问题描述
某维度表的字符串列同时出现两条记录,A记录以半角空格(英文空格)结束,B记录以全角空格(中文空格)结束,除此之外其他部分均相同。Analysis Service处理的时候抛出“Key not found”的异常,导致处理失败。
为了实验,我们创建两张非常简单的表:
Create Table [FactTransaction](
[TransactionKey] [int] not null,
[EmployeeKey] [int] not null
)
Create Table [DimEmployee](
[EmployeeKey] [int]not null,
[EmployeeName] [nvarchar](32) not null
)
接着我们开始往维度表中添加几条记录。
insert into DimEmployee(EmployeeKey,EmployeeName)values(1,'员工 ') -- 半角空格
insert into DimEmployee(EmployeeKey,EmployeeName)values(2,'员工') -- 全角空格
然后我们在BIDS中新建一个Analysis Service的Olap工程,将DimEmployee表作为维度表,并新建指标TotalTransactions ::= Count(TransactionKey)表示每个员工的交易数量:
所有设置保持默认,OK,现在开始处理Employee维度。这个时候Analysis Service会提示你:
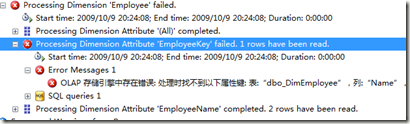
Processing Dimension Attribute 'EmployeeKey' failed. 1 rows have been read.
OLAP 存储引擎中存在错误: 处理时找不到以下属性键: 表:“dbo_DimEmployee”,列:“EmployeeName”,值:“员工 ”。该属性为“EmployeeName”。
这个错误翻译成英文就是Key not found.
问题分析
发生了什么事
在我们上面设计的OLAP方案中,一个EmployeeKey有且只能有一个EmployeeName,EmployeeKey属性的处理依赖于 EmployeeName属性。这个依赖关系在维度设计视图中的Attribute Relationship属性关系面板中指定。
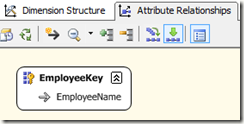
Analysis Service会在处理完EmployeeName属性之后再处理EmployeeKey属性。在处理每一个EmployeeKey属性成员的时候,都会去找对应的EmployeeName属性成员。
上面的处理错误实际上就是说,在处理EmployeeKey的某个成员的时候,它对应的EmployeeName属性成员应该是“员工 ”(全角空格)的——从表记录
中可以看到这个对应关系——但是在属性存储文件(Analysis Service自己的存储结构)中却找不到该属性成员。
这里没有告诉我们到底是哪个EmployeeKey属性成员处理的时候出了问题,但是由于我们的数据仓库非常简单,我们可以直接看出来,EmployeeName=“员工 ”(全角空格)的EmployeeKey为2。
那为什么全角空格的EmployeeName属性成员没有导入到Analysis Service的属性存储文件中呢?我们来展开看一下处理EmployeeName时Analysis Service向Sql Server发起的查询。
[dbo_DimEmployee].[EmployeeName] AS [dbo_DimEmployeeEmployeeName0_0]
FROM [dbo].[DimEmployee] AS [dbo_DimEmployee]
将这行代码放到Sql Server中去执行一下,我们发现sql Server只给我们返回了半角空格的记录,全角空格的记录被过滤掉了。这也就解释了,为什么全角空格的属性成员没能进入Analysis service中。进而导致依赖这个成员的属性处理失败。
Sql Server Collation
这里需要提一下Sql Server的排序规则(Collation)。排序规则会影响数据之间的比较以及顺序。具体细节参见MSDN:SQL Server Collation Fundamentals。这里我只提一个和这个问题相关的,并且容易被人遗忘的设置,那就是Width-Sensitive(宽度敏感)设置。我们知道,有些字符既有单字节形式(半角字符),又有双字节形式(全角字符),例如1234和1234。如果设置为宽度不敏感,那么Sql Server就会将这些字符的单双字节形式一视同仁。这样你在select distinct的时候,单双字节字符形式的字符串就只能一个。这也就是为什么上面我们select distinct的时候只出来半角空格的缘故。
Sql Server和Analysis Service排序规则相同为什么还会出错?
Analysis Service自己也有一个排序规则的设置。我们检查了一下这两者的设置,发现是一样的。那么Analysis Service在查找“员工 ”(全角空格)属性成员的时候,即使找不到这个成员,但是应该至少可以匹配到“员工 ”(半角空格)的成员才是呀。关键是,半角空格的成员也根本不存在。默认情况下,所有字符串类型的维度属性在处理时都会被right trim,也就是结尾的空格均会被去除。
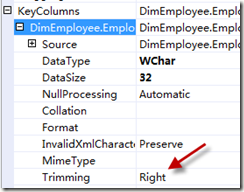
也就是说,最终进入Analysis Service的属性成员是“员工”,不带任何空格,而这个成员和全角空格(全角空格无法被right trimming掉)的显然无法匹配上。
发散一下
如果Analysis设置了对每个属性成员左右都trim的话,那么一旦数据仓库出现“ 员工”(左边带全角空格)和“ 员工”(左边带半角空格)的数据的时候,处理失败。
如果数据仓库中同时出现“员工”,“员工 ”(全角空格),那么也会造成出错,这是因为select distinct会将右侧空格去除之后再比较数据是否相等。
如果将维度属性的Trimming设置为None的话,那么当数据仓库中出现“员工”,“员工 ”(若干个半角空格结尾)这样数据的时候,也会造成处理失败,这也是为什么Analysis Service默认设置为right trimming的其中一个原因(和Sql Server的行为保持一致)。
如果数据中同时出现“员工 ”(半角空格),“员工 ”(全角空格),“员工 ”(先全角空格,再tab空格)这样的数据组合,处理正常。
总结
出现这样的情况,不好通过改变Sql Server或者Analysis Service的排序规则来修正这个问题。只能在ETL的阶段对此类数据进行预处理,将末尾的全角空格给剔除掉。如果业务系统对全半角的区别不感兴趣,也可以直接使用正则表达式将所有全角字符替换成相应的半角字符。