原文链接https://www.cnblogs.com/luweiseu/archive/2012/07/14/2591573.html
作者:wlu
7. 网络流算法--Ford-Fulkerson方法及其多种实现
网络流
在上一章中我们讨论的主题是图中顶点之间的最短路径,例如公路地图上两地点之间的最短路径,所以我们将公路地图抽象为有向带权图。本章我们将对基于有向带权图的模型做进一步扩展。
很多系统中涉及流量问题,例如公路系统中车流量,网络中的数据信息流,供油管道的油流量等。我们可以将有向图进一步理解为“流网络”(flow network),并利用这样的抽象模型求解有关流量的问题。
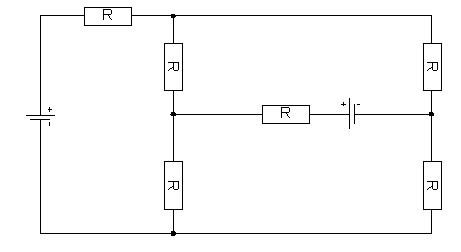
图 电路原理图可抽象为网络流
流网络中每条有向边可以认为是传输物质的管道,每个管道有固定的容量,可以看作是物质能够流经该管道的最大速度。顶点是管道之间的交叉连接点,除了汇点之外,物质只流经这些点,不会再顶点滞留或消耗。也就是说,物质进入某顶点的速度必须等于离开该顶点的速度。这一特性被称为“流守恒”(flow conservation)。例如图中的电路原理图,根据基尔霍夫电流定律,在每个交叉连接点出,流进的电流等于流出的电流。电流的定义为单位时间内通过导线某一截面的电荷量,即为电荷的流动速度。所以,用流守恒的观点可以理解为:电荷量流进某交叉顶点的速度等于离开该顶点的速度。
在本章我们将讨论最大流问题,这是流网络中最简单的问题:在不违背容量限制的条件下,求解把物质从源点传输到汇点的最大速率。本章主要介绍流网络和流的基本概念和性质,并提供流网络的数据结构描述和实现,以及一种解决最大流的经典方法及其算法实现,即Ford-Fulkerson方法。
.1 流网络
网络流G=(v, E)是一个有向图,其中每条边(u, v)均有一个非负的容量值,记为c(u, v) ≧ 0。如果(u, v) ∉ E则可以规定c(u, v) = 0。网络流中有两个特殊的顶点,即源点s和汇点t。
与网络流相关的一个概念是流。设G是一个流网络,其容量为c。设s为网络的源点,t为汇点,那么G的流是一个函数f:V×V →R,满足一下性质:
l 容量限制:对所有顶点对u,v∈V,满足f(u, v) ≦ c(u, v);
l 反对称性:对所有顶点对u,v∈V,满足f(u, v) = - f(v, u);
l 流守恒性:对所有顶点对u∈V-{s, t},满足Σv∈Vf(u,v)=0。
f(u, v)称为从顶点u到顶点v的流,流的值定义为:
|f| =Σv∈Vf(s,v),
即从源点s出发的总的流。
在最大流问题中,我们需要求解源点s到汇点t之间的最大流f(s, t),同时我们还希望了解达到该值的流。对于一个指定的源点s和指定汇点t的网,我们称之为st-网。
如图所示为一个流网络,其中顶点之间的边的粗细对应着边的容量大小。
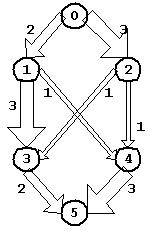
图 有向图表示网络流
下面以图为例,在流的三个性质条件下尝试性地寻找图中的最大流,如图(a~c)。
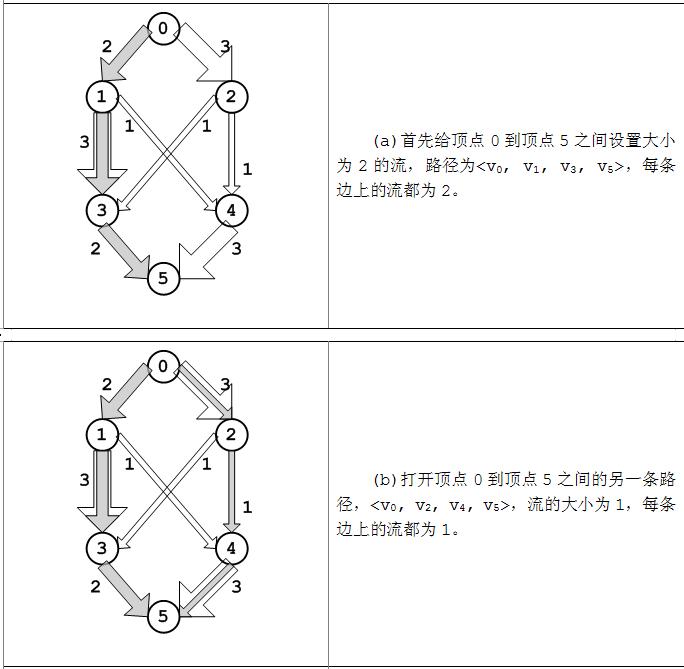
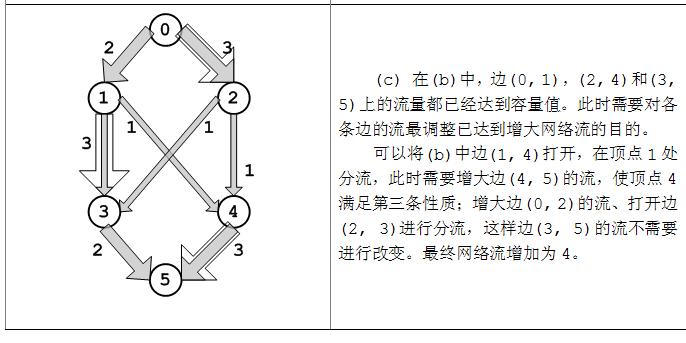
从上图(a~c)中可以发现,流网络从源点s流出的量依次为2,3,5,而流入汇点t的流量也2,3,5。事实上,任何流从s流出量总应该等于到汇点t的流入量,下面对这一命题做简单证明。

构造:如图(a),对原流网络做扩展,增加顶点s’和一条边(s’, s),边的流和容量都与从s流出的流的值相等;增加顶点t’和一条边(t, t’),边的流和容量都与到t的流的值相等。
我们要证明s’的流出量等于t’的流入量,只要证明对任意顶点集合,流出量等于流入量即可。采用归纳证明。
证明:对于单个顶点构成的顶点集合,其流出量必然等于流出量;假设,对于一给定的顶点集合A此属性成立,则需要验证增加一个顶点v后得到的新的集合A’=A∪{v}也满足此属性。
如图,对集合A,从v流入的流记为f3,其它的流入量合计为f1;流出到v的流记为f4,其它的流出流量合计为f6。注意,这里的流都指的是流的值,都是非负的。
A的流入量为fin(A) = f1 + f3,流出量为fout(A) = f2 + f4;根据假设可以得出关系:
f1 + f3 = f2 + f4;
对顶点v,根据流的第二条性质,得出关系:
f6 + f3 = f5 + f4。
根据上面两个等式,可以得到关系:
f1 – f6 = f2 – f5,
即:
f1 + f5 = f2 + f6。
A’的流入量fin(A’) = f1 + f5,流出量fout(A’) = f2 + f6,所以集合A’满足属性。
将这个属性应用于扩展前的原始流网络中的所有顶点,可以得出边(s’, s)上的流等于边(t’, t)上的流,也就是从s流出量等于到汇点t的流入量。
.2 Ford-Fulkerson方法
本节开始讨论解决最大流问题的Ford-Fulkerson方法,该方法也称作“扩充路径方法”,该方法是大量算法的基础,有多种实现方法。在以后章节中我们将介绍并分析一种特定的算法。
Ford-Fulkerson算法是一种迭代算法,首先对图中所有顶点对的流大小清零,此时的网络流大小也为0。在每次迭代中,通过寻找一条“增广路径”(augument path)来增加流的值。增广路径可以看作是源点s到汇点t的一条路径,并且沿着这条路径可以增加更多的流。迭代直至无法再找到增广路径位置,此时必然从源点到汇点的所有路径中都至少有一条边的满边(即边的流的大小等于边的容量大小)。
这里提及一个新的概念,即“增广路径”。下面我们将进一步引入“残留网络”(residual network)来讨论增广路径的寻找算法,并引入“最大流最小割”(Max-Flow Min Cut)定理来证明Ford-Fulkerson算法的正确性。
.2.1 残留网
给定一个流网络G和一个流,流的残留网Gf拥有与原网相同的顶点。原流网络中每条边将对应残留网中一条或者两条边,对于原流网络中的任意边(u, v),流量为f(u, v),容量为c(u, v):
l 如果f(u, v) > 0,则在残留网中包含一条容量为f(u, v)的边(v, u);
l 如果f(u, v) < c(u, v),则在残留网中包含一条容量为c(u, v) - f(u, v)的边(u, v)。
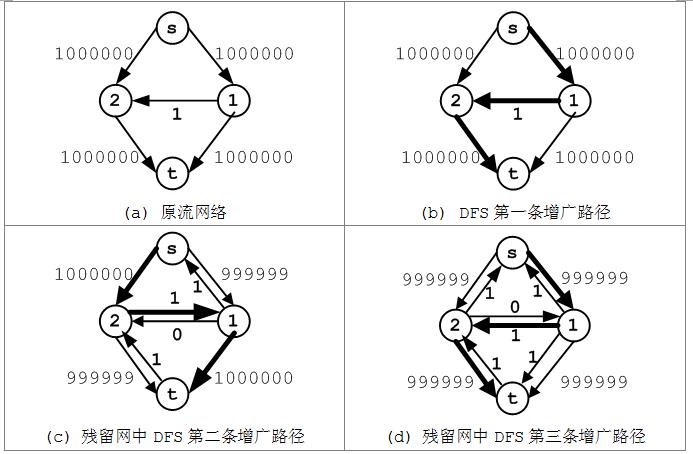
残留网允许我们使用任何广义图搜索算法来找一条增广路径,因为残留网中从源点s到汇点t的路径都直接对应着一条增广路径。以图为例,具体分析增广路径及其相应残留网,如图(a~d)。
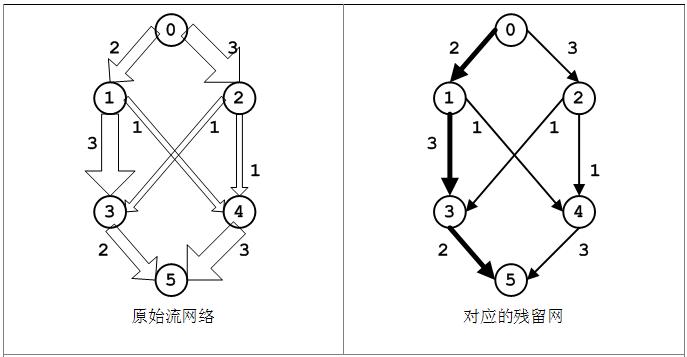
(a)原始图流网络,每条边上的流都为0。因为f(u, v) = 0 < c(u, v),则在残留网中包含容量为c(u, v)的边(u, v),所以此时残留图中顶点与原始流网络相同,边也与原始流网络相同,并且边的容量与原始流网络相同。
在残留网中可以找到一条增广路径<v0, v1, v3, v5>,每条边的流为2,此原始流网络和残留网中相应的边会有所变化,如下图。
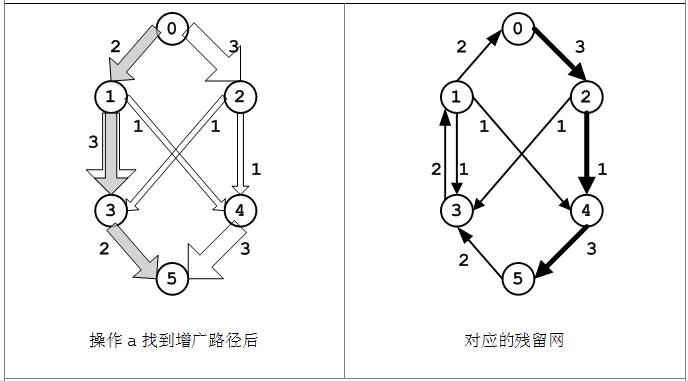
(b)在操作(a)之后,路径<v0, v1, v3, v5>上有了大小为2的流,此时需要对残留图中相应的边做调整:
f(0, 1) > 0,在残留图中有容量为2的边(1, 0);
c(1, 3) > f(1, 3) > 0,在残留图中有容量为1的边(1, 3)和容量为2的边(3, 1);
f(3, 5) > 0,在残留图中有容量为2的边(5, 3).
在残留网中可以找到一条增广路径<v0, v2, v4, v5>,每条边的流为1,此原始流网络和残留网会有所变化,如下图。
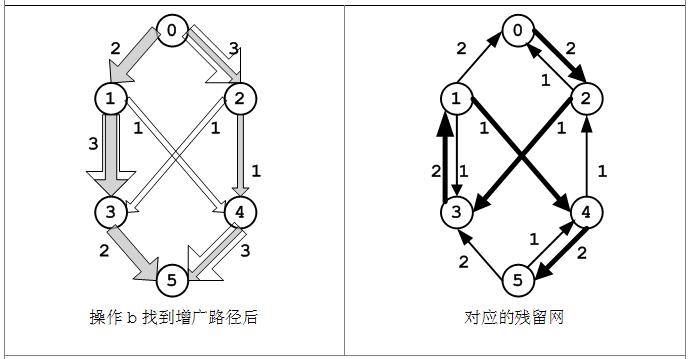
(c)在操作(b)之后,路径<v0, v2, v4, v5>上有了大小为1的流,此时需要对残留图中相应的边做调整:
c(0, 2) > f(0, 2) > 0,在残留图中有容量为2的边(0, 2)和容量为1的边(2, 0);
f(2, 4) > 0,在残留图中有容量为1的边(4, 2);
c(4, 5) > f(4, 5) > 0,在残留图中有容量为2的边(4, 5)和容量为1的边(5, 4).
进一步在残留网中可以找到一条增广路径<v0, v2, v3, v1, v4, v5>,每条边的流为1,此原始流网络和残留网会有所变化,如下图。
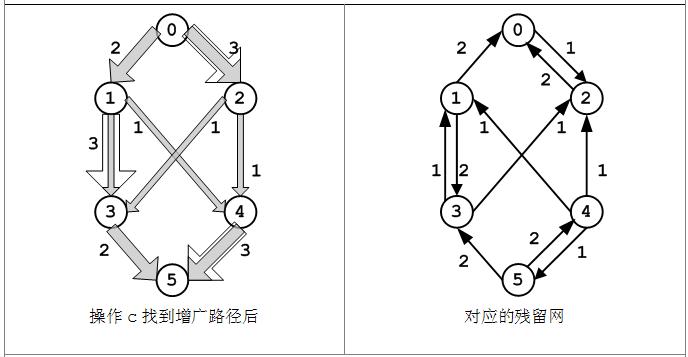
(d)在操作(c)之后,路径<v0, v2, v3, v1, v4, v5>上有了大小为1的流,此时需要对残留图中相应的边做调整:
c(0, 2) > f(0, 2) > 0,在残留图中有容量为1的边(0, 2)和容量为2的边(2, 0);
f(2, 3) > 0,在残留图中有容量为1的边(3, 2);
c(3, 1) > f(3, 1) > 0,在残留图中有容量为1的边(3, 1)和容量为2的边(1, 3);
f(1, 4) > 0,在残留图中有容量为1的边(4, 1);
c(4, 5) > f(4, 5) > 0,在残留图中有容量为1的边(4, 5)和容量为2的边(5, 4);
此时残留图中无法再找到顶点0到顶点5的路径,则迭代结束,我们认为图d中即为寻找到的最大流。
2 最大流最小割
我们刚刚讨论了基于残留网的增广路径的寻找方法,这里我们将证明Ford-Fulkerson算法迭代停止时得到的流是最大流,即一个流是最大流,当且仅当残留网中不包含增广路径。该命题的证明需要借助于流网络中的一个重要定理,即最大流最小割定理。
流网络G=(V, E)的割(S, T)将V分为S和T=V-S两个部分,使得源点s∈S,汇点t∈T。如果f是一个流,则穿过割(S, T)的流用f(S, T) = Σu∈SΣv∈T f(u, v)表示,割(S, T)的容量用C(S, T) = Σu∈SΣv∈T c(u, v)。如图,流网络的一个割为({s, v1, v2},{v3, v4, t})
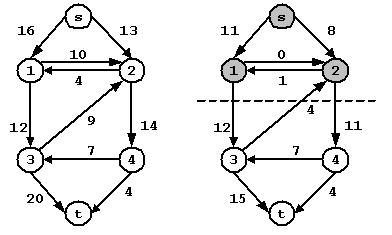
图 (a)流网络每条边上是容量大小 (b)流网络的一个割,边上是流的大小
通过该割的流量为:
f(S, T) = Σu∈{s, v1, v2}Σv∈{v3, v4, t} f(u, v)
= f(v1, v3) + f(v2, v3) + f(v2, v4)
= 12 + (-4) + 11 = 19
容量为:
C(S, T) = Σu∈{s, v1, v2}Σv∈{v3, v4, t} c(u, v)
= c(v1, v3) + c(v2, v4)
= 12 + 14 = 26
其中割的流可能是正数也可能是负数,而容量一定是非负的。在流网络中,每个割的流都是相同的,其值等于流网络的流的值;并且每个割的流都不大于割的容量。
如图,s’为扩展的顶点,其中边(s’, s)的流和容量都等于顶点s的流出量,记为f1。虚线将流网络分为两个集合S和T,形成割(S, T)。从S流出的流量为f2,流入S的流量为f3。在第一节中我们证明了流网络中的顶点集合的流入量等于流出量,所以f1 + f2 = f3。
即f1 = f3 – f2,其中f1等于流网络的流的值,f3-f2为割(S, T)的流量,所以,割的流等于流网络的流的值。
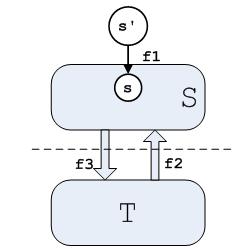
在上图中,计算割(S, T)的流量时f3的提供正的流量值,而f2提供的是负的流量值,并且在计算割的容量时只有提供流量f3的边的容量参与相加,根据流的第一条性质,f3的值不会大于割的容量,所以:
f(S, T) = f3 – f2 ≦ f3 ≦ C(S, T)。
由于流网络中所有割的流都相等并且等于网络的流,所有网络的任何流的值都不大于任何一个割的容量。
根据上面对流网络的中割的概念的介绍,下面引入最大流最小割定理,并利用该定理说明Ford-Fulkerson算法的正确性。
最大流最小割定理:一个网中所有流中的最大值等于所有割中的最小容量。并且可以证明一下三个条件等价:
l f是流网络G的一个最大流;
l 残留网Gf不包含增广路径;
l G的某个割(S, T),满足f(S, T) = c(S, T).
证明:
1.(反证法)假设f是G的最大流,但是Gf中包含增广路径p。显然此时沿着增广路径可以继续增大网络的流,则f不是G的最大流,与条件矛盾;
2.假设Gf中不包含增广路径,即Gf中不包含从s到t的路径。定义:
S = {v∈V:Gf中包含s到v的路径},
令T = V – S,由于Gf中不存在从s到t的路径,则t∉S,所以得到G的一个割(S, T)。对每对顶点u∈S,v∈T,必须满足f(u, v) = c(u, v),否则边(u, v)就会存在于Gf的边集合中,那么v就应当属于S(而事实上是v∈T)。所以,f(S, T) = c(S, T);
3.我们已经证明,网络的任何流的值都不大于任何一个割的容量,如果G的某个割(S, T),满足f(S, T) = c(S, T),则说明割(S, T)的流达到了网络流的上确界,它必然是最大流。
Ford-Fulkerson算法的迭代终止条件是残留网中不包含增广路径,根据上面的等价条件,此时得到的流就是网络的最大流。
.3 Ford-Fulkerson方法的实现
在前一节,我们讨论了Ford-Fulkerson方法中所应用到的几个概念以及保证该方法正确性的重要属性。本节将讨论Ford-Fulkerson方法的具体实现,包括残留网的更新和增广路径的获取。
增广路径事实上是残留网中从源点s到汇点t的路径,可以利用图算法中的任意一种被算法来获取这条路径,例如BFS,DFS等。其中基于BFS的算法通常称为Edmonds-Karp算法,该算法是“最短”扩充路径,这里的“最短”由路径上的边的数量来度量,而不是流量或者容量。
这里所选的路径寻找方法会直接影响算法的运行时间,例如,对图采用DFS的方法搜索残留网中的增广路径。图(b)中是第一次搜索得到的增广路径为<s, v1, v2, t>,路径的流大小为1;图(c)和(d)中搜索得到的增广路径的流大小也是1。可以发现,在这个例子中,采用DFS算法将需要2000000次搜索才能得到最大流。
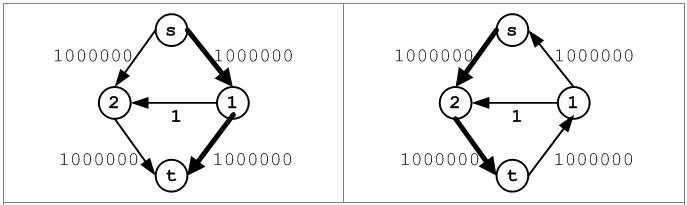
如果换一种方法对残留网中的进行遍历将会很快求得流网络的最大流。如图,第一次在顶点1搜索下一条边时,不是选择边(1, 2)而是选择容量更大的边(1, t);第二次在顶点2处搜索下一条边时,选择边(2, t)。这样只要两次遍历即可求解最大流。可见,在残留网中搜索增广路径的算法直接影响Ford-Fulkerson方法实现的效率。
3.1 流网络数据结构
.3.1.1 流网络边的数据结构
流网络数据结构与图数据结构比较相似,首先也需要设计流网络的边的数据结构。这里我们只讨论基于连接表的流网络数据结构的实现。在图数据结构中边包含了源点、终点以及边所在其对应链表中的节点的指针。
流网络边种同样包含上述三个成员,但还包括其它针对流网络算法的成员函数,其实现如下:

//私有成员变量
//边的源顶点和终节点
private int vert1, vert2;
//单链表节点,
private SingleNode itself;
//构造函数
public NetworkEdge(int _v1, int _v2, SingleNode _it){
vert1 = _v1;
vert2 = _v2;
itself = _it;
}
public int get_v1() {
return vert1;
}
public int get_v2() {
return vert2;
}
public SingleNode get_lk(){
return itself;
}
// 判断v是否是源点
public boolean from(int v){
return v == get_v1();
}
// 返回边的v顶点的另一顶点
public int other(int v){
return from(v)?vert2:vert1;
}
}
其中函数from判断给定顶点v是否是这条边的源点,如果是则返回true,否则返回false;给定顶点v,函数other返回这条边的另一顶点。
.3.1.2 流网络数据结构
流网络数据结构的连接表法的实现与图数据结构类似。需要定义一个链表来存放与给定顶点相邻的顶点,以及这两个顶点形成的边的信息,在流网络中,边的信息包括边的容量和边的流量。所以链表的节点设计为:
//私有成员,终点、权重、流
private int des, cap, flow;
//构造函数
public NetworkLLinkNode(int _des, int _wt, int _flow){
des = _des;
cap = _wt;
flow = _flow;
}
// 设置终点
public void set_des(int _d){
des = _d;
}
// 设置权重
public void set_wt(int _wt){
cap = _wt;
}
// 设置流
public void set_flow(int f){
flow = f;
}
// 获取终点
public int get_des(){
return des;
}
// 获取权重
public int get_wt(){
return cap;
}
// 获取流
public int get_flow(){
return flow;
}
// 比较两个两个顶点的权重
public int compareTo(Object arg0) {
int _wt = ((NetworkLLinkNode)(arg0)).get_wt();
if(cap > _wt) return 1;
else if(cap < _wt) return -1;
else return 0;
}
}
其中成员变量包括边的终点、容量和流,函数compareTo比较相同源点的两条边的容量。
基于流网络边和链表节点数据结构,流网络数据结构的实现如下:
// 私有成员变量
//顶点链表数组,数组的每个元素对应于
//与顶点相连的所有顶点形成的链表
private NetworkNodeLList[] vertexList;
//边的个数和顶点的个数
private int num_Edge, num_Vertex;
//节点标记数组
private int[] mark;
public Network(int n){
vertexList = new NetworkNodeLList[n];
for(int i = 0; i < n; i++){
vertexList[i] = new NetworkNodeLList();
}
num_Edge = 0;
num_Vertex = n;
mark = new int[n];
}
public int get_nv() {
return num_Vertex;
}
public int get_ne() {
return num_Edge;
}
public NetworkEdge firstEdge(int v) {
vertexList[v].goFirst();
if(vertexList[v].getCurrVal() == null) return null;
return new NetworkEdge(v,
((NetworkLLinkNode)(vertexList[v].getCurrVal()
.getElem())).get_des(),
vertexList[v].currNode());
}
public NetworkEdge nextEdge(NetworkEdge w) {
if(w == null) return null;
int v = w.get_v1();
vertexList[v].setCurr(w.get_lk());
vertexList[v].next();
if(vertexList[v].getCurrVal() == null) return null;
return new NetworkEdge(v,
((NetworkLLinkNode)(vertexList[v].getCurrVal()
.getElem())).get_des(),
vertexList[v].currNode());
}
public boolean isEdge(NetworkEdge w) {
if(w == null) return false;
int v = w.get_v1();
vertexList[v].setCurr(w.get_lk());
if(!vertexList[v].inList()) return false;
return ((NetworkLLinkNode)(vertexList[v].getCurrVal()
.getElem())).get_des() == w.get_v2();
}
public boolean isEdge(int i, int j) {
for(vertexList[i].goFirst();
vertexList[i].getCurrVal() != null &&
((NetworkLLinkNode)(vertexList[i].getCurrVal()
.getElem())).get_des() < j;
vertexList[i].next());
return vertexList[i].getCurrVal() != null &&
((NetworkLLinkNode)(vertexList[i].getCurrVal()
.getElem())).get_des() == j;
}
public int edge_v1(NetworkEdge w) {
if(w == null) return -1;
return w.get_v1();
}
public int edge_v2(NetworkEdge w) {
if(w == null) return -1;
return w.get_v2();
}
public void setEdgeC(int i, int j, int wt) {
if(i < 0 || j < 0) return;
NetworkLLinkNode gln = new NetworkLLinkNode(j, wt, 0);
if(isEdge(i, j)){
vertexList[i].setCurrVal(
new ElemItem<NetworkLLinkNode>(gln));}
else{
vertexList[i].insert(
new ElemItem<NetworkLLinkNode>(gln));
num_Edge++;
}
}
public void setEdgeC(NetworkEdge w, int wt) {
if(w != null)
setEdgeC(w.get_v1(), w.get_v2(), wt);
}
public int getEdgeC(int i, int j) {
if(isEdge(i, j))
return ((NetworkLLinkNode)(vertexList[i].
getCurrVal().getElem())).get_wt();
else return Integer.MAX_VALUE;
}
public int getEdgeC(NetworkEdge w) {
if(w != null)
return getEdgeC(w.get_v1(), w.get_v2());
else
return Integer.MAX_VALUE;
}
/**
* 新添加的函数,获取i为始点,j为终点的边
*/
public NetworkEdge getNetworkEdge(int i, int j){
if(isEdge(i, j))
return new NetworkEdge(i, j,
vertexList[i].currNode());
else return null;
}
public void setEdgeFlow(int i, int j, int flow) {
if(i < 0 || j < 0) return;
int wt = getEdgeC(i, j);
NetworkLLinkNode gln = new NetworkLLinkNode(j, wt, flow);
if(isEdge(i, j)){
vertexList[i].setCurrVal(
new ElemItem<NetworkLLinkNode>(gln));}
else{
vertexList[i].insert(
new ElemItem<NetworkLLinkNode>(gln));
num_Edge++;
}
}
public void setEdgeFlow(NetworkEdge w, int flow) {
if(w != null)
setEdgeFlow(w.get_v1(), w.get_v2(), flow);
}
public int getEdgeFlow(int i, int j) {
if(isEdge(i, j))
return ((NetworkLLinkNode)(vertexList[i].getCurrVal()
.getElem())).get_flow();
else return Integer.MAX_VALUE;
}
public int getEdgeFlow(NetworkEdge w) {
if(w != null) return getEdgeFlow(w.get_v1(), w.get_v2());
else return Integer.MAX_VALUE;
}
public void addflowRto(NetworkEdge w, int v, int d){
int pflow = (w.get_v1() == v)?(-1 * d):d;
pflow += getEdgeFlow(w);
setEdgeFlow(w, pflow);
}
public void delEdge(int i, int j) {
if(isEdge(i, j)){
vertexList[i].remove();
num_Edge--;
}
}
public void delEdge(NetworkEdge w) {
if(w != null)
delEdge(w.get_v1(), w.get_v2());
}
public void setMark(int v, int val) {
if(v >= 0 && v < num_Vertex) mark[v] = val;
}
public int getMark(int v) {
if(v >= 0 && v < num_Vertex) return mark[v];
else return -1;
}
int getEdgeCap(NetworkEdge e) {return this.getEdgeC(e); }
// 如果v是e的起点,则返回e的流(f);若v是e的终点,则返回e的容量-e的流(c-f)
int capRto(NetworkEdge e, int v) {
return e.from(v)?getEdgeFlow(e):(getEdgeC(e) - getEdgeFlow(e));
}
}
流网络与图数据结构的差别包括以下几点:
setEdgeC函数设置网络中边的容量,对应图结构中设置图的边的权重。一般而言,网络中边的容量通常很少改变,所以该函数通常只在创建流网络时被调用;
setEdgeFlow函数设置网络边上的流,其实现与setEdgeC很类似,在最大流算法中网络边的流的大小是不断更新的,该函数便实现边上流的更新。
addflowRto函数对给定边上的流进行更新,给定边w,顶点v和流量d,如果v是边w的源点则将边上的流增加d,否则减去d;
capRto函数返回给定边上的流量,在讲解流网络相关概念时,我们提到,对给定的边(u, v),f(u, v) = -f(v, u);该函数形参为给定的边e和顶点v,如果v是e的源点,则返回边e上的流,否则返回流的相反数。
.3.2 优先队列搜索
本节将讨论有向带权图的一个新的搜索算法,称为基于优先队列的图搜索算法。首先将介绍基于下标堆得优先队列数据结构,并在下文介绍利用该数据结构对Ford-Fulkerson算法的改进。
.3.2.1 基于下标堆的优先队列
本节首先介绍基于下标对的优先队列数据结构。假设要在优先队列中处理的记录在一个已存在的数组中,可以让优先队列例程通过数组下标来引用数据项。这样队列中只需要数组的下标,所有对优先队列的操作都是对数组下标的操作。这里之所以要讨论这种优先队列,主要是因为在图数据结构中我们使用顶点的标号来访问顶点,我们可以将顶点的标号作为优先队列中的元素项,通过这种映射方式可以更高效地利用优先队列处理有向带权图。
这里基于下标的优先队列与前面章节中讨论的优先队列的基本操作类似,读者可以温习一下前面关于堆和优先队列的内容。基于下标的优先队列的实现如下:
// 存放元素内容的数组
private ElemItem[] a;
// 序号的优先队列,元素的优先级
private int[] pq, qp;
// 元素总数
private int N;
// 类型,-1表示最大堆;1表示最小堆。
private int type;
/**
* 构造函数
* @param items 元素项数组
*/
public intPQi(ElemItem[] items, int type){
a = items; N = 0;
pq = new int[a.length + 1];
qp = new int[a.length + 1];
this.type = type;
}
/**
* 比较a[i]和a[j]
* @param i, j 第i, j个元素
* @return type = -1时,
* 如果a[i]小于a[j]返回true,否则false
*/
private boolean less(int i, int j){
int c = a[pq[i]].compareTo(a[pq[j]]);
return c * type > 0;
}
/**
* 交换a[i]和a[j]
* @param i, j 第i, j个元素
*/
private void exch(int i, int j){
int t = pq[i];
pq[i] = pq[j];
pq[j] = t;
qp[pq[i]] = i;
qp[pq[j]] = j;
}
/**
* 将a[k]向上移
* @param k 表示待移动的是a[k]
* 函数将元素a[k]移动到正确的位置,使得a[k]
* 比其子节点元素大。
*/
private void swim(int k){
while(k > 1 && less(k / 2 , k)){
exch(k, k / 2);
k = k / 2;
}
}
/**
* 自顶向下堆化,将a[k]逐渐下移
* @param k 表示代移动的是a[k]a
* @param N 表示元素总个数为N
* 函数将元素a[k]移动到正确的位置
*/
private void sink(int k, int N){
while(2 * k <= N){
int j = 2 * k;
if(j < N && less(j, j + 1)) j++;
if(!less(k, j)) break;
exch(k, j);
k = j;
}
}
//判断当前队列是否为空
public boolean empty(){
return N == 0;
}
/**
* 插入一个新的元素,插入的位置为v
*/
public void insert(int v){
pq[++N] = v;
qp[v] = N;
swim(N);
}
/**
* 获取(删除)当前最大的元素
* @return 当前最大的元素
*/
public int getmax(){
exch(1, N);
sink(1, N - 1);
return pq[N--];
}
// 改变第k个元素
public void change(int k){
swim(qp[k]);
sink(qp[k], N);
}
// 调整第k个元素在堆中的位置
public void lower(int k){
swim(qp[k]);
}
}
其中元素项数组a为指向队列中处理的记录对应的数组的指针,称这里的数组为客户数组。数组pq为指向用户数组中元素的下标数组,堆中第i个位置处对应着客户数组中第pq[i]个元素,用a[pq[i]]来访问客户数组中对应的元素。数组qp为客户数组中各元素的优先级,qp[j]表示客户数组中第j的元素项的优先级为qp[j],那么优先队列中第i个位置对应的数组元素的优先级为pq[pq[i]]。在这里我们对堆中每个位置的优先级的量化为:队列中第i个位置对应数组元素的优先级为i,也就是说qp[pq[i]]=i。这里有一个新的成员变量type,该变量决定了堆的类型。
在less函数中,首先应用函数compareTo比较客户数组中两个元素a[i]和a[j],比较结果为c。如果a[i]<a[j]则c<0,若此时type=-1,则c*type>0,less函数返回true;反之,若此时type=1,则c*type<0,less函数返回false。所以在type=-1时,这里的less函数与之前中讨论的最大堆中的less函数功能相同。事实上,这里的type取值-1表示最大堆,反之取值1表示最小堆。由于less函数在处理队列的其它函数中都有调用,下面我们以最大堆为例,即type=-1,进行讨论。
函数swim将队列中指定k位置对应的客户数组的下标向上移动到正确的位置,直到其父节点处对应的元素值不比它小为止。sink函数的过程与之相反,是将k位置上的对应的下标向下移动到合适的位置。getmax函数返回队列顶部对应的客户数组的下标,在最大堆中,该下表对应着客户数组中的最大项。
.3.2.2 PFS搜索增广路径
接下来将介绍一种Ford-Fulkerson算法的实现,该算法沿着可以使流得到最大增长的路径进行扩充,可以利用基于下标堆的优先队列来实现。在图中的示例就是基于这个思路。在算法中用数组wt记录每个能提供的流(的相反数),数组st记录与每个顶点相关联的提供最大流的边。算法的实现如下:
* 优先级优先遍历函数;
* 函数搜索网络起点s至终点t的最大流路径。
*/
private boolean PFS(){
int M = -1 * Integer.MAX_VALUE;
// 基于下标堆(最小堆)的优先队列
intPQi pQ = new intPQi(wt, 1);
for(int v = 0; v < G.get_nv(); v++){
wt[v] = new ElemItem<Integer>(0);
st[v] = null;
pQ.insert(v);
}
// 起点s置于优先队列顶部
wt[s] = new ElemItem<Integer>(M);
pQ.lower(s);
// 迭代过程,寻找流量最大的路径
while(!pQ.empty()){
// 堆顶顶点号,getmax返回最小
int v = pQ.getmax();
wt[v] = new ElemItem<Integer>(M);
// v到达终点或者st[v]为空则推出迭代
if(v == t) break;
if(v != s && st[v] == null) break;
// 更新v的所有相邻顶点在扩充路径上的流
for(NetworkEdge E = G.firstEdge(v);
G.isEdge(E); E = G.nextEdge(E)){
NetworkEdge TmpE = E;
// 如果E的容量为负,则将E更新为E的反向边
if(G.getEdgeC(E) < 0){
E = G.getNetworkEdge(E.get_v2(), E.get_v1());
}
if(E == null) return false;
// 获取E的另一顶点w
int w = E.other(v);
// 获取顶点w在扩充路径上的流
int cap = G.capRto(E, w);
int wt_v = ((Integer)(wt[v].getElem())).intValue();
int P = cap < (-1 * wt_v)?cap:(-1 * wt_v);
int wt_w = ((Integer)(wt[w].getElem())).intValue();
if(cap > 0 && (-1 * P) < wt_w){
// 更新顶点w在扩充路径上的流
wt[w] = new ElemItem<Integer>(-1 * P);
// 更新优先队列
pQ.lower(w);
st[w] = E;
}
E = TmpE;
}
}
System.out.println("--------------------------");
for(int k = 0; k < st.length; k++ ){
if(st[k] != null)
System.out.println(st[k].get_v1()
+ "-" + st[k].get_v2());
}
return st[t] != null;
}
算法中利用的下标堆优先队列中使用了最小堆,队列的客户数组为wt,算法按照能提供的流由大到小的顺序取出队列中的顶点v。获取所有与顶点v相关联的边,这些边不仅包括以v为源点的边,还包括以v为终点的边。然后对每条边上的另一顶点w(相对于顶点v)所能提供的流的大小wt[w]以及对应的边st[w]。一旦顶点v找不到相关联的边则函数返回false,即找不到增广路径。
在流网络中。访问与顶点v相关联的边时,我们只能通过firstEdge和nextEdge迭代访问以顶点v为源点的边。但是在算法中我们还需要访问以v为终点的边,这需要对原始流网络做技巧性的调整。我们给原始流网络中的每一条边预留一条反向的边,这条边的容量为-1。如果源点为v的某条边E的容量G.getEdgeC(E) < 0,则将边E反向即可获得对应的以v为终点的边。
.3.3 流增广过程
基于PFS搜索得到的st数组,我们可以得到各个顶点相关联的能提供最大流的边,根据这些边形成的增广路径可以增加网络流。流网络源点为s,汇点为t,则从t开始,更新边(st[t], t),然后继续向顶点s迭代直到到达顶点s。算法实现如下:
int d = G.capRto(st[t], t);
for(int v = ST(t); v != s;
v = ST(v)){
int tt = G.capRto(st[v], v);
if(G.capRto(st[v], v) < d)
d = G.capRto(st[v], v);
}
G.addflowRto(st[t], t, d);
for(int v = ST(t); v != s; v = ST(v))
G.addflowRto(st[v], v, d);
}
.3.4 基于PFS的Ford-Fulkerson算法
结合PFS搜索过程和流增广过程可以实现高效的Ford-Fulkerson方法。该算法沿着可以使流得到最大增长的路径进行扩充。实现如下:
// 迭代
while(PFS()){
augument();
// 打印当前网络各边的网络流
for(int i = 0; i < G.get_nv(); i++){
for(NetworkEdge E = G.firstEdge(i);
G.isEdge(E); E = G.nextEdge(E)){
if(G.getEdgeFlow(E) > 0)
System.out.print(E.get_v1() +
" <-- " + G.getEdgeFlow(E) +
"/" +G.getEdgeC(E) +
" --> " + E.get_v2() + " || ");
}
System.out.println();
}
}
}
算法中迭代地运用PFS搜索残留图中的增广路径,并调用增广过程不断增加网络的流。以图为例,编写测试程序:
public static void main(String args[]){
Network N = new Network(6);
N.setEdgeC(0, 1, 2);
N.setEdgeC(0, 2, 3);
N.setEdgeC(1, 3, 3);
N.setEdgeC(1, 4, 1);
N.setEdgeC(2, 3, 1);
N.setEdgeC(2, 4, 1);
N.setEdgeC(3, 5, 2);
N.setEdgeC(4, 5, 3);
N.setEdgeC(1, 0, -1);
N.setEdgeC(2, 0, -1);
N.setEdgeC(3, 1, -1);
N.setEdgeC(4, 1, -1);
N.setEdgeC(3, 2, -1);
N.setEdgeC(4, 2, -1);
N.setEdgeC(5, 3, -1);
N.setEdgeC(5, 4, -1);
NetworkMaxFlow NF = new NetworkMaxFlow(N, 0, 5);
NF.Ford_Fulkerson();
}
}
PFS搜索得到的增广路径的边:
0-1
0-2
1-3
2-4
3-5
当前每条边上的流/容量:
0 <-- 2/2 --> 1 ||
1 <-- 2/3 --> 3 ||
3 <-- 2/2 --> 5 ||
PFS搜索得到的增广路径的边:
1-3
0-2
2-3
2-4
4-5
当前每条边上的流/容量:
0 <-- 2/2 --> 1 || 0 <-- 1/3 --> 2 ||
1 <-- 2/3 --> 3 ||
2 <-- 1/1 --> 4 ||
3 <-- 2/2 --> 5 ||
4 <-- 1/3 --> 5 ||
PFS搜索得到的增广路径的边:
1-3
0-2
2-3
1-4
4-5
当前每条边上的流/容量:
0 <-- 2/2 --> 1 || 0 <-- 2/3 --> 2 ||
1 <-- 1/3 --> 3 || 1 <-- 1/1 --> 4 ||
2 <-- 1/1 --> 3 || 2 <-- 1/1 --> 4 ||
3 <-- 2/2 --> 5 ||
4 <-- 2/3 --> 5 ||
PFS搜索得到的增广路径的边:
0-2
从结果可以看出,进过三次搜索便可以找出流网络中的最大流。每次都打印显示PFS搜索得到的增量路径以及网络中每条边上的流。
再以图为例,验证基于PFS算法的Ford-Fulkerson算法可以更高效:
N.setEdgeC(0, 1, 100);
N.setEdgeC(0, 2, 100);
N.setEdgeC(1, 2, 1);
N.setEdgeC(1, 3, 100);
N.setEdgeC(2, 3, 100);
N.setEdgeC(1, 0, -1);
N.setEdgeC(2, 0, -1);
N.setEdgeC(2, 1, -1);
N.setEdgeC(3, 1, -1);
N.setEdgeC(3, 2, -1);
NetworkMaxFlow NF = new NetworkMaxFlow(N, 0, 3);
NF.Ford_Fulkerson();
PFS搜索得到的增广路径的边:
0-1
0-2
1-3
当前每条边上的流/容量:
0 <-- 100/100 --> 1 ||
1 <-- 100/100 --> 3 ||
PFS搜索得到的增广路径的边:
0-2
2-3
当前每条边上的流/容量:
0 <-- 100/100 --> 1 || 0 <-- 100/100 --> 2 ||
1 <-- 100/100 --> 3 ||
2 <-- 100/100 --> 3 ||
PFS搜索得到的增广路径的边:
可见,基于PFS算法的Ford-Fulkerson方法的实现比基于DFS的实现效率更高。事实上,可以证明基于PFS算法的实现中所需要的增广路径搜索次数最多为V·E/2,而普通的Ford-Fulkerson方法所需的增广路径的搜索次数最多为V·M,其中M为流网络中最大的边容量,通常需要的搜索次数更多。
C#调用C++导出(dllexport)方法
IIS7.5 GZip配置
wcf学习笔记--初识wcf
Greenplum installation guide
Cloudera 5.8.2 Installation guide
WPF DataGrid 合并单元格
wpf DataGrid CheckBox列全选
WPF button 圆角制作
WPF passwordbox 圆角制作
- 最新文章
-
Katalon Studio有关的一些项目设置(转载)
Katalon 学习笔记(一)(转载)
web测试通用要点大全(Web Application Testing Checklist)(转载)
Android 开发知识体系
mysql中You can’t specify target table for update in FROM clause错误解决方法
常用域名记录解释:A记录、MX记录、CNAME记录、TXT记录、AAAA记录、NS记录
图片滚动(UP)的JS代码详解(offsetTop、scrollTop、offsetHeigh)【转】
关于滚动相关的属性【转】
为什么JSP改动不需要重启服务器
htmlparser 学习