在成功获取微博用户的列表之后,我们可以对每个用户的主页内容进行爬取了
环境
tools
1、chrome及其developer tools
2、python3.6
3、pycharm
Python3.6中使用的库
1 import urllib.error 2 import urllib.request 3 import urllib.parse 4 import urllib 5 import json 6 import pandas as pd 7 import time 8 import random 9 import re 10 from datetime import datetime 11 from lxml import etree
爬取字段确定
首先,我们只管的浏览用户主页,点击全部微博,观察我们能获取到的信息:
- 用户id
- 微博id
- 微博时间
- 微博内容
- 微博发布平台
- 微博评论数
- 微博点赞数
- 微博转发数
- 原微博id
- 原微博用户id
- 原微博用户名
- 原微博内容
- 原微博评论数
- 原微博点赞数
- 原微博转发数
然后,我们利用Chrome的developer tools观察用户个人主页所能获取到的主要内容,发现有些转发内容如果过长,无法直接通过用户主页进行爬取,而需要点进该条微博链接,对原微博进行爬取。
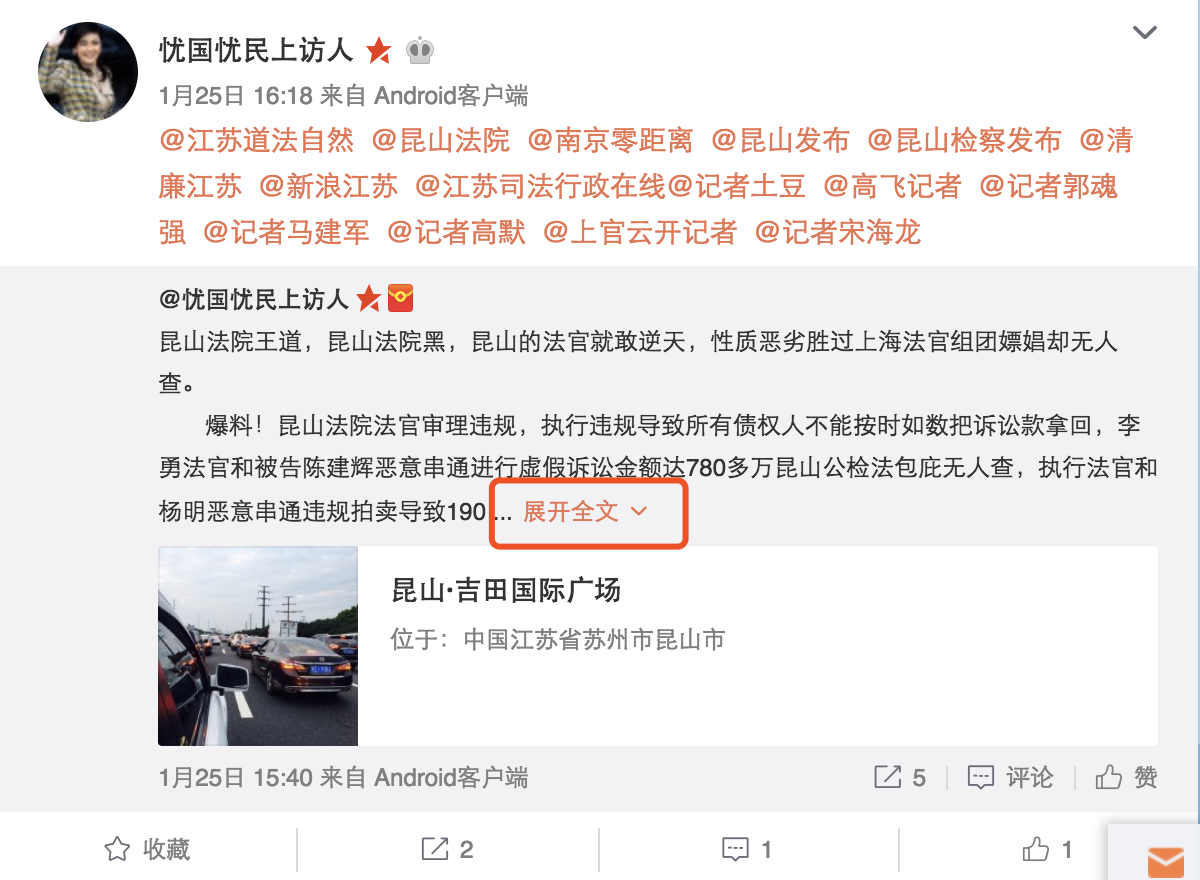
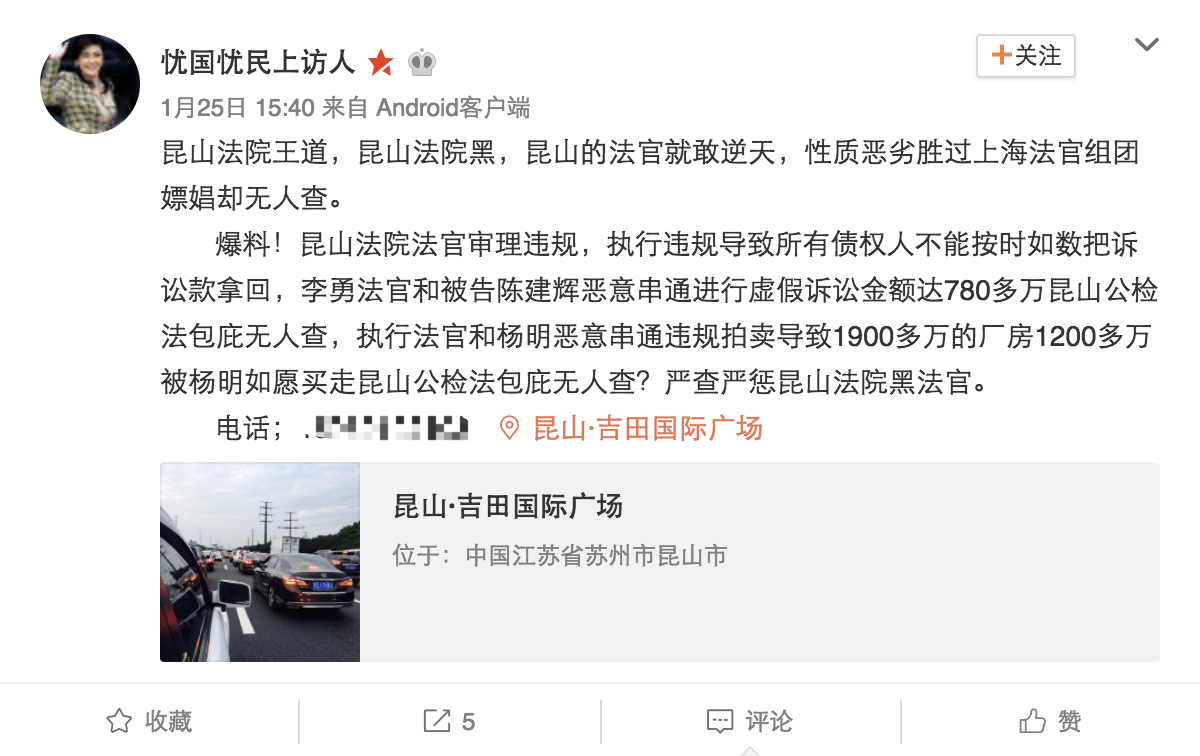
因此,我们可以爬取原微博的url,通过解析原微博url的内容来获取原微博的具体内容。
最终,通过综合情况,最后确定的字段为:
- 用户id——uid
- 微博id——mid
- 微博时间——time
- 微博发布平台——app_source
- 微博内容——content
- 微博评论数、点赞数、转发数——others
- 微博地址——url
- 是否转发——is_repost
- 原微博id——rootmid
- 原微博用户id——rootuid
- 原微博名——rootname
- 原微博地址——rooturl
加载页包抓取
在对用户的微博内容进行爬取时,最为困难的是解决网页加载的问题。微博需要两次加载,才能载入微博的全部内容,并进入下一页,因此,如何抓取到加载页的包是我们工作中最为重要的部分。
这里,我们需要借助Chrome的开发者工具,抓取页面加载时出现的包
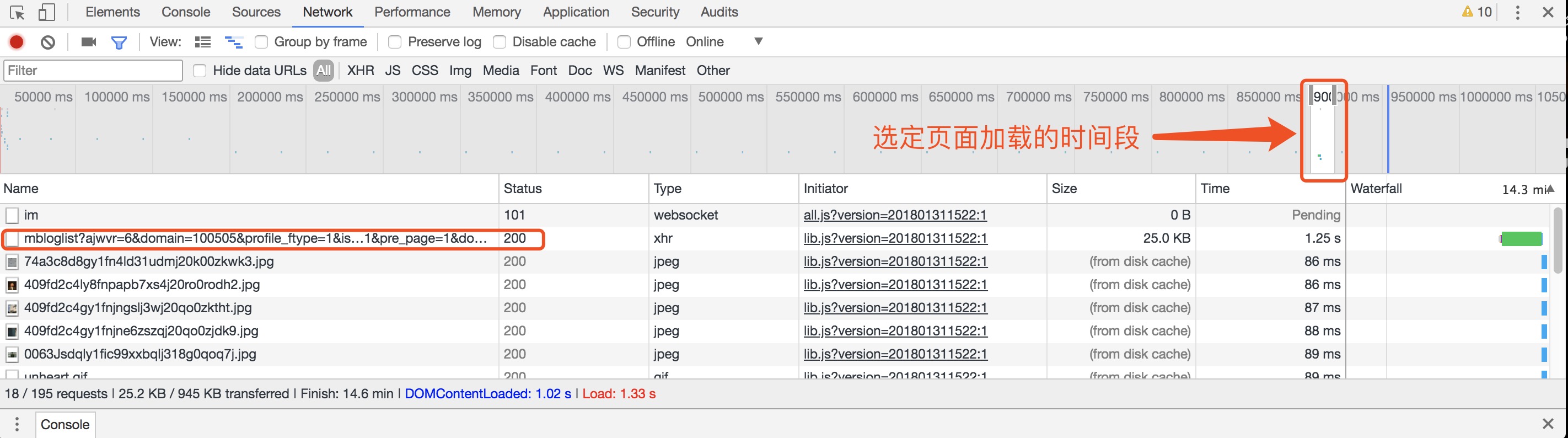
发现加载的时间段中,出现了一个xhr类型的文件,长得最像我们需要的加载包:
https://weibo.com/p/aj/v6/mblog/mbloglist?ajwvr=6&domain=100505&profile_ftype=1&is_all=1&pagebar=0&pl_name=Pl_Official_MyProfileFeed__22&id=1005051956890840&script_uri=/p/1005051956890840/home&feed_type=0&page=1&pre_page=1&domain_op=100505&__rnd=1517384223025
再加载一次试验一下,发现出现它又出现了:
https://weibo.com/p/aj/v6/mblog/mbloglist?ajwvr=6&domain=100505&profile_ftype=1&is_all=1&pagebar=1&pl_name=Pl_Official_MyProfileFeed__22&id=1005051956890840&script_uri=/p/1005051956890840/home&feed_type=0&page=1&pre_page=1&domain_op=100505&__rnd=1517384677638
看到pl_name=Pl_Official_MyProfileFeed__22基本上就准了,为了保险起见,我们再点开链接看看,然后发现——果然是熟悉的配方,熟悉的味道~~
仔细解析这段url,发现:
- is_all是页面属性,表示全部微博
- page和pre_page都表示页数
- id是用户id【uid】和domain【100505】的结合体
- script_uri是当前用户的主页url字段
- pagebar长得最像加载页,第一个加载页为0,第二个加载页为1
- __rnd是时间戳,可以省略
结合初始网页没有pre_page和pagebar这两个字段,我们去掉这两个字段,运行一下url,观察一下所得到的内容,发现为加载前的用户发布的微博内容。
因此我们可以将用户主页的每一页分为三个部分,分成三个url进行解析,获取整个页面的内容。
具体代码如下:
1 # 初始化url 2 def getBeginURL(self): 3 begin_url = 'https://weibo.com/p/aj/v6/mblog/mbloglist?ajwvr=6&domain=100505&is_all=1&id=100505'+str(self.uid)+ 4 '&script_uri=/u/1956890840&domain_op=100505&page=' 5 return begin_url 6 7 # 设置加载页url,并获取html内容 8 def getHTML(self,page_num,extend_part = ''): 9 # extend_part为获取加载页的扩展字段 10 url = self.getBeginURL()+str(page_num)+extend_part 11 data = urllib.request.urlopen(url).read().decode('utf-8') 12 html = json.loads(data)['data'] 13 return html 14 15 for x in range(3): 16 if x == 0: # 初始页面 17 extend_part = '' 18 elif x == 1: 19 b = x - 1 20 extend_part = '&pre_page=' + str(i) + '&pagebar=' + str(b) 21 elif x == 2: 22 b = x - 1 23 extend_part = '&pre_page=' + str(i) + '&pagebar=' + str(b) 24 html = self.getHTML(i, extend_part) 25 page = etree.HTML(html)
以上,最为头大的问题就解决啦~
博主写代码的时候为了解决加载包的问题头疼了好几天,结果发现Chrome的开发者工具比我想的还要强大的多,不由的感叹自己的愚蠢。发现了加载包的规律有,后面的一切都水到渠成,迅速的完成了微博内容爬取的代码~
下面是我的代码,各位可以参考。
博主为了可以实时更新内容,设置了爬取微博的时间段,可以避免每次都爬取页数而造成微博重复爬取的麻烦。
代码还有很多需要改进的地方,希望各位多多交流~


1 import urllib.error 2 import urllib.request 3 import urllib.parse 4 import urllib 5 import json 6 import pandas as pd 7 import time 8 import random 9 import re 10 from datetime import datetime 11 from datetime import timedelta 12 from lxml import etree 13 14 class getWeiboContent(): 15 """ 16 微博内容爬取: 17 mid 18 time 19 app_source 20 content 21 url 22 others(repost, like, comment) 23 is_repost 24 rootmid 25 rootname 26 rootuid 27 rooturl 28 """ 29 def __init__(self, uid, begin_date=None, begin_page=1, interval=None, flag=True): 30 self.uid = uid # 微博用户ID 31 self.begin_page = begin_page # 起始页 32 self.interval = interval # 需要爬取的页数,默认为None 33 self.begin_date = begin_date # 爬取的微博的起始发布日期,默认为None 34 self.flag = flag 35 36 # 初始化url 37 def getBeginURL(self): 38 begin_url = 'https://weibo.com/p/aj/v6/mblog/mbloglist?ajwvr=6&domain=100505&is_all=1&id=100505'+str(self.uid)+ 39 '&script_uri=/u/1956890840&domain_op=100505&page=' 40 return begin_url 41 42 # 设置加载页url,并获取html内容 43 def getHTML(self,page_num,extend_part = ''): 44 url = self.getBeginURL()+str(page_num)+extend_part 45 print(url) 46 data = urllib.request.urlopen(url).read().decode('utf-8') 47 html = json.loads(data)['data'] 48 return html 49 50 # 爬取每条微博的内容,输出字典 51 def getContent(self,node): 52 dic = {} 53 dic['mid'] = node.xpath('./@mid')[0] 54 print('mid:'+dic['mid']) 55 dic['time'] = node.xpath('.//div[@class="WB_from S_txt2"]/a[1]/@title')[0] 56 app_source = node.xpath('.//div[@class="WB_from S_txt2"]/a[2]/text()') 57 if len(app_source) !=0 : # 部分微博不显示客户端信息 58 dic['app_source'] = app_source[0] 59 content = node.xpath('./*/*/div[@class="WB_text W_f14"]')[0].xpath('string(.)') 60 dic['content'] = re.compile(' s*(.*)').findall(content)[0] 61 others = node.xpath('.//ul[@class="WB_row_line WB_row_r4 clearfix S_line2"]//span[@class="line S_line1"]/span/em[2]/text()') 62 dic['repost_num'] = others[1] 63 dic['comment_num'] = others[2] 64 dic['like_num'] = others[3] 65 detail_info = node.xpath('./div[@class="WB_feed_handle"]/div/ul/li[2]/a/@action-data')[0] 66 dic['url'] = re.compile('&url=(.*?)&').findall(detail_info)[0] 67 rootmid = node.xpath('./@omid') 68 # 判断是否存在转发微博 69 if len(rootmid) != 0: 70 dic['is_repost'] = 1 71 dic['rootmid'] = rootmid[0] 72 weibo_expend = node.xpath('./*/*/div[@class="WB_feed_expand"]')[0] 73 rootname = weibo_expend.xpath('./*/*/a[@class="W_fb S_txt1"]/@nick-name') 74 # 判断原博是否被删除 75 if len(rootname) != 0: 76 dic['rootuid'] = re.compile('rootuid=(.*?)&').findall(detail_info)[0] 77 dic['rootname'] = re.compile('rootname=(.*?)&').findall(detail_info)[0] 78 dic['rooturl'] = re.compile('rooturl=(.*?)&').findall(detail_info)[0] 79 80 return dic 81 82 # 获取微博内容 83 def getWeiboInfo(self): 84 i = self.begin_page 85 # 判断是否划定了爬取页数 86 if self.interval is None: 87 # 若未划定爬取页数,则设置自动翻页参数hasMore=True 88 hasMore = True 89 end_page = False 90 else: 91 # 若划定爬取页数,则爬取页数优先 92 end_page = self.begin_page+self.interval 93 hasMore = False 94 # 初始化一个DataFrame用于存储数据 95 weibo_df = pd.DataFrame() 96 while (i <= end_page | hasMore) and self.flag: 97 for x in range(3): 98 if x == 0: # 初始页面 99 extend_part = '' 100 elif x == 1: # 第一个加载页 101 b = x-1 102 extend_part = '&pre_page=' + str(i) + '&pagebar=' + str(b) 103 elif x == 2: # 第二个加载页 104 b = x-1 105 extend_part = '&pre_page=' + str(i) + '&pagebar=' + str(b) 106 html = self.getHTML(i, extend_part) 107 page = etree.HTML(html) 108 if page is None: 109 break 110 else: 111 detail = page.xpath('//div[@class="WB_cardwrap WB_feed_type S_bg2 WB_feed_like "]') 112 # 判断用户是否发过微博 113 if len(detail) == 0: 114 print('该用户并未发过微博') 115 break 116 weibo = {} 117 weibo['mid'] = [] 118 weibo['time'] = [] 119 weibo['content'] = [] 120 weibo['app_source'] = [] 121 weibo['url'] = [] 122 weibo['repost_num'] = [] 123 weibo['comment_num'] = [] 124 weibo['like_num'] = [] 125 weibo['is_repost'] = [] 126 weibo['rootmid'] = [] 127 weibo['rootname'] = [] 128 weibo['rootuid'] = [] 129 weibo['rooturl'] = [] 130 for w in detail: 131 all_info = self.getContent(w) 132 # 判断是否设置了微博的开始日期 133 if self.begin_date is None: 134 pass 135 else: 136 weibo_dt = datetime.strptime(all_info['time'], '%Y-%m-%d %H:%M').date() 137 begin_dt = datetime.strptime(self.begin_date, "%Y-%m-%d").date() 138 # 判断微博发布日期是否在开始日期之后 139 if begin_dt > weibo_dt: 140 # 当微博发布日期在开始日期之后时,停止爬取 141 self.flag = False 142 break 143 weibo['mid'].append(all_info.get('mid', '')) 144 weibo['time'].append(all_info.get('time', '')) 145 weibo['app_source'].append(all_info.get('app_source','')) 146 weibo['content'].append(all_info.get('content', '')) 147 weibo['url'].append(all_info.get('url', '')) 148 weibo['repost_num'].append(all_info.get('repost_num', '')) 149 weibo['comment_num'].append(all_info.get('comment_num', '')) 150 weibo['like_num'].append(all_info.get('like_num', '')) 151 weibo['is_repost'].append(all_info.get('is_repost', 0)) 152 weibo['rootmid'].append(all_info.get('rootmid', '')) 153 weibo['rootname'].append(all_info.get('rootname', '')) 154 weibo['rootuid'].append(all_info.get('rootuid', '')) 155 weibo['rooturl'].append(all_info.get('rooturl', '')) 156 weibo = pd.DataFrame(weibo) 157 weibo['uid'] = self.uid 158 weibo_df = weibo_df.append(weibo,ignore_index=True) 159 # 提取下一页链接 160 if page is None: 161 break 162 else: 163 next_page = page.xpath('//a[@class="page next S_txt1 S_line1"]/@href') 164 if len(next_page) == 0: # 判断是否存在下一页 165 self.flag = False 166 print('已是最后一页') 167 else: 168 page_num = re.compile('page=(d*)').findall(next_page[0])[0] 169 i = int(page_num) 170 time.sleep(random.randint(5, 10)) # 设置睡眠时间 171 return weibo_df 172 173 if __name__=='__main__': 174 uid = input('请输入uid:') 175 begin_date = input('请输入日期,格式为xxxx-xx-xx:') 176 begin_page = input('请输入开始页,默认为1:') 177 getWeiboContent(uid, begin_date).getWeiboInfo()