其实分布式事物也是个老大难的问题了,从提出到现在一直都没有个特别优雅有效的解决方案,上周遇到个分布式的问题,我想了很久,也查了很多资料。找了几种方案,但都没有达到自己的预期,现在先记录下此时对分布式事务的理解。
分布式事务概述
1.为什么会需要分布式事务?
我们可以考虑下以下的场景,假设现在有一个电商平台,包含的功能有订单,支付,库存。当我们去电商平台下一笔订单,下单成功后电商平台会跳转到支付平台,支付成功后会更新库存的数据,然后电商平台就可以给我们发货了。
假设在支付的时候,电商平台向银行发起扣款,可能银行扣款成功了,但是给电商平台返回结果的时候网络出现了问题,没能返回正确的支付结果信息。那电商平台会认为支付失败,即不会给客户发货了。但实际上客户的钱已经被扣了。
针对这种情况,我们希望能把电商平台和银行这一整个支付流程放到一个事物里面。
这里就产生了两个问题:
1.作为电商平台,银行的代码是不由我控制的,我怎样才可以把它的代码和我的代码放到一个事物里面呢?
2.目前的事务都是基于单数据库的本地事务,目前的数据库仅支持单库事务,并不支持跨库事务,如何能做到多数据的事务呢?
基于上述情况,分布式事务理论就出现了,着微服务架构的普及,一个大型业务系统往往由若干个子系统构成,这些子系统又拥有各自独立的数据库。往往一个业务流程需要由多个子系统共同完成,而且这些操作可能需要在一个事务中完成。在微服务系统中,这些业务场景是普遍存在的。此时,我们就需要在数据库之上通过某种手段,实现支持跨数据库的事务支持,这也就是大家常说的“分布式事务”。
分布式事务的基本理论:
1.CAP理论

CAP理论说的是:在一个分布式系统中,最多只能满足C、A、P中的两个需求。
对于一个业务系统来说,可用性和分区容错性是必须要满足的两个条件,并且这两者是相辅相成的。业务系统之所以使用分布式系统,主要原因有两个:
-
提升整体性能 当业务量猛增,单个服务器已经无法满足我们的业务需求的时候,就需要使用分布式系统,使用多个节点提供相同的功能,从而整体上提升系统的性能,这就是使用分布式系统的第一个原因。
-
实现分区容错性 单一节点 或 多个节点处于相同的网络环境下,那么会存在一定的风险,万一该机房断电、该地区发生自然灾害,那么业务系统就全面瘫痪了。为了防止这一问题,采用分布式系统,将多个子系统分布在不同的地域、不同的机房中,从而保证系统高可用性。
这说明分区容错性是分布式系统的根本,如果分区容错性不能满足,那使用分布式系统将失去意义。
此外,可用性对业务系统也尤为重要。在大谈用户体验的今天,如果业务系统时常出现“系统异常”、响应时间过长等情况,这使得用户对系统的好感度大打折扣,在互联网行业竞争激烈的今天,相同领域的竞争者不甚枚举,系统的间歇性不可用会立马导致用户流向竞争对手。因此,我们只能通过牺牲一致性来换取系统的可用性和分区容错性。这也就是下面要介绍的BASE理论。
2.Base理论
eBay的架构师Dan Pritchett源于对大规模分布式系统的实践总结,在ACM上发表文章提出BASE理论。文章链接:https://queue.acm.org/detail.cfm?id=1394128
BASE理论是对CAP理论的延伸,核心思想是即使无法做到强一致性(Strong Consistency,CAP的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性(Eventual Consitency)。
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的缩写。
1. 基本可用(Basically Available):指分布式系统在出现不可预知故障的时候,允许损失部分可用性。
2. 软状态( Soft State):指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性。
3. 最终一致( Eventual Consistency):强调的是所有的数据更新操作,在经过一段时间的同步之后,最终都能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
分布式事务的服务模式
服务模式是柔性事务流程中的特殊操作实现,现在大多数分布式方案都会使用其中的几个服务模式
1. 可查询操作
服务操作具有全局唯一标识
可以使用业务单据号(如订单号)
或者使用系统分配的操作流水号(如支付记录流水号)
或者使用操作资源的组合组合标识(如商户号+商户订单号)
• 操作有唯一的、确定的时间(约定以谁的时间为准)
已支付为例:提交一个支付请求后,可能同步返回和异步返回都会有问题,这个时候就需要我们主动向支付渠道查询支付结果
2.幂等操作
重复调用多次产生的业务结果与调用一次产生的业务结果相同
3.TCC操作
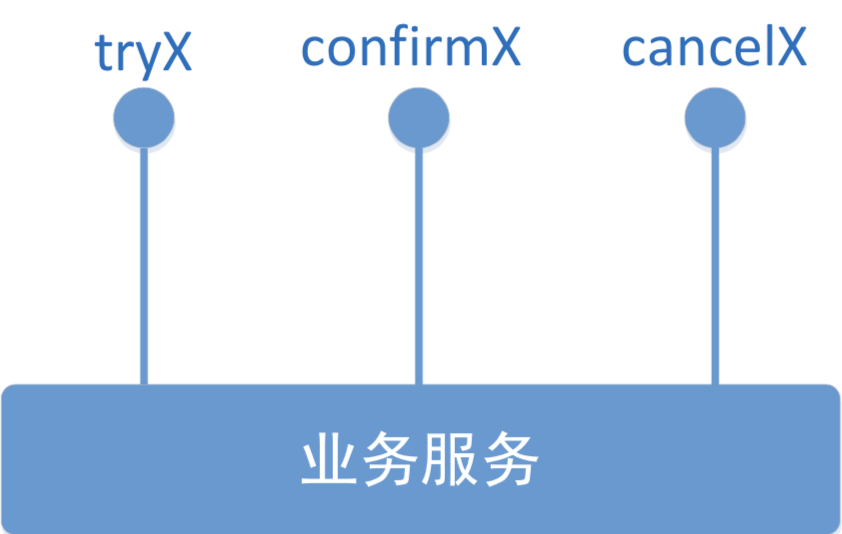
Try: 尝试执行业务
• 完成所有业务检查(一致性)
• 预留必须业务资源(准隔离性)
Confirm:确认执行业务
• 真正执行业务
• 不作任何业务检查
• 只使用Try阶段预留的业务资源
• Confirm操作要满足幂等性
Cancel: 取消执行业务
• 释放Try阶段预留的业务资源
• Cancel操作要满足幂等性
4.补偿
1.抵销(或部分抵销)正向业务操作的业务结果
2.补偿操作满足幂等性
分布式事务的解决方案
1.最大努力通知
业务活动的主动方在完成业务处理后,向业务活动被动方发送通知消息(允许消息丢失)
主动方可以设置时间阶梯型通知规则,在通知失败后按规则重复通知,直到通知N次后不再通知
主动方提供校对查询接口给被动方按需校对查询,用于恢复丢失的业务消息
这种方案在支付场景尤为常见,支付渠道一般会同时提供同步回调,异步回调,主动查询,更精确的还会有对账单的下载。
服务之间的通信很难确保百分之百的成功,如果失败了,在对于一致性要求不高的场合下,多试几次总会成功的,这种思想对于分布式事务的设计尤为重要。
2.可靠消息最终一致
消息中间件能够降低系统间的耦合性,在分布式场景中,我们也可以通过消息帮助我们实现分布式事务。
这里会有几个问题:
1.业务执行成功后,确保消息必须能够发送
2.消费端必须要能够反馈消息的消费结果
针对上述两个问题,我们思考下可靠消息一致性的实现。
1.确保消息必须能够发送
1.1确保消息必须能够发送,我们首先做的是先将将消息落地。所以我们可以将本地的业务操作和消息落地 放到一个本地事务中,如果消息落地失败,业务也得回滚,这一步可以保证一致性
1.2消息落地成功后,我们可以用一个定时器定时的根据消息的状态,时间将消息投递到mq的中间件------这一步有可能会出现异常(生成方投递失败)
2.消费端必须要能够反馈消息的消费结果
2.1消息如果投递成功,消费端会消费消息,消费完成后,通知到消息生产方------这一步有可能会出现异常(通知生产者失败)
这里有两种通知方式:
1.生产方提供服务接口给消费端调用
2.通过消息,消费端发送消费结果给生产端。
上述流程如下图所示,我们可以将这种方式称为 本地消息服务

上述方案通过消息实现了分布式事务,但是其中会有好几个流程会导致事务的不一致,这里我们通过消息确认和消息查询,消息生产者会定时根据消息状态去投递消息,所以如果消费者无法正常的进行消息确认,那么消息会不断的进行投递,所以消费端同时需要做幂等性。
虽然上述方案解决了一致性的要求,但是上面的系统耦合性太高了,主动方和被动方都存在互相调用的情况,所以有了独立消息服务的方案。
独立消息服务指的是将消息的处理独立出来,单独形成一个服务,如下图所示
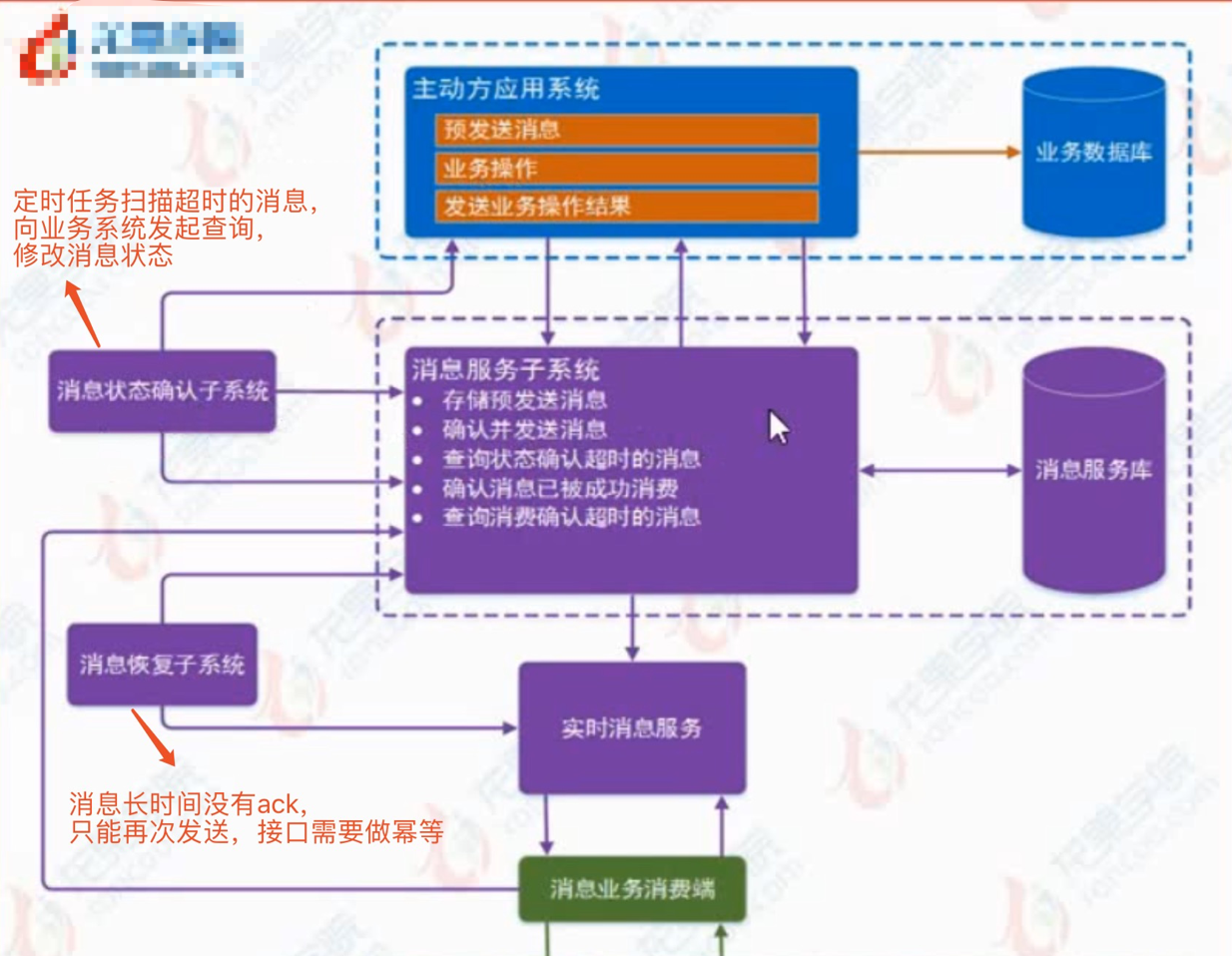
具体的流程如下
1.主动方预发送消息到消息系统,消息系统保存消息,将保存结果反馈给主动方----可能直接发送失败或者反馈的时候失败
2.主动方收到正确的消息保存结果后,开始执行业务,业务执行完成后,将业务执行结果发送出去------可能存在发送失败问题
3.消息服务收到业务执行结果后,对消息做更新或者删除(对应业务的成功与失败),然后投递到中间件,消费端取消费------消费端可能获取不到消息
4.消费端消费完成后,将消费结果返回-----可能无法返回
上述各个流程都会出现异常,下面我们来解决异常情况
1.第一步如果出现异常,消息和业务都不会执行下去,数据的一致性得到了保障,业务系统需要用定时任务保障这些未执行的业务
2.第二步如果出现异常了,业务执行了,但是消息未投递出去,数据就不一致了,这时候需要消息服务定时的根据消息的时间和状态查询业务的状态,以便能及时的更新消息状态
3.第三步和第四步是同一个解决方案,对于消息系统来说,消息投递出去后 如果消费端不给我ack,我是没办法知道我是否投递成功的。所以对于长时间没有ack的消息,消息系统统一都会认为消息投递失败,再次进行投递。这时候,消费端必须要做到幂等性。
3.TCC
相关代码还在研究,待完成。。。
参考:
http://www.tianshouzhi.com/api/tutorials/distributed_transaction/383
https://juejin.im/post/5aa3c7736fb9a028bb189bca
http://www.roncoo.com/course/view/7ae3d7eddc4742f78b0548aa8bd9ccdb