1. Redis基本介绍
1.1 传统数据存储出现的问题
- 海量用户
- 高并发
罪魁祸首——关系型数据库:
- 性能瓶颈:磁盘IO性能低下
- 扩展瓶颈:数据关系复杂,扩展性差,不便于大规模集群
解决思路
- 降低磁盘IO次数,越低越好 —— 内存存储
- 去除数据间的关系,越简单越好 —— 不存储关系,仅存储数据
1.2 NoSql简介
也就是可以使用 NoSql 解决,即Not-OnlySQL(泛指非关系型的数据库),作为关系型数据库的补充。
常见Nosql数据库:
- Redis
- memcache
- HBase
- MongoDB
特征:
- 可扩容,可伸缩
- 大数据量下得高性能
- 灵活得数据模型,
- 高可用
1.3 Redis简介
概念:
Redis(REmote DIctinary Server)是用C语言开发的一个开源的高性能键值对(key-value)数据库
特征:
- 数据间没有必然的关联关系
- 内部采用单线程机制进行工作
- 高性能。官方提供测试数据,50个并发执行100000个请求,读的速度是110000次/s,写的速度是81000次/s。
- 多数据类型支持:string(字符串类型)、list(列表类型)、hash(散列类型)、set(集合类型)、sorted_set(有序集合类型)
- 持久化支持。可以进行数据灾难恢复
应用场景:
- 为热点数据加速查询(主要场景)、如热点商品、热点新闻、热点资讯、推广类等提高访问量信息等。
- 任务队列、如秒杀、抢购、购票等
- 即时信息查询,如各位排行榜、各类网站访问统计、公交到站信息、在线人数信息(聊天室、网站)、设备信号等
- 时效性信息控制,如验证码控制,投票控制等
- 分布式数据共享,如分布式集群构架中的session分离
- 消息队列
- 分布式锁
2. 五种常用数据类型
redis 自身可以看做是一个 Map,其中所有的数据都是采用 key : value 的形式存储
数据类型指的是存储的数据的类型,也就是 value 部分的类型,key 部分永远都是字符串
2.1 String 字符串类型
- 存储的数据:单个数据,最简单的数据存储类型,也是最常用的数据存储类型
- 存储数据的格式:一个存储空间保存一个数据
- 存储内容:通常使用字符串,如果字符串以整数的形式展示,可以作为数字操作使用
String 类型数据的基本操作
-
添加/修改数据:
set key value -
获取数据:
get key -
删除数据:
del key -
添加/修改多个数据:
mset key1 valueq key2 value2 … -
获取多个数据:
mget key1 key2 … -
获取数据字符个数(字符串长度):
strlen key -
追加信息到原始信息后部(如果原始信息存在就追加,否则新建):
append key value
上面的mset和 mget 中的m 指的是 Multiple, 代表此操作为事务性操作,后面详细说
String类型数据的扩展操作
业务场景1
大型企业级应用中,分表操作是基本操作,使用多张表存储同类型数据,但是对应的主键id必须保证统一性,不能重复。Oracle数据库具有sequence设定,可以解决该问题,但是MySQL数据库并不具有类似的机制,那么就不能使用自增的方式用作主键了,如何解决?
相关指令:
-
设置数值数据增加指定范围的值
incr key // 指定的key的值自增1 incrby key increment //指定的key的值自增指定的 increment 值,可以是负数 incrbyfloat key increment //可以加一个小数,上面两个不行 -
设置数值数据减少指定范围的值
decr key //自减1 decrby key increment //自减指定的值
redis用于控制数据库表主键id,为数据库表主键提供生成策略,保障数据库表的主键唯一性
此方案适用于所有数据库,且支持数据库集群
注意事项:
- string在redis内部存储默认就是一个字符串,当遇到增减类操作incr,decr时会转成数值型进行计算。
- redis所有的操作都是原子性的,采用单线程处理所有业务,命令是一个一个执行的,因此无需考虑并发 带来的数据影响。
- 注意:按数值进行操作的数据,如果原始数据不能转成数值,或超越了redis 数值上限范围,将报错。 9223372036854775807(java中long型数据最大值,Long.MAX_VALUE)
业务场景2:
- 启动海选投票,只能通过微信投票,每个微信号每 4 小时只能投1票。
- 电商商家开启热门商品推荐,热门商品不能一直处于热门期,每种商品热门期维持3天,3天后自动取消热门。
- 新闻网站会出现热点新闻,热点新闻最大的特征是时效性,如何自动控制热点新闻的时效性。
相关指令:
设置数据具有指定的生命周期
setex key seconds value // 设置key-value 存活指定时间单位秒
psetex key milliseconds value //单位毫秒
redis 控制数据的生命周期,通过数据是否失效控制业务行为,适用于所有具有时效性限定控制的操作
string 类型数据操作的注意事项
指令返回的值的含义:
- 数据操作不成功的反馈与数据正常操作之间的差异 (根据不同的指令类型有所区分,例如返回1到底是操作成功还是运行结果值)
- 表示运行结果是否成功
- (integer) 0 代表 false 失败
- (integer) 1 代表 true 成功
- 表示运行结果值
- (integer) 3 代表 3个
- (integer) 1 代表 1个
- 表示运行结果是否成功
- 数据未获取到
- (nil)等同于null
单个value数据最大值:512M
**数值计算最大范围(java中的long的最大值):9223372036854775807 **
常用的存储方式
- 例如: 在redis中为大V用户设定用户信息粉丝数和博文数,以用户主键和属性值作为key,后台设定定时刷新策略即可
eg: user:id:3506728370:fans → 12210947
eg: user:id:3506728370:blogs → 6164
eg: user:id:3506728370:focuss → 83
-
例如: 在redis中以json格式存储大V用户信息,定时刷新(也可以使用hash类型)
eg: user:id:3506728370 → {"id":3506728370,"name":"春晚","fans":12210862,"blogs":6164, "focus":83} -
关系型数据库中的热点数据key命名惯例
// 表名:主键名:主键值:字段名
order:id:3954561:name
2.2 hash 类型
现存问题:
对象类数据的存储如果具有较频繁的更新需求操作会显得笨重 (需要存多个key代表一个对象或者存一个json),比较臃肿
hash 类型 介绍
- 新的存储需求:对一系列存储的数据进行编组,方便管理,典型应用存储对象信息
- 需要的存储结构:一个存储空间保存多个键值对数据
- hash类型:底层使用哈希表结构实现数据存储
示意图:
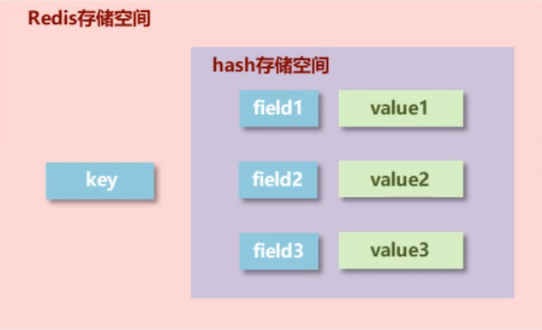
hash存储结构优化
- 如果field数量较少,存储结构优化为类数组结构
- 如果field数量较多,存储结构使用HashMap结构
hash 类型数据的基本操作
-
添加/修改数据
hset key field value // 在指定的key中设置一个hash结构的值 键为field 值为 value -
获取数据
hget key field //获取指定field hgetall key //获取全部 -
删除数据
hdel key field1 [field2] -
添加/修改多个数据
hmset key field1 value1 field2 value2 … -
获取多个数据
hmget key field1 field2 … -
获取哈希表中字段的数量
hlen key -
获取哈希表中是否存在指定的字段
hexists key field
hash 类型数据扩展操作
-
获取哈希表中所有的字段名和字段值
hkeys key //获取本hash中所有的key hvals key //获取所有的value -
设置指定字段的数值数据增加指定范围的值
hincrby key field increment // 指定某个hash中的某个字段对应的值增加 指定的值 hincrbyfloat key field increment //增加的值可以是小数
hash 类型数据操作的注意事项
- hash类型下的value只能存储字符串,不允许存储其他数据类型,不存在嵌套现象。如果数据未获取到, 对应的值为(nil)
- 每个 hash 可以存储 2^32 - 1 个键值对
- hash类型十分贴近对象的数据存储形式,并且可以灵活添加删除对象属性。但hash设计初衷不是为了存 储大量对象而设计的,切记不可滥用,更不可以将hash作为对象列表使用
- hgetall 操作可以获取全部属性,如果内部field过多,遍历整体数据效率就很会低,有可能成为数据访问瓶颈
hash 类型应用场景
场景一:
电商网站购物车设计与实现
业务分析:
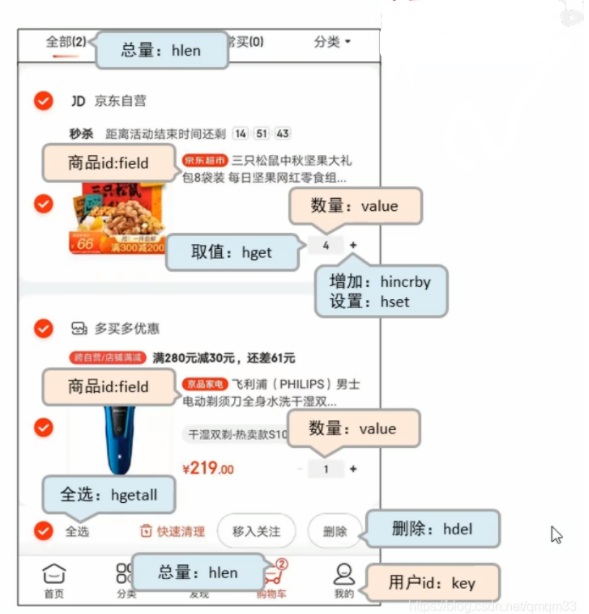
根据上图:
- 以客户id作为key,每位客户创建一个hash存储结构存储对应的购物车信息
- 将商品编号作为field,购买数量作为value进行存储
- 添加商品:追加全新的field与value
- 浏览:遍历hash
- 更改数量:自增/自减,设置value值
- 删除商品:删除field
- 清空:删除key
所以在不考虑购物车与数据库间持久化同步、购物车与订单间关系、未登录用户购物车信息存储等 其他情况时, redis中的hash结构就可以满足我们的需求
思考:
当前设计是否加速了购物车的呈现 ?
当前仅仅是将数据存储到了redis中,并没有起到加速的作用,商品信息还需要二次查询数据库 ,因为只是存了数量,商品的信息还是没有储存
优化方式1:
每条购物车中的商品记录保存成两条field
- field1专用于保存购买数量
命名格式:商品id:nums
保存数据:数值
- field2专用于保存购物车中显示的信息,包含文字描述,图片地址,所属商家信息等
命名格式:商品id:info
保存数据:json
但是这种方式,每个商品的信息, 在不同的用户购物车中,都需要保存,数据极度冗余,所以可以将商品的信息单独保存在一个hash中
优化方式2:
商品信息单独存放, 需要的时候直接拿取,
但是此时有个问题,若每个用户添加商品进入购物车时,对应的都要将商品信息添加一遍,若商品hash中已经存在此商品信息,操作将多余
可以使用如下命令:
hsetnx key field value // 存值时判断是否已经存在此field,若存在则不set
场景二:
双11活动日,销售手机充值卡的商家对移动、联通、电信的30元、50元、100元商品推出抢购活动,每种商 品抢购上限1000张
解决方案
- 以商家id作为key
- 将参与抢购的商品id作为field
- 将参与抢购的商品数量作为对应的value
- 抢购时使用降值的方式控制产品数量
redis 应用于抢购,限购类、限量发放优惠卷、激活码等业务的数据存储设计
2.3 list类型
基本介绍
数据存储需求:存储多个数据,并对数据进入存储空间的顺序进行区分
需要的存储结构:一个存储空间保存多个数据,且通过数据可以体现进入顺序
list类型:保存多个数据,底层使用双向链表存储结构实现
示意图:

list 类型数据基本操作
-
添加/修改数据
// 创建和添加是同一个 命令 lpush key value1 [value2] …… //向链表的左边添加一个元素,可以是多个 rpush key value1 [value2] …… // 从右边添加 -
获取数据
lrange key start stop // 从左边依次取出元素, start stop 是开始结束索引,并且两边包含 lindex key index // 从左边取出指定索引的元素 llen key //list长度 -
获取并移除数据
lpop key //从list左边拿出一个元素
rpop key //从右边拿
-
规定时间内获取并移除数据 (b代表block 阻塞的意思)
blpop key1 [key2] timeout // 从指定的若干个list中获取左边的值,若没有获取到,则等待指定的时间,(秒),一旦获取到一个 就返回结束 brpop key1 [key2] timeout //从右边 brpoplpush source destination timeout //从指定的source list中右边拿出一个数据 放到destination list中右边, 获取不到则阻塞等待
业务场景
场景1: 微信朋友圈点赞,要求按照点赞顺序显示点赞好友信息 如果取消点赞,移除对应好友信息
此时若点赞人是在中间,这是如果需要删除记录,则需要删除中间的元素,如何操作
移除指定数据
lrem key count value //从左边删除 指定的元素值 value, 并且指定删除的个数 count, 因为list中的元素是可以重复的
redis 应用于具有操作先后顺序的数据控制
其他场景:
- twitter、新浪微博、腾讯微博中个人用户的关注列表需要按照用户的关注顺序进行展示,粉丝列表需要将最 近关注的粉丝列在前面
- 新闻、资讯类网站如何将最新的新闻或资讯按照发生的时间顺序展示?
- 企业运营过程中,系统将产生出大量的运营数据,保障多台服务器操作日志的统一顺序输出?
解决方式:
-
依赖list的数据具有顺序的特征对信息进行管理
-
使用队列模型解决多路信息汇总合并的问题
-
使用栈模型解决最新消息的问题
list 类型数据操作注意事项
- list中保存的数据都是string类型的,数据总容量是有限的,最多2^32 - 1 个元素 (4294967295)。
- list具有索引的概念,但是操作数据时通常以队列的形式进行入队出队操作,或以栈的形式进行入栈出栈操作
- 获取全部数据操作结束索引设置为-1
- list可以对数据进行分页操作,
2.4 set 类型
基本介绍
新的存储需求:存储大量的数据,在查询方面提供更高的效率
需要的存储结构:能够保存大量的数据,高效的内部存储机制,便于查询
set类型:底层与hash存储结构完全相同,仅存储键,不存储值(nil),并且值是不允许重复的
示意图:
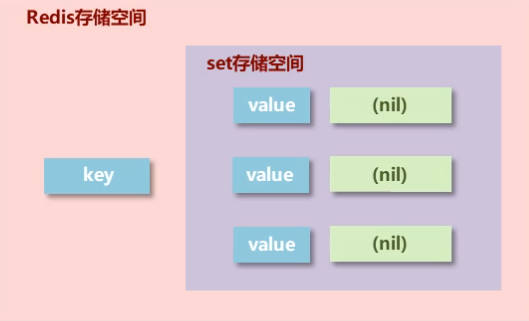
基本操作
-
添加数据
sadd key member1 [member2] -
获取全部数据
smembers key -
删除数据
srem key member1 [member2] -
获取集合数据总量
scard key -
判断集合中是否包含指定数据
sismember key member
扩展操作
每位用户首次使用今日头条时会设置3项爱好的内容,但是后期为了增加用户的活跃度、兴趣点,必须让用户 对其他信息类别逐渐产生兴趣,增加客户留存度,如何实现?
解决方式:
- 系统分析出各个分类的最新或最热点信息条目并组织成set集合
- 随机挑选其中部分信息
- 配合用户关注信息分类中的热点信息组织成展示的全信息集合
相关命令:
-
随机获取集合中指定数量的数据
srandmember key [count] // 随机获取set中指定的元素个数 -
随机获取集合中的某个数据并将该数据移出集合
spop key [count] //随机拿取
redis 应用于随机推荐类信息检索,例如热点歌单推荐,热点新闻推荐,热卖旅游线路,应用APP推荐, 大V推荐等
其他业务场景:
- 脉脉为了促进用户间的交流,保障业务成单率的提升,需要让每位用户拥有大量的好友,事实上职场新人不 具有更多的职场好友,如何快速为用户积累更多的好友?
- 新浪微博为了增加用户热度,提高用户留存性,需要微博用户在关注更多的人,以此获得更多的信息或热门 话题,如何提高用户关注他人的总量?
- QQ新用户入网年龄越来越低,这些用户的朋友圈交际圈非常小,往往集中在一所学校甚至一个班级中,如何 帮助用户快速积累好友用户带来更多的活跃度?
- ...
相关命令:
-
求两个集合的交、并、差集
sinter key1 [key2] //两个set 集合中相同的一部分 sunion key1 [key2] // 加在一起的部分 sdiff key1 [key2] // key1 去除 key2 中剩下的部分,所以调过来结果可能不相同 -
求两个集合的交、并、差集并存储到指定集合中 (destination集合)
sinterstore destination key1 [key2] sunionstore destination key1 [key2] sdiffstore destination key1 [key2] -
将指定数据从原始集合中移动到目标集合中 ,
smove source destination member
redis 应用于同类信息的关联搜索,二度关联搜索,深度关联搜索
显示共同关注(一度) 显示共同好友(一度)
由用户A出发,获取到好友用户B的好友信息列表(一度)
由用户A出发,获取到好友用户B的购物清单列表(二度)
由用户A出发,获取到好友用户B的游戏充值列表(二度)
set 类型数据操作的注意事项
set 类型不允许数据重复,如果添加的数据在 set 中已经存在,将只保留一份
set 虽然与hash的存储结构相同,但是无法启用hash中存储值的空间
set 类型应用场景
场景一:
集团公司共具有12000名员工,内部OA系统中具有700多个角色,3000多个业务操作,23000多种数据,每 位员工具有一个或多个角色,如何快速进行业务操作的权限校验?
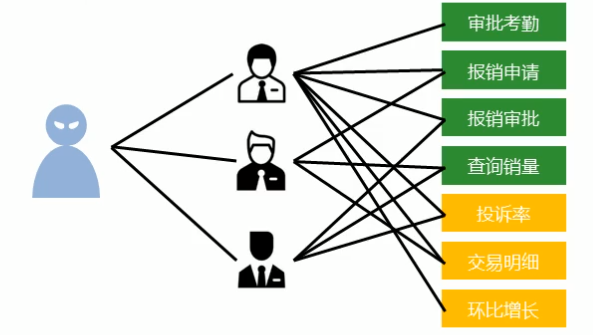
解决方案:
- 依赖set集合数据不重复的特征,依赖set集合hash存储结构特征完成数据过滤与快速查询
- 根据用户id获取用户所有角色
- 根据用户所有角色获取用户所有操作权限放入set集合
- 根据用户所有觉得获取用户所有数据全选放入set集合
redis应用于同类型不重复数据的合并操作
场景二:
公司对旗下新的网站做推广,统计网站的PV(访问量),UV(独立访客),IP(独立IP)。
PV:网站被访问次数,可通过刷新页面提高访问量
UV:网站被不同用户访问的次数,可通过cookie统计访问量,相同用户切换IP地址,UV不变
IP:网站被不同IP地址访问的总次数,可通过IP地址统计访问量,相同IP不同用户访问,IP不变
解决方案:
- 利用set集合的数据去重特征,记录各种访问数据
- 建立string类型数据,利用incr统计日访问量(PV)
- 建立set模型,记录不同cookie数量(UV)
- 建立set模型,记录不同IP数量(IP)
redis 应用于同类型数据的快速去重
场景三:
redis 应用于基于黑名单与白名单设定的服务控制
解决方案:
基于经营战略设定问题用户发现、鉴别规则
- 周期性更新满足规则的用户黑名单,加入set集合
- 用户行为信息达到后与黑名单进行比对,确认行为去向
- 黑名单过滤IP地址:应用于开放游客访问权限的信息源
- 黑名单过滤设备信息:应用于限定访问设备的信息源
- 黑名单过滤用户:应用于基于访问权限的信息源
2.5 sorted_set 类型
基本介绍
新的存储需求:数据排序有利于数据的有效展示,需要提供一种可以根据自身特征进行排序的方式
需要的存储结构:新的存储模型,可以保存可排序的数据
sorted_set类型:在set的存储结构基础上添加可排序字段
示意图:
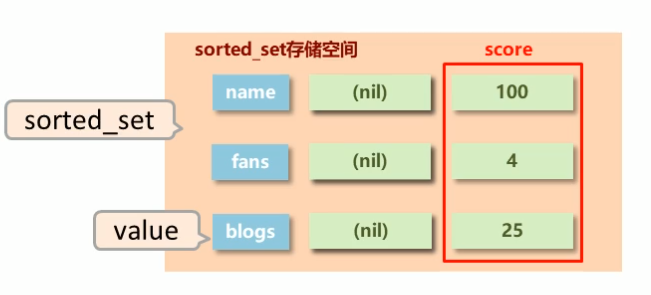
sorted_set 类型数据的基本操作
-
添加数据
zadd key score1 member1 [score2 member2] //score1 顺序值, member1 value值 ,可以多次储存 -
获取全部数据
zrange key start stop [WITHSCORES] // 获取从start 索引start开始到 stop 结束后的元素,若带上withscores 则顺序号和元素一起输出 zrevrange key start stop [WITHSCORES] //输出结果 倒转 -
删除数据
zrem key member [member ...] //删除指定的值 -
按条件获取数据
zrangebyscore key min max [WITHSCORES] [LIMIT] // 获取指定顺序号 min开始到 max 结束的值, limit 0 3 意为分页操作, 从结果的0索引开始 查询3个 zrevrangebyscore key max min [WITHSCORES] //结果反转 -
条件删除数据
zremrangebyrank key start stop // 删除元素,指定索引开始结束 zremrangebyscore key min max // 删除元素,指定score 排序值的开始结束注意:
min与max用于限定搜索查询的条件
start与stop用于限定查询范围,作用于索引,表示开始和结束索引
offset与count用于限定查询范围,作用于查询结果,表示开始位置和数据总量
-
获取集合数据总量
zcard key // 总个数 zcount key min max //指定范围内的个数 -
集合交、并操作
zinterstore destination numkeys key [key ...] //将指定个数numkeys的sorted_set ,中共同拥有的部分元素移动到destination sorted_set中, 指定几个,后面的key 就要写几个, 合并后, 排序字段默认是相加合并,也可以指定规则为取最大最小值 zunionstore destination numkeys key [key ...] //将相交操作改外合并 -
获取数据对应的索引(排名)
zrank key member // 获取 sorted_set中 值为member 的索引(排名) zrevrank key member // 获取倒着数的索引 -
score值获取与修改
zscore key member //获取 sorted_set 中值为member 的score值 zincrby key increment member //将 sorted_set中 值为member的score值加上指定的值increment
sorted_set 类型数据操作的注意事项
- score保存的数据存储空间是64位,如果是整数范围是-9007199254740992~9007199254740992
- score保存的数据也可以是一个双精度的double值,基于双精度浮点数的特征,可能会丢失精度,使用时 候要慎重
- sorted_set 底层存储还是基于set结构的,因此数据不能重复,如果重复添加相同的数据,score值将被反复覆盖,保留最后一次修改的结果
sorted_set 类型应用场景
当任务或者消息待处理,形成了任务队列或消息队列时,对于高优先级的任务要保障对其优先处理,如 何实现任务权重管理。
- 对于带有权重的任务,优先处理权重高的任务,采用score记录权重即可
- redis 应用于即时任务/消息队列执行管理
3. redis通用指令
3.1 Key 相关通用操作
key是一个字符串,通过key获取redis中保存的数据 ,对于key本身,也有一些命令
-
删除指定key
del key -
获取key是否存在
exists key -
获取key的类型
type key
key 扩展操作(时效性控制)
-
为指定key设置有效期
expire key seconds // 单位秒 pexpire key milliseconds //单位毫秒 expireat key timestamp //设置到某个时间戳(秒) pexpireat key milliseconds-timestamp //毫秒 -
获取key的有效时间
ttl key // 查看当前key 有效期还剩多久,如果key不存在返回-2,若指定的key没有设置有效期则是-1 pttl key // 毫秒 -
切换key从时效性转换为永久性
persist key //将一个有期限的key转为永久, 不存在的key 则是返回0
key 扩展操作(查询key)
-
查询key
/** 对于pattern 有如下匹配规则 keys * 查询所有 keys it* 查询所有以it开头 keys *heima 查询所有以heima结尾 keys ??heima 查询所有前面两个字符任意,后面以heima结尾 keys user:? 查询所有以user:开头,最后一个字符任意 keys u[st]er:1 查询所有以u开头,以er:1结尾,中间包含一个字母,s或t */ keys pattern
key 其他操作
-
为key改名
rename key newkey renamenx key newkey -
对指定的value进行排序排序
sort key // 对 list,set,sorted_set 进行排序 -
其他key通用操作
help @generic
3.2 数据库通用操作
由于key是由程序员定义的 .
redis在使用过程中,伴随着操作数据量的增加,会出现大量的数据以及对应的key
数据不区分种类、类别混杂在一起,极易出现重复或冲突
所以,redis为每个服务提供有16个数据库,编号从0到15 ,每个数据库之间的数据相互独立
db 基本操作
-
切换数据库
select index //默认为0 -
数据移动
move key db //移动本库中的数据到指定的库中, 而且必须保证目的地库没有此key -
数据清除
dbsize // 当前库有多少key flushdb //清除当前库数据 flushall //清除所有库数据(常用高级命令,一般到一个新公司第一件事执行这个命令,会受到所有人的关注) -
其他操作
quit //退出 ping //测试服务器是否连通 echo message //输出日志