github地址:https://github.com/iduta/iresnet
论文地址:https://arxiv.org/abs/2004.04989
该论文主要关注点:
- 网络层之间的信息流动-the flow of information through the network layers
- 残差构造模块-the residual building block
- 投影捷径-the projection shortcut
该论文主要贡献:
- 提出了一种新的残差网络。该网络提供了一个更好的信息流动的路径,使得网络更易于优化。
- 改善了投影捷径,减少了信息的损失。所谓的投影捷径,是指当前残差块和下一个残差块的维度不一致时使用的跳跃连接。
- 提出了一个构造模块增加空间通道,以学习到更加强大的空间模式
- 与ResNet相比,在没有增加模型复杂度的情况下,在六个数据集上都取得了提升
直接看代码:


import torch import torch.nn as nn import os from div.download_from_url import download_from_url try: from torch.hub import _get_torch_home torch_cache_home = _get_torch_home() except ImportError: torch_cache_home = os.path.expanduser( os.getenv('TORCH_HOME', os.path.join( os.getenv('XDG_CACHE_HOME', '~/.cache'), 'torch'))) default_cache_path = os.path.join(torch_cache_home, 'pretrained') __all__ = ['iResNet', 'iresnet18', 'iresnet34', 'iresnet50', 'iresnet101', 'iresnet152', 'iresnet200', 'iresnet302', 'iresnet404', 'iresnet1001'] model_urls = { 'iresnet18': 'Trained model not available yet!!', 'iresnet34': 'Trained model not available yet!!', 'iresnet50': 'https://drive.google.com/uc?export=download&id=1Waw3ob8KPXCY9iCLdAD6RUA0nvVguc6K', 'iresnet101': 'https://drive.google.com/uc?export=download&id=1cZ4XhwZfUOm_o0WZvenknHIqgeqkY34y', 'iresnet152': 'https://drive.google.com/uc?export=download&id=10heFLYX7VNlaSrDy4SZbdOOV9xwzwyli', 'iresnet200': 'https://drive.google.com/uc?export=download&id=1Ao-f--jNU7MYPqSW8UMonXVrq3mkLRpW', 'iresnet302': 'https://drive.google.com/uc?export=download&id=1UcyvLhLzORJZBUQDNJdsx3USCloXZT6V', 'iresnet404': 'https://drive.google.com/uc?export=download&id=1hEOHErsD6AF1b3qQi56mgxvYDneTvMIq', 'iresnet1001': 'Trained model not available yet!!', } def conv3x3(in_planes, out_planes, stride=1): """3x3 convolution with padding""" return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False) def conv1x1(in_planes, out_planes, stride=1): """1x1 convolution""" return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False) class BasicBlock(nn.Module): expansion = 1 def __init__(self, inplanes, planes, stride=1, downsample=None, norm_layer=None, start_block=False, end_block=False, exclude_bn0=False): super(BasicBlock, self).__init__() if norm_layer is None: norm_layer = nn.BatchNorm2d # Both self.conv1 and self.downsample layers downsample the input when stride != 1 if not start_block and not exclude_bn0: self.bn0 = norm_layer(inplanes) self.conv1 = conv3x3(inplanes, planes, stride) self.bn1 = norm_layer(planes) self.relu = nn.ReLU(inplace=True) self.conv2 = conv3x3(planes, planes) if start_block: self.bn2 = norm_layer(planes) if end_block: self.bn2 = norm_layer(planes) self.downsample = downsample self.stride = stride self.start_block = start_block self.end_block = end_block self.exclude_bn0 = exclude_bn0 def forward(self, x): identity = x if self.start_block: out = self.conv1(x) elif self.exclude_bn0: out = self.relu(x) out = self.conv1(out) else: out = self.bn0(x) out = self.relu(out) out = self.conv1(out) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) if self.start_block: out = self.bn2(out) if self.downsample is not None: identity = self.downsample(x) out += identity if self.end_block: out = self.bn2(out) out = self.relu(out) return out class Bottleneck(nn.Module): expansion = 4 def __init__(self, inplanes, planes, stride=1, downsample=None, norm_layer=None, start_block=False, end_block=False, exclude_bn0=False): super(Bottleneck, self).__init__() if norm_layer is None: norm_layer = nn.BatchNorm2d # Both self.conv2 and self.downsample layers downsample the input when stride != 1 if not start_block and not exclude_bn0: self.bn0 = norm_layer(inplanes) self.conv1 = conv1x1(inplanes, planes) self.bn1 = norm_layer(planes) self.conv2 = conv3x3(planes, planes, stride) self.bn2 = norm_layer(planes) self.conv3 = conv1x1(planes, planes * self.expansion) if start_block: self.bn3 = norm_layer(planes * self.expansion) if end_block: self.bn3 = norm_layer(planes * self.expansion) self.relu = nn.ReLU(inplace=True) self.downsample = downsample self.stride = stride self.start_block = start_block self.end_block = end_block self.exclude_bn0 = exclude_bn0 def forward(self, x): identity = x if self.start_block: out = self.conv1(x) elif self.exclude_bn0: out = self.relu(x) out = self.conv1(out) else: out = self.bn0(x) out = self.relu(out) out = self.conv1(out) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) if self.start_block: out = self.bn3(out) if self.downsample is not None: identity = self.downsample(x) out += identity if self.end_block: out = self.bn3(out) out = self.relu(out) return out class iResNet(nn.Module): def __init__(self, block, layers, num_classes=1000, zero_init_residual=False, norm_layer=None, dropout_prob0=0.0): super(iResNet, self).__init__() if norm_layer is None: norm_layer = nn.BatchNorm2d self.inplanes = 64 self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = norm_layer(64) self.relu = nn.ReLU(inplace=True) self.layer1 = self._make_layer(block, 64, layers[0], stride=2, norm_layer=norm_layer) self.layer2 = self._make_layer(block, 128, layers[1], stride=2, norm_layer=norm_layer) self.layer3 = self._make_layer(block, 256, layers[2], stride=2, norm_layer=norm_layer) self.layer4 = self._make_layer(block, 512, layers[3], stride=2, norm_layer=norm_layer) self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) if dropout_prob0 > 0.0: self.dp = nn.Dropout(dropout_prob0, inplace=True) print("Using Dropout with the prob to set to 0 of: ", dropout_prob0) else: self.dp = None self.fc = nn.Linear(512 * block.expansion, num_classes) for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)): nn.init.constant_(m.weight, 1) nn.init.constant_(m.bias, 0) # Zero-initialize the last BN in each residual branch, # so that the residual branch starts with zeros, and each residual block behaves like an identity. # This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677 if zero_init_residual: for m in self.modules(): if isinstance(m, Bottleneck): nn.init.constant_(m.bn3.weight, 0) elif isinstance(m, BasicBlock): nn.init.constant_(m.bn2.weight, 0) def _make_layer(self, block, planes, blocks, stride=1, norm_layer=None): if norm_layer is None: norm_layer = nn.BatchNorm2d downsample = None if stride != 1 and self.inplanes != planes * block.expansion: downsample = nn.Sequential( nn.MaxPool2d(kernel_size=3, stride=stride, padding=1), conv1x1(self.inplanes, planes * block.expansion), norm_layer(planes * block.expansion), ) elif self.inplanes != planes * block.expansion: downsample = nn.Sequential( conv1x1(self.inplanes, planes * block.expansion), norm_layer(planes * block.expansion), ) elif stride != 1: downsample = nn.MaxPool2d(kernel_size=3, stride=stride, padding=1) layers = [] layers.append(block(self.inplanes, planes, stride, downsample, norm_layer, start_block=True)) self.inplanes = planes * block.expansion exclude_bn0 = True for _ in range(1, (blocks-1)): layers.append(block(self.inplanes, planes, norm_layer=norm_layer, exclude_bn0=exclude_bn0)) exclude_bn0 = False layers.append(block(self.inplanes, planes, norm_layer=norm_layer, end_block=True, exclude_bn0=exclude_bn0)) return nn.Sequential(*layers) def forward(self, x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.avgpool(x) x = x.view(x.size(0), -1) if self.dp is not None: x = self.dp(x) x = self.fc(x) return x def iresnet18(pretrained=False, **kwargs): """Constructs a iResNet-18 model. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ model = iResNet(BasicBlock, [2, 2, 2, 2], **kwargs) if pretrained: os.makedirs(default_cache_path, exist_ok=True) model.load_state_dict(torch.load(download_from_url(model_urls['iresnet18'], root=default_cache_path))) return model def iresnet34(pretrained=False, **kwargs): """Constructs a iResNet-34 model. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ model = iResNet(BasicBlock, [3, 4, 6, 3], **kwargs) if pretrained: os.makedirs(default_cache_path, exist_ok=True) model.load_state_dict(torch.load(download_from_url(model_urls['iresnet34'], root=default_cache_path))) return model def iresnet50(pretrained=False, **kwargs): """Constructs a iResNet-50 model. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ model = iResNet(Bottleneck, [3, 4, 6, 3], **kwargs) if pretrained: os.makedirs(default_cache_path, exist_ok=True) model.load_state_dict(torch.load(download_from_url(model_urls['iresnet50'], root=default_cache_path))) return model def iresnet101(pretrained=False, **kwargs): """Constructs a iResNet-101 model. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ model = iResNet(Bottleneck, [3, 4, 23, 3], **kwargs) if pretrained: os.makedirs(default_cache_path, exist_ok=True) model.load_state_dict(torch.load(download_from_url(model_urls['iresnet101'], root=default_cache_path))) return model def iresnet152(pretrained=False, **kwargs): """Constructs a iResNet-152 model. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ model = iResNet(Bottleneck, [3, 8, 36, 3], **kwargs) if pretrained: os.makedirs(default_cache_path, exist_ok=True) model.load_state_dict(torch.load(download_from_url(model_urls['iresnet152'], root=default_cache_path))) return model def iresnet200(pretrained=False, **kwargs): """Constructs a iResNet-200 model. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ model = iResNet(Bottleneck, [3, 24, 36, 3], **kwargs) if pretrained: os.makedirs(default_cache_path, exist_ok=True) model.load_state_dict(torch.load(download_from_url(model_urls['iresnet200'], root=default_cache_path))) return model def iresnet302(pretrained=False, **kwargs): """Constructs a iResNet-302 model. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ model = iResNet(Bottleneck, [4, 34, 58, 4], **kwargs) if pretrained: os.makedirs(default_cache_path, exist_ok=True) model.load_state_dict(torch.load(download_from_url(model_urls['iresnet302'], root=default_cache_path))) return model def iresnet404(pretrained=False, **kwargs): """Constructs a iResNet-404 model. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ model = iResNet(Bottleneck, [4, 46, 80, 4], **kwargs) if pretrained: os.makedirs(default_cache_path, exist_ok=True) model.load_state_dict(torch.load(download_from_url(model_urls['iresnet404'], root=default_cache_path))) return model def iresnet1001(pretrained=False, **kwargs): """Constructs a iResNet-1001 model. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ model = iResNet(Bottleneck, [4, 155, 170, 4], **kwargs) if pretrained: os.makedirs(default_cache_path, exist_ok=True) model.load_state_dict(torch.load(download_from_url(model_urls['iresnet1001'], root=default_cache_path))) return model
代码太长了,就折叠起来了。
看下iresnet50()的输出:
iResNet( (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (layer1): Sequential( (0): Bottleneck( (conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (1): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (relu): ReLU(inplace=True) ) (2): Bottleneck( (bn0): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (layer2): Sequential( (0): Bottleneck( (conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (1): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (relu): ReLU(inplace=True) ) (2): Bottleneck( (bn0): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (relu): ReLU(inplace=True) ) (3): Bottleneck( (bn0): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (layer3): Sequential( (0): Bottleneck( (conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (1): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (relu): ReLU(inplace=True) ) (2): Bottleneck( (bn0): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (relu): ReLU(inplace=True) ) (3): Bottleneck( (bn0): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (relu): ReLU(inplace=True) ) (4): Bottleneck( (bn0): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (relu): ReLU(inplace=True) ) (5): Bottleneck( (bn0): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (layer4): Sequential( (0): Bottleneck( (conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (1): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (2): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (relu): ReLU(inplace=True) ) (2): Bottleneck( (bn0): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (avgpool): AdaptiveAvgPool2d(output_size=(1, 1)) (fc): Linear(in_features=2048, out_features=1000, bias=True) )
然后是原始resnet50的输出:
ResNet( (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (layer1): Sequential( (0): Bottleneck( (conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (layer2): Sequential( (0): Bottleneck( (conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (3): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (layer3): Sequential( (0): Bottleneck( (conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (3): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (4): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (5): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (layer4): Sequential( (0): Bottleneck( (conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (avgpool): AdaptiveAvgPool2d(output_size=(1, 1)) (fc): Linear(in_features=2048, out_features=1000, bias=True) )
我们对照着看下iresnet50和resnet50有什么异同:
(1)第一个不同点
在iresnet50中:

在resnet50中:

iresnet50与resnet50相比:少了一个MaxPool2d。
(2) 第一个相同点

这里是每一组中的第0个bottleneckl。特别需要注意最后的一个ReLU。中间的两个ReLU由于是在前向传播过程中计算的,因此在打印模型结构的时候省略了。而且iresnet最后主干路上是没有ReLU激活函数的。
(3) 第二个不同点
在iresnet60中:

在resnet50中:

当某残差块和下一层残差块维度不一致时,iresnet50中跳跃连接进行了改动。
(4)第三个不同点
咋irenet50中:

在resnet50中:

这里是每一组中的第1个bottleneck。与resnet50相比,iresnet50这conv3之后没有bn3层 。同样的,这里的主干路上也没有ReLU。
(5)第四个不同点
在Iresnet50中:

在第1个bottleneck之后的botleneck使用的就是上述所示的结构,即bn+relu+conv的组合。在主干路上同样没有ReLU。
(6) 第五个不同点
每一组中的最后一个bottleneck,在(5)的基础上在主干路上增加一个BN+ReLU。
构造残差块的方式就如Fig 1所示:

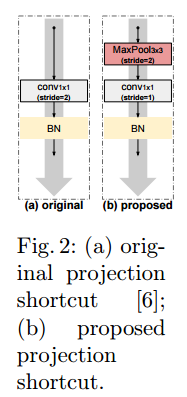
针对于downsampling的改进就是下图所示:
除此之外,还借鉴了ResNeXt的思想,同时将bottleneck中通道的增减顺序颠倒过来,即先利用1×1卷积增加通道,最后在进行减少通道。
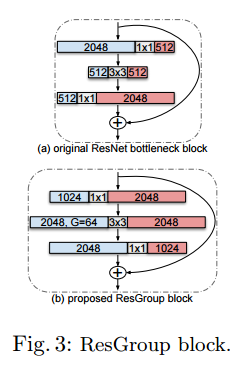
使用了ResGrou block的网络结构如下所示:

知道了其实怎么做的,接下来就是解决为什么它要这么做?
1、为什么在原始ResNet中每一组残差块的前中部分的主干上都不使用ReLU?
这个位置的ReLU会让负权值清零,对信息传播带来负面影响,特别是在网络刚开始训练的时候,会存在很多负权值、
2、pre-act比原始ResNet更易于优化,为什么还要对pre-act ResNet的模块进行改动?
(1)直连通道上没有BN,使得全信号通道上没有归一化,增加了学习的难度
(2)四个残差组之间都是以1个1×1卷积结束,几个block之间缺少非线性,限制了学习的能力。
因此在每一组中最后一个bottleneck的主干上加一个ReLU+BN。
3、为什么要对下采样层进行改进?
因为使用1×1的步长为2的卷积会丢失75%的重要信息,而余下的25%的信息也没有设计什么有意义的标准,会对主干路上的流信息造成负面影响。
4、为什么使用本文的方式进行下采样层的改造?
改造后将考虑来自特征映射的所有信息,并在下一步中选择激活度最高的元素,减少了信息的损失。同时,conv3×3可以视为软下采样,3×3max pooling可以视为硬下采样,两种方式优势可以互补。硬下采样有助于选择激活度最高的元素,软下采样有助于不丢失所有空间信息,有利于更好的定位。
5、为什么要设计ResGroup?
原始bottleneck中先使用1×1卷积减少通道数目,再使用3×3卷积操作,最后使用1×1卷积增加通道数目。而botleneck的核心是3×3卷积, 3×3卷积可操作的通道数目太少会削弱网络的学习能力,因此考虑先增加通道,最后再进行减少。为了减少参数和浮点计算量采用分组卷积的方式。
最终结果就不一一说明了,直接上图:
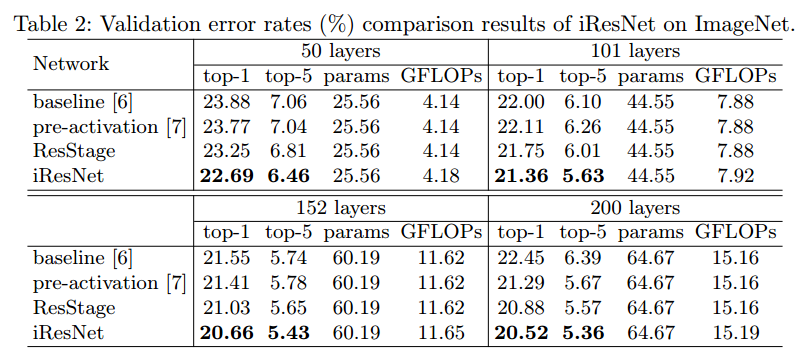
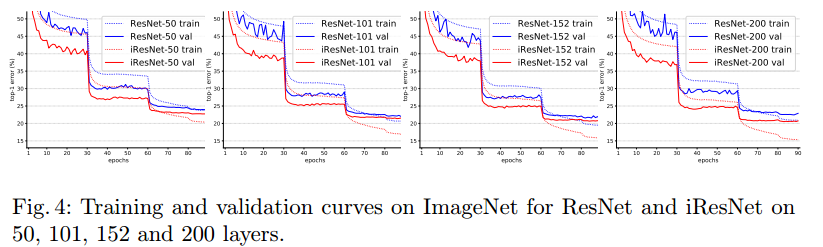
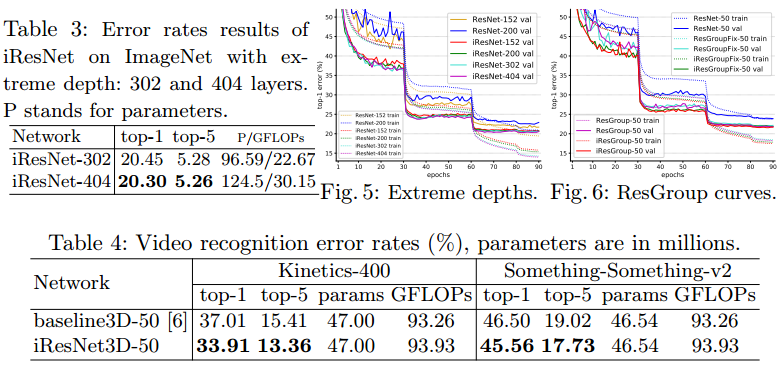

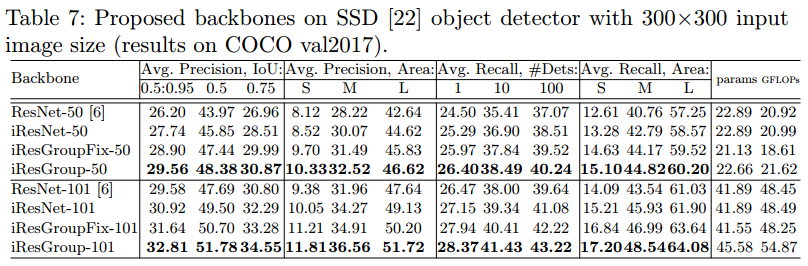
后面还有一些就不粘了,感兴趣的可以去看原论文。需要注意的是该方法成功唉cifar10/cifar100上训练出了一个3002层的网络,在imagenet上成功训练出404层的网络。虽然一味的增加网络的深度并不是有效的,但是在将来的某一天,更深的网络也许会找到其适合的任务。
如有错误,欢迎指出。