视图
CBV FBV
- CBV : class based view 基于类的视图
FBV: funcation based view 基于函数的视图
使用:在views里,好处是不需要加if判断了
举个基于类的views的例子
在views里
from django.views import View
class AddPublisher(View):
def get(self,request):
# get请求hr@qutke.com
return response
def post(self,request):
# post请求
return response
在url里的路径
url(r'^add_publisher/', views.AddPublisher.as_view()),
as_view()的流程:
1). 程序启动的时候,就执行as_view() 定义view函数并返回
2). 请求到来的时候,执行父类里面的view函数:
(1). 实例化当前的类 ——》 self
(2). self.request = request
(3). 执行self.dispatch的方法:
3.1. 判断请求方式是否别允许:
3.1.1. 允许 通过反射拿到对用请求方式的方法 —— 》 handler
3.1.2. 不允许 self.http_method_not_allowed ——》 handler
3.2. 执行handler 得到 HttpResponse对象 返回
使用装饰器
定义一个timer装饰器
FBV : 直接加在函数上
CBV : from django.utils.decorators import method_decorator
@method_decorator(timer)
def get(self, request):
@method_decorator(timer)
def dispatch(self, request, *args, **kwargs):
ret=super().dispatch(request,*args,**kwargs) #调用父类方法
return ret
(1)指定给谁加上
@method_decorator(timer,name='post')
@method_decorator(timer,name='get')
class AddPublisher(View):
(2)要是这种的话,就不用写dispatch方法了,他会加在父类的方法上
@method_decorator(timer,name='dispatch')
class AddPublisher(View):
使用类装饰器和直接使用@timer有什么区别?
没什么区别,主要区别在于装饰器里的args,func上
1) 不使用method_decorator:
Args (<app01.views.AddPublisher object at 0x03B465B0>, <WSGIRequest: GET '/add_publisher/'>)
Func :func函数,取值,对应得request是第二个值(就是取值不太方便)
2) 使用method_decorator:
Args 是 (<WSGIRequest: GET '/add_publisher/'>,)
Func :bondfunc 绑定函数,取值的话第一个值对应得是request对象
request
1)属性
request.method #请求方式 POST GET :类型是字符串
request.GET #是url地址上的参数,不是get带的参数
request.POST #form表单用户提交POST请求的数据
#request.POST.get(‘name’) #得到数据(返回值,get()是字典形式)*
request.FILES # 上传的文件
request.path_info # 路径 不包含IP和端口 参数
print(request.path_info,type(request.path_info)) 结果:/index/ <class 'str'>
request.body # 请求体 请求数据 get没有请求体
结果:get b’ ‘ 是空的,post ’ b’ czc…name=’’’里面有内容
Request.META #请求头的信息
Request.COOKIES: #一个标准的python字典
Request.session: #一个既会读又课写的类似于字典的形象,表示当前会话
以上的必须记住
Request.scheme 协议 http https 结果是http 类型是字符串
Request.encoding:表示提交数据的编码方式,如果为None,则default_charset=’utf-8’
2)方法
Request.get_full_path() #路径 不包含ip和端口 包含参数
Request.is_ajax() #判断是否是ajax请求
Request.host() #获取主机的ip和端口
上传文件
-
form 表单里写上编码方式
enctype="multipart/form-data"
-
要是POST请求,在模板里要写上 {% csrf_token%}
-
request.FILES 打印结果是字典
request.FILES.get(‘s19’) 获取值, 文件在内存里
4) chunks:意思是一片一片的传
这是一个上传下载文件的代码:
在views里
def upload(request):
if request.method=='POST':
print(request.POST)
f1 = request.FILES.get('s19')
print(f1,type(f1))
with open(f1.name,'wb')as f: #把文件写进去,字节形式
for chunk in f1.chunks():
f.write(chunk)
return render(request,'upload.html')
在模板里
<form action="" method="post" enctype="multipart/form-data">
{% csrf_token %}
文件 <input type="file" name="s19">
<button>上传</button>
</form>
response
HttpResponse('字符串') ——》 返回的字符串
render(request,'模板的文件名',{k1:v1}) ——》 返回一个完整的HTML页面
redirect(要跳转的地址) —— 》重定向 Location :地址
jsonresponse
httpresponse 和jsonresponse 的区别
Jsonresponse 传输字典类型的,要想传输其他类型,加上safe=False
from django.http.response import JsonResponse
JsonResponse(data) # Content-Type: application/json
JsonResponse(data,safe=False) # 传输非字典类型
举个例子
import json
from django.http.response import JsonResponse
def json_data(request):
date={'name':'alex','age':30}
# return HttpResponse(date) #得到的是字典的键
ret = HttpResponse(json.dumps(date))
ret['Content-Type']='application/json'
return ret #{'name':'alex','age':30}
# Content-Type: text/html; charset=utf-8
# return JsonResponse(date) #{'name':'alex','age':30}
# Content-Type: application/json
return JsonResponse(li,safe=False)
分组
- Django settings.py配置文件中默认没有 APPEND_SLASH 这个参数,但 Django 默认这个参数为 APPEND_SLASH = True。 其作用就是自动在网址结尾加'/'。
2.分组 ( )
url(r'^blog/([0-9]{4})/([0-9]{2})/$', views.blog),
分组的结果会当做位置参数 ——》 传递给视图函数
def blog(request,name,aa):
return HttpResponse('ok')
3.命名分组 (?P
url(r'^blog/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.blog),
分组的结果会当做关键字参数 ——》 传递给视图函数
def blog(request,year,month):
print(year,month)
return HttpResponse('ok')
4.include 路由分发
先匹配一级目录,在匹配二级目录 (多个app的时候)
from django.conf.urls import url,include
from app01 import views
urlpatterns = [
url(r'^app01/', include('app01.urls')),
url(r'^app02/', include('app02.urls')),
]
**传递额外的参数给视图函数 **
注:要是命名函数的名字和参数的键同名,那命名函数名字的值就是参数的值
url(r'^blug/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/',views.blug,{'foo':'v1'})
def blug(request,year,month,**kwargs):
print(year,month)
print(kwargs)
return HttpResponse('ok')
5. URL命名和反向解析
静态地址
1)命名
url(r'^blog/$', views.blogs, name='xxxx'),
url(r'^home/',views.home)
使用:
在模板
{% url 'xxxx' %} ——》 '/blog/' 一个完整的URL
或是在py文件
from django.urls import reverse
reverse('xxxx') ——》 '/blog/
2)命名分组
url(r'^blog/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.blog,name='blog' ),
使用:
在模板
{% url 'blog' ‘2019’ ‘12’ %} ——》 '/blog/2019/12/' 一个完整的URL 位置传参
{% url 'blog' month='09' year='2016' %} '/blog/2016/09/' 关键字传参
在py文件
from django.urls import reverse
reverse('blog',args=('2018','02')) ——》 '/blog/2018/02'
reverse('blog', kwargs={'year': '2020', 'month': '03'}) ——》 /blog/2020/03
namespace 在多个app下有相同的方法,用'namespace:name'便于区分
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^app01/', include('app01.urls',namespace='app01')),
url(r'^app02/', include('app02.urls',namespace='app02')),
]
使用:
在模板
{% url 'namespace:name' 参数 %}
在py文件
reverse( 'namespace:name' ,arrgs=(),kwargs={} )
admin的使用
LANGUAGE_CODE = 'zh-Hans' 改成中文
1. 创建超级用户
python manage.py createsuperuser
用户名和密码 密码 数字+字母+至少8位
2. 注册model
在app下的admin.py中写
from app01 import models
admin.site.register(models.Person)
3. 访问 http://127.0.0.1:8000/admin/
ORM模型
对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。
ORM的操作:
类 —— 》 表
对象 —— 》 数据(记录)
属性 —— 》 字段
models.User.objects.all() # 所有数据 对象列表
models.User.objects.get(username='alex') # 获取一个满足条件的对象 没有数据 或者 多条数据就报错
models.User.objects.filter(username='alex1') # 获取满足条件的所有对象 对象列表1) 对应关系
class Student(models.Model)
models.CharField (max_length=32) # varchar(32)
models.AutoField (primary_key=True) #自增字段 pk主键
models.ForeignKey (‘Publisher’,on_delete=models.CASCADE) #publisher是所管连的表的类名(可以是字符串的形式)
models.CASCADE 是级联删除
default=’男’
on_delete=models.SET_DEFAULT 是设置默认值
SET_NULL是设置为空
SET(value)
on_delete:所关联的表删除后,对这个表所做的操作
django1.11版本之前的不用填写 默认是on_delete=models.CASCADE
django2.0版本之后就是必填项
1.ORM字段 对象关系映射
常用的字段
AutoField :自增字段 自增的整形字段,必填参数primary_key=True,则成为数据库的主键。无该字段时,django自动创建。
一个model不能有两个AutoField字段。
AutoField****IntegerField: 一个整数类型。数值的范围是 -2147483648 ~ 2147483647。
AutoField****CharField: 字符类型
AutoField****DateField ; 日期类型
参数:
auto_now:每次修改时修改为当前日期时间。
auto_now_add:新创建对象时自动添加当前日期时间。每次修改时,时间不变
auto_now和auto_now_add和default参数是互斥的,不能同时设置。
AutoField****DatetimeField : 日期时间字
AutoField****BooleanField : - 布尔值类型
AutoField****NullBooleanField 可以为空
AutoField****TextField- 文本类型
AutoField****FloatField:浮点型
AutoField****DecimalField 10进制小数
2.参数
1). null = Ture 数据库中可以为空
2). blank = Ture 表单中可以为空
3). db_column 修改数据库中字段的列名
4). default 默认值
5) unique=True 唯一
6) verbose_name=’名字’ Admin中显示的字段名称中文提示
7) choices Admin中显示选择框的内容可供选择的值 gender=models.BooleanField('性别',default=False,choices=((0,'男'),(1,'女')))
8) help_text='请输入正确年龄' Admin中该字段的提示信息
3.自定义一个char类型字段:
class MyCharField(models.Field):
"""
自定义的char类型的字段类
"""
def __init__(self, max_length, *args, **kwargs):
self.max_length = max_length
super(MyCharField, self).__init__(max_length=max_length, *args, **kwargs)
def db_type(self, connection):
"""
限定生成数据库表的字段类型为char,长度为max_length指定的值
"""
return 'char(%s)' % self.max_length
使用:用自定义的类名 phone = MyCharField(max_length=11,)
4. 表的参数
Class Mate类是固定写法,是给上边的类做的标配
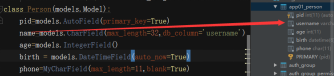
class Person(models.Model):
pid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32, db_column='username', unique=True, verbose_name='姓名') # varchar(32)
class Meta:
# 数据库中生成的表名称 默认 app名称 + 下划线 + 类名
db_table = "person"
# 排序
ordering = ('pk',)
# 联合索引
index_together = [
("name", "age"),
]
# 联合唯一索引
unique_together = (("name", "age"),)
下图是该名字,改变后,名字变了,内容不变


5. ORM的查询(13条) 必知必会13条
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "orm_practice.settings")
import django
django.setup()
from app01 import models
返回的是对象列表 (8)
all 获取表中所有的数据 ——》 对象列表 QuerySet
filter # 获取表中满足条件的所有数据 ——》 对象列表 QuerySet
exclude 获取表中不满足条件的所有数据 ——》 对象列表 QuerySet
order_by 对已经排好序的结果进行倒序 ——》 对象列表 QuerySet
排序 默认升序 字段加- 降序 多个字段 ——》 对象列表 QuerySet
models.Person.objects.all().order_by('-age', 'pk'),先按第一个字段排,要是有两个一样的,按第二个排
reverse 翻转
ret = models.Person.objects.all().order_by('pk').reverse()
values 获取数据的字段名和对应的值 ——》 对象列表 QuerySet [{} ,{}]字典
# 不填写参数 获取所有字段名字和值 obj=models.Person.objects.values()
# 填写参数 获取指定字段名字和值 obj=models.Person.objects.values('name',’age’)
values_list
获取数据的字段对应的值 ——》 对象列表 QuerySet [() ,()] 元祖
# 不填写参数 获取所有字段值
# 填写参数 获取指定字段值 有顺序
distinct 去重 所有字段都一样才去重
返回的是对象 (3)
get # 获取一条数据 ——》 对象 获取不到或者多条就报错
first 取第一个元素 没有元素 None
last 取最后一个元素 没有元素 None
返回布尔值 (1)
exists 判断是否存在 models.Person.objects.filter(name='alex').exists()
返回数字 (1)
count 计数
单表的双下划线
ret = models.Person.objects.filter(pk=1)
ret = models.Person.objects.filter(pk__gt=1) # greater than 大于
ret = models.Person.objects.filter(pk__lt=3) # less than 小于
ret = models.Person.objects.filter(pk__gte=1) # greater than equal 大于等于
ret = models.Person.objects.filter(pk__lte=3) # less than equal 小于等于
ret = models.Person.objects.filter(pk__range=[1, 3]) # 范围 左右都包含
ret = models.Person.objects.filter(pk__in=[1, 5]) # in 只要1和5
ret = models.Person.objects.filter(name__contains='alex') # like 完全包含
ret = models.Person.objects.filter(name__icontains='ale') # like 忽略大小写 ignore
ret = models.Person.objects.filter(name__startswith='a') # 以a开头
ret = models.Person.objects.filter(name__istartswith='a') # 以a开头忽略大小写
ret = models.Person.objects.filter(name__endswith='a') # 以a开头
ret = models.Person.objects.filter(name__iendswith='g') # 以a开头忽略大小写
ret = models.Person.objects.filter(phone__isnull=True) # phone字段为空
ret = models.Person.objects.filter(phone__isnull=False) # phone字段不为空
ret = models.Person.objects.filter(birth__year=2019)
ret = models.Person.objects.filter(birth__contains='2019-04-09') 包含,相当于like
# ret = models.Person.objects.filter(birth__month=4)
外键的操作
1)基于对象的查询
正向查询
正向查询: 外键所在表去查另一张表,Book >> Publisher
反向查询:普通表去查外键所在的表,Publisher >> Book
book_obj = models.Book.objects.get(pk=1)
# print(book_obj.publisher) # 书籍所关联的对象
# print(book_obj.publisher.name) # 书籍所关联的对象的名字
# print(book_obj.publisher_id) # 书籍所关联的对象的ID
反向查询
pub_obj = models.Publisher.objects.get(pk=1)
# 外键中 不指定related_name pub_obj.表名小写_set 关系管理对象
# print(pub_obj.book_set,type(pub_obj.book_set)) # 表名小写_set 关系管理对象
# print(pub_obj.book_set.all())
# 外键中 指定related_name='books' pub_obj.books 关系管理对象
# print(pub_obj.books,type(pub_obj.books)) # 表名小写_set 关系管理对象
2)基于字段的查询 外键名__name=’ ’ 跨表查询
查询人民出版社出版的所有书籍
ret = models.Book.objects.filter(publisher__name='人民出版社')
查询丰乳肥臀的出版社
不指定 related_name 跨表时使用 表名小写__字段
# ret = models.Publisher.objects.filter(book__title='丰乳肥臀')
# 指定 related_name='books' 跨表时使用books__字段
# ret = models.Publisher.objects.filter(books__title='丰乳肥臀')
# 指定 related_name='books' related_query_name='book' 跨表时使用book__字段
ret = models.Publisher.objects.filter(book__title='丰乳肥臀')
# print(ret)
print(pub_obj.books.all())
多对多
基于对象的查询
author_obj.books ——》 关系管理对象
author_obj.books.all() ——》 关系管理对象
不指定related_name
book_obj.author_set ——》 关系管理对象
book_obj.author_set.all() ——》 作者写过所有的书籍对象
指定related_name=’authors‘
book_obj.authors——》 关系管理对象
book_obj.authors.all() ——》 作者写过所有的书籍对象
管理对象的方法
all 获取所有的对象
set 设置关系 多对多 [ id,id ] [对象,对象] 一对多 [对象]
add 添加关系 多对多 id,id 对象,对象 一对多 对象
remove 删除关系 一对多:必须设置外键可为空,才有remove clear方法
clear 清空所有的关系
create 创建一个对象并且添加关系
`book_obj.authors.create(name='xxxx') `
pub_obj.books.set(models.Book.objects.filter(pk__in=[3])) # 设置关系 【对象 】
pub_obj.books.add(*models.Book.objects.filter(pk__in=[4])) # 添加关系 对象
pub_obj.books.remove(*models.Book.objects.filter(pk__in=[3])) # 删除关系 对象 外键 null=True
pub_obj.books.clear() # 删除关系 对象 外键 null=True
聚合 aggregate
所获取的是对象列表[{ },{ }]
例:
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "orm_practice.settings")
import django
django.setup()
from app01 import models
from django.db.models import Max, Min, Count, Avg, Sum
# 1 所有书的平均价格
# res = models.Book.objects.aggregate(Avg('price'))
# print(res)
# 2.上述方法一次性使用
res = models.Book.objects.aggregate(Max('price'), Min('price'), Sum('price'), Count('pk'), Avg('price'))
print(res)
分组 annotate
# 分组查询 annotate
"""
MySQL分组查询都有哪些特点
分组之后默认只能获取到分组的依据 组内其他字段都无法直接获取了
严格模式
ONLY_FULL_GROUP_BY
"""
from django.db.models import Max, Min, Sum, Count, Avg
# 1.统计每一个书的作者个数
# res = models.Book.objects.annotate() # models后面点什么 就是按什么分组
"""
author_num是自定义的字段 用来存储统计出来的每本书对应的作者个数
"""
# res = models.Book.objects.annotate(author_num=Count('authors')).values('title', 'author_num')
# print(res)
# 2.统计每个出版社卖的最便宜书的价格
# res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name','min_price')
# print(res)
# 3.统计不止一个作者的图书
# 1.先按照图书分组 求每一本书对应的作者个数
# 2.过滤出不只一个作者的图书
# res = models.Book.objects.annotate(author_num=Count('authors')).filter(author_num__gt=1).values('title', 'author_num')
"""
只要你的orm语句得出的结果还是一个queryset对象
那么就可以继续无限制的点queryset对象封装的方法
"""
# print(res)
# 4.查询每个作者出的书的总价格
# res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name','sum_price')
# print(res)
"""
如果按照指定的字段分组该如何处理呢
model.Book.objects.values('price').annotate()
如果出现分组查询报错的情况
需要修改数据库严格模式
"""
方式一:
ret = models.Publisher.objects.annotate(min=Min('book__price')).values()
方式二
ret = models.Book.objects.values('publisher__name').annotate(min=Min('price')) #对象列表{}
for i in ret:
print(i)
F和Q查询
from django.db.models import F, Q
F查询 比较两个字段
ret=models.Book.objects.filter(sale__gt=F('kucun')) update(sale=F(‘sale’)*2)
Q 查询 |或 ;& 与 ;~ 非
Filter(Q(pk_gt=5)) == Q((‘ss’,kk))
F查询
# 1.查询卖出数大于库存数的书籍
"""
能够帮助你直接获取表中某个字段对应的数据
"""
from django.db.models import F
# res = models.Book.objects.filter(maichu__gt=F('kuncun'))
# print(res)
# 2.将所有书籍的价格提升50元
# models.Book.objects.update(price=F('price') +500)
# 3.将所有书的名称后面加上爆款两个字
"""
在操作字符类型数据的时候 F不能够直接做到字符串的拼接
"""
from django.db.models.functions import Concat
from django.db.models import Value
models.Book.objects.update(title=Concat(F('title'),Value('爆款')))
# models.Book.objects.update(title=Concat(F('title')+'爆款') # 所有名称都会全部变成空白
Q查询
# 1.查询卖出数大于100或者价格小于600的书籍
# res = models.Book.objects.filter(maichu__gt=100,price__lt=600)
"""filter括号内多个参数是and关系"""
from django.db.models import Q
# res = models.Book.objects.filter(Q(maichu__gt=100),Q(price__lt=600)) # Q包裹逗号分割 还是and关系
# res = models.Book.objects.filter(Q(maichu__gt=100)|Q(price__lt=600)) # | or关系
# res = models.Book.objects.filter(~Q(maichu__gt=100)|Q(price__lt=600)) # ~ not关系
# print(res)
# Q的高阶用法 能够将查询条件的左边也变成字符串的形式
# q = Q()
# q.connector = 'or'
# q.children.append(('maichu__gt', 100))
# q.children.append(('price__lt', 600))
# res = models.Book.objects.filter(q) # 默认还是end关系
# print(res)
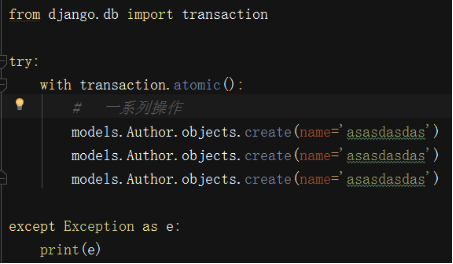
事务
"""
事务
ACID
原子性
不可分割的最小单位
一致性
跟原子性是相辅相成
隔离性
事物之间互相不干扰
持久性
事务一旦确认永久生效
事务的回滚
rollback
事务的确认
commit
"""
# 目前只需要掌握Django如何简单的开启事务
# 事务
from django.db import transaction
try:
with transaction.atomic():
# sql1
# sql2
# 在with代码块内书写的所有orm操作都是属于同一个事务
except Exception as e:
print(e)
print('执行其他操作')
only与defer , select_related与prefetch_related
"""
orm语句的特点:
惰性查询
如果仅仅只是书写了orm语句 在后面根本没有用到该语句查询出来的参数
那么orm会惰性识别
"""
# only与defer
# res = models.Book.objects.all()
# print(res) # 要用数据了才会走数据库
# 获取书籍表中所有书的名字
# res = models.Book.objects.values('title')
# for d in res:
# print(d.get('title'))
# 实现获取到的是一个数据对象 然后点title就能够拿到书名 并且没有其他字段
# res = models.Book.objects.only('title')
# res = models.Book.objects.all()
#QuerySet [<Book: 三国演义爆款>, <Book: 红楼梦爆款>, <Book: 论语爆款>, <Book: 聊斋爆款>, <Book: 老子爆款>]>
# print(res)
# for i in res:
# print(i.title) # 点击only括号内的字段 不会走数据库
# print(i.price) # 点击only括号内没有的字段 会重新走数据库查询而all不需要走
res = models.Book.objects.defer('title')
for i in res:
print(i.price)
# print(res)
"""
defer与only刚好相反
defer括号内放的字段不在查询出来的对象里面 查询该字段需要重新走数据
而如果查询的是非括号内的字段 则不需要走数据库
"""
# select_related与prefetch_related
# select_related与prefetch_related 跟跨表操作有关
# res = models.Book.objects.all()
# for i in res:
# print(i.publish.name) # 每循环一次就要走一次数据库查询
# res = models.Book.objects.select_related('publish') # INNER JOIN
"""
select_related内部直接先将book与publish连起来 然后一次性将大表里面的所有数据
全部封装给查询出来的对象
这个时候无论是点击book表的数据还是publish的数据都无需再走数据查询了
select_related括号内只能放外键字段 一对多 一对一
多对多不行
"""
# print(res)
# for i in res:
# print(i.publish.name)
res = models.Book.objects.prefetch_related('publish') # 子查询
"""
prefetch_related该方法内部其实就是子查询
将子查询出来的所有结果也给你封装到对象中
给你的感觉就是一次性完成的
"""
for i in res:
print(i.publish.name)
cookie
定义:cookie就是保存在浏览器本地的一组组键值对
特性:
- 服务器让浏览器进行设置的
- 保存在浏览器本地的,浏览器也可以不保存
- 下次访问时自动携带相应的cookie
为什么要有cookie?
HTTP协议是无状态的,每次请求都是没关系的,没办法保存,状态,使用cookie保存状态
django的操作:
-
设置 本质: 响应头 set-cookie
ret = redirect('/home/') #响应对象 ret.set_cookie('is_login', '1') # 普通的cookie max_age=5设置时间 path domain #ret.set_signed_cookie(key='is_login',value= '1', salt='day62') # 加密的cookie #参数: max_age=5设置时间, path='/', Cookie生效的路径,/ 表示根路径,特殊的:根路径的cookie可以被任何url的页面访问domain=None, Cookie生效的域名 -
获取 本质:请求头cookie
request.COOKIES[key] {} # 普通的cookie 或者 request.COOKIES.get(key) #request.get_signed_cookie('is_login',salt='day62',default='') # 加密的cookie -
删除
ret = redirect('/login/') ret.delete_cookie('is_login')
session
session 当做字典使用
定义: 保存在服务器上一组组键值对,必须依赖于cookie。
为什么要使用session?(特性)
- cookie保存在浏览器本地,不安全
- cookie的大小受到限制
django中操作session
-
设置
request.session[key] = value 或者 request.session.setdefault(key,value) -
获取
request.session[key] 或者 request.session.get(key) -
删除
del request.session['k1'] request.session.delete() # 删除所有的session数据 不删除cookie request.session.flush() # 删除所有的session数据 删除cookie request.session.exists("session_key") #检查会话session的key在数据库中是否存在
其他:
request.session.set_expiry(10) #设置超时时间,但是数据库的session不会删
通过request.session.clear_expired() # 清除已过期的数据
配置: 了解
from django.conf import global_settings
#数据库Session
SESSION_ENGINE = 'django.contrib.sessions.backends.db' # 引擎(默认)
#缓存Session
SESSION_ENGINE = 'django.contrib.sessions.backends.cache' # 引擎
#文件Session
SESSION_ENGINE = 'django.contrib.sessions.backends.file'
SESSION_COOKIE_AGE = 1209600 设置失效时间的
SESSION_COOKIE_PATH = "/" # Session的cookie保存的路径(默认)
SESSION_COOKIE_DOMAIN = None # Session的cookie保存的域名(默认)
SESSION_COOKIE_SECURE = False # 是否Https传输cookie(默认)
SESSION_COOKIE_HTTPONLY = True # 是否Session的cookie只支持http传输(默认)
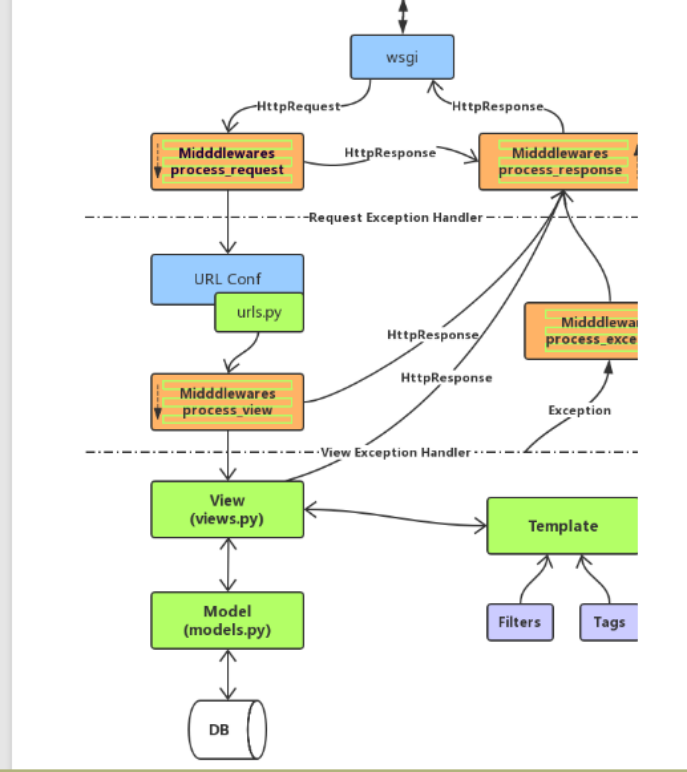
中间件
本质上就是python中的类
使用:
在app01下新建一个middlewares文件夹,在里面新建一个py文件
from django.utils.deprecation import MiddlewareMixin
在setting里添加配置
1)官方的说法:中间件是在全局范围内一个用来处理Django的请求和响应的框架级别的钩子
2) 五种方法:(执行时间、执行顺序、参数、返回值)
- process_request(self,request)
- process_view(self, request, view_func, view_args, view_kwargs)
- process_exception(self, request, exception)
- process_template_response(self,request,response)
- process_response(self, request, response)
process_request(self,request)
执行时间:
视图函数执行之前(请求到来后,路由匹配前)
执行顺序:
按照注册的顺序 顺序执行
参数:
request - 和视图中的request对象是同一个
返回值:
None: 正常流程
HttpResponse对象: 后面的中间件的process_request方法、视图都不执行,直接执行当前中间件的process_response方法,再返回给浏览器
process_response(self, request, response)
执行时间:
视图函数执行之后
执行顺序:
按照注册的顺序 倒序执行
参数:
request - 和视图中的request对象是同一个
response - 视图函数返回的响应对象
返回值:
HttpResponse对象: 必须返回
process_view(self, request, view_func, view_args, view_kwargs)
执行时间:
在process_request方法后,路由匹配之后,视图函数执行之前
执行顺序:
按照注册的顺序 顺序执行
参数:
request - 和视图中的request对象是同一个
view_func - 视图函数
view_args - 给视图使用的位置参数
view_kwargs - 给视图使用的关键字参数
返回值:
None: 正常流程
HttpResponse对象: 后面的中间件的process_view方法、视图都不执行,直接执行最后一个中间件的process_response方法,再返回给浏览器
process_exception(self, request, exception)
执行时间(触发的条件):
视图函数执行之后,视图有异常时才执行
执行顺序:
按照注册的顺序 倒序执行
参数:
request - 和视图中的request对象是同一个
exception - 错误的对象
返回值:
None: 正常流程 ,交给下一个中间件处理异常,都返回的是None,交给django处理异常(大黄页)
HttpResponse对象: 后面的中间件的process_exception方法不执行,直接执行最后一个中间件的process_response方法,再返回给浏览器
process_template_response(self,request,response)
执行时间(触发条件):
视图函数执行之后,要求视图函数返回的对象是TemplateResponse对象
执行顺序:
按照注册的顺序 倒序执行
参数:
request - 和视图中的request对象是同一个
response - 视图函数返回的响应对象
返回值:
HttpResponse对象: 必须返回
csrf相关的装饰器
csrf_exempt # 当前的视图不需要CSRF校验
csrf_protect # 当前的视图需要CSRF校验
from django.views.decorators.csrf import csrf_exempt, csrf_protect
from django.views.decorators.csrf import ensure_csrf_cookie
@ csrf_exempt
def login(request) 普通函数直接加
CBV中 csrf_exempt只能加在dispatch上或是类上
@method_decorator(csrf_exempt,name='dispatch')
csrf中间件步骤
- 请求到来时执行process_request方法:
从cookie中获取csrftoken的值 —— 》 赋值给 request.META['CSRF_COOKIE'] - 执行process_view方法:
- 查看视图是否加了csrf_exempt装饰器:
- 有 不需要csrf 校验 返回none
- 没有 需要csrf 校验
- 请求方式的判断:
- 如果是 'GET', 'HEAD', 'OPTIONS', 'TRACE' 不需要csrf 校验 返回none
- 其他方式需要csrf 校验
- 进行CSRF校验:
- 从request.META获取到csrftoken的值
- 尝试从表单中获取csrfmiddlewaretoken的值:
- 能获取到
csrfmiddlewaretoken的值和cookie中的csrftoken值做对比
1. 对比成功 通过csrf校验
2. 对比不成功 不通过csrf校验 拒绝请求 - 获取不到 尝试从请求头中获取x-csrftoken的值
x-csrftoken的值和cookie中的csrftoken值做对比- 对比成功 通过csrf校验
- 对比不成功 不通过csrf校验 拒绝请求
- 能获取到
- 查看视图是否加了csrf_exempt装饰器:
json 和XML对比
JSON 简单的语法格式和清晰的层次结构明显要比 XML 容易阅读,并且在数据交换方面,由于 JSON 所使用的字符要比 XML 少得多,可以大大得节约传输数据所占用得带宽。
ajax
(Asynchronous Javascript And XML)翻译成中文就是“异步的Javascript和XML”,
AJAX 不是新的编程语言,而是一种使用现有标准的新方法
定义: 是一个js的技术,发送请求的一种途径。
特点:
- 异步 2. 局部刷新 3. 传输的数据量小(xml json)
发请求的途径:
- 地址栏上输入地址 GET
- a标签 GET
- form表单 GET/POST
简单实例 固定格式
$.ajax({
url:'/calc/',
type:'post',
data:{
i1:$('[name="i1"]').val(),
i2:$('[name="i2"]').val(),
},
success:function (res) {
$('[name="i3"]').val(res)
}
})
参数
$.ajax({
url: '/ajax_test/', # 请求的地址
type: 'post', # 请求的方式
data: { # 请求的数据
name: 'alex',
age: 73,
hobby: JSON.stringify(['装逼', '作死', '卖烧饼']) #将对象转成字符串
},
success: function (res) { # 成功后执行的函数
location.href=地址 重定向 #返回时不要redirect了
},
error: function (res) { # 失败后执行的函数
console.log(res)
},
})
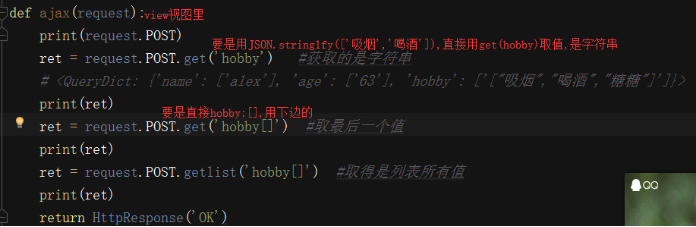
ret=json.loads(ret)
print(ret,type(ret)) #<class 'list'>
ajax上传文件
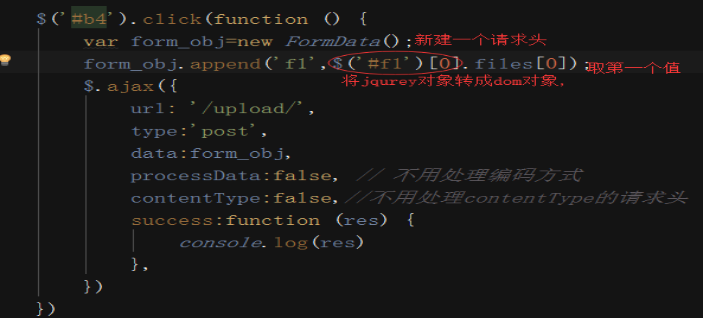

ajax通过django的csrf校验
-
确保csrftoken的cookie
- 一个加 {% csrf_tokne%}
- 给视图函数加装饰器
-
提供参数
- 给data添加数据
data: {
csrfmiddlewaretoken:隐藏标签或是cookie
csrfmiddlewaretoken: $('[name="csrfmiddlewaretoken"]').val(),
i1: $('[name="i1"]').val(),
i2: $('[name="i2"]').val(),
},
2. 加x-csrftoken的请求头
headers: {
'x-csrftoken': 隐藏标签或是cookie
'x-csrftoken': $('[name="csrfmiddlewaretoken"]').val(),
},
3.文件导入
<script src="/static/ajax_setup.js"></script> - 给data添加数据
总结:json
数据交换的格式
Python
数据类型: 数字 字符串 列表 字典 布尔值 None
转化:
序列化 Python的类型 ——》 json的字符串
json.dumps(Python的类型)
json.dump(Python的类型, f )
反序列化 json的字符串 ——》 Python的类型
json.loads( json的字符串)
json.load(f )
js
数据类型: 数字 字符串 列表 字典 布尔值 null
转化:
序列化 js的类型 ——》 json的字符串
JSON.stringify( js的类型 )
反序列化 json的字符串 ——》 JS的类型
JSON.parse( json的字符串 )
JsonResponse({}) # contentType :application/json
JsonResponse([],safe=False)
form组件 是一个类
from django import forms
class RegForm(forms.Form):
user = forms.CharField()
pwd = forms.CharField()
# gender=forms.CharField(widget=forms.Select(choices=((1,'男'),(2,'女')))) #单选下拉框
# gender=forms.CharField(widget=forms.SelectMultiple(choices=((1,'男'),(2,'女')))) #多选
# gender=forms.ChoiceField(choices=((1,'男'),(2,'女')),
widget=forms.widgets.RadioSelect() #单选radio
) #单选下拉框
gender=forms.MultipleChoiceField(choices=((1,'男'),(2,'女'))) #多选
使用: 在views
form_obj=ReForm() #实例化对象
form_obj = RegForm(request.POST) #把post提交过来的数据直接传进去
return render(request,'reg2.html',{'form_obj':form_obj })
模板 :
{{ form_obj.as_p }} ——》 生成p标签 label 和 input标签
{{ form_obj} input框
{{ form_obj.user }} ——》 字段对应的input标签
{{ form_obj.user.id_for_label }} ——》 input标签的ID
{{ form_obj.user.label }} ——》 字段对应的input标签的中文
{{ form_obj.user.errors }} ——》 当前字段的所有错误信息
{{ form_obj.user.errors.0 }} ——》 当前字段的第一个错误信息
{{ form_obj.non_field_errors.0 }} __all__的错误的显示
form组件的主要功能如下:
- 生成页面可用的HTML标签
- 对用户提交的数据进行校验
- 保留上次输入内容
form字段
CharField 文本
ChoiceField 选择框
MultipleChoiceField 多选框
字段参数
在form标签里写上novalidate ,就不提示错了(取消浏览器的提示错误)
widget=forms.PasswordInput #密码是密文 label=’中文’
required=True, 是否允许为空
widget=None, HTML插件
label=None, 用于生成Label标签或显示内容
initial=None, 初始值 (设置默认值)
error_messages=None, 错误信息 {'required': '不能为空', 'invalid': '格式错误'}
validators=[], 自定义验证规则
disabled=False, 是否可以编辑
is_valide()是否验证成功
关于choice的注意事项:
在使用选择标签时,需要注意choices的选项可以从数据库中获取,但是由于是静态字段 获取的值无法实时更新,那么需要自定义构造方法从而达到此目的。
方法一:在类里面定义一个__init取继承父类
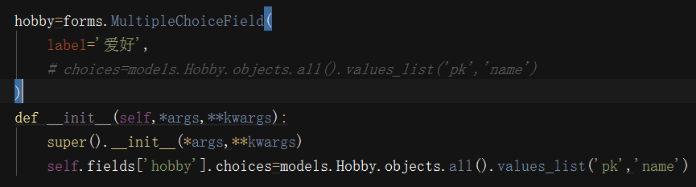
方法二:
from django.forms import models as form_model
hobby=form_model.ModelMultipleChoiceField(queryset=models.Hobby.objects.all())
校验
1). 内置校验
min_length=8,
max_length
required=True
2). 自定义校验
Validators=[check]
字段的参数
validators=[check,RegexValidator()],
1. 写函数
from django.core.exceptions import ValidationError
def check(value):
# 自定义校验规则
# 通过校验 不用返回
# 没有通过校验 抛出异常 raise ValidationError('有非法字符')
2. 内置的校验器
from django.core.validators import RegexValidator
phone = forms.CharField(
validators=[RegexValidator(r'^1[3-9]d{9}$', '手机号格式不正确')]
is_valid()的流程:
- 执行self.errors的方法 ——》 self.full_clean()
- full_clean方法():
- 定义一个存放错误信息的字典 self._errors = ErrorDict()
- 定义一个存放正确(经过校验)值 的字典 self.cleaned_data = {}
- 执行self._clean_fields():
- 依次循环所有的字段
- 执行内部的校验 和 自定义校验器的校验 value = field.clean(value)
- 将正确的值放在self.cleaned_data self.cleaned_data[name] = value
- 有局部钩子就执行
- 通过校验 self.cleaned_data[name] 重新赋值
- 不通过校验 self.cleaned_data[name] 当前字段的键值对被清除 self._errors中存放当前字段的错误信息
- 执行self._clean_form() ——》 self.clean()
- 如果有重新定义就执行
- 通过校验 返回所有的值 self.cleaned_data 重新赋值
- 不通过校验 把错误信息添加到 all 中
- 如果有重新定义就执行
局部钩子和全局钩子
from django.core.exceptions import ValidationError
def clean_user(self):
# 局部钩子
value = self.cleaned_data.get('user') # alex
# 通过校验规则 返回正确的值 (你可以修改)
return "{}dsb".format(value)
# 不通过校验规则 抛出异常
raise ValidationError('错误提示')
def clean(self):
# 全局钩子
# 通过校验规则 返回正确的值(所有的值 self.cleaned_data ) (你可以修改)
# 不通过校验规则 抛出异常
pwd = self.cleaned_data.get('pwd')
re_pwd = self.cleaned_data.get('re_pwd')
if pwd == re_pwd:
return self.cleaned_data
raise ValidationError('两次密码不一致')
modelform组件
'oncontextmenu':"return false"是不让你右键点击
from django import forms
from django.core.exceptions import ValidationError
class RegForm(forms.ModelForm):
password = forms.CharField(min_length=6, widget=forms.PasswordInput(attrs={'placeholder': '您的密码'}))
re_password = forms.CharField(min_length=6, widget=forms.PasswordInput(attrs={'placeholder': '确认您的密码'}))
class Meta:
model = models.UserProfile
fields = '__all__' # ['字段名']
exclude = ['is_active']
widgets = {
'username': forms.TextInput(attrs={'placeholder': '您的用户名'}),
'password': forms.PasswordInput(attrs={'placeholder': 'xxxxx'}),
'name': forms.TextInput(attrs={'placeholder': '您的真实姓名'}),
'mobile': forms.TextInput(attrs={'placeholder': '您的手机号'}),
}
error_messages = {
'username': {'invalid': '请输入正确的邮箱地址'}
}
def clean(self):
# 获取到两次密码
password = self.cleaned_data.get('password')
re_password = self.cleaned_data.get('re_password')
if password == re_password:
# 加密后返回
md5 = hashlib.md5()
md5.update(password.encode('utf-8'))
password = md5.hexdigest()
self.cleaned_data['password'] = password
# 返回所有数据
return self.cleaned_data
# 抛出异常
self.add_error('re_password', '两次密码不一致!!')
raise ValidationError('两次密码不一致')
字段的展示:
1. 普通字段
{{ 对象.字段名 }}
2. choice参数
对象.字段名 ——》 数据库的值
对象.get_字段名_display() ——》显示 中文
{{ 对象.get_字段名_display }} 放在前端不加括号
外键字段 对象(__str__)
3. 自定义方法 models里
def show_classes(self):
return ' | '.join([str(i) for i in self.class_list.all()])
{{ 对象.show_classes }}
safe
不需要转义 和safe一样
在后端用mark_safe 在前端用safe
from django.utils.safestring import mark_safe
mark_safe(<span style="background-color: {};color: white;padding: 4px">{}</span>)
编辑时, instance=obj : 把原始数据放到这里,给页面展示
Request.POST:获取提交的值

Git
https://gitee.com/
1.配置:
Git config –global user.email ‘qi@live.com’
Git config –global user.name ‘qi’
Git init :先创建个空库
git status: 查看状态
git add . :添加
git add 文件
get --version : 查看版本
git commit –m’添加注册和登录功能’ :提交到本地
Git log :查看版本信息
git reset :是回滚到commit之前,(还可以重新修改,在提交)
git reset –hard ‘版本号’ :回到最原始的位置
Git reflog :查看版本号 在会滚回来还是git reset –hard ‘版本号’
Git clone 远程仓库地址
给远程仓库起别名:Git remote add origin 远程仓库地址
Git stash :保存
Git stash list : 查看“某个地方”存储的所有记录
Git stash clear : 清空某个地方
Git stash drop :编号 ,删除指定编号的记录
git push origin master:最后提交到服务器码云
git pull origin master :拉代码,从远程拉到本地
==>
Git fetch origin master : 去仓库 获取
+
git merge origin/master-和网上下的master分支合并
git show <commit-hashId> 便可以显示某次提交的修改内容
同样 git show <commit-hashId> filename 可以显示某次提交的某个内容的修改信息。
如何把分支A 上某个commit应用到分支b上:git cherry-pick <commit id>
2.rebase变基
使git记录简洁(除了第1条后边的全整合在一起),多个记录 ——》1个记录
用法:git rebase 分支
1)Rebase第一种:
第一步:Git rebase -i HEAD~3
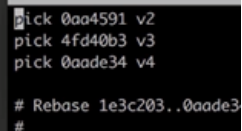
第二步:把第二,三行pick 变成s, s代表把当前版本合并到上一个版本,最终v3,v4都合并到v2中了

第三步:
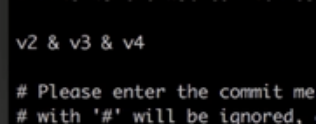
HEAD~3:合并前3条
注:合并记录时不要把已提交(push)到仓库的代码合并,容易起冲突
2)rebase第二种:
- 第一步:git branch dev touch dev1.py git add git commit
- 第二步:git checkout master touch master1.py git add git commit
- 第三步:git checkout dev git rebase master(在dev上合并master)
- 第四步:git checkout master git merge dev(切换到master,再合并dev)
Git log --graph --pretty=format:”%h %s” 结果就是一条简单的直线
3)Rebase第三种:
git pull origin master (有分叉)
==》
Git fetch origin dev
+
Git rebase origin master/dev
3.记录图形展示
Git log --graph
git log --graph --pretty=format:"%h %s"
4.merge 和 rebase命令的区别
Merge一次性展示所有冲突,rebase每次展示一次commit提交的冲突
Merge保留完整的历史记录,rebase会重写历史记录
5. git rebase 产生冲突
方法一:git add 文件名
Git rebase --continue
方法二:
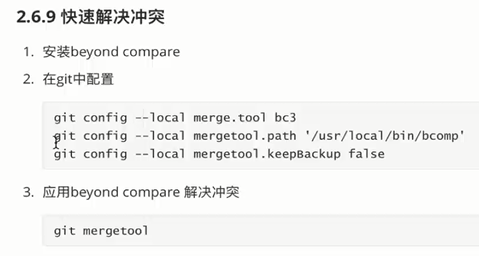
分支
git branch 查看
git branch dev 新建dev分支
git branch -d dev 删除dev分支
git checkout dev 切换到dev分支
git merge dev 从dev合并到当前分支(有冲突 手动解决),在commit一下
Git clone http:xxx :克隆
git checkout -b dev :创建并切换到分支
注:先切换分支在合并,切换到merge,再把dev合并到merge
**单人开发 **
新建一个dev分支 开发新功能
开发完成 合并到master分支
有bug 新建debug分组
到debug分支上修改bug
修改完成 合并到master分支 并且删除debug分支
多人协作开发
远程仓库中每人有自己的分支
在本地开发 开发完成后提交到自己的分支
提交pull requests 合并到dev分支上
Github (仓库,小公司,网站):花钱放到别人的仓库
Gitlab (工具,大公司,开源软件)是一个用于仓库管理系统的开源项目,使用Git作为代码管理工 具:自己公司搭建一个属于自己的仓库,自己买服务器,自己有管理员,页避免代码泄露
gitignore的作用:
配置 git 需要忽略的文件或文件夹,在 .gitignore 文件配置的文件或文件夹不会随着 git 提交到你的仓库
修改 git 历史提交 commit 信息(重写历史)
https://www.jianshu.com/p/0f1fbd50b4be
git 已经提交了,如何去修改以前的提交信息
解决方法
修改最新的 log
如果只修改最新一条提交信息的 log 内容,直接使用命令 git commit --amend 就可以
修改历史的 log
假设提交记录如下:
$ git log
commit 9ac1179332670365a3e5ea00a6486998eb66db7a (HEAD -> fix_aop_no_class_defined, origin/fix_aop_no_class_defined)
Author: candyleer <295198088@qq.com>
Date: Mon Apr 16 19:58:23 2018 +0800
update test case
Signed-off-by: candyleer <295198088@qq.com>
commit 223fc80d17273b19238dcb648e6d6eefc579de0f
Author: candyleer <295198088@qq.com>
Date: Mon Apr 16 18:47:50 2018 +0800
unit test case
Signed-off-by: candyleer <295198088@qq.com>
commit 2275781a0d75add037721832bd68c1a8edb3813e
Author: candyleer <295198088@qq.com>
Date: Mon Apr 16 18:29:29 2018 +0800
should find method from parent
-
执行 git 命令, 修改近三次的信息
$ git rebase -i HEAD~3
将会得到提交日志是和git log倒叙排列的,我们要修改的日志信息位于第一位.
1 pick 2275781 should find method from parent
2 pick 223fc80 unit test case
3 pick 9ac1179 update test case
4
5 # Rebase 79db0bd..9ac1179 onto 79db0bd (3 commands)
6 #
7 # Commands:
8 # p, pick = use commit
9 # r, reword = use commit, but edit the commit message
2.我们现在要修改修改要should find method from parent这条日志,那么修改的日志为,将第一个pick 修改为edit, 然后 :wq 退出.
1 edit 2275781 should find method from parent
2 pick 223fc80 unit test case
3 pick 9ac1179 update test case
将会看到如下信息,意思就是如果要改日志,执行git commit --amend,如果修改完成后,执行git rebase --continue
client_java git:(fix_aop_no_class_defined) git rebase -i HEAD~3
Stopped at 2275781... should find method from parent
You can amend the commit now, with
git commit --amend
Once you are satisfied with your changes, run
git rebase --continue
➜ client_java git:(2275781)
3.正式修改,执行命令,-s 就是自动加上Signed-off-by:
$ git commit --amend -s
client_java git:(63b2cfd) git commit --amend -s
[detached HEAD c46b30e] 1should find method from parent
Date: Mon Apr 16 18:29:29 2018 +0800
1 file changed, 4 insertions(+), 1 deletion(-
修改完成后,:wq 退出,然后完成此次 log 的rebase
$ git rebase --continue
client_java git:(c46b30e) git rebase --continue
Successfully rebased and updated refs/heads/fix_aop_no_class_defined.
4.这样本地修改就完成啦,用git log 再看下:
commit 449efc747ffb85567667745b978ed7e3418cfe27 (HEAD -> fix_aop_no_class_defined)
Author: candyleer <295198088@qq.com>
Date: Mon Apr 16 19:58:23 2018 +0800
update test case
Signed-off-by: candyleer <295198088@qq.com>
commit 69237c0bd48439ea0d8b87bf2c7c7ac4786c66d4
Author: candyleer <295198088@qq.com>
Date: Mon Apr 16 18:47:50 2018 +0800
unit test case
Signed-off-by: candyleer <295198088@qq.com>
commit c46b30e456af6ecdf4a629a485e5efe5485e52b1
Author: candyleer <295198088@qq.com>
Date: Mon Apr 16 18:29:29 2018 +0800
1should find method from parent
Signed-off-by: candyleer <295198088@qq.com>
所有信息都有Signed-off-by:这个参数了
5。最后push 到远程仓库,所有的 DCO 就都可以加上啦,-f强制推送
git push origin <you_branch_name> -f