零、背景
公司最近有个爬虫的项目,先拿小红书下手,但是小红书很多内容 web 端没有,只能用 app 爬,于是了解到 Appium 这个强大的框架,即可以做自动化测试,也可以用来当自动化爬虫。
本文的代码只是一个简单的 spike,没有太多深入的实践。后续如果有深挖,我会来补充的。
一、介绍
Appium 实际上继承了 Selenium(一个流行的 web 浏览器自动化测试框架), 也是利用 Webdriver 来实现 App 的自动化测试。
1、其实 Appium 和 WebDriver 在技术上并不是“测试框架”,而是“自动化库”。
2、WebDriver 已成为自动化Web浏览器的事实标准,并且收录在W3C工作草案里。
Appium是跨平台的:它允许您使用相同的API针对多个平台(iOS,Android,Windows)编写测试。
但是底层,Appium 通过使用供应商提供的自动化框架来满足需求:
- iOS 9.3及以上版本:Apple的 XCUITest
- iOS 9.3及更低版本:Apple的 UIAutomation
- Android 4.2+:Google的 UiAutomator / UiAutomator2
- Android 2.3+:Google的 Instrumentation
- Windows:微软的 WinAppDriver
Appium是开源的。
二、Appium 架构
属于 C/S 架构,包括:
Appium Server: 是一个用 Node.js 编写的公开的 REST API WEB 服务器。
Appium Client: 有很多客户端库(Java,Ruby,Python,PHP,JavaScript 和 C#)。
三、安装
此章针对 mac 用户对 android 进行测试。
1、 安装 Appium Server
推荐安装:Appium Desktop ,包含 Appium Server + Appium Client(提供的是 UI 界面化的操作),还有丰富的调试功能。
2、安装 Appium Client
python 开发环境:pip3 install Appium-Python-Client
node.js 开发环境: npm install -g appium
3、安装 Android SDK
1、可以通过安装 android studio 来安装 Android SDK。
下载:https://developer.android.com/studio/index.html?hl=zh-cn
2、添加环境变量
在 ~/.bash_profile (我用的是 zsh,所以是 ~/.zprofile )里添加:
export ANDROID_HOME=/Users/xjnotxj/Library/Android/sdk
export PATH=${PATH}:${ANDROID_HOME}/tools
export PATH=${PATH}:${ANDROID_HOME}/platform-tools
4、验证安装
检验上述的安装是否完备,可以通过 appium-doctor 这个包:npm install -g appium-doctor
appium-doctor --android
# or for ios
appium-doctor --iod
四、使用
1、Appium Client 采用 UI 方式
以我的 三星 s9+ 手机为例。
1、手机用数据线连上电脑,同时打开 USB 调试。
2、启动 appium server,并 start 一个 session(如下图红色箭头)。
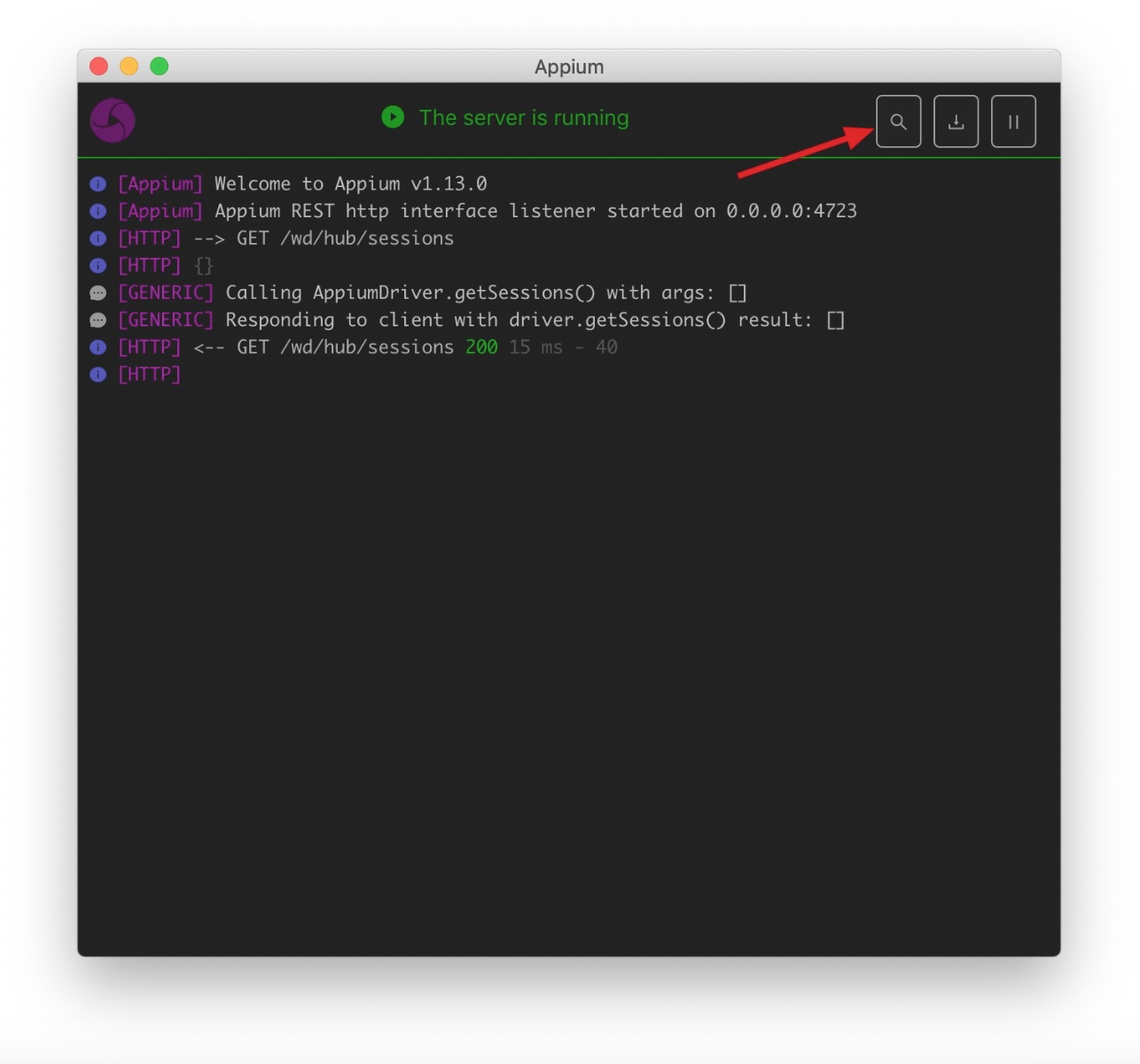
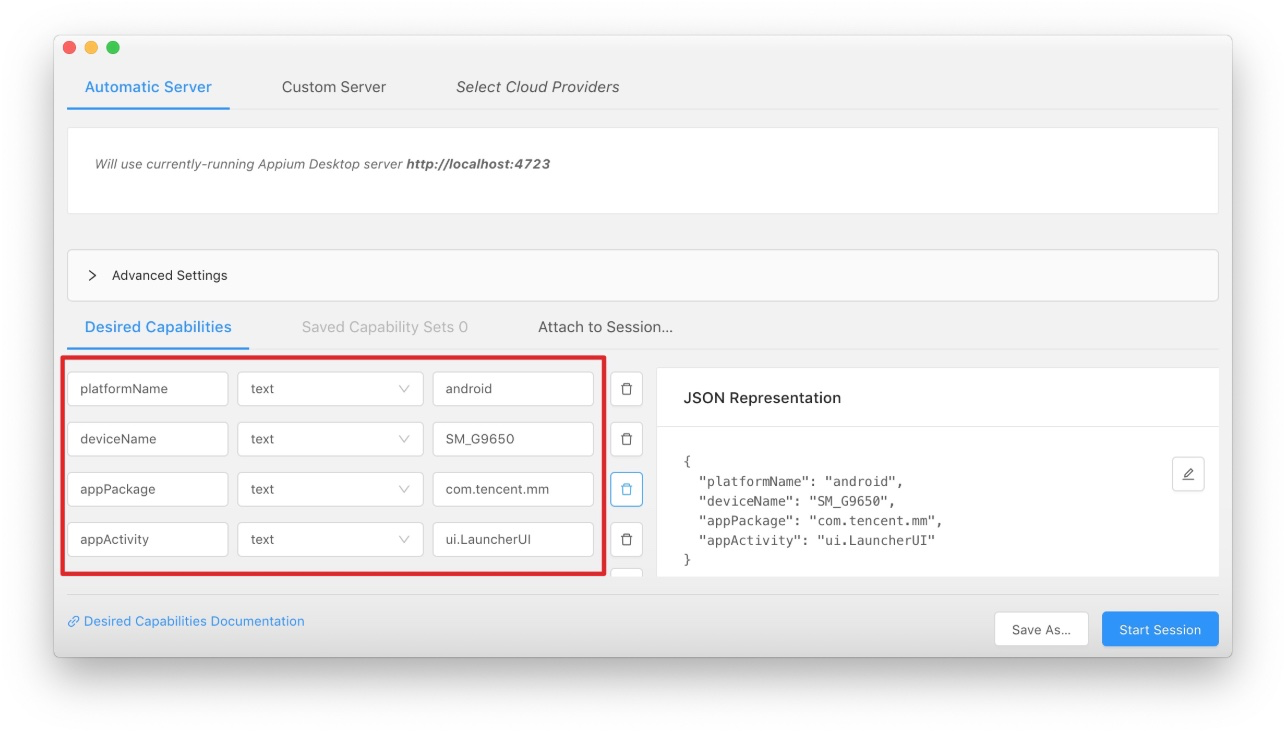
3、输入 desired_caps 配置,并点击 start session:
{
"platformName": "android",
"deviceName": "SM_G9650",
"appPackage": "com.tencent.mm",
"appActivity": "ui.LauncherUI",
"noReset": true
}
参数解释:
deviceName:
adb devices -l命令返回值里的 model 值appPackage / appActivity :获取方法请看:https://www.cnblogs.com/fnng/p/7350900.html
推荐加上
noReset:true:可以每次测试不重置应用(我的微信聊天记录就是这么没有的……)
4、点击录制按钮

5、使用界面化操作 app
6、结束录制后可支持导出各种编程语言的代码
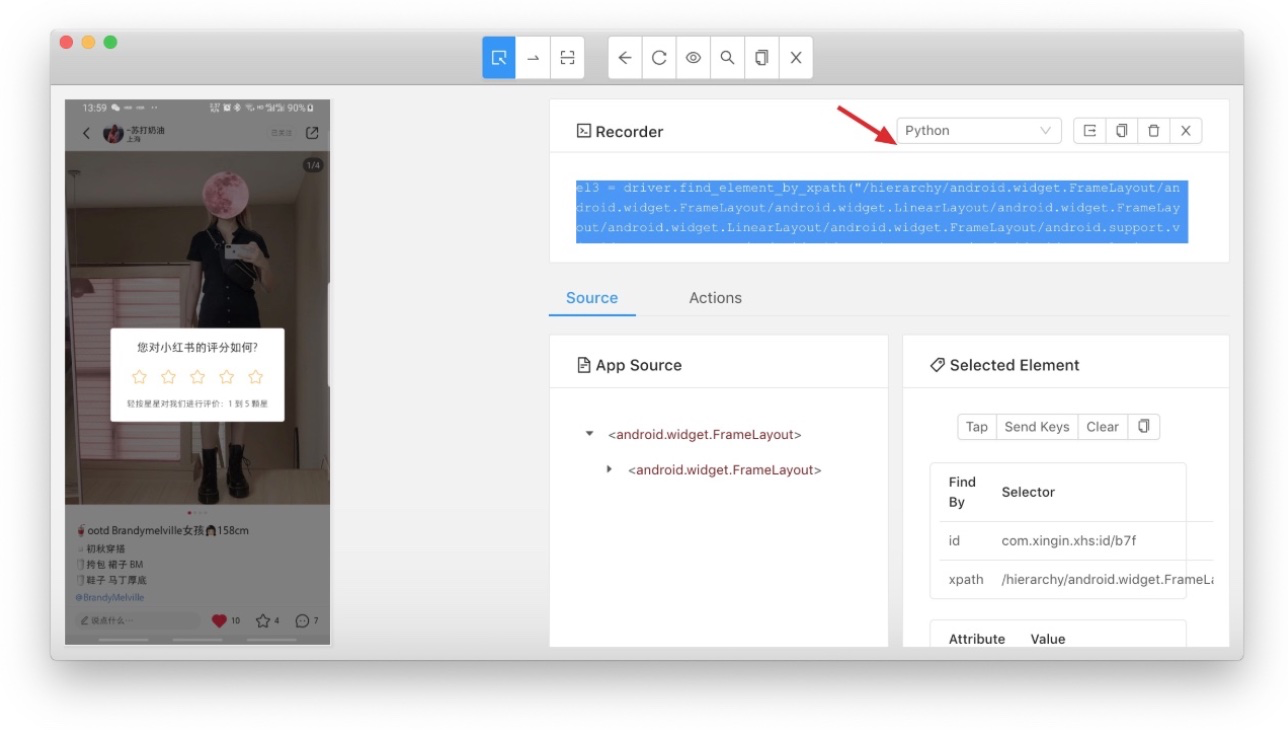
此次录制的步骤如下:
1、启动小红书
2、点击主页瀑布流的第一个帖子
3、点击底部的喜欢按钮
导出的代码如下:
el3 = driver.find_element_by_xpath("/hierarchy/android.widget.FrameLayout/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.support.v4.widget.DrawerLayout/android.widget.LinearLayout/android.widget.RelativeLayout/android.support.v4.view.ViewPager/android.widget.LinearLayout/android.widget.FrameLayout/android.support.v4.view.ViewPager/android.widget.FrameLayout/android.view.ViewGroup/android.support.v7.widget.RecyclerView/android.widget.FrameLayout[1]/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.ImageView")
el3.click()
el4 = driver.find_element_by_id("com.xingin.xhs:id/b7f")
el4.click()
2、拓展 - Appium 三种等待元素的方法
Appium 里定位元素是经常的操作,但是有时元素的加载需要时间(如 Ajax 时受到网速的限制),为了避免在元素没有加载好的时候去定位,从而抛出 NoSuchElementException 的异常,下面介绍三种等待元素的方法。
(1) sleep
import time
# 等待10s
time.slee(10)
简单粗暴。
(2) 隐式等待
针对所有元素定义的等待时间。
# focus here
driver.implicitly_wait(10)
……
driver.find_element_by_xpath(…A…)
……
driver.find_element_by_xpath(…B…)
implicitly_wait() 只有一个参数,就是最长等待时间,期间会不断轮询。
implicitly_wait 适用于所有定位元素的函数。
(3) 显式等待
可以针对单个元素定义不同的等待方式。
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Remote(server, desired_caps)
# focus here
wait = WebDriverWait(driver, 30)
temp = wait.until(EC.presence_of_element_located(
(By.ID, 'com.xingin.xhs:id/axk')))
temp.click()
1、WebDriverWait() 的参数有四个:
-
driver:浏览器驱动。
-
timeout:最长超时时间,默认以秒为单位。
-
poll_frequency:检测的间隔(步长)时间,默认为 0.5 S。
-
ignored_exceptions:超时后的异常信息,默认情况下抛 Nosuchelementexception 异常。
2、WebDriverWait() 可以调用 until / until_not。前者是当参数为 True 时才触发,后者是当参数为 False 时触发。
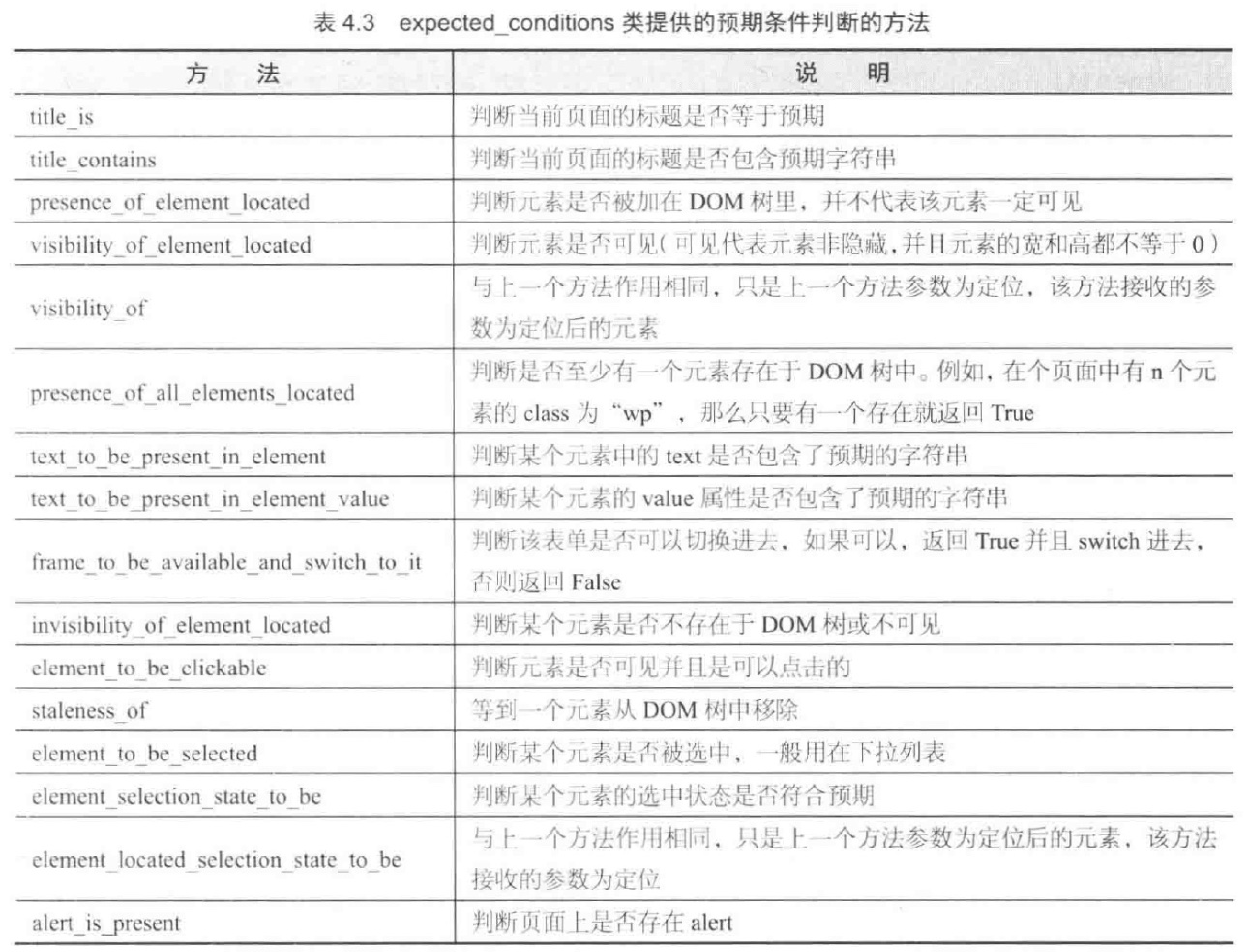
3、expected_conditions 也就是 EC,提供了预期条件判断的方法,比如:
presence_of_element_located : 判断元素是否被加在 DOM 树里,并不代表该元素一定可见
visibility_of_element_located : 判断元素是否可见(可见代表元素非隐藏,并且元素的宽和高都不等于 0)
除此之外还有更多种:
3、Appium Client 采用编码方式
(1) 此次需求
1、打开小红书
2、点击顶部搜索栏,键入想要搜的用户名
3、点击搜出来的第一个用户,进入个人详情页
4、获取此人的 关注数 / 粉丝 / 获赞与收藏
5、获取此人发的所有帖子的 标题/封面/被喜欢数
(2) 重难点
需求1-4很简单,就是定位元素,然后操控元素和获取元素的 attribute 就好。
关于定位元素,优先用 id,没有 id 的时候退而求其次用 xpath。至于 id/xpath 的值,可以用 appium desktop 界面化的去查看,如下图:
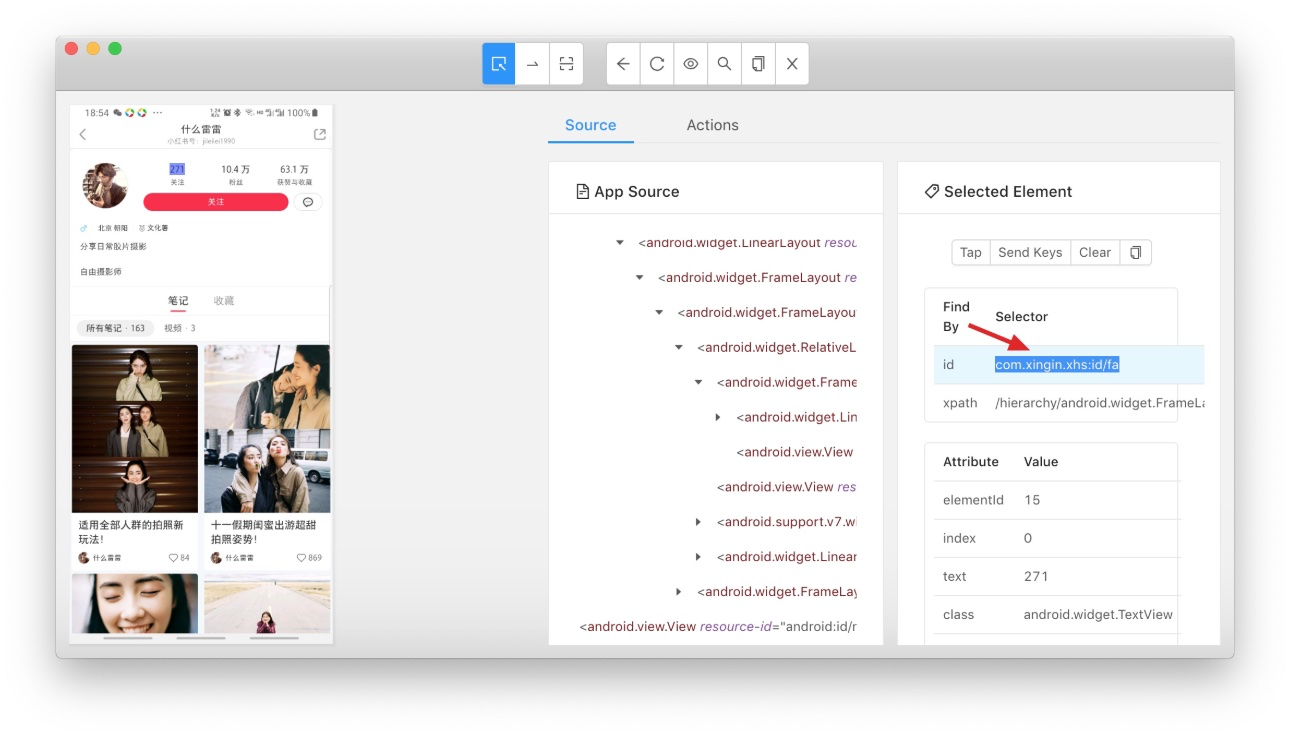
重点是需求5,因为用户发的帖子是一个瀑布流,即:
1、内容很长,需要页面往下滑动
解决方案:设置一个 loop,然后一直调用swipe滚动函数。
2、滑动的过程中会懒加载
解决方案:调用swipe滚动函数的时候,最后一个参数 duration 值设的大一些,比如个把秒,这样可以让滑动变的较慢,从而边滑动边触发懒加载,让页面顺畅进行。
3、瀑布流的帖子高度不一,参差不齐,可能会取到重复帖子
解决方案:将错就错,就取冗余数据,但用比如 set 这种数据结构来避免数据重复。
4、如何判断内容取尽,滑到底部了?
解决方案:用一个土办法的方法,即始终记录上一次取的数据,跟当前取的数据做对比,如果完全一样,证明页面没变化,则退出 loop。
(3) 注意点
在需求5向下滑动帖子的过程中,有以下几个注意点:
1、每个帖子的 xpath 格式为:
/hierarchy/android.widget.FrameLayout/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.FrameLayout/android.widget.FrameLayout/android.widget.RelativeLayout/android.view.ViewGroup/android.view.ViewGroup/android.view.ViewGroup/android.view.ViewGroup/android.widget.FrameLayout[n]/……
上面的n 取正整数(即从1开始)。
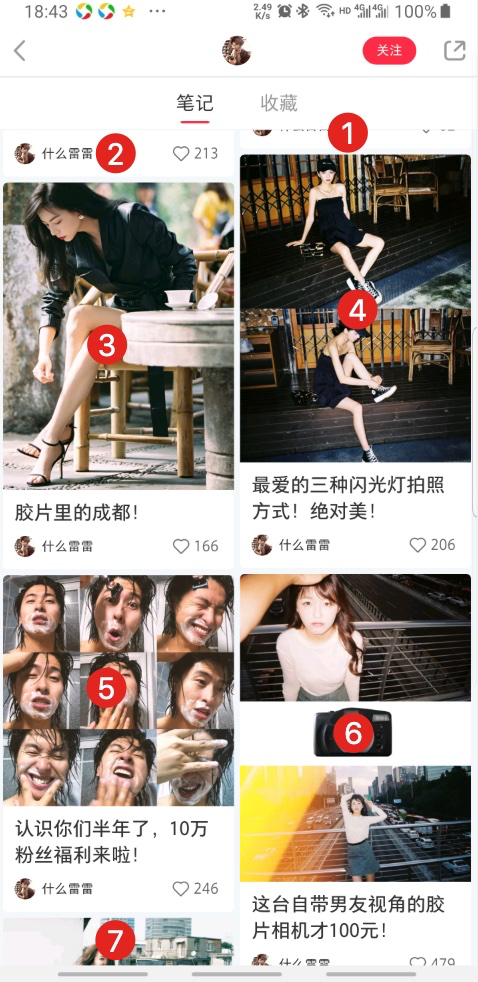
2、不管怎样向下滑动页面,n的值不是累加的,而是根据当前显示的仅有帖子重新排列的,如下图。
3、且 appium 是可见即可爬的,所以下图①的帖子内容几乎都被遮住了,会取不到内容。
4、从下图看,一个页面最多只能显示 8 个帖子。
(4) 代码
from appium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException
import time
server = 'http://localhost:4723/wd/hub'
desired_caps = {
"platformName": "android",
"deviceName": "SM_G9650",
"appPackage": "com.xingin.xhs",
"appActivity": "com.xingin.xhs.activity.SplashActivity",
"noReset": True # 可以每次测试不重置应用(我的微信聊天记录就是这么没有的……)
}
# 切换到 unicode 键盘,避免例如中文输入不了的问题
desired_caps["unicodeKeyboard"] = True
desired_caps["resetKeyboard"] = True
driver = webdriver.Remote(server, desired_caps)
driver.implicitly_wait(1)
wait = WebDriverWait(driver, 30)
start = time.time()
print("start")
# 1、目的一:进入个人资料详情页
# 点击搜索框
temp = wait.until(EC.presence_of_element_located(
(By.XPATH, '/hierarchy/android.widget.FrameLayout/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.support.v4.widget.DrawerLayout/android.widget.LinearLayout/android.widget.RelativeLayout/android.support.v4.view.ViewPager/android.widget.LinearLayout/android.widget.LinearLayout/android.widget.FrameLayout[2]/android.widget.FrameLayout/android.widget.FrameLayout/android.widget.FrameLayout')))
temp.click()
# 输入 search text
temp = wait.until(EC.presence_of_element_located(
(By.ID, 'com.xingin.xhs:id/axk')))
temp.set_text("小蒋")
# 点击搜索按钮
temp = wait.until(EC.presence_of_element_located(
(By.ID, 'com.xingin.xhs:id/axn')))
temp.click()
# 切换到用户 tab
temp = wait.until(EC.presence_of_element_located(
(By.XPATH, '/hierarchy/android.widget.FrameLayout/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.FrameLayout/android.widget.FrameLayout/android.view.ViewGroup/android.widget.LinearLayout/android.widget.HorizontalScrollView/android.widget.LinearLayout/android.support.v7.app.a.b[3]')))
temp.click()
# 所有的用户里选择第一个
temp = wait.until(EC.presence_of_element_located(
(By.XPATH, '/hierarchy/android.widget.FrameLayout/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.FrameLayout/android.widget.FrameLayout/android.view.ViewGroup/android.view.ViewGroup/android.widget.FrameLayout/android.view.ViewGroup/android.widget.RelativeLayout[1]')))
temp.click()
# 2、目的二:搜刮想要的信息
# (1)获取用户详情页的总览信息
temp = wait.until(EC.presence_of_element_located(
(By.ID, 'com.xingin.xhs:id/fa')))
temp_n = temp.text
print("关注数:" + str(temp_n))
temp = wait.until(EC.presence_of_element_located(
(By.ID, 'com.xingin.xhs:id/a0h')))
temp_n = temp.text
print("粉丝:" + str(temp_n))
temp = wait.until(EC.presence_of_element_located(
(By.ID, 'com.xingin.xhs:id/ah6')))
temp_n = temp.text
print("获赞与收藏:" + str(temp_n))
# (2)获取此人所有发帖信息
# 定义滑动函数
def swipeDown(value):
# 获取屏幕的高
x = driver.get_window_size()['width']
# 获取屏幕宽
y = driver.get_window_size()['height']
# 滑动页面(最后一个参数设的比较大,防止下拉懒加载的时候打断原有滑动应该有的距离)
driver.swipe(1/2*x, 1/2*y, 1/2*x, value * y, 3000)
# 首先把页面往上拉一些(把总览信息收上去)
swipeDown(0.28)
# 获取用户所有发帖
per_n = 8 # 每次翻页后抓取个数(依据:一个页面最大显示贴子数的个数,包括了显示不全的)
result = set() # 存获取到的帖子(会有重复获取的情况,因此用 set 数据结构)
last_result = "" # 记录上一次翻页获取的数据(为了实现翻到页底退出循环的功能)
while True:
cur_result = "" # 记录当前翻页获取的数据(为了实现翻到页底退出循环的功能)
for i in range(1, per_n + 1):
print("正在获取当前页的第" + str(i) + "个帖子……")
# 获取 img
# 待写:因为普通办法行不通(找不到图片的 src),考虑用截图 api
# 获取 title
# 待写:因为普通办法行不通(很诡异,可见但不可得,元素的 text 属性值是空的),考虑用 OCR api
# 获取被 like 数
try:
temp = driver.find_element_by_xpath('/hierarchy/android.widget.FrameLayout/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.FrameLayout/android.widget.FrameLayout/android.widget.RelativeLayout/android.view.ViewGroup/android.view.ViewGroup/android.view.ViewGroup/android.view.ViewGroup/android.widget.FrameLayout['
+ str(i) +
']/android.widget.LinearLayout/android.widget.LinearLayout[2]/android.widget.RelativeLayout/android.widget.TextView')
like_n = temp.text
# save result (其实最好使用 titile 作为 set 的 key,但是因为获取不到 title,暂时拿 like 数将就下吧)
result.add(like_n)
cur_result = cur_result + str(like_n)
print("第" + str(i) + "个帖子的被 like 数" + " : " + str(like_n))
except NoSuchElementException as e:
# 找不到就不管了(找不到的原因是此帖显示不全)
pass
# 滑动翻页(系数太小已经不好计算了,所以分两次滑动吧)
swipeDown(0.16)
swipeDown(0.16)
# 判断是否滑到底
if(cur_result == last_result):
break
else:
last_result = cur_result
end = time.time()
print("end")
print("total time:")
print(end - start)
print("result:")
print(result)
print 结果:
关注数:283
粉丝:2.0 万
获赞与收藏:7071
正在获取当前页的第1个帖子……
第1个帖子的被 like 数 : 71
正在获取当前页的第2个帖子……
第2个帖子的被 like 数 : 79
正在获取当前页的第3个帖子……
第3个帖子的被 like 数 : 57
正在获取当前页的第4个帖子……
第4个帖子的被 like 数 : 80
正在获取当前页的第5个帖子……
正在获取当前页的第6个帖子……
正在获取当前页的第7个帖子……
正在获取当前页的第8个帖子……
正在获取当前页的第1个帖子……
第1个帖子的被 like 数 : 57
正在获取当前页的第2个帖子……
正在获取当前页的第3个帖子……
第3个帖子的被 like 数 : 134
正在获取当前页的第4个帖子……
第4个帖子的被 like 数 : 125
正在获取当前页的第5个帖子……
第5个帖子的被 like 数 : 77
正在获取当前页的第6个帖子……
正在获取当前页的第7个帖子……
第7个帖子的被 like 数 : 128
正在获取当前页的第8个帖子……
正在获取当前页的第1个帖子……
第1个帖子的被 like 数 : 125
正在获取当前页的第2个帖子……
第2个帖子的被 like 数 : 116
正在获取当前页的第3个帖子……
第3个帖子的被 like 数 : 128
正在获取当前页的第4个帖子……
第4个帖子的被 like 数 : 116
正在获取当前页的第5个帖子……
第5个帖子的被 like 数 : 124
正在获取当前页的第6个帖子……
第6个帖子的被 like 数 : 111
正在获取当前页的第7个帖子……
正在获取当前页的第8个帖子……
正在获取当前页的第1个帖子……
正在获取当前页的第2个帖子……
正在获取当前页的第3个帖子……
第3个帖子的被 like 数 : 164
正在获取当前页的第4个帖子……
第4个帖子的被 like 数 : 170
正在获取当前页的第5个帖子……
第5个帖子的被 like 数 : 140
正在获取当前页的第6个帖子……
第6个帖子的被 like 数 : 105
正在获取当前页的第7个帖子……
正在获取当前页的第8个帖子……
正在获取当前页的第1个帖子……
第1个帖子的被 like 数 : 170
正在获取当前页的第2个帖子……
正在获取当前页的第3个帖子……
第3个帖子的被 like 数 : 143
正在获取当前页的第4个帖子……
第4个帖子的被 like 数 : 97
正在获取当前页的第5个帖子……
第5个帖子的被 like 数 : 93
正在获取当前页的第6个帖子……
第6个帖子的被 like 数 : 171
正在获取当前页的第7个帖子……
正在获取当前页的第8个帖子……
正在获取当前页的第1个帖子……
第1个帖子的被 like 数 : 93
正在获取当前页的第2个帖子……
第2个帖子的被 like 数 : 90
正在获取当前页的第3个帖子……
第3个帖子的被 like 数 : 111
正在获取当前页的第4个帖子……
第4个帖子的被 like 数 : 73
正在获取当前页的第5个帖子……
第5个帖子的被 like 数 : 80
正在获取当前页的第6个帖子……
正在获取当前页的第7个帖子……
正在获取当前页的第8个帖子……
正在获取当前页的第1个帖子……
第1个帖子的被 like 数 : 73
正在获取当前页的第2个帖子……
正在获取当前页的第3个帖子……
第3个帖子的被 like 数 : 109
正在获取当前页的第4个帖子……
第4个帖子的被 like 数 : 87
正在获取当前页的第5个帖子……
第5个帖子的被 like 数 : 68
正在获取当前页的第6个帖子……
第6个帖子的被 like 数 : 141
正在获取当前页的第7个帖子……
正在获取当前页的第8个帖子……
正在获取当前页的第1个帖子……
第1个帖子的被 like 数 : 68
正在获取当前页的第2个帖子……
正在获取当前页的第3个帖子……
第3个帖子的被 like 数 : 138
正在获取当前页的第4个帖子……
第4个帖子的被 like 数 : 174
正在获取当前页的第5个帖子……
正在获取当前页的第6个帖子……
第6个帖子的被 like 数 : 109
正在获取当前页的第7个帖子……
正在获取当前页的第8个帖子……
正在获取当前页的第1个帖子……
第1个帖子的被 like 数 : 70
正在获取当前页的第2个帖子……
第2个帖子的被 like 数 : 142
正在获取当前页的第3个帖子……
第3个帖子的被 like 数 : 76
正在获取当前页的第4个帖子……
正在获取当前页的第5个帖子……
第5个帖子的被 like 数 : 115
正在获取当前页的第6个帖子……
正在获取当前页的第7个帖子……
正在获取当前页的第8个帖子……
正在获取当前页的第1个帖子……
第1个帖子的被 like 数 : 81
正在获取当前页的第2个帖子……
第2个帖子的被 like 数 : 74
正在获取当前页的第3个帖子……
第3个帖子的被 like 数 : 115
正在获取当前页的第4个帖子……
正在获取当前页的第5个帖子……
第5个帖子的被 like 数 : 101
正在获取当前页的第6个帖子……
正在获取当前页的第7个帖子……
正在获取当前页的第8个帖子……
正在获取当前页的第1个帖子……
第1个帖子的被 like 数 : 75
正在获取当前页的第2个帖子……
第2个帖子的被 like 数 : 270
正在获取当前页的第3个帖子……
第3个帖子的被 like 数 : 131
正在获取当前页的第4个帖子……
正在获取当前页的第5个帖子……
第5个帖子的被 like 数 : 132
正在获取当前页的第6个帖子……
正在获取当前页的第7个帖子……
正在获取当前页的第8个帖子……
正在获取当前页的第1个帖子……
第1个帖子的被 like 数 : 128
正在获取当前页的第2个帖子……
正在获取当前页的第3个帖子……
第3个帖子的被 like 数 : 109
正在获取当前页的第4个帖子……
第4个帖子的被 like 数 : 107
正在获取当前页的第5个帖子……
正在获取当前页的第6个帖子……
第6个帖子的被 like 数 : 74
正在获取当前页的第7个帖子……
正在获取当前页的第8个帖子……
正在获取当前页的第1个帖子……
第1个帖子的被 like 数 : 64
正在获取当前页的第2个帖子……
正在获取当前页的第3个帖子……
第3个帖子的被 like 数 : 72
正在获取当前页的第4个帖子……
第4个帖子的被 like 数 : 77
正在获取当前页的第5个帖子……
正在获取当前页的第6个帖子……
第6个帖子的被 like 数 : 60
正在获取当前页的第7个帖子……
正在获取当前页的第8个帖子……
正在获取当前页的第1个帖子……
第1个帖子的被 like 数 : 72
正在获取当前页的第2个帖子……
第2个帖子的被 like 数 : 77
正在获取当前页的第3个帖子……
第3个帖子的被 like 数 : 60
正在获取当前页的第4个帖子……
第4个帖子的被 like 数 : 33
正在获取当前页的第5个帖子……
第5个帖子的被 like 数 : 98
正在获取当前页的第6个帖子……
正在获取当前页的第7个帖子……
正在获取当前页的第8个帖子……
正在获取当前页的第1个帖子……
第1个帖子的被 like 数 : 72
正在获取当前页的第2个帖子……
第2个帖子的被 like 数 : 77
正在获取当前页的第3个帖子……
第3个帖子的被 like 数 : 60
正在获取当前页的第4个帖子……
第4个帖子的被 like 数 : 33
正在获取当前页的第5个帖子……
第5个帖子的被 like 数 : 98
正在获取当前页的第6个帖子……
正在获取当前页的第7个帖子……
正在获取当前页的第8个帖子……
end
total time:
177.27380394935608
result:
{'87 ', '128 ', '97 ', '138 ', '132 ', '81 ', '174 ', '134 ', '33 ', '107 ', '57 ', '80 ', '115 ', '170 ', '171 ', '64 ', '90 ', '60 ', '105 ', '140 ', '164 ', '98 ', '270 ', '125 ', '142 ', '75 ', '68 ', '93 ', '72 ', '131 ', '74 ', '143 ', '116 ', '124 ', '76 ', '77 ', '111 ', '109 ', '79 ', '101 ', '73 ', '70 ', '141 ', '71 '}
(5) 坑
1、搜索框不能输入中文
解决方案:切换到 unicode 键盘。
在desired_caps里加几行配置:
desired_caps["unicodeKeyboard"] = True
desired_caps["resetKeyboard"] = True
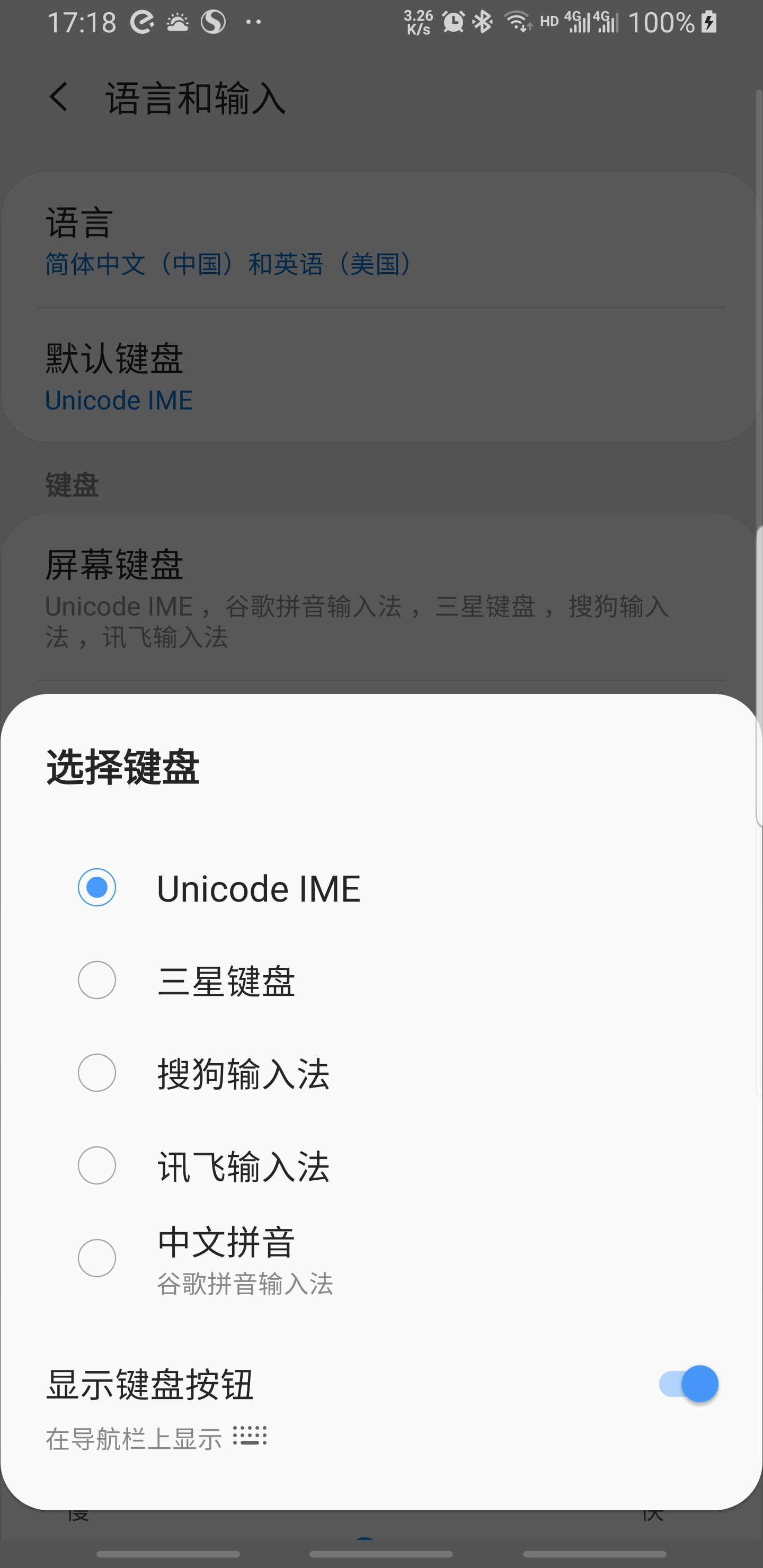
有的手机会出现诡异的问题,比如我的 三星 S9+,加了上面的配置后,输入中文的成功率是50%,即隔一次好一次,很规律,原因未知。
解决方案:在系统设置里强制把输入法切换成 unicode 键盘。
2、获取不到帖子的标题
其他的元素获得内容只要获取 text 这个 attrbute 就好了,但偏偏标题不行,这个违背了所看即所爬啊。原因未知。
解决方案:用 OCR 吧。
3、获取不到帖子的封面图
找不到任何关于图的信息。
解决方案:用 截图的 api 吧。
参考资料:
《python 3 网络爬虫开发实战》(主要)
《Selenium 2 自动化测试实战》(一点点)