一、STL 概述
1.1 C++标准库
高级程序设计语言希望尽可能减少程序员的重复工作,因此提供了各种抽象机制降低程序复杂性。在程序设计实践中积累了许多经验和代码,充分利用这些经验和代码是降低程序复杂性的有效途径。程序设计语言必须提供代码重用的机制。一般而言有源代码级别的重用和二进制代码级别的重用两种机制,源代码级别的重用非常简单,只需要将源代码一起编译即可。但是许多时候源代码丢失或者厂商不愿意公开源代码,只有二进制代码可用,此时程许多程序设计语言提供了标准库和相应的库管序设计语言应该提供重用二进制代码的机制。
理机制,通过标准库用户可以使用常用的算法和数据结构,通过库管理机制用户可以使用第三方的库,从而扩充标准库。现代编程语言倾向于将程序设计语言理解为程序设计环境。除了核心的语言成分外,还包括编程实践中经常用到的算法和数据结构,作为核心语言的支持。例如 Java 规范中就明确提到语言提供的标准库 java.lang.*将自动加载,C 语言规范中对标准库也有相应的定义。
Pascal 因为没有定义标准库和提供库管理机制被许多 C 程序员诟病。C++在许多方面类似 C,例如采用 C 中的虚拟机观点,具有指针,类型结构的内存布局于 C 相同,但是 C++在更多的方面与 C 不同。C++中引入了更高级的面向对象抽象机制,提供了构造大型程序的名空间机制,具有比 C 复杂的类型机制,具有编译时模板机制,具有更多的运行时机制。因此需要设计体现 C++特色的标准库。
C++的特色在于提供灵活的机制,执行效率高。标准库作为语言的支持成分,需要大量的重复使用,因此 C++标准库应该体现效率。这也是 C 标准库的特征之一。其次 C++提供了高级抽象机制,因此标准库应该通用。通用意味着标准库对用户定义的类型有良好的支持。
C++中引入面向对象机制,强调信息封装,用户定义类型千变万化,因此标准库应当具有操作任意类型的能力。同时对这些用户定义类型不能有任何假定,否则不方便用户使用标准库。最后标准库的组织应该结构化,包含程序设计中最有用最核心的工具。C++标准库有如下设计目标:结构化良好、完整全面、包含最有用的程序组件;程序组件在理论上尽可能抽象,但是执行效率尽可能接近手工编写的 C 代码。
1.2 标准模板库 STL
STL 是 Standard Template Library 的简称。STL 不仅是可重用的组件库,而且是一个包括算法与数据结构的软件体系结构。STL 整体设计庞大、稳定、完整且可扩展、注重效率,体现了泛型编程的精髓。
STL 中广泛使用模板技术获取通用性,模板技术的本质是参数化的类型声明和使用。C++提供的模板机制体现了 C++的许多考虑:注重效率,记法简洁。
STL 中广泛使用模板和重载技术,采用泛型编程技术,STL 中的算法和数据结构的效率有着严格的保证,采用算法分析中的渐进复杂度表示。使得标准库非常通用。早期的 STL实现由 Stepanov 和 Austern 完成。
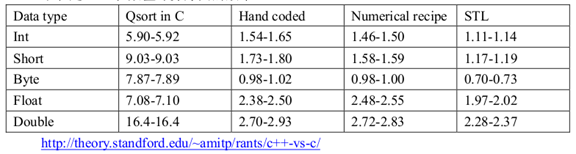
下表是 STL 在数值计算方面的效率。
库是一系列程序组件的集合,它们可以在不同的程序中重复使用。库函数遵照以下的规则:接受一些符合预先指定类型的参数,返回一个特定类型的值或改变一些已有的值。设计一个能被广泛使用的 C 或 C++库的一个重要组成部分就是,猜测出这些函数中最有可能出现的参数组合情况。
设计一个能被广泛使用的 C++库的另一个重要组成部分就是猜测类中最有可能出现的成员对象类型的组合情况。
通用容器的需求程序员不希望重复设计链表、队列、树这些常用的数据结构,但是 C 不提供抽象操作类型的机制。因此 C 程序员利用宏和其它编程技巧实现了通用的链表操作,下面是从 Linux
下 gcc 源代码中摘录的关于通用链表操作的实现。
* List declarations.
*/
#define LIST_HEAD(name, type)\
struct name { \
struct type *lh_first;
/* first element */\
}
#define LIST_HEAD_INITIALIZER(head)\
{ NULL }
#define LIST_ENTRY(type) \
struct { \
struct type *le_next;
/* next element */\
struct type **le_prev;
/* address of previous next element */\
}
/*
* List functions.
*/
#define LIST_EMPTY(head) ((head)->lh_first == NULL)
#define LIST_FIRST(head) ((head)->lh_first)
#define LIST_FOREACH(var, head, field)\
for ((var) = LIST_FIRST((head));\
(var);\
(var) = LIST_NEXT((var), field))
#define LIST_INIT(head) do {\
LIST_FIRST((head)) = NULL;\
} while (0)
#define LIST_INSERT_AFTER(listelm, elm, field) do { \
if ((LIST_NEXT((elm), field) = LIST_NEXT((listelm), field)) \
LIST_NEXT((listelm), field)->field.le_prev = \
&LIST_NEXT((elm), field); \
LIST_NEXT((listelm), field) = (elm);\
(elm)->field.le_prev = &LIST_NEXT((listelm), field); \
} while (0)
#define LIST_INSERT_BEFORE(listelm, elm, field) do {\
(elm)->field.le_prev = (listelm)->field.le_prev;\
LIST_NEXT((elm), field) = (listelm);\
*(listelm)->field.le_prev = (elm);\
(listelm)->field.le_prev = &LIST_NEXT((elm), field);\
} while (0)
#define LIST_INSERT_HEAD(head, elm, field) do {\
if ((LIST_NEXT((elm), field) = LIST_FIRST((head))) != NULL) \
LIST_FIRST((head))->field.le_prev = &LIST_NEXT((elm), field);\
LIST_FIRST((head)) = (elm);\
(elm)->field.le_prev = &LIST_FIRST((head));\
} while (0)
#define LIST_NEXT(elm, field) ((elm)->field.le_next)
#define LIST_REMOVE(elm, field) do {\
if (LIST_NEXT((elm), field) != NULL)\
LIST_NEXT((elm), field)->field.le_prev =\
(elm)->field.le_prev;\
*(elm)->field.le_prev = LIST_NEXT((elm), field);\
} while (0)
该代码的主要意图是定义一个链表结构,该结构可以内嵌到用户定义的类型中,通过链表结构实现链表操作。从代码可以看出这样的实现很难读懂;采用宏实现无法进行类型检查,加大了调试难度;使用不自然,容易出错。象上面 C 中的链表操作要求用户定义的类型中嵌入链表结构,这违反了信息封装的原则,同时使用不方便,因此程序员希望 C++能提供自然、通用的容器,这些容器能容纳用户定义的类型,并提供各种操作,而不需要强制用户定义的类型具有某种结构。例如向量、链表、队列都属于容器。这些容器提供的操作不依赖于容器包含的类型。
通用算法的需求
好的算法是一笔重要的财富,许多算法其实对参数只有很少的要求。程序员希望能够重用这些算法。不同算法对参数有不同的要求,C++标准库必须对用户类型进行抽象,得出算法所需的最低要求。
迭代器的需求
Pascal 语言的设计者 N. Wirth 提出过一个著名的公式:算法+数据结构=程序。数据结构即通用容器,算法还需要操作这些通用容器,但是如何操纵这些容器呢?迭代器提供了一种简洁的记法解决这些问题。迭代器扩展了指针的概念,使得存取容器变得异常容易,同时迭代器也具有非常好的可扩展性。
与迭代器相关的是如何表示迭代器界定的元素集合,为此引入区间概念。区间是指元素集合,其中的元素具有"第一"和"最后"的概念,每个元素(除了最后一个元素)都有后继,只要以"一个接一个"的方式,便能遍历整个集合,取得从头至尾的所有元素。
函数对象的需求
C 中提供了函数指针,但是函数指针不适合在 C++中工作,因为函数指针不能很好的与C++的其它语言成分结合在一起,例如函数指针无法重载,函数指针无法建立模板,函数指针没有作用域规则。因此 C++扩展了函数指针的概念提供了函数对象。其实函数对象就是提供了 operator ()重载的对象,但是经过这样处理之后将函数指针具有的功能与 C++中其它的语言成分完全结合在一起,获得比函数指针更强大的能力。
模板的需求
模板概念根植于对描述参数化容器类的愿望,扩展静态类型检查所能处理的问题。C++中的解决方法之一是采用宏机制,但是宏机制有许多缺点:根本不遵守作用域规则和类型规则,不能与其它语言特性友好相处(构造函数和析构函数)。从前面的代码也可看出宏机制不自然、难于理解,不适合构造大型程序。因此必须采用新的机制使得记法方便、运行效率高、类型安全。
通用容器类的特点是对不同类型的容器元素,操作也不同。例如通用链表操作加入要取表头的元素,如果是 int 型链表那么该操作返回 int 值,如果是 double 型链表,同样的操作要返回 double 值。也就是说通用容器类能够被参数化。C++是静态编译型语言,要想对实现参数化的类,必须在编译时完成。同时 C++也很强调类型匹配,因此参数化类型必须经过静态类型检查。参数化类型不能对参数有任何假定,因此必须与语言其它特性友好相处。C++中的模板基于源代码正文,占用的是编译时间。原因是希望能有宏机制的效率。
模板与其它语言成分的关系
模板概念是 C++中非常有效的概念,原因在于模板可以与其它语言成分协同工作,而宏机制却不行。例如模板函数和模板类可以向普通函数和类一样,用在同样的上下文中,模板类中也可以定义虚函数,类声明中也可以定义模板成员函数,以至于模板类可以继承,模板函数可以重载。
总之,模板概念已经完全与其它语言成分融合在一起,构成 C++语言强大的语言特性之一。模板的威力在于把握了约束的时机,首先将模板作为预处理的文本,然后将约束检查推迟到使用模板的时候,兼顾了效率和代码尺寸。
1.3 C++语言机制概述
正是 C++语言提供的机制使得 STL 取得了成功。STL 中用到的 C++语言特性主要有模板和函数重载。
1.3.1 模板机制
声明模板时 C++设计者希望函数的参数传递机制也能适合模板参数传递,这也体现 C++的风格,尽可能将机制贯彻到底,减少程序员的学习成本。因此模板参数传递具有 C++中函数传参的特性,如缺省参数值、模板类重载、模板参数的类型推导等等。
模板参数的限制
模板参数没有任何限制,在这一点上模板与宏机制完全一样。没有对模板参数进行限制使得模板可以提供像宏机制一样的灵活性,避免增加编译器的负担。实现时完全可以将模板当作预处理,编译器的其它部分不用改变。不限制模板参数使得所有的类型检查推迟到模板使用时,因此可能出现莫名其妙的出错信息。
如果限制模板参数,那么模板在很大程度上称为语言的内部机制,与宏机制有很大差别,一方面增加了编译器的复杂度,很难实现,不利于模板的使用。另一方面使得针对模板的调试会带来很大的方便。
模板参数检查只能放到模板实例化时进行,因为只有在实例化时模板才接受已经定义好的类型。这样做有一个缺点,如果一个模板没有被实例化,那么模板中的错误将无法检测。有时候关于模板的出错信息表现为链接错误,这样的错误会使用户感到迷惑。解决方法是构造更强大的编译器。
限制模板参数的一种方法是采用继承描述模板参数。这种方式也不尽人意。因为许多时候继承并不能完全描述类型之间的关系。例如 int 和 complex 都属于数值类型,但这两种类型并没有继承关系,但一般的数值计算函数都接受这两种类型作为参数。还有导致过度使用继承同时引入一些垃圾代码,如引入一个完全抽象的基类,然后增加基类的限制。
比较上面两种看法可以看出不限制模板参数更有利。因此从工程实际的角度看,增强编译器对模板出错信息的诊断是当务之急。
引入非类型参数的必要
引入非类型参数的最主要目的是代替数组,提供具有安全检查的替代品。
例如如下代码
T v[i];
int sz;
public:
Buffer():sz(i) {}
int size() {return sz;}
//...
}
可以提供类似于 Java 数组 length()的功能。采用这种做法可以减少数组越界的情况。
参数类型匹配
所有的参数检查都在实例化模板时完成。
作用域
C++支持分别编译,因此需要仔细考察引入模板后对分别编译产生的影响。
传统上 C++采用.cpp 文件和.hpp 文件作为源文件。其中.hpp 是接口部分,.cpp 是实现部分。模板定义无论放入接口部分还是放入实现部分,都会出现问题。模板放入接口部分将导致编译单位将包含所有的模板定义,会导致编译性能下降。模板放入实现部分将涉及如何找到模板定义,实现起来特别复杂,因为编译单元需要保存模板定义。解决方法是构造功能更强的编译器,该编译器能够记录已经遇到的模板定义,以及模板的出处。并将这些信息记录目标文件中,在模板实例化时查找这些相应的符号表。有了更强的编译器之后,模板作为语言成分可以纳入到已有的作用域规则之中。
避免代码膨胀
使用模板的一个代价是实例化模板时总要重新生成类声明,如果程序中多处使用模板将会生成非常多的冗余代码,从而增加编译时间和占用内存。实际上可以避免重复生成代码,注意到类模板和函数模板的声明由类型参数唯一确定,实际类型参数相同的模板实例实际上可以共享同一份类定义。
实例化
- 显式实例化
显式实例化非常有必要。因为 C++只在实例化时才真正展开模板同时进行类型检查,但此时有关模板的错误往往表现为链接错误。因此需要提供一种机制使程序员能够强制编译器生成模板实例,并进行类型检查,这相当于使模板的类型检查提前到编译时刻,因此出错信息表现为编译错误,有利于调试。显示实例化可能使得分别编译时产生冗余代码。
- 模板特殊化
模板对任意模板参数都描述了一个函数或者类的定义。但是出于效率考虑,有许多特殊情况可以单独设计。简单例子是一般类都有构造函数和析构函数,但是 C++的基本类型并不需要这些函数,因此对于做内存管理的模板而言,初始化这样的类型可以直接操作内存而不必遵循对一般类的操作流程。
因为模板参数类型可能匹配一般模板也可能匹配特殊模板,因此需要定义规则使编译器能够知道使用哪个模板定义。
对此 C++采用使用之前先声明的方法,如果在作用域中声明了特殊化,则使用特殊化模板,否则使用一般化模板。
注重效率:减少编译时间(实例化时机和实例化动作),减少运行时间(模板特殊化)
指向类模板成员函数的指针
显然 C++在设计时也考虑到这些问题,因此提供了相应的机制,如 C++标准中定义了指向类成员函数的指针。另一方面利用 typedef 可以简化和包装类型定义,C++标准允许在typedef 使用模板声明。有了以上的语言特性,加上 traits 技术,即可实现指向类模板成员函数的指针。示意代码如下:
class A
{
public:
T f(T t){return t;} //定义模板类的成员函数
};
template <typename T>
struct A_traits
{
typedef T (A<T>::*f_ptr)(T); //定义指向 A 类的成员函数的指针类型
};
int main(void)
{
A<int> a;
A_traits<int>::f_ptr fp;
fp = &A<int>::f; //指向具体对象的成员函数
(a.*fp)(3); //调用该成员函数
}
代码在 g++ 2.4.3 Linux 平台下编译通过。
1.3.2 函数重载
函数重载是 C++中的另一种抽象机制,也是基于类型的程序设计的重要手段。函数重载是指在作用域中具有相同名字的函数,这些函数的参数类型或参数个数不同,因而被认为不同的函数,当发生函数调用是编译器根据实参个数和类型匹配相应的函数。
函数重载使得程序员将概念上相似的操作抽象为一个函数名,减少了程序员的概念复杂性,例如加法操作可以用于实数、复数和向量,程序员只需面对抽象的加法操作,而由编译器选择相应类型的法操作。
函数重载的关键之处在于参数匹配。当发生函数调用时,编译器如何找到对应的重载函数呢?这依赖与以下规则:精确匹配和类型转换匹配。精确匹配指实参类型与某个重载函数的形参精确匹配,当然这个重载函数就是所要的函数。类型转换匹配是指实参类型经过某种转换后可与形参精确匹配。
参数匹配规则
实际上参数类型匹配非常复杂,因为往往出现这样的情况,对于一个重载函数这些实参需要转换匹配,对于另一个重载函数那些函数需要转换匹配,如何决定应该选择哪个重载函数呢?而且存在许多转换,如提升、标准转换和用户定义的转换,如何界定这些转换的合适程度呢?C++认为可能出现多个重载函数匹配一个函数调用,因此需要按照某种规则给这些候选函数评分,选出一个最优匹配的函数,如果存在多个最优,则认为出错。
- 精确匹配
C++语言中存在一些最小转换,如数组可以看作指针从语言的内部表示上来看没有任何区别,两者都表现为内存地址;引用可以作为值,比如表达式中可以用普通变量也可以用引用变量,从语言实现上看没有任何区别,因为两者都需要从内存中取值。总结起来 C++中的最小转换如下:左值到右值的转换,数组到指针的转换,函数到指针的转换,限定修饰符转换。符合这些转换也可以认为是精确匹配。
- 提升
C++语言中也存在其它的转换,逻辑表示相同但是表示内部表示长度不同的类型需要转换,但这种转换不会损失细节,因而称为提升。一般而言有相应的机器指令可以完成这样的转换。 x86 体系结构下有扩展指令将 8 位数据扩展为 32 位数据。如例如字符型转换为整型,计算机内部表示相同只是占用内存长度不同。单精度转换为双精度,根据 IEEE 浮点数规范可知这两种类型的逻辑表示完全相同,只是某些域的位数不同,因此表示数的范围和精度不同。总结起来提升有以下几种:char、short 转换为 int,float 提升为 double,枚举类型提升第一个为能表达枚举常量的类型(int 或 long),布尔型提升为整型。
- 标准转换
C++中的标准转换指类型的逻辑表示不同,因此需要编译器调用标准例程进行转换,可能会损失细节。显然这种操作需要更多的指令才能完成。例如整数转换为浮点数,一般机器下提供的指令是将普通寄存器中的二进制为复制到浮点寄存器中,因此要将整数转换为浮点数,必须按照浮点数的格式在普通寄存器中完成装配,然后送入浮点寄存器中进行运算。其次标准转换会损失细节,如浮点转换为整数。需要特别注意的是指针类型之间的转换属于标准转换,尽管语言内部的指针表示为 32 位地址值,但是指针具有特殊的语义,指针的语义与所指向的类型密切相关。例如指向 int 型的指针与指向 struct 的指针就完全不同,因为在解引用时 int 指针与 struct 指针读取的内存大小就完全不同。标准转换有:整值类型转换,浮点转换,浮点——整值转换,指针转换,bool 转换。
- 用户定义转换
C++中还允许用户定义类型转换。例如拷贝构造函数和赋值操作符重载就可以认为是用户定义的类型转换,因为从语义上而言,这些函数确实将一种类型转换为另一种类型,当然采用的不是标准的 C++语法。从 C++语言参数传递也可看出,实参传递时编译器会试图调用拷贝构造函数初始化形参。
最佳函数
类型转换从按照评分高低排序如下:精确匹配,提升,标准转换,用户定义转换。可能有多个函数符合要求,因此需要选出最佳的函数,C++语言采用如下条件选择最佳函数:实参转换不比其它可行函数的转换更差,在某些实参上的转换比其它函数更好。也就是说最佳可行函数在每个实参转换上都是最好的。可以看出,采用这样定义的最佳函数是唯一的。当然也可能出现不存在最佳可行函数的情况,这时编译器将报错。
1.3.3 名字空间
随着程序设计实践的发展,程序规模越来越大,传统的模块化语言在大型系统面前已经显得力不从心。例如 C 语言其实只有很简单的模块支持,以源文件为编译单位,名字解析只有两层结构,在大型程序中很容易出现名字冲突,因此程序员不得不在函数名和变量名之前添加各种前缀以示区分,使得程序很难读,增加了程序员的概念复杂性。Java 语言增加了对模块的支持,增加了包管理机制,使得模块管理非常方便。实际上面向对象语言一般用于构造大型程序,因此必须设计灵活有效的模块支持,语言才能得到广泛应用。C++增加了名字空间作为语言的基本成分,对模块名字封装提供了支持。名字解析呈现出层次结构,利于程序的分别开发,程序员也不必绞尽脑汁的避免名字冲突,因此可以为函数或变量取更贴切的名字,从而有利于维护和调试。
现在的 C++名字空间不是特别完善,首先名字空间作为作用域的一种没有访问权限的控制。如果能提供访问控制,则可以对模块进行更细粒度的组织,有利于信息隐藏和封装。
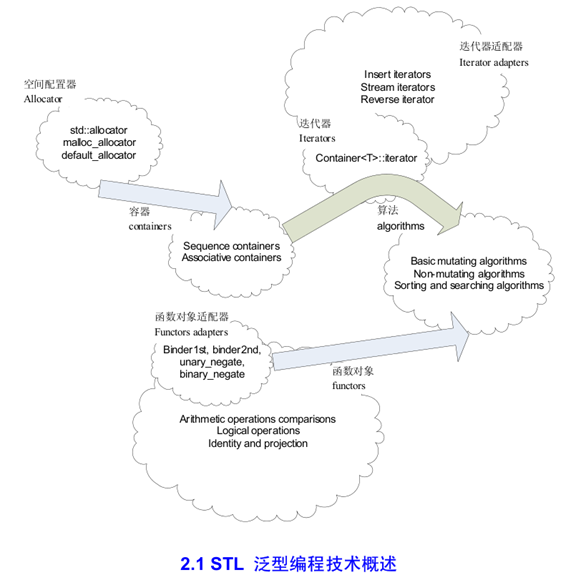
二、STL 的体系结构
STL 分为概念性结构和实体结构。STL 的概念性结构是整个 STL 的设计哲学,其核心部分是泛型编程和 concept。STL 的实体结构是实现这些概念性结构的程序实体,包括算法和数据结构,如 vector,list 等等。
STL 的体系结构如下图所示:
泛型编程产生的背景
N. Wirth 曾经提出"算法+数据结构=程序",长期的程序设计实践也产生了许多优秀的算法和数据结构。例如,快速排序算法只要求数组元素可以比较大小即可完成排序工作,二叉排序树也只要求树节点可以比较大小,即可完成二叉树的各种操作。也就是说,算法和数据结构与类型无关,或者说能适用于任何类型。除了计算机科学中存在泛型对象之外,数学中也广泛存在这样的对象,例如,求最大公因数的 Euclid 算法,最开始用于整数,其实只要是组成环的代数结构,都可以用 Euclid算法求最大公因数。
STL 的创始人 Stepanov 曾经谈到他曾经意识到累加操作的正确性只依赖于操作对象满足加法结合律。进一步算法和数据结构也不是对所有的类型都适用,类型必须满足某些性质。
另一方面,现有的库缺乏对泛型编程的支持,程序员往往发现即使有库可以提供常用的数据结构,还是不得不重新的设计它们,因为库提供的这些数据结构不能直接用于他们的任务,尽管只需要对这些数据结构做很小的改动。
还有,用于列表的算法尽管在形式上与用于树的算法非常相似,但二者不能互操作。也就是说,没有提供一种统一的数据结构访问机制,使得算法可以作用于不同的数据结构。这些程序设计实践都要求泛型编程的出现。
从上面的讨论可以看出,算法和数据结构是泛型对象,对这些泛型对象的细化和设计就构成了泛型程序设计的主要内容。
类型抽象在泛型编程中的体现
Concept 是泛型编程中对类型的一种抽象。可以认为 Concept 就是类型需要满足的性质。可以定义一组抽象概念(concepts),只要类型满足某组条件,我们就说此类型符合这个concept。这些 concepts 非常重要,因为算法假定参数 "符合某些 concpets"或者认为"不同 concepts 之间存在某种关系"。此外,这些 concepts 形成明确定义的体系结构是 STL 的概念性结构,也是 STL 最重要的部分。由于 concept,使得可以编写通用的代码。
实际上,早在 70 年代 Stepanov 就利用 Ada 和 Scheme 进行泛型编程的实践。但是 Ada不能很好的支持泛型编程,例如没有模板机制,而 Scheme 不能提供足够的效率。直到 C++产生之后,泛型编程才获得了生命力。可以说泛型编程和 C++是相互促进的,泛型编程对C++的最大贡献是 STL,C++也为泛型编程思想的提供了优秀的实践平台,C++为了更好的支持泛型编程还准备增加一些语言特性。
泛型编程和效率
泛型编程非常关注效率。Stepanov 曾经说道:"我开始考虑有关泛型编程的问题是在 70年代末期,当时我注意到有些算法并不依赖于数据结构的特定实现,而只是依赖于该结构的几个基本的语义属性。
于是我开始研究大量不同的算法,结果发现大部分算法可以用这种方法从特定实现中抽象出来,而且效率无损。对我来说,效率是至关重要的,要是一种算法抽象在实例化会导致性能的下降,那可不够棒。"C++采用 C 语言的机器模型,具有非常高的效率。因此泛型编程希望尽可能少使用 C++的动态特性,尽量在编译时完成,而不留在运行时。C++提供的与类型相关的机制有继承、模板、重载。只有模板和重载在编译时完成,继承的许多特性将涉及运行时机制。因此 STL中大量使用模板和重载。
除此之外,STL 中广泛使用模板特殊化,为的是对不同类型进一步优化。将具体算法设计得尽可能通用,但是不损失效率。如果算法不能覆盖所有情况,那么增加更通用得形式,同时保证使用时自动选择最有效的形式。
泛型编程与 STL
STL 泛型编程在 C++中的具体实践。泛型编程中对类型的抽象表现为 STL 中的 concept,算法和数据结构互操作在 STL 中体现为容器、迭代器和仿函数,对效率的关注体现为 STLtraits 技术。
泛型编程与面向对象编程
泛型编程从本质上说与面向对象编程完全不同。面向对象编程关注领域本身,而泛型编程关注算法和数据结构。关注点的不同使得两者用途完全不同,面向对象用于构造大型的应用系统,而泛型编程用于构造大型的库。因为泛型编程关注的算法和数据结构不是大型应用关注的重点,大型应用系统的重点是业务分析,不涉及复杂的算法和数据结构,而库属于语言的支持,需要提供程序员常见编程问题的解决方案,因此需要关注算法和数据结构。
其次,面向对象方法已经渗透到整个系统的分析和设计中,应用非常广泛,而泛型编程还不是一种系统设计方法学,没有形成完整的方法论,只局限在程序设计的底层部分。
2.2 STL Concept 概述
STL 的概念性结构的基础是 concept,STL 的创始人 Stepanov 曾经谈起 concept 起源于对代数性质的认识,可以认为 concept 是类型的代数性质,或者是类型需要满足的条件。concept 是一组类型要求;concept 是类型集合,通常的集合都有元素应该满足的条件;concept是一组合法程序,描述了这些程序可以用于哪些类型,例如,从 C++程序文本可以看出类型是否具有某些运算符操作,是否有缺省构造函数等等。常用有效表达式来描述 concept。说明类型具有哪些语义操作。concept 是一种更高级的抽象。concept 之间存在一种强化关系(refinement)。
基本 concept
STL 中的基本 concept 有 Assignable,允许对类型赋值。Default Constructible 允许定义临时变量。Equality Comparable 允许相等比较。Less Than Comparable 允许小于或等于比较。
Strict Weakly Comparable 类型具有全序关系。
Iterators concept 迭代器概念
迭代器概念根据迭代器遍历数据结构的方式分为 Trivial Iterator、Input Iterator、OutputIterator、Forward Iterator、Bidirectional Iterator 和 Random Access Iterator。Input Iterator 只能读取迭代器的值,只有一种遍历方式;Output Iterator 只能写迭代器的值,只有一种遍历方式、Forward Iterator 可以复制迭代器,遍历不会改变以前的迭代器所处的位置;Bidirectional Iterator 可以双向遍历;Random Access Iterator 可以采用数组的访问方
式引用迭代器。
函数对象概念
函数对象根据参数个数分为 Generator 不带参数,Unary Function 一个参数,Binary Function 两个参数。因为 STL 的通用算法经常需要条件判断,为此 STL 将返回值为 bool 类型的函数对象作为 Predicate(谓词概念)。Predicate 一个参数的谓词,Binary Predicate 为两个参数的谓词。为了产生随机数和散列,STL 还定义了两种特殊的函数对象概念:Random Number Generator 和 Hash Function,分别用于产生随机数和用作散列函数。这两个概念具有与其它函数对象概念不同的要求:
Random Number Generator 要求返回值是均匀分布的整数,Hash Function 概念要求返回值只与参数有关,传递同样的参数将返回同样的结果。
容器概念
- 基本容器概念
Forward Container,元素有明确的次序,迭代过程不会改变次序。Reversible Container,可以双向遍历整个容器。Random Access Container,可以按照数组的方式访问容器内的元素
- 序列概念
Sequence 大小可变的容器,元素在容器中的位置可以相互比较大小。Associative Container按照键值访问元素的容器,元素的位置没有大小关系。一般而言对容器要求具有恒等性质,
即放入容器中的对象与原对象是相等的。如果从更细节的角度说,容器中的对象与原对象在内存中的内容应该完全一样。
分配器概念
Allocater 用来封装内存管理的细节。
concept 存在的问题
没有提供 concept 支持的语言,也没有对 concept 统一的描述,因此针对 concept 的编程实践无法深入。C++没有提供任何机制支持概念抽象。因此无法在 STL 上实践 concept,无法在实际编程中利用 concept。而且 STL 中的概念无法获得检查,程序员安全有可能传递编写违反概念要求的容器,同时提供相同的接口。当前的 concept 完全是一种概念需求,用户无法声明一个符合某个概念的类型,概念之间的关系也无法体现,没有提供概念的静态或者动态检查。
2.3 STL Iterator 概述
泛型编程中的算法追求通用性,因此算法应该对多种数据结构有效。例如,对数据的累加作为算法,不仅对数组元素能够累加,对采用二叉树表示的元素也能够累加。因此必须提供一种通用的形式使得算法能够访问数据结构,这种形式应该简单有效。为此 STL 提出迭代器概念,直观上,迭代器提供一种遍历数据结构的方式,STL 的迭代器明显带有 C++的痕迹。
迭代器是一种抽象的设计概念,迭代器提供了一种方法,是之能够依序巡访某个容器所含的各个元素,而无需暴露该聚合物的内部表达式。STL 的中心思想在于:将数据结构和算法分开,彼此独立设计,最后以迭代器将它们结合在一起。迭代器是一种行为类似指针的对象,而指针的各种行为中最常见也最重要的便是解引用和成员访问,因此,迭代器最重要的编程工作就是对 operator*和 operator->进行重载。容器与迭代器密切相关,为此每一种 STL容器都提供有专属迭代器。
与其它语言如 Clu 或 Icon 的迭代器相比,C++STL 的迭代器有其特点和不足。C++语言强调静态类型检查,更重要的是 C++完全继承了 C 语言对具体机器的抽象,即 C++中的抽象计算机与 C 语言的抽象计算机完全相同。但是在诸如 Clu 和 Icon 这样的语言里,对机器的抽象与 C++有很大差异,例如 C++语言中的控制语句完全是面向过程的,可以直接对应到机器代码,而 Clu 或 Icon 中的语句则是描述性的,需要编译器回溯搜索。因此性能不能得到保证,因为回溯搜索的性能与采用的回溯策略以及搜索目标在搜索空间的位置密切相关。
迭代器的另一个重要作用就是遍历数据结构,当然不同的数据结构提供了不同的遍历方法,例如 vector 的使用非常类似与数组,而数组是可以随机访问的,因此可以访问前后的第n 个元素,而单向链表只能访问其后的元素。将迭代器分类使得针对不同迭代器算法可以单独优化,例如排序算法对单向链表迭代器和数组迭代器就可以分别采用插入排序和快速排序,从而提高效率。因此迭代器有不同种类,每一类满足不同的语义性质,为此 STL 将迭代器分为如下几类:输入迭代器(Input Iterator) , 输出迭代器(Output Iterator) 前向迭代器(Forward Iterator)双向迭代器(Bidirectoional erator)
,随机访问迭代器(Random Access Iterator)。这些迭代器之间存在一种强化关系(refinement)。关系如下图:
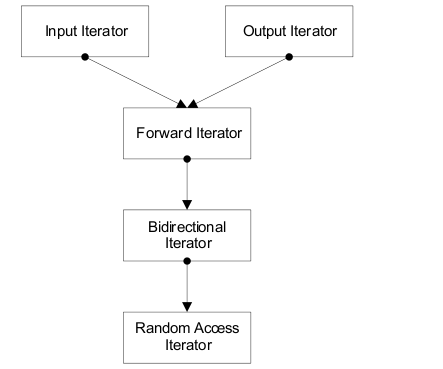
可以用代数结构中的群、环、域之间的关系类比强化关系。
不同类的迭代器定义了不同的遍历方法,但对外提供了统一接口,即重载运算符 operator++和 operator --,这两个运算符是基本的遍历方法。例如 Input Iterator 和 Output Iterator 只有operator ++, Forward Iterator 还有 operator +=,而进一步 Bidirectional Iterator 还有 operator --,Random Access Operator 还有 opeator []。
2.4 STL Traits 技术概述
在设计 Iterator 的时候,往往需要使用容器内的用户类型,尽管有时候可以使用参数推导机制,但是因为 C++参数推导并不完善,许多时候无法由参数推导获得所需类型。为此将一系列的相关类型集中在一起,作为 Traits。例如 Iterator 的 Traits 依赖与容器元素的类型。例如,常用的相关类型有 Value Type 容器内元素的类型,Difference Type 迭代器之间的距离,对于文件这个距离可能非常大,Reference Type 容器内元素的引用类型,Pointer Type容器元素的指针类型,可以看到,相关类型全部都依赖于容器内元素的类型,因此 traits 也可以认为是一种类型表达式。实际实现时,容器中利用模板参数和 typedef 定义这些相关类型,迭代器利用容器的相关类型重新定义自己的相关类型即可。
2.5 SGI STL Type Traits 技术概述
SGI STL 是 STL 的实现版本之一,也是流行最广的实现之一。SGI STL 在实现是有不少创新。Type Traits 就是其中之一,Type Traits 将 traits 技术用于类型,提取类型的相关特性。
type traits 的设计目的
希望优化不同的类型的复制操作,提高效率。__type_traits 负责提取类型的特征。所关注的类型特征为:类型是否有 non-trivial default ctor?是否具备 non-trivial copy ctor?是否具备 non-trivial assignment operator?是否具备 non-trivial dtor?如果不是,针对这些类型的构造、析构、拷贝、赋值等操作就可以采用直接内存操作,从而提高效率。
__type_traits 提供了一种机制,允许针对不同的类型属性,在编译时期完成函数分派。其实质就是函数重载。
type traits 的实现
注意的是函数分派在编译时完成,如何表示这些特征呢?显然不能采用 bool 类型,因为编译时只能识别类型,而不能识别类型具有的值。
受到的启发是能否定义两种特殊的类型,一种类型代表真,另一种类型代表假呢?根据函数重载的规定,类型不同将代表不同的函数,因此可以分派到不同的函数中。
首先定义最一般的__type_traits,对所有类型都有效,其次针对不同的具体类型(例如,预定义类型)定义特殊的__type_traits。某些编译器会自动为所有类型提供适当的特殊版本(标量类型(scalar):一般而言对 struct/union 可以直接操作内存,其次没有定义构造函数,以及构造函数为空的类型都可以直接操作内存),可以根据类声明判断类是否具有默认构造函数,是否具有简单的内存结构,即对象拷贝等价于内存拷贝。
2.6 STL 实体体系结构
2.6.1 容器
- 序列式容器
vector 容器是数组的抽象。维护连续的线性空间,提供随机访问迭代器。但是 vector 可以动态增长,。插入删除操作后原来的迭代器失效。list 容器在 STL 中是环形双向链表。提供双向迭代器。插入删除后原来的迭代器仍然有效。deque 是双向开口的连续空间。可以在两端插入和删除。但是 deque 与 vector 有巨大差异:首先 deque 允许常数时间内对两端进行插入删除操作;其次 deque 没有容量概念,deque动态地以分段连续空间组合而成,随时可以增加一段新的空间并链接起来。 vector 在原有而空间不足时需要申请新的空间然后将旧空间中的元素复制到新空间。deque 采用一块映象区map 控制存储缓冲区节点,缓冲区是一段连续线性空间,是 deque 的存储主体。
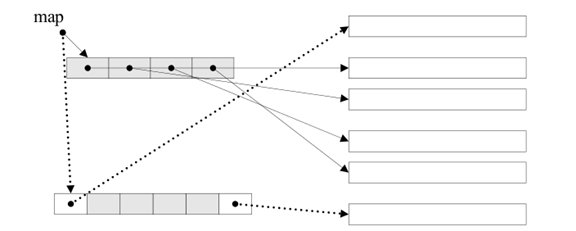
stack 是先进后出的 FILO 结构,stack 在 STL 中并没有特殊实现,只是 deque 的简单包装。
queue 是先进先出的 FIFO 结构,是 deque 的简单包装。
priority_queue 是一个优先队列,其内的元素依照权值排列。priority_queue 完全以底部容器为根据,加上堆的处理规则,因此 priority_queue 也称为适配器。
slist 是单向链表,与 list 相比具有占用内存少,操作快的优点。
- 关联式容器
RB-tree 红黑树是二叉平衡搜索树的一种。RB-tree 的迭代器属于双向迭代器,前进和后退的方向就是元素按照大小排列的方向。复杂度插入删除查找的复杂度均为 O ( log n ) 。
set 与数学中的集合定义相同。在实现上以 RB-tree 为基础,set 迭代器是只读迭代器。
map 拥有键值(key)和实值(value),依据键值自动排序。不允许两个元素拥有相同的键值。以 RB-tree 为实现基础。
mutltiset 和 multimap 与 set 和 map 相同,区别在于允许键值相同。
hashtable 开链方式的散列表,表格重建(当链中的节点超过表格大小时重建整个表格)。
迭代器(在链中前进或后退,如果到达链的结尾则指向下一个非空链的开头)。
2.6.2 通用算法
- 非变易性算法
for_each 提供对于容器内每个元素进行循环操作
find 线性查找
find_fist_of 对于给定值的集合,在容器内线性查找
adjacent_find 线性查找邻近且相等的元素对
count 计算给定值的出现次数
mismatch 比较两个序列,找出第一个不相同元素的位置
equal 两个序列的判等操作,逐一比较元素是否相等
search 在一个序列中查找与另一个序列匹配的子序列
search_n 在序列中查找一系列符合给定值的元素
find_end 在一个序列中查找最后一个与另一个序列匹配的子序列
- 变易性算法
copy 复制元素到另外一个序列
swap 两个容器元素交换
transform 序列中的元素都用这个元素变换后的值代替
replace 替换给定值的元素
fill 填充给定值的元素
generate 用某函数的返回值来代替序列中的所有元素
remove 删除序列中等于某一给定之的所有元素
unique 删除所有连续相等的元素
reverse 将元素之间的位置关系取逆
rotate 循环移动序列中的元素
random_shuffle 随机排列元素
partition 按某一顺序重新排列元素
- 有序队列算法
sort,stable_sort,partial_sort 对元素排序
nth_element 查找第 n 个大的元素
binary_search lower_bound upper_bound equal_range 用二分查找搜索有序队列
merge 归并两个有序队列
includes set_union set_intersection set_difference set_sysmetric_difference 集合运算
push_heap pop_heap make_heap sort_heap 堆操作
min max min_element max_element 求最大、最小元素
lexicographical_compare 字典序比较
next_permutation prev_permutation 依据字典序生成排列
- 通用数字算法
accumulate 累加
inner_product 内积
partial_sum 累加部分元素
adjacent_difference 计算相邻元素的差,保存在另一个序列中迭代器、区间(数组范围)、迭代器特征
函数对象
函数对象将函数封装在对象内,通过重载运算符 operator()实现。函数对象与函数指针差别在于:
- 编译时将函数对象传递给算法
- 通过内联相应的调用提高效率
- 本地封装函数对象所用信息。指针传递函数需要使用静态或全局数据
函数适配器:接收函数对象,生成另一个函数对象。主要有 4 类:绑定器:将参数绑定到特殊值,从而将二元函数对象变为一元函数对象。否定器:逆转谓词函数对象的含义;函数指针适配器:允许函数指针(一元或二元)与库提供的函数适配器一起工作;成员函数指针适配器:允许成员函数指针(一元或二元,包括隐含的 this 指针)与库提供的函数适配器一起工作。
三、STL 存在的问题
代码膨胀
C++分别编译过程中以及模板重复实例化引起的代码膨胀有时可能非常惊人。一方面消耗大量的编译时间,另一方面执行时代码过大引起多次的磁盘操作,影响执行速度。
异常完全和出错信息问题
STL 不象 Java 定义了完整的异常。实际上 STL 只有为数不多的几种异常类型。许多时候导致程序员调试工作大大增加。
模板机制套用宏机制,因此只有在真正编译链接时才能看到模板引起的错误消息,这些消息数目巨大,而且表现为编译错误和链接错误,程序员无法找到错误的真正所在。因此设计更加强大的编译器,使得模板称为语言内部机制,而不是象宏机制一样的预处理机制,从长远看这是很有必要的,另一方面丰富语言调试机制,使得 STL 可以定制错误消息,或者专门设计 STL 相关的出错信息。
模块机制
C++在许多特性方面毫无必要的与 C 兼容,象模块机制,C++也简单采用 C 的头文件机制,头文件机制已经很不适应现代程序设计的需要,C++应该提供一套更加完善的模块机制。
编译模式过于复杂,尤其是针对模板的分离编译模式,概念不够统一清晰,仍然保留 C的分别编译模式和头文件包含,很容易产生名字冲突,尤其时头文件的重复包含及其繁琐,应该由编译器自动解决。
符号重载与代数性质不全等的问题
如全序,代数意义与运算符重载下的意义不完全一致,可能潜藏问题。另外 C++并没有方便形式化方法的机制,因此无法验证类型是否符合其声称的代数性质。实际上在 C++中根本不适合采用形式化方法来检验程序。
函数对象与函数式语言中的函数的差别
C++非常关注效率,因此尽管有许多呼声要求在 C++中增加一些函数式程序设计语言的成分,Stroutrup 还是放弃了这些高阶语言成分。作为 C++语言的核心可以控制高阶成分的引入,但是没有理由禁止在库级别引入高阶成分。虽然函数对象开始进入 STL 中,但是距离真正的高阶函数还是有不少距离。函数对象只是重载括号运算符,不能像函数式语言那样将函数作为操作对象,不能实现函数式语言的程序设计方法。因此在 STL 中引入高阶成分的途径之一是在库级别引入一些特性,使得可以采用函数式语言程序设计风格来设计程序。
C++对泛型编程的支持不够
只有早期绑定,没有后期绑定,实际上 C++没有给程序员选择;不能很好的支持 concept,即无法形式化的支持接口,没有指向 concpet 的指针,无法检查 concept;因为模板实现采用预处理方式,因此 C++对模板采用延迟实例化方式,只有使用时才实例化模板,同时对模板进行静态检查,如果模板没有被实例化,其中语法错误可能隐藏很久。
STL 实现中的大量冗余拷贝
STL 在实现时参数传递等许多地方出现冗余拷贝。整个 STL 还需仔细设计,尤其是 STL的内存管理部分,设计好的话可以在一定程度上采用引用语义。如果只采用采用值语义,实际编程中会产生大量的中间复制操作。
宏机制和内联函数
C++并不能保证内联函数一定展开,许多时候,尤其是编写系统软件,需要强制某个函数展开。其次宏机制效率高,而 C++的虚函数因为需要查找虚表,效率上有损失,MFC 的消息映射就采用宏机制而避免采用虚函数。实际上用宏机制也有许多好的程序设计方法,仅用内联函数是无法代替宏机制的,有没有一种机制能吸收两者的优点,同时摒弃其缺点呢?