子查询主要分为相关子查询和非相关子查询,本次以例子的形式为大家分享如何做数据库的子查询
创建数据库
CREATE DATABASE demo103
创建两张表
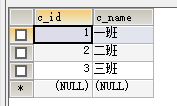
CREATE TABLE t_class(
c_id INT AUTO_INCREMENT PRIMARY KEY,
c_name VARCHAR(50) NOT NULL
)
CREATE TABLE t_student(
s_id INT AUTO_INCREMENT PRIMARY KEY,
s_name VARCHAR(50) NOT NULL,
s_sex VARCHAR(20) DEFAULT'男',
s_classid INT,
CONSTRAINT FOREIGN KEY (s_classid) REFERENCES t_class(c_id)
)
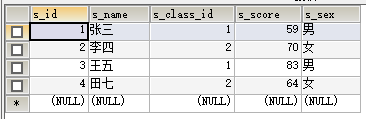
-- 学生表是看不出有3班的,不代表没有三班,这是为什么单独把班级表抽出来的原因,而且学生的班级只能对应班级表中
-- 已经存在的班级,不能随意输入,因为做了外键约束。
-- 现在改掉1,2,3班 换成110班 120班 119班,那你还知道学生表中的班级id对应的是哪个班不?
-- 查询学生姓名及对应班级名称 涉及到2个表
-- 学生姓名可以从t_student 获取,最多只能得到s_classid,班级名称c——那么哪儿来,班级名称要从 t_class获取
SELECT s_name FROM t_student
SELECT c_name FROM t_class
-- 就可以使用子查询 就是一个嵌套查询 一个查询中嵌入另外一个查询 最多嵌入255条查询
-- 首先from t_student这张表 然后找的s_name 和s_classid 这个时候一行一行去看,是不是每行都可以得到一个s_classid
-- 然后再到t_class表中去找c_name
-- 1.相关子查询, 子查询必须依赖于主查询 ,子查询单独运行会报错,依赖于主查询的结果
-- select嵌套 只能返回单行单列
-- 每次主查询 执行一次,子查询也会执行一次,最终执行N+1次,效率低下,如果主查询没有提供数据,子查询无法执行
-- select 嵌套只能返回单行单列
SELECT s_name,(SELECT c_name FROM t_class WHERE c_id=s_classid) FROM t_student
-- 2.非相关子查询
-- 子查询对主查询没有依赖 子查询只会执行一次,只会在from的时候才执行,性能较高,能独立运行,只是给主查询提供条件值
-- from 嵌套 必须要给嵌套的子查询表起别名,可返回多行多列数据
-- 查询性别为女 并且姓名为张三的
SELECT * FROM (SELECT * FROM t_student WHERE s_sex='女') AS t1
WHERE t1.s_name='张三'
-- where 嵌套 执行2次,子查询可以单独运行,不依赖主查询,只是给主查询提供条件值
-- 查询一班的学生有哪些
万一 t_class 的 c_id 三班==1 ,→首先找到一班的c_id → where s_classid=一班的c_id
SELECT * FROM t_student WHERE s_classid=1
-- →首先找到一班的c_id select c_id from t_class where c_name='一班'
SELECT * FROM t_student WHERE s_classid=(SELECT c_id FROM t_class WHERE c_name='一班') -- 返回多行单列 (in 关键词)
-- 实际上子查询就是嵌套查询
-- 嵌套位置
-- select | where | from
-- 查询与张三一个班级的学生有哪些
-- 找出张三是哪个班
SELECT s_classid FROM t_student WHERE s_name='张三'
-- 找出张三同班 的 classid=1 的同学
SELECT s_name FROM t_student WHERE s_classid=1
SELECT * FROM t_student WHERE s_classid=(SELECT s_classid FROM t_student WHERE s_name='张三')
-- 查询与张三一个班级的学生有哪些,结果不包含张三
SELECT * -- 3
FROM t_student -- 1
WHERE s_classid=(SELECT s_classid FROM t_student WHERE s_name='张三') -- 2
HAVING s_name!='张三' -- 4 where是在select之前,不能用做聚合函数的判断
-- having是在selcet之后,而且还可以用在select里面的聚合函数
-- 并且是之后才执行,所以可以用在二次筛选,
-- 有聚合函数就必须要用having
AND s_name!='张三' -- 4 AND也可以
-- 名字比较混乱加别名
SELECT * -- 3
FROM t_student t2 -- 1
WHERE t2.s_classid=(SELECT t1.s_classid FROM t_student t1 WHERE t1.s_name='张三') -- 2
HAVING t2.s_name!='张三' -- 4
-- 查询班上比平均分高的学生有哪些
-- @1 找到平均分
SELECT AVG(IFNULL(s_score,0)) FROM t_student
-- where s_score > 平均分
SELECT * FROM t_student WHERE s_score>( SELECT AVG(IFNULL(s_score,0)) FROM t_student)
-- 查询每个班上比平均分高的学生有哪些
-- @1 找到每个班平均分
SELECT s_classid,AVG(IFNULL(s_score,0)) FROM t_student GROUP BY s_classid
-- where s_score > 平均分
SELECT *
FROM (SELECT *,AVG(IFNULL(s_score,0)) FROM t_student GROUP BY s_classid) t2
WHERE t2.s_score>(SELECT AVG(IFNULL(s_score,0)) FROM t_student)
-- 第二种
SELECT * FROM t_student t1
WHERE s_score>(SELECT AVG(s_score) FROM t_student t2 WHERE t2.s_classid=t1.s_classid GROUP BY s_classid)
-- 这个where也嵌套了一个相关子查询,所以我们在这儿只是说明一个事:相关还是非相关跟位置没关系
-- 查询至少有一名学生的班级名称
SELECT c_name FROM t_class WHERE c_id IN(1,2,3) -- 如果三班没有学生呢,这是我们知道只有1,2,3班有学生
-- in 集合的概念,一堆,不能直接用等号嘛
SELECT s_classid FROM t_student -- 获取到t_student 里面有出现的s_classid 有出现,代表至少有一名学生
SELECT c_id,c_name FROM t_class WHERE c_id IN(SELECT s_classid FROM t_student)
-- ANY有点类似IN | All,只是语法不一样,用等号(where=) any必须结合子查询来使用 ANY子查询投影出来的结果
SELECT c_id,c_name FROM t_class WHERE c_id= ANY(SELECT s_classid FROM t_student)
SELECT c_name FROM t_class WHERE c_id= ANY(1,2,3) -- 错误 any必须结合子查询来使用
-- 有两个张三。查询分数高于任意一个张三的所有学生
-- 张三的分数
SELECT s_score FROM t_student WHERE s_name='张三'
SELECT * FROM t_student WHERE s_score>ANY( SELECT s_score FROM t_student WHERE s_name='张三')
-- 还可以使用MIN
SELECT * FROM t_student WHERE s_score>(SELECT MIN(s_score) FROM t_student WHERE s_name='张三')
-- 查询分数高于任意一个张三的所有学生 -- 使用all
SELECT * FROM t_student WHERE s_score>ALL(SELECT s_score FROM t_student WHERE s_name='张三')
-- any 和all 必须跟子查询 不能单独使用
-- 子查询不管怎么变,都只有三种,在where中嵌套一个,form 一个,select一个