一、列表(list)
- 列表是Python中的一个对象
- 对象(object)就是内存中专门用来存储数据的一块区域
- 之前我们学习的对象,像数值,它只能保存一个单一的数据
- 列表中可以保存多个有序的数据
- 列表是用来存储对象的对象
- 列表的使用:
1.列表的创建
(1)通过中括号[]来创建列表,my_list = [] #创建 一个空列表
(2)列表中存储的数据称为元素
(3)一个列表中可以存储多个元素,也可以在创建列表时,来指定列表中的元素
(4)当向列表中添加多个元素时,多个元素之间使用逗号(,)隔开
my_list = [10,20,30,40,50] print(my_list)
(5)列表中可以保存任意的对象
my_list = [10,'hello',None,40,50] print(my_list)
(6)列表中都会按照插入的顺序存储到列表中
(7)我们可以通过索引(index)来获取列表中的元素
索引是元素在列表中的位置,列表中的每一个元素都有一个索引,第一个位置的索引为0,第二个位置的索引为1...
通过索引来获取列表的元素
- 语法:my_list[索引] my_list[0]
my_list[10,'hello',None,40,50] print(my_list[0]) #打印结果为10
- 如果使用的索引超过了最大范围,会抛出异常
(8)获取列表的长度,列表中元素的个数
len()函数,通过该函数可以获取列表的长度
my_list = [10,'hello',None,40,50] print(len(my_list)) #打印结果为5
获取到的长度的值,是列表的最大索引 + 1
2.切片
(1)切片指从现有的列表中,获取一个子列表
(2)创建一个列表,一般创建列表时,变量的名字会使用复数
(3)列表的索引可以是负数
(4)如果索引是负数,则从后向前获取元素,-1表示倒数第一个,-2表示倒数第二个,以此类推
(5)通过切片来获取指定的元素
- 语法:列表[起始:结束]
my_lists = [10,'hello',None,40,50] print(my_lists[0:2]) #只打印10,hello
- 通过切片获取元素时,会包括起始位置的元素,不会包括结束位置的元素
- 做切片操作时,总会返回一个新的列表,不会影响原来的列表
- 起始和结束位置的索引都可以省略不写
如果省略结束位置,则会一直截取到最后
如果省略开始位置,则会从第一个元素开始截取
如果起始位置和结束位置全部省略,则相当于创建了一个列表的副本
(6)步长
- 语法:列表[起始:结束:步长]
- 步长表示,每次获取元素的间隔,默认值是1
- 步长不能是0,但是可以是负数
如果是负数,则会从列表的后部向前截取元素
3.操作列表的数据
(1)+ 和 *
+ 号可以将两个列表拼接为一个列表
my_list = [1,2,3] + [4,5,6] print(my_list) #打印结果为1,2,3,4,5,6
* 号可以将列表重复指定的次数
my_list = [1,2,3] * 5 print(my_list) # 打印结果为1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3
(2)in 和 not in
in用来检查指定元素是否存在于列表中,如果存在返回true,否则返回false
my_list = [1,2,3] * 5 print(1 in my_list) #返回true
not in用来检查指定元素是否并不存在于列表中,如果存在返回false,否则返回true
my_list = [1,2,3] * 5 print(1 not in my_list) #返回false
(3)len()获取列表元素的个数
my_list = [1,2,3] * 5 print(len(my_list)) # 打印结果为15
(4)min()获取列表元素的最小值
my_list = [1,2,3] * 5 print(min(my_list)) # 打印结果为1
(5)max()获取列表元素的最大值
my_list = [1,2,3] * 5 print(max(my_list)) # 打印结果为3
两个方法(method),方法和函数基本是一样,只不过方法必须通过对象.方法()的形式调用
xxx.print()方法实际上就是和对象关系紧密的函数
1)s.index()获取指定元素在列表中第一次出现时的索引
index()第2个参数,表示查找的起始位置,第3个参数表示查找的结束位置
如果要获取列表中没有的元素,则会抛出异常
2)s.count()
s.count()是统计元素在列表中出现的次数
二、序列(sequence)
序列是Python中最基本的一种数据结构
数据结构指计算机中数据存储的一种方式
序列用于保存一组有序的数据,所有的数据在序列中都有唯一的位置(索引)
并且序列中的数据会按照添加的顺序来分配索引
序列的分类:
(1)可变序列(序列中元素可以改变):
列表(list)
(2)不可变序列(序列中元素不可以改变):
字符串(str)
元祖(tuple)
前面我们讲的列表的所有操作都是序列的通用操作
三、修改列表的元素
1.通过索引直接修改列表元素
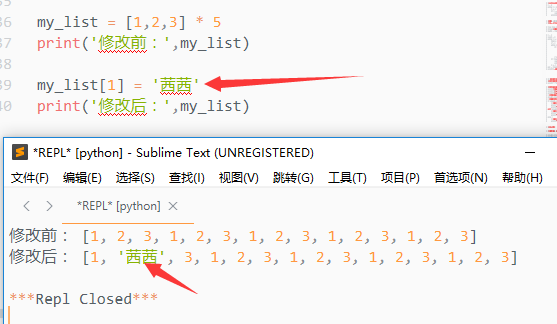
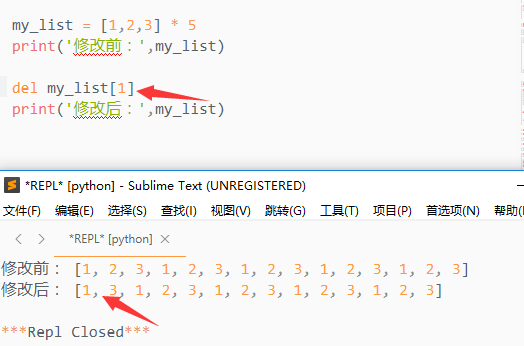
可通过del来删除元素
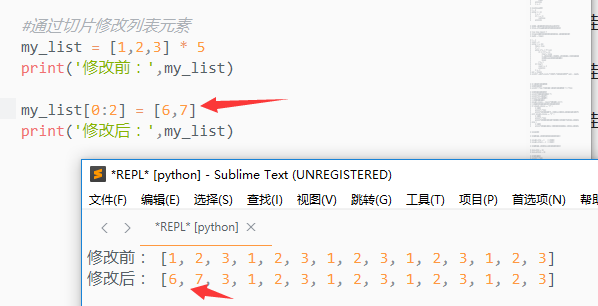
2.通过切片来修改列表元素
在给切片赋值时,只能使用序列
在替换时,可以替换多个元素
向索引为0的位置插入元素(在前插入一个新元素):my_list[0:0]=[555]
当设置了步长时,序列中元素的个数必须和切片中元素的个数一致: my-list[::2] = [7,8,9]
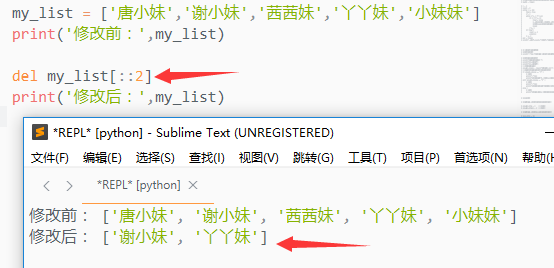
通过切片来删除元素:del my_list[::2]
注意:
以上操作只针对于可变序列
若要对不可变序列进行修改,先将其转化为可变序列
方法:s = list(s)
3.列表的方法
(1)插入
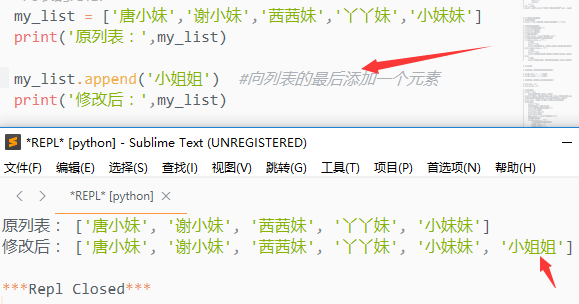
1)s.append()
向列表的最后添加一个元素
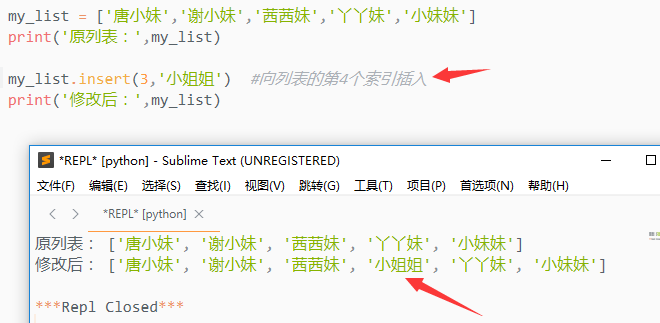
2)s.insert(i,x)
向列表的指定位置插入一个元素,i 代表位置,x代表插入的元素
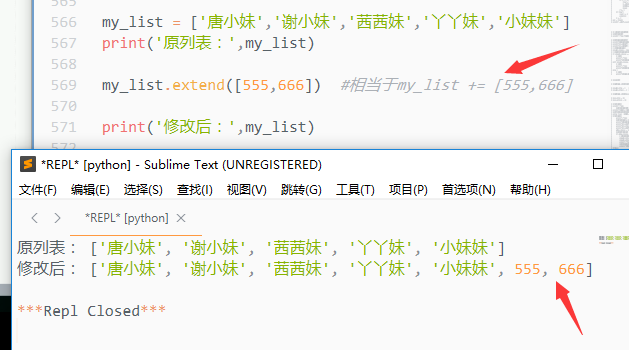
3)s.extend([t])
使用新的序列来扩展当前序列
需要一个序列作为参数,它会将该序列中的元素添加到当前列表中
与append()区别:
append()是传一个元素,而extend([])是传一个列表(多个元素)
(2)删除
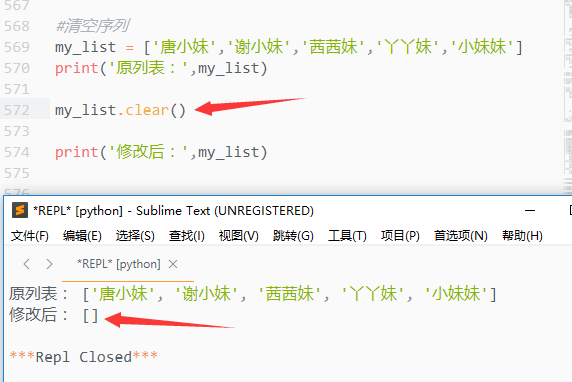
1)clear()
清空序列
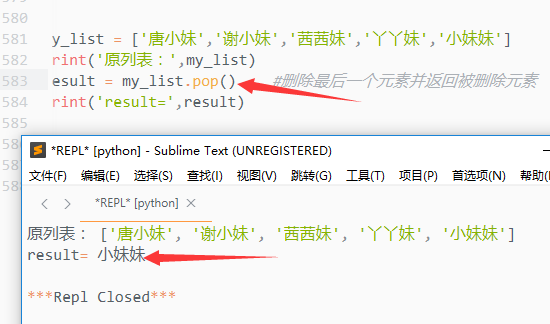
2)pop()
根据索引删除并返回被删除元素
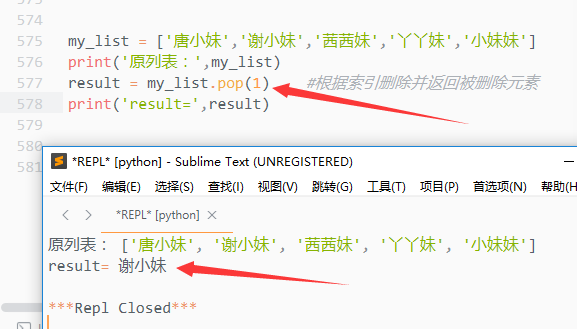
如果没有指定删除元素,默认删除最后一个元素
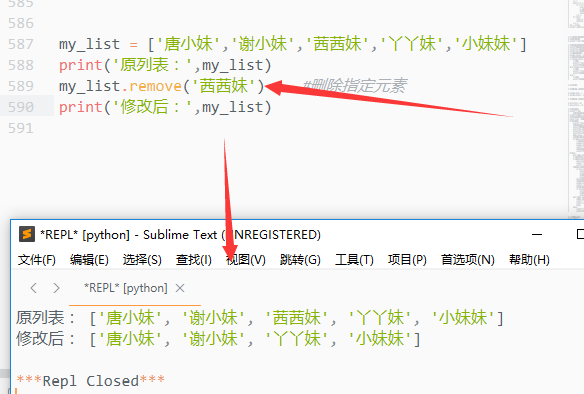
3)remove()
删除指定元素
如果相同值的元素有多个,只会删除第一个
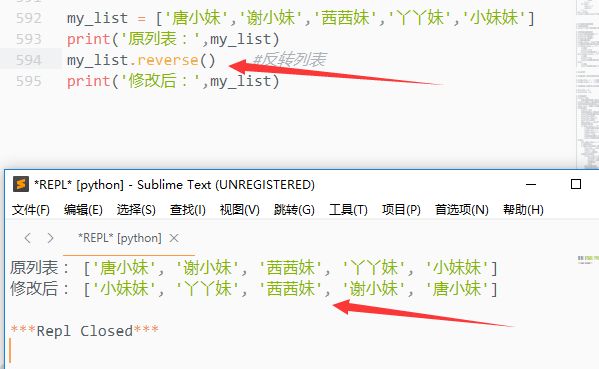
4)reverse()
反转列表
4)sort()
对列表中元素进行排序(默认是升序排列)
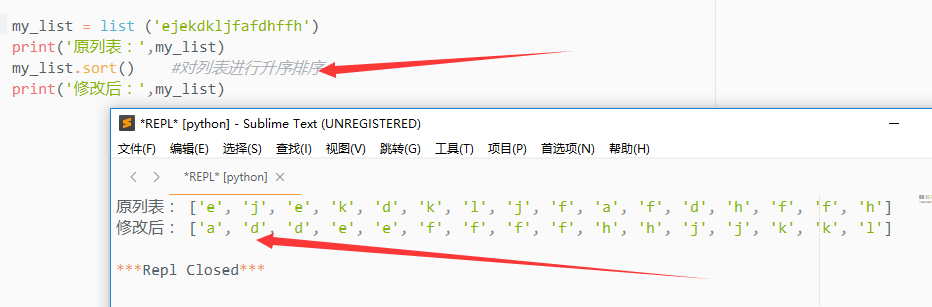
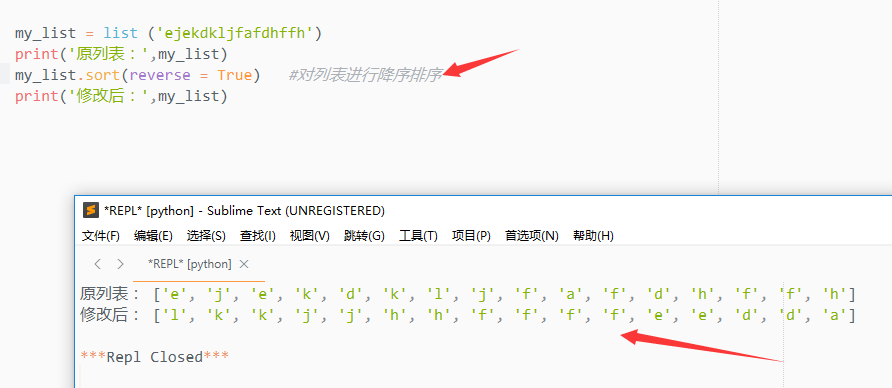
修改排列方式为降序
四、遍历列表
遍历列表,指的就是将列表中的所有元素取出来
1.通过while循环来遍历列表
i = 0 my_list = ['唐小妹','谢小妹','茜茜妹','丫丫妹','小妹妹'] while i < len(my_list): #采用len()输出所有元素长度 print(my_list[i]) #打印列表所有元素 i += 1
2.通过for循环来遍历列表
语法:
for 变量 in 序列 : 代码块
for循环的代码块会执行多次,序列中有几个元素就会执行几次
每执行一次,就会将序列中的一个元素赋值给变量
可以通过变量,来获取列表中的元素
# 通过for循环来遍历列表 my_list = ['唐小妹','谢小妹','茜茜妹','丫丫妹','小妹妹'] for i in my_list : print(my_list)
五、range()函数
range()可以用来生成一个自然数的序列
s = range(5) print(list(s)) #打印结果为0,1,2,3,4
该函数需要三个参数
- 起始位置(可以省略,默认是0)
- 结束位置
- 步长(可以省略,默认是1)
s = range(0,9,3) print(list(s)) #打印结果为0,3,6
通过range()可以创建一个指定次数的for循环
for循环除了创建方式以外,其余都和while一样
像else、break、continue都可以在for循环中使用
#通过range()可以创建一个指定次数的for循环
for i in range(30): print(i) #打印结果为0到30的自然数
六、元祖tuple(不可变序列)
元祖是不可变的序列,操作方式基本和列表一致
在操作元祖时,当成是一个不可变的列表就行了
一般当我们希望数据不改变时,使用元祖,其他情况都使用列表
元祖是不可变对象,不能尝试为元祖的元素重新赋值
当元祖元素不是空元素时,括号可以省略,若元祖元素不是空元祖,里边至少要有一个逗号
my_tuple = () #空元祖
print(my_tuple,type(my_tuple)) #打印结果为() <class 'tuple'>
my_tuple = 1,2,3,4,5 #非空元祖使用逗号隔开 print(my_tuple) #打印结果为(1, 2, 3, 4, 5)
元祖的解包(解构):
解包指将元祖的每个元素都赋值给变量
my_tuple = 1,2,3,4 a,b,c,d = my_tuple print('a=',a) print('b=',b) print('c=',c) print('d=',d) #打印结果为: a= 1 b= 2 c= 3 d= 4
#交换ab的值 a = 10 b = 20 a,b = b,a print(a,b)
在对元祖进行解包时,变量的数量必须和元祖的数量一致
也可以在变量前面添加一个*号,这样变量将会获取元祖中所有剩余的元素
my_tuple = 10,20,30,40 a,b,*c = my_tuple print(a,b,c) 打印结果为10 20 [30, 40]
注意:不能出现两个或两个以上的*号变量
七、可变对象
每个对象中都保存三个数据:
id(标识)
type(类型)
value(值)
- 可变是指的值可变。
- 列表就是一个可变对象
a[0] = 10 #通过变量修改对象的值,这种操作不会改变变量所指向的对象,id不变 a = [4,5,6] #给变量重新赋值,这种操作会改变变量所指向的对象,id改变
- 当修改对象时,如果有其他变量也指向该对象,则修改也会在其他变量中体现
- 为一个变量重新赋值时,不会影响其它变量
一般只有在为变量赋值时,才是修改变量,其余的都是修改对象
== 和 !=比较的是对象的值是否相等 is 和 is not 比较的是对象的id是否相等(比较两个对象是否是同一个对象)
八、字典(dictionary)
字典属于一种新的数据结构,称为映射(mapping)
字典的作用和列表类似,都是用来存储对象的容器
列表存储数据的性能很好,但是查询数据的性能很差
在字典中,每一个元素都有一个唯一的名字,通过这个唯一的名字可以快速查找到指定的元素
在查询元素时,字典的效率是非常快的
在字典中可以保存多个对象,每一个对象都有一个唯一的名字
- 这个唯一的名字称为键(key),通过key可以快速的查找value
- 这个对象,我们称其为值(value)
- 所以字典,我们也称为键值对(key-value)结构
- 每个字典都可以有多个键值对,而每一个键值对我们都称其为一项(item)
1.语法:
{key:value,key:value,key:value,key:value}
字典的值可以是任意对象
字典的键可以是任意的不可变对象(int、str、bool、tuple...),但是一般使用字符串
- 字典的键是唯一的不能重复的,如果出现重复,后边 会替换前面的
d = {'name':'刘茜茜','age':18,'gender':'女'}
print(d,type(d)) #打印结果为{'name': '刘茜茜', 'age': 18, 'gender': '女'} <class 'dict'>
根据键来获取值
d = {'name':'刘茜茜','age':18,'gender':'女'}
print(d['name']) #获取name的值,打印结果为刘茜茜
如果使用了字典中不存在的键,会抛出异常
2.字典的使用
(1)获取的方法
1)使用dict()函数来创建字典
# 使用dict()函数来创建字典 d = dict(name='刘茜茜',age=18,gender='女') print(d) #打印结果为{'name': '刘茜茜', 'age': 18, 'gender': '女'}
每一个参数都是一个键值对,参数名就是键,参数值就是值(这种方式创建的字典,key都是字符串)
也可以将一个包含有双值子序列的序列转换为字典
双值序列,序列中只有两个值,[1,2] 、 ('a',4) 、 'ab'
子序列,如果序列中的元素也是序列,那么我们就称这个元素为子序列
[(1,2),(3,5)]
d = dict([('name','茜茜妹'),('age',12)]) print(d) #打印结果为{'name': '茜茜妹', 'age': 12}
2)len()获取字典中键值对的个数
d = dict([('name','茜茜妹'),('age',12)]) print(len(d)) #打印结果为2
3)in和not in
in是检查字典中是否包含指定的键
not in是检查字典中是否不包含指定的键
#in的用法
d = dict([('name','茜茜妹'),('age',12)]) print('刘茜茜'in d) #打印结果为false
#not in的用法 d = dict([('name','茜茜妹'),('age',12)]) print('刘茜茜' not in d) #打印结果为true
4)根据键值来获取字典中的值
1' 语法:d[key]
通过[]来获取值时,如果不存在就会抛出异常keyError
d = dict([('name','茜茜妹'),('age',12)]) print(d['name']) #打印结果为茜茜妹
注意:变量不加引号,字符串加引号
2' 语法:s.get(key[,default])
与前面一个区别在于,如果获取的值不存在,会返回None
d = dict([('name','茜茜妹'),('age',12)]) print(d.get('刘茜茜')) #打印结果为None
也可以指定一个默认值来作为第二个参数,这样获取不到值时,将会返回默认值
d = dict([('name','茜茜妹'),('age',12)]) print(d.get('hello','刘茜茜')) #因为hello不存在,所以打印结果为刘茜茜,如果存在,打印茜茜妹
(2)修改的方法
1)d[key] = value
如果key存在则覆盖 ,不存在则添加
d = dict([('name','茜茜妹'),('age',12)]) d['name'] = '刘茜茜' print(d) #打印结果为{'name': '刘茜茜', 'age': 12}
2)s.setdefault(key[,default])
可以用来向字典中添加key-value
- 如果key已经存在于字典中,则会返回key的值,不会对字典做任何操作
- 如果key不存在,则向字典中添加这个key,并设置value
d = dict([('name','茜茜妹'),('age',12)]) d.setdefault('学名','刘茜茜') #'学名'不存在,所以进行添加操作 print(d) #打印结果为{'name': '茜茜妹', 'age': 12, '学名': '刘茜茜'}
3)s.update([other])
将其他的字典中的key-value添加到当前字典中
d1 = {'a':1,'b':2,'c':3}
d2 = {'d':4,'e':5,'f':6}
d1.update(d2) # 将字典d2添加到字典d1中
print(d1) # 打印结果为{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6}
如果other字典中key与当前字典重复,则直接覆盖当前字典的key-value
d1 = {'a':1,'b':2,'c':3}
d2 = {'d':4,'e':5,'f':6,'a':7} # a的值与d1字典重复,直接覆盖d1的值
d1.update(d2) # 将字典d2添加到字典d1中
print(d1) # 打印结果为{'a': 7, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6}
(3)删除的方法
1)del s[key]
d = {'a':1,'b':2,'c':3}
del d['a'] # 删除d字典中a的值
print(d) # 打印结果为{'b': 2, 'c': 3}
2)s.popitem()
随机删除字典中的键值对,一般都会删除最后一个键值对
d = {'d':4,'e':5,'f':6}
d.popitem()
print(d) #打印结果为{'d': 4, 'e': 5}
删除之后,它会将删除的key-value作为返回值返回
返回的是一个元祖,元祖中有两个元素,第一个元素是删除的key,第二个元素是删除的value
当使用s.popitem()删除空字典时,会抛出异常
3)s.pop()
根据key删除字典中的key-value
d = {'d':4,'e':5,'f':6}
d.pop('e')
print(d) #打印结果为{'d': 4, 'f': 6}
会将被删除的value返回
如果删除不存在的key,会抛出异常
如果指定了默认值,再删除不存在的key时,不会报错,而是直接返回默认值
4)s.clear()
用来清空字典,删除字典所有项
5)s.copy()
用于对字典进行浅复制
复制以后的对象与原对象是相互独立的,不会相互影响
浅复制只会复制对象里面的值,如果值也是一个可变对象,这个可变对象不会被复制
九、遍历字典
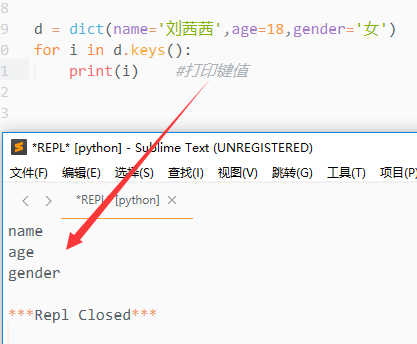
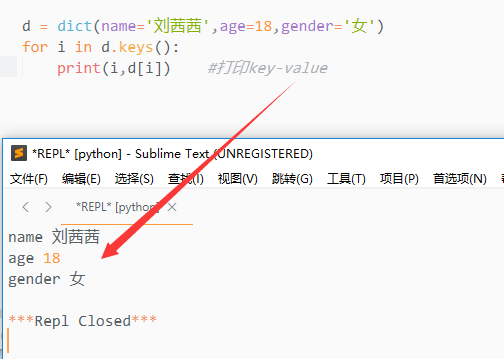
1.keys()
该方法会返回字典所有的key
d = dict(name='刘茜茜',age=18,gender='女') result = d.keys() print(result) #打印结果为dict_keys(['name', 'age', 'gender'])
该方法会返回一个序列,序列中保存有字典的所有的键
通过遍历keys()来获取所有的键值
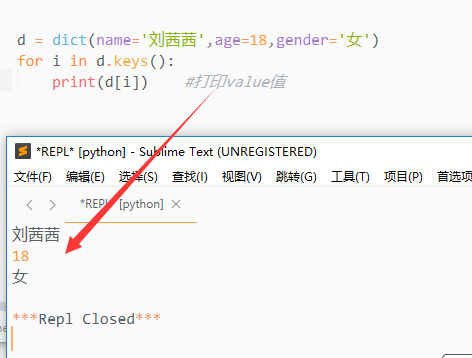
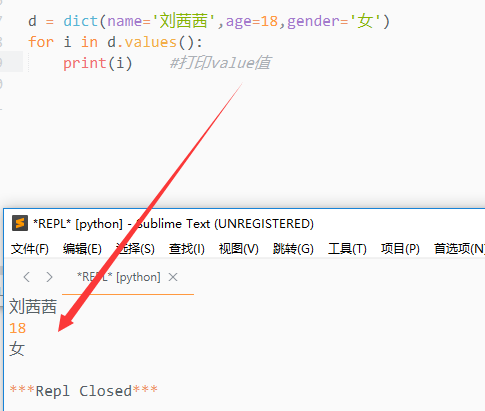
2. s.values()
该方法会返回一个序列,序列中保存有字典的所有的值
3.s.items()
返回字典中所有的项
会返回一个序列,序列中包含双值子序列
双值分别是字典中的key和value
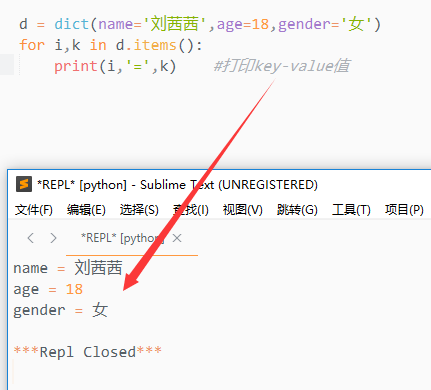
注意:这里返回的是两个值,所以我们需要用两个变量去接收它(我使用的是i , k)
十、集合(set)
集合和列表非常相似,都是直接把值存储起来
集合与列表不同点:
- 集合中只能存贮不可变对象
- 集合中存储的对象是无序的(不是按照元素的插入顺序保存)
- 集合中不能出现重复的元素(集合中的元素都是唯一的)
1.集合的使用
(1)使用{}来创建集合
s = {1,2,30,4,50}
print(s,type(s)) #打印结果为{1, 2, 4, 50, 30} <class 'set'>
(2)使用set()函数来创建集合
可以通过set()来将序列和字典转化为集合
s = set([1,2,3,456,6,7,8]) #将列表转化为集合,打印结果为{1, 2, 3, 6, 7, 456, 8} <class 'set'> s = set('hello') #将序列转换为集合,打印结果为{'l', 'o', 'h', 'e'} <class 'set'> s = set({'a':1,'b':2,'c':3}) #将序列转换为集合,打印结果为{'c', 'b', 'a'} <class 'set'> print(s,type(s))
注意:使用set()函数将字典转换为集合时,只会包含字典中的键。
不能使用索引去创建集合,须先转换为列表
(3)in和not in来检查集合中的元素
s = set([1,2,3,456,6,'f',8]) print('f' in s) #打印结果为True print(1 not in s) #打印结果为False
(4)使用len()来获取集合中元素的数量
s = set([1,1,2,3,456,6,'f',8]) result = len(s) #获取集合的数量 print(result) #打印结果为7,因为有重复的,所以会默认是1个
(5)add()向集合中添加元素
s = {1,1,2,3,456,6,'f',8}
s.add('xixi') #向集合中添加元素
print(s) #打印结果为{1, 2, 3, 6, 456, 8, 'f', 'xixi'}
(6)update()将一个集合的元素添加到当前集合中
update()可以将一个集合中的元素添加到当前集合中
update()可以传递序列或字典作为参数,字典只会使用键
#向集合中传集合
s = set('hello') s2 = set('茜茜') s2.update(s) #把s中的元素添加到s2中 print(s2) #打印结果为{'l', 'e', 'o', 'h', '茜'}
# 向集合中传序列 s = set('hello') s2 = set((10,20,30,40,50)) s2.update(s) #把s中的元素添加到s2中 print(s2) #打印结果为{40, 10, 'o', 'l', 50, 20, 'h', 'e', 30}
# 向集合中传字典 s = set('hello') s2 = set({'a':1,'b':2,'c':3}) s2.update(s) #把s中的元素添加到s2中 print(s2) #打印结果为{'a', 'b', 'e', 'l', 'h', 'o', 'c'}
(7)pop()随机删除一个集合中的元素
随机删除并返回一个集合中的元素
# 随机删除集合中的元素 s = set('hello') a = s.pop() #随机删除s中的元素 print('删除的元素a =',a) #打印结果为删除的元素a = h print(s) #打印结果为{'e', 'o', 'l'}
(8)remove()删除集合中指定的元素
# 删除集合中指定的元素 s = set('hello') a = s.remove('e') #随机删除s中的指定的元素e print('删除的元素a =',a) #打印结果为删除的元素a = None print(s) #打印结果为{'l', 'o', 'h'}
(9)clear()清空集合
#清空集合 s = set('hello') s.clear() #清空集合 print(s) #打印结果为set()
(10)copy()对集合进行浅复制
#对集合进行浅复制 s = set('hello') a = s.copy() #浅复制集合s print(a) #打印结果为{'l', 'e', 'o', 'h'} print(s) #打印结果为{'l', 'e', 'o', 'h'}
2.集合的运算
在对集合做运算时,不会影响原来的集合,而是返回一个运算结果
(1)&交集运算
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}
result = s1 & s2 #对两个集合进行交集运算
print(result) #打印结果为{4, 5}
(2)| 并集运算
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}
result = s1 | s2 #对两个集合进行并集运算
print(result) #打印结果为{1, 2, 3, 4, 5, 6, 7, 8}
(3)- 差集运算
差集:只找第一个集合有的但是第二个集合没有的元素
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}
result = s1 - s2 #对两个集合进行差集运算
print(result) #打印结果为{1, 2, 3}
(4)^ 异或集
异或: 获取不相交的集合元素
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}
result = s1 ^ s2 #对两个集合进行异或运算
print(result) #打印结果为{1, 2, 3, 6, 7, 8}
(5)<= 检查一个集合是否是另一个集合的子集
如果a集合中元素全部都在b集合中出现,那么a集合就是b集合的子集,b集合是a集合超集
如果a集合与b集合相等,也会返回true
s1 = {1,2,3}
s2 = {1,2,3,4,5}
result = s1 <= s2 #检查s1是否是s2的子集,如果是返回true,否则返回false
print(result) #打印结果为True
(6)< 检查一个集合是否是另一个集合的真子集
如果超集b中含有子集a中的所有元素,并且b中含有a中没有的元素,则b就是a的真超集,a是b的真子集
s1 = {1,2,3}
s2 = {1,2,3,4,5}
result = s1 < s2 #检查s1是否是s2的真子集,如果是返回true,否则返回false
print(result) #打印结果为True
(7)> 检查一个集合是否是另一个集合的超集
如果超集b中含有子集a中的所有元素,并且b中含有a中没有的元素,则b就是a的真超集,a是b的真子集
s1 = {1,2,3}
s2 = {1,2,3,4,5}
result = s2 > s1 #检查s2是否是s1的真超集,如果是返回true,否则返回false
print(result) #打印结果为True