NNLM(Neural Network Language Model)
神经网络语言模型对理解word2vec模型有很大的帮助, 包括对后期理解CNN,LSTM进行文本分析时有很大的帮助.
模型训练数据
是一组词序列w1…wT,wt∈V。其中 V 是所有单词的集合(即训练预料中的词构成的词典), 词向量把n-gram的离散空间转换为连续空间.
概率函数
$f(w_{t},w_{t-1},...,w_{t-n+2}, w_{t-n+1})=p(w_{t} | {w_{1}}^{t-1})$
在这个模型中,可分为特征映射和计算条件概率分布两部分:
1. 一个 |V|×m映射矩阵C,每一行表示某个单词的特征向量,是m维,共|V|列,即|V|个单词都有对应的特征向量在C中
2.通过一个函数 g (g 是前馈或递归神经网络)将输入的词向量序列(C(wt−n+1),...,C(wt−1)) 转化为一个概率分布,即该函数$p(w_{t} | {w_{1}}^{t-1})$是来估计,其中i有|V|种取值。如果把该网络的参数记作ω,那么整个模型的参数为 θ = (C,ω)。我们要做的就是在训练集上使下面的目标似然函数最大化.
目标函数:
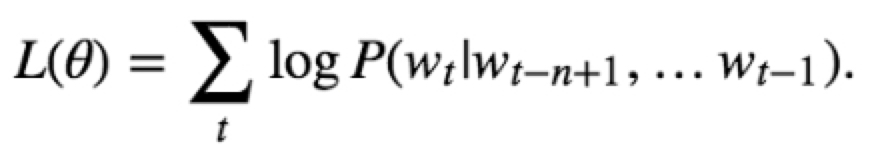
神经网络语言模型的网络结构图:
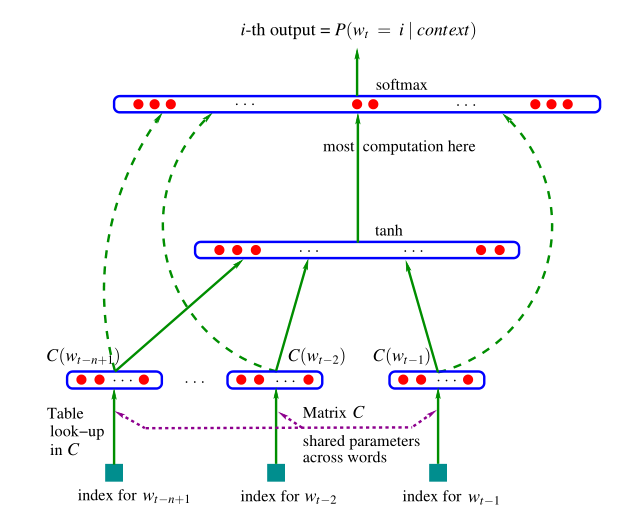
网络结构:
从下往上依次是:
输入层:window窗口中上下文的每个词one-hot向量
投影矩阵: 紫色虚线表示词语通过投影矩阵Matrix C对词进行映射
投影矩阵也是稠密词向量, 词典维数V,稠密词向量表示维数D

1*|V|*|V|*m = 1*m
神经网络输入层: 为经过投影矩阵映射后的词向量的拼接, 输入向量大小为窗口上下文词的数量乘以定义的词向量的长度
神经网络隐藏层: 加激活函数tanh等进行非线性映射
输出层:softmax做归一化,保证概率和为1.
$p(w_{t}|w_{t-1},...,w_{t-n+2}, w_{t-n+1}) = frac{ e^{y_{w_{t}}} }{ sum_{i}^{ }e^{y_{i}} }$