奇异矩阵分解SVD
奇异矩阵分解的核心思想认为用户的兴趣只受少数几个因素的影响,因此将稀疏且高维的User-Item评分矩阵分解为两个低维矩阵,即通过User、Item评分信息来学习到的用户特征矩阵P和物品特征矩阵Q,通过重构的低维矩阵预测用户对产品的评分.SVD的时间复杂度是O(m3).
在了解奇异矩阵分解前, 先要了解矩阵分解, 矩阵分解就是特征值分解, 特征值分解和奇异值分解的目的都是一样,就是提取出一个矩阵最重要的特征.先谈谈特征值分解吧:
一.特征值分解:
如果说一个向量v是方阵A的特征向量,将一定可以表示成下面的形式:
![]() 这时候λ就被称为特征向量v对应的特征值,特征值不改变向量的方向,只会对向量进行伸缩的长度变换,一个矩阵的一组特征向量是一组正交向量.特征值分解是将一个矩阵分解成下面的形式:
这时候λ就被称为特征向量v对应的特征值,特征值不改变向量的方向,只会对向量进行伸缩的长度变换,一个矩阵的一组特征向量是一组正交向量.特征值分解是将一个矩阵分解成下面的形式:
![]() 其中Q是这个矩阵A的特征向量组成的矩阵,Σ是一个对角阵,每一个对角线上的元素就是一个特征值.一个矩阵其实就是一个线性变换,因为一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换.特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵.
其中Q是这个矩阵A的特征向量组成的矩阵,Σ是一个对角阵,每一个对角线上的元素就是一个特征值.一个矩阵其实就是一个线性变换,因为一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换.特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵.
二.奇异值分解:
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,比如说有N个用户,每个用户对应M个物品,这样形成的一个N * M的矩阵就不可能是方阵,我们怎样才能描述这样普通的矩阵呢的重要特征呢?奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法:
设 A 为一个 $m imes n$ 阶实矩阵, $r=mathrm{rank}A $,SVD 具有以下形式:
$A=USigma V^T$
其中 U 是 $m imes m$ 阶, V 是 $n imes n $阶, $Sigma$ 是 $m imes$ n 阶.特别的是,方阵 U 和 V 都是实正交矩阵(orthogonal matrix),也就是说, $U^T=U^{-1}$ ,$ V^T=V^{-1}$, $Sigma$ 是(类)对角矩阵,对角线上的值对应于对角矩阵的特征值,(类)对角矩阵上是奇异值,
图示可以帮助我们了解SVD 的矩阵结构. SVD 最特别的地方是 
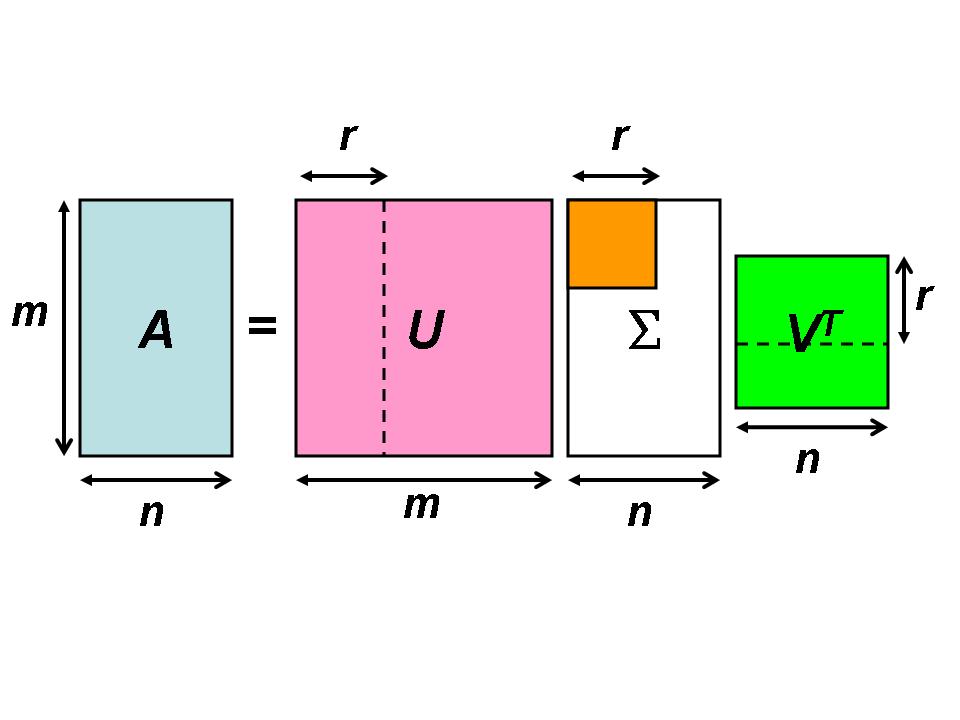
令 U 的行向量(column vector)为$ mathbf{u}_i $, $i=1,ldots,m $, V 的行向量为$ mathbf{v}_j $,$ j=1,ldots,n $,$ A=USigma V^T$ 可以表示为 r 个秩-1 (rank-one) 矩阵之和:

上式指出 A 仅由 U 的前 r 个行向量(以 $U_r $表示),$ V^T $的前 r 个列向量(以 $V_r^T$ 表示),以及 $Sigma$ 的左上 $r imes r$ 分块决定(以 $Sigma_r$ 表示), 矩阵 A 总共有 $m imes n $个元,$ U_r$ 有 $m imes r $个元, $V_r^T$ 有$ r imes n$ 个元,$ Sigma_r$ 则只需储存主对角的 r 个非零元. 若以SVD 形式储存,总计有 $(m+n+1) imes r $个元. 当 r 远小于 m 和 n 时,利用矩阵的SVD 可以大幅减少储存量.

三.推荐系统隐语义模型中应用
1.假定有U个用户, V个item, R为打分矩阵
假定有K个隐含变量, 我们需要找到矩阵P(U*K)和Q(K*V):
![]()
2.如何才能找到最佳的P和Q呢?
梯度下降(由于用户和物品的特征向量维度比较低,因而可以通过梯度下降(Gradient Descend)的方法高效地求解):
1.定义损失函数(加正则化项)
![]()
2.求梯度/偏导, 更新迭代公式:

3.再还原回矩阵乘积, 即可补充未打分项.
四.矩阵分解在推荐中的优缺点
矩阵分解方法将高维User-Item评分矩阵映射为两个低维用户和物品矩阵,解决了数据稀疏性问题.使用矩阵分解具有以下优点:
1.比较容易编程实现,随机梯度下降方法依次迭代即可训练出模型.
2.比较低的时间和空间复杂度,高维矩阵映射为两个低维矩阵节省了存储空间,训练过程比较费时,但是可以离线完成;评分预测一般在线计算,直接使用离线训练得到的参数,可以实时推荐.
3.预测的精度比较高,预测准确率要高于基于领域的协同过滤以及内容过滤等方法.
4.非常好的扩展性,很方便在用户特征向量和物品特征向量中添加其它因素,例如添加隐性反馈因素的SVD++,添加时间动态time SVD++,此方法将偏置部分和用户兴趣都表示成一个关于时间的函数,可以很好的捕捉到用户的兴趣漂移.
矩阵分解的不足主要有:
1.模型训练比较费时.
2.推荐结果不具有很好的可解释性,分解出来的用户和物品矩阵的每个维度* 无法和现实生活中的概念来解释,无法用现实概念给每个维度命名,只能理解为潜在语义空间.