引用
人生苦短,Python是岸。近年来随着人工智能和机器学习的发展,Python大火,但其实Python并不是一门年轻的语言,早在1991年它就出现了。这门编程语言已经发展了多年,在可预见的未来也会继续保持它的地位。如今是Python的世界,花时间学习Python编程语言将是你对未来最好的投资。
目录
Python三部曲
1、Paython是什么
Python 是一门有条理的和强大的面向对象的程序设计语言,类似于Perl, Ruby, Scheme, Java。现在流行的AI人工智能技术大部分都是用Python语言编写的,这大大促进了的Python语言的发展。AI深度学习技术本身的特点决定了其不适合静态编译型语言,而Python语言被选作AI技术框架的基础语言,更多的是源于Python的动态特性及其开发效率高等性能优势。
2、Python能干嘛
Python为我们提供了非常完善的基础代码库,覆盖了网络、文件、GUI、数据库、文本等大量内容,被形象地称作“内置电池(Batteries included)”。用Python开发,许多功能不必从零编写,直接使用现成的即可。除了内置的库外,Python还有大量的第三方库,也就是别人开发的,供你直接使用的东西。当然,如果你开发的代码通过很好的封装,也可以作为第三方库给别人使用。许多大型网站就是用Python开发的,例如YouTube、Instagram,还有国内的豆瓣。很多大公司,包括Google、Yahoo等,甚至NASA(美国航空航天局)都大量地使用Python。而网上给Python的定位是“优雅”、“明确”、“简单”,所以Python程序看上去总是简单易懂,初学者学Python,不但入门容易,而且将来深入下去,可以编写那些非常非常复杂的程序。
3、Python怎么用
在Linux、Windows、Mac OS的命令行窗口或Shell窗口,执行python命令,启动Python交互式解释器。交互式解释器会等待用户输入Python语句。输入Python语句并回车,解释器会执行语句并输出结果。交互式解释器是学习Python语言比较好的工具,优点是输入Python语句可以立即得到反馈。
我们来看下Python世界排行榜
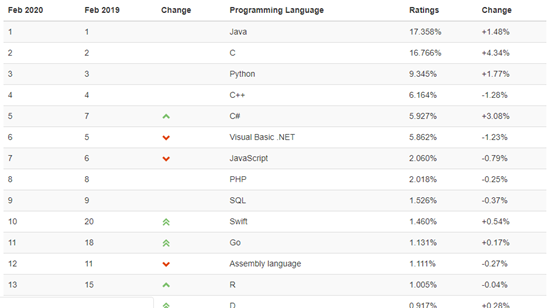
我记得19年的时候Python晋升到了第二,Hahah 当初我还以为我的小咖啡被超越了,现在发现java这门语言还是稳居世界第一,毕竟市场占有率是最高的,无论硬件软件都可以用java做。
豆瓣爬虫
豆瓣的防爬虫策略做的真的好,在最新的热门电影里面是用了Ajax动态加载的,打开豆瓣电影页面这部分是成加载状态的。
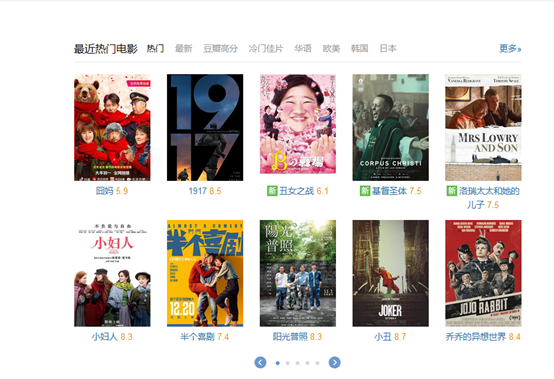
好了进入正题。先获取对应的Refer、User-Agent、Refer
这个三个获取后可以直接获取数据
具体代码如下
1 from lxml import etree 2 import requests,copy,json 3 from json2html import * 4 5 6 douban_url='https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&page_limit=50&page_start=0' 7 headers={ 8 'User-Agent':'填写自己的User-Agent', 9 'Referer': 'https://movie.douban.com/' 10 } 11 response = requests.get(douban_url,headers=headers) 12 resp = response.text 13 14 informjson = json.loads(resp) 15 jsonhtml = json2html.convert(json = informjson,table_attributes="id="info-table" class="table table-bordered table-hover"") 16 17 parser = etree.HTMLParser(encoding='utf-8') 18 result = etree.HTML(jsonhtml,parser=parser) 19 resp_ehtml = result.xpath("//table[@class='table table-bordered table-hover']")[1] 20 son_resphtml = resp_ehtml.xpath('./tbody/tr[position()>0]') 21 for resp in son_resphtml: 22 # print(etree.tostring(resp,encoding='utf-8').decode('utf-8')) 23 title = resp.xpath('./td//text()')[2] 24 rate = resp.xpath('./td//text()')[0] 25 url = resp.xpath('./td//text()')[3] 26 photo_url = resp.xpath('./td//text()')[5] 27 mp4_format =resp.xpath('./td//text()')[1] 28 sums_count ={ 29 'title' :title, 30 'rate' :rate, 31 'url' :url, 32 'photo_url': photo_url, 33 'mp4_format': mp4_format 34 } 35 copt = copy.deepcopy(sums_count) 36 print(copt) 37 for index,value in dict.items(copt): 38 print("字典:%s 字典值:%s " % (index,value))
显示结果:
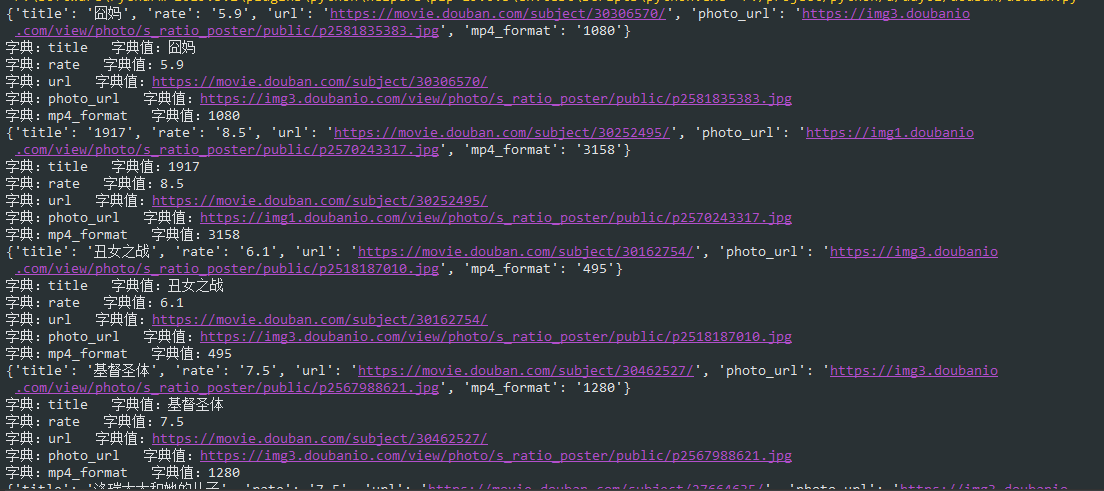
上面用到一些包,这些包提供安装方法
1 pip install lxml-4.5.0-cp38-cp38-win_amd64.whl 2 pip install requests,json2html
常见的Requests github地址:https://github.com/requests/requests
lxml python 官方文档:http://lxml.de/index.html
这些包可以自行在这里下载:https://www.lfd.uci.edu/~gohlke/pythonlibs/
总结
爬虫真的很有趣,通过模拟人的行为,来抓取有价值的数据。像论坛发的抢票软件、惠惠购物助手。百度(360、必应、搜狗、谷歌)的搜索引擎都是用爬虫做的,通过关键词抓取相关数据来展示出来。
So,学好Python,让生活节奏变得更加轻松,惬意!