们的ground truth就是正确的tag,向量表示中就是只在正确tag的位置为1,其余为0,训练的目标就是最小化我们的预测向量(每个tag有对应的可能性值)和ground truth的交叉熵。
模型优劣:
模型的结构实际总体借鉴了NLP的CBOW模型,将function或者method转换成语义树的结构应该比直接将代码parse成词汇能保留更多的语义信息,应该可以提高编码器的性能。但这样相当于一个强假设,且将线性数据变成了图结构数据,使得数据的处理难度也加大了。
复现结果:
我们设置了 epochs=6,使用了数据集 java-small。在网上找到了一个日本团队复现的结果,在同数据集上结果对比:
| model | P | R | F1 |
|---|---|---|---|
| ours | 46.48 | 35.75 | 40.41 |
| others | 50.64 | 37.40 | 43.02 |
可能是训练时长不够的原因,比该日本团队的结果稍差一点,但大致上可以认为是完成了模型复现。
在复现的最初,我找到了网上的一组源代码数据,曾经尝试从提取代码树开始一点一点处理数据,但是由于源代码处理某些细节比较困难,而时间太短,处理失败了。所以最终还是利用了论文公开的处理好的数据。数据处理好后,复现实际上就比较容易了。按照论文将model 建好就可以开始 train 了。
模型改进
-
现在的模型是将每条 path 都做 embedding,但有些 path 会 share 一些部分。我们可以去掉这些 share 的部分。利用attention机制,给非重合部分更大的权重,可以做更细粒度的embedding。
-
对于这个模型对没见过的 label 无法预测的问题,可以借鉴 NLP 里的 copy mechanism,但是跟NLP不同的是,代码段里能copy过来的东西不一定有用,没有太多有意义的单词,这对输入数据就有要求。
由于时间的原因,我们没有实现这两点改进。
对伙伴的评价
我的结对伙伴是吴紫薇。由于我们两个都没有太多的实验时间,所以一共只进行了两次线下 sync,大部分工作是在线上交流的。由于我对机器学习相关知识并不是非常熟悉,理解不深,紫薇同学为我讲解了很多相关知识与思路,令我收益颇丰。这是一次很开心的合作。