首先是注意力公式:
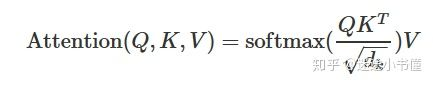
其计算图:

代码:
def attention(query, key, value, mask=None, dropout=None): # query, key, value的形状类似于(30, 8, 10, 64), (30, 8, 11, 64), #(30, 8, 11, 64),例如30是batch.size,即当前batch中有多少一个序列; # 8=head.num,注意力头的个数; # 10=目标序列中词的个数,64是每个词对应的向量表示; # 11=源语言序列传过来的memory中,当前序列的词的个数, # 64是每个词对应的向量表示。 # 类似于,这里假定query来自target language sequence; # key和value都来自source language sequence. "Compute 'Scaled Dot Product Attention'" d_k = query.size(-1) # 64=d_k scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) # 先是(30,8,10,64)和(30, 8, 64, 11)相乘, #(注意是最后两个维度相乘)得到(30,8,10,11), #代表10个目标语言序列中每个词和11个源语言序列的分别的“亲密度”。 #然后除以sqrt(d_k)=8,防止过大的亲密度。 #这里的scores的shape是(30, 8, 10, 11) if mask is not None: scores = scores.masked_fill(mask == 0, -1e9) #使用mask,对已经计算好的scores,按照mask矩阵,填-1e9, #然后在下一步计算softmax的时候,被设置成-1e9的数对应的值~0,被忽视 p_attn = F.softmax(scores, dim = -1) #对scores的最后一个维度执行softmax,得到的还是一个tensor, #(30, 8, 10, 11) if dropout is not None: p_attn = dropout(p_attn) #执行一次dropout return torch.matmul(p_attn, value), p_attn #返回的第一项,是(30,8,10, 11)乘以(最后两个维度相乘) #value=(30,8,11,64),得到的tensor是(30,8,10,64), #和query的最初的形状一样。另外,返回p_attn,形状为(30,8,10,11). #注意,这里返回p_attn主要是用来可视化显示多头注意力机制。
多头注意力:
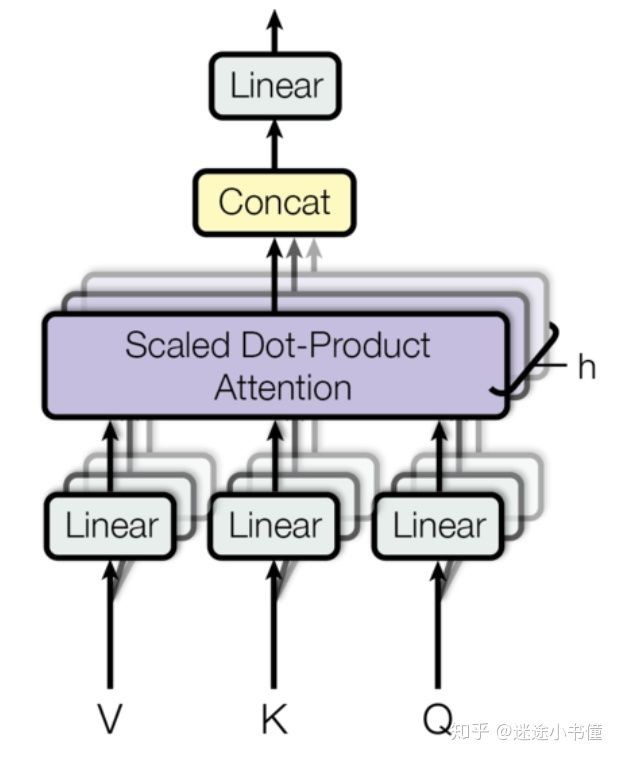
class MultiHeadedAttention(nn.Module): def __init__(self, h, d_model, dropout=0.1): # h=8, d_model=512 "Take in model size and number of heads." super(MultiHeadedAttention, self).__init__() assert d_model % h == 0 # We assume d_v always equals d_k 512%8=0 self.d_k = d_model // h # d_k=512//8=64 self.h = h #8 self.linears = clones(nn.Linear(d_model, d_model), 4) #定义四个Linear networks, 每个的大小是(512, 512)的, #每个Linear network里面有两类可训练参数,Weights, #其大小为512*512,以及biases,其大小为512=d_model。 self.attn = None self.dropout = nn.Dropout(p=dropout) def forward(self, query, key, value, mask=None): # 注意,输入query的形状类似于(30, 10, 512), # key.size() ~ (30, 11, 512), #以及value.size() ~ (30, 11, 512) if mask is not None: # Same mask applied to all h heads. mask = mask.unsqueeze(1) # mask下回细细分解。 nbatches = query.size(0) #e.g., nbatches=30 # 1) Do all the linear projections in batch from #d_model => h x d_k query, key, value = [l(x).view(nbatches, -1, self.h, self.d_k) .transpose(1, 2) for l, x in zip(self.linears, (query, key, value))] # 这里是前三个Linear Networks的具体应用, #例如query=(30,10, 512) -> Linear network -> (30, 10, 512) #-> view -> (30,10, 8, 64) -> transpose(1,2) -> (30, 8, 10, 64) #,其他的key和value也是类似地, #从(30, 11, 512) -> (30, 8, 11, 64)。 # 2) Apply attention on all the projected vectors in batch. x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout) #调用上面定义好的attention函数,输出的x形状为(30, 8, 10, 64); #attn的形状为(30, 8, 10=target.seq.len, 11=src.seq.len) # 3) "Concat" using a view and apply a final linear. x = x.transpose(1, 2).contiguous(). view(nbatches, -1, self.h * self.d_k) # x ~ (30, 8, 10, 64) -> transpose(1,2) -> #(30, 10, 8, 64) -> contiguous() and view -> #(30, 10, 8*64) = (30, 10, 512) return self.linears[-1](x) #执行第四个Linear network,把(30, 10, 512)经过一次linear network, #得到(30, 10, 512).