来源商业新知网,原标题:Flair:一款简单但技术先进的NLP库
过去的几年里,在NLP(自然语言处理)领域,我们已经见证了多项令人难以置信的突破,如ULMFiT、ELMo、Facebook的PyText以及谷歌的BERT等等。
这些技术大大推进了NLP的前沿性研究,尤其是语言建模。只要给出前几个单词的顺序,我们就可以预测下一个句子。
但更重要的是,机器也找到了长期无法实现推测语句的关键因素。
那就是:语境!
对语境的了解打破了阻碍NLP技术进步的障碍。而今天,我们就来讨论这样的一个库:Flair。

至今为止,单词要么表示为稀疏矩阵,要么表示为嵌入式词语,如GLoVe,Bert和ELMo。但是,事物总有改进的空间,Flair就愿意更正不足。
在本文中,首先我们将了解Flair是什么以及其背后的概念。然后将深入讨论使用Flair实现NLP任务。

一. 什么是Flair库?

Flair是由Zalando Research开发的一个简单的自然语言处理(NLP)库。 Flair的框架直接构建在PyTorch上,PyTorch是最好的深度学习框架之一。 Zalando Research团队还为以下NLP任务发布了几个预先训练的模型:
1. 名称-实体识别(NER):它可以识别单词是代表文本中的人,位置还是名称。
2. 词性标注(PoS):将给定文本中的所有单词标记为它们所属的“词性”。
3. 文本分类:根据标准对文本进行分类(标签)。
4. 培训定制模型:制作我们自己的定制模型。
所有的这些模型,看起来很有前景。但真正引起我注意的是,当我看到Flair在NLP中超越了几项最先进成绩的时候。看看这个目录:
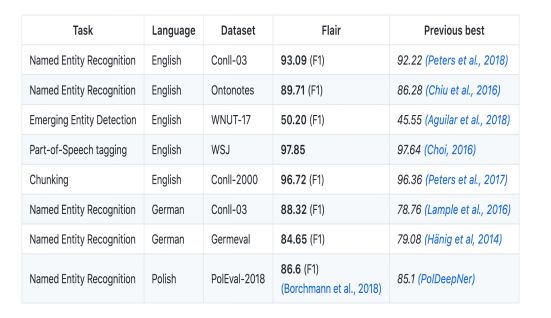
注意:F1评分主要是用于分类任务的评估指标。在评估模型时,它通常用于机器学习项目中的精度度量。F1评分考虑了现有项目的分布。
二. Flair库的优势是什么?
Flair库中包含了许多强大的功能,以下是最突出的一些方面:
· 它包括了最通用和最先进的单词嵌入方式,如GloVe,BERT,ELMo,字符嵌入等。凭借Flair API技术,使用起来非常容易。
· Flair的界面允许我们组合不同的单词嵌入并嵌入文档,显著优化了结果。
· 'Flair 嵌入'是Flair库提供的签名嵌入。它由上下文字符串嵌入提供支持,我们将在下一节中详细了解这一概念。
· Flair支持多种语言,并有望添加新语种。
三 . 用于序列标记的上下文字符串嵌入简介
在处理NLP任务时,上下文语境非常重要。通过先前字符预测下一个字符,这一学习过程构成了序列建模的基础。
上下文字符串的嵌入,是通过熟练利用字符语言模型的内部状态,来产生一种新的嵌入类型。简单来说,它通过字符模型中的某些内部原则,使单词在不同的句子中可以具有不同的含义。
注意:语言和字符模型是单词/字符的概率分布,因此每个新单词或新字符都取决于前面的单词或字符。

有两个主要因素驱动了上下文字符串的嵌入:
1. 这些单词被理解为字符(没有任何单词的概念)。也就是说,它的工作原理类似于字符嵌入。
2. 嵌入是通过其周围文本进行语境化的。这意味着根据上下文,相同的单词可以有不同的嵌入意义。很像自然的人类语言,不是吗?在不同的情况下,同一个词可能有不同的含义。
让我们看个例子来理解这个意思:
· 案例1:读一本书(Reading a book)
· 案例2:请预订火车票(Please book a train ticket)
说明:
· 在案例1中,book是一个名词
· 在案例2中,book是动词
语言是如此奇妙而复杂的东西啊!
四. 使用Flair在Python中执行NLP任务
是时候让Flair进行测试了!我们已经了解了这个神奇图书馆的全部内容。现在让我们亲眼看看它在机器上是如何运行的。
我们将使用Flair在Python中执行以下所有NLP任务:
1.使用Flair对嵌入的文本分类
2.词性标记(PoS)与NLTK库的比较
建立环境

我们将使用Google Colaboratory运行我们的代码。Colab最棒的一点就是它免费提供GPU支持!这极大地方便了学习模型的深度培训。
为什么使用Colab?
· 完全免费
· 具有相当不错的硬件配置
· 你的Web浏览器上都有,即使是硬件过时的旧机器也可以运行
· 连接到你的Google云端硬盘
· 很好地与Github集成
你只需要一个稳定的互联网连接。
关于数据集
我们将努力研究Twitter Sentiment Analysis(推特敏感度分析)的实践问题。
而这一挑战带来的问题是:
这项任务的目的是检测推文中的仇恨言论。为了简单起见,如果它带有相关的种族主义或性别歧视情绪,我们则判断这条推文包含仇恨言论。因此,这项任务是将带有种族主义或性别歧视地推文与其他推文分类。
1.使用Flair嵌入进行文本分类
第1步:将数据导入Colab的本地环境:
# Install the PyDrive wrapper & import libraries.
# This only needs to be done once per notebook.
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
# Authenticate and create the PyDrive client.
# This only needs to be done once per notebook.
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
# Download a file based on its file ID.
# A file ID looks like: laggVyWshwcyP6kEI-y_W3P8D26sz
file_id = '1GhyH4k9C4uPRnMAMKhJYOqa-V9Tqt4q8' ### File ID ###
data = drive.CreateFile({'id': file_id})
#print('Downloaded content "{}"'.format(downloaded.GetContentString()))
你可以在驱动器中数据集文件的可共享链接中找到文件ID。
将数据集导入Colab笔记本:
import io
Import pandas as pd
data = pd.read_csv(io.StringIO(data.GetContentString()))
data.head()
已从数据中删除所有表情符号和符号,并且字符已转换为小写。
第2步:安装Flair
# download flair library #
import torch
!pip install flair
import flair
简要介绍一下Flair数据类型
这个库的对象有两种类型—句子和标记对象。一个句子持有一个文本句子,基本上是标记列表:
from flair.data import Sentence
# create a sentence #
sentence = Sentence('Blogs of Analytics Vidhya are Awesome.')
# print the sentence to see what’s in it. #
print(Sentence)
第3步:准备文本以使用Flair
#extracting the tweet part#
text = data['tweet']
## txt is a list of tweets ##
txt = text.tolist()
print(txt[:10])
第4步:使用Flair嵌入单词
## Importing the Embeddings ##
from flair.embeddings import WordEmbeddings
from flair.embeddings import CharacterEmbeddings
from flair.embeddings import StackedEmbeddings
from flair.embeddings import FlairEmbeddings
from flair.embeddings import BertEmbeddings
from flair.embeddings import ELMoEmbeddings
from flair.embeddings import FlairEmbeddings
### Initialising embeddings (un-comment to use others) ###
#glove_embedding = WordEmbeddings('glove')
#character_embeddings = CharacterEmbeddings()
flair_forward = FlairEmbeddings('news-forward-fast')
flair_backward = FlairEmbeddings('news-backward-fast')
#bert_embedding = BertEmbedding()
#elmo_embedding = ElmoEmbedding()
stacked_embeddings = StackedEmbeddings( embeddings = [
flair_forward-fast,
flair_backward-fast
])
你会注意到,我们刚刚使用了一些上面最流行的单词嵌入。你可以删除评论'#'以使用所有嵌入。
现在你可能会问,到底什么是“堆叠嵌入”?在这里,我们可以结合多个嵌入来构建一个功能强大的单词表示模型,不需要太复杂。很像合唱,不是吗?
我们使用Flair的堆叠嵌入只是为了减少本文中的计算时间。使用你喜欢的任何组合可以随意地使用这个和其他嵌入。
测试堆叠嵌入:
# create a sentence #
sentence = Sentence(‘ Analytics Vidhya blogs are Awesome .')
# embed words in sentence #
stacked.embeddings(sentence)
for token in sentence:
print(token.embedding)
# data type and size of embedding #
print(type(token.embedding))
# storing size (length) #
z = token.embedding.size()[0]
第5步:将文本矢量化
我们将使用两种方法展示这一点。
· 在推文中嵌入词的意思
我们将在这种方法中计算以下内容:
对于每个句子:
1.为每个单词生成单词嵌入
2.计算每个单词嵌入的平均值以获取句子嵌入
from tqdm import tqdm ## tracks progress of loop ##
# creating a tensor for storing sentence embeddings #
s = torch.zeros(0,z)
# iterating Sentence (tqdm tracks progress) #
for tweet in tqdm(txt):
# empty tensor for words #
w = torch.zeros(0,z)
sentence = Sentence(tweet)
stacked_embeddings.embed(sentence)
# for every word #
for token in sentence:
# storing word Embeddings of each word in a sentence #
w = torch.cat((w,token.embedding.view(-1,z)),0)
# storing sentence Embeddings (mean of embeddings of all words) #
s = torch.cat((s, w.mean(dim = 0).view(-1, z)),0)
· 文档嵌入:将整个推文矢量化
from flair.embeddings import DocumentPoolEmbeddings
### initialize the document embeddings, mode = mean ###
document_embeddings = DocumentPoolEmbeddings([
flair_embedding_backward,
flair_embedding_forward
])
# Storing Size of embedding #
z = sentence.embedding.size()[1]
### Vectorising text ###
# creating a tensor for storing sentence embeddings
s = torch.zeros(0,z)
# iterating Sentences #
for tweet in tqdm(txt):
sentence = Sentence(tweet)
document_embeddings.embed(sentence)
# Adding Document embeddings to list #
s = torch.cat((s, sentence.embedding.view(-1,z)),0)
你可以为模型选择任一种方法。现在我们的文本已经矢量化过,我们可以将其提供给我们的机器学习模型了!
第6步: 为训练集和测试集划分数据
## tensor to numpy array ##
X = s.numpy()
## Test set ##
test = X[31962:,:]
train = X[:31962,:]
# extracting labels of the training set #
target = data['label'][data['label'].isnull()==False].values
第7步:构建模型并定义自定义评估程序(用于F1分数)
· 为XGBoost定义自定义F1评估程序
def custom_eval(preds, dtrain):
labels = dtrain.get_label().astype(np.int)
preds = (preds >= 0.3).astype(np.int)
return [('f1_score', f1_score(labels, preds))]
· 构建XGBoost模型
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
### Splitting training set ###
x_train, x_valid, y_train, y_valid = train_test_split(train, target,
random_state=42,
test_size=0.3)
### XGBoost compatible data ###
dtrain = xgb.DMatrix(x_train,y_train)
dvalid = xgb.DMatrix(x_valid, label = y_valid)
### defining parameters ###
params = {
'colsample': 0.9,
'colsample_bytree': 0.5,
'eta': 0.1,
'max_depth': 8,
'min_child_weight': 6,
'objective': 'binary:logistic',
'subsample': 0.9
}
### Training the model ###
xgb_model = xgb.train(
params,
dtrain,
feval= custom_eval,
num_boost_round= 1000,
maximize=True,
evals=[(dvalid, "Validation")],
early_stopping_rounds=30
)
至此,我们的模型已经通过训练,可以进行评估了!
第8步: 可以预测了!
### Reformatting test set for XGB ###
dtest = xgb.DMatrix(test)
### Predicting ###
predict = xgb_model.predict(dtest) # predicting
我们可以把预测上传到练习题界面,其中,0.2是概率阈值。
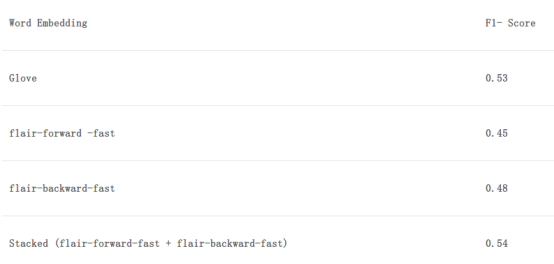
注意:根据Flair的官方文档显示,一个嵌入和其他嵌入堆叠时,效果更佳。但是存在一个问题。

在CPU上计算可能需要非常长的时间,强烈建议利用GPU来获得更快的结果,你可以在Colab中使用免费的。
2.词性标注(POS)
我们将使用Conll-2003数据集的一个子集,是一个预先标记的英文数据集。
第1步:导入数据集
### file was uploaded manually to local environment of Colab ###
data = open('pos-tagged_corpus.txt','r')
txt = data.read()
#print(txt)
数据文件每行包含一个单词,空行表示句子边界。
第2步:从数据集中提取句子和PoS标签
### converting text in form of list of (words with their tags) ###
txt = txt.split('n')
### removing DOCSTART (document header)
txt = [x for x in txt if x != '-DOCSTART- -X- -X- O']
### check ###
for i in range(10):
print(txt[i])
print(‘-’*10)
### Extracting Sentences ###
# Initialize empty list for storing words
words = []
# initialize empty list for storing sentences #
corpus = []
for i in tqdm(txt):
## if blank sentence encountered ##
if i =='':
## previous words form a sentence ##
corpus.append(' '.join(words))
## Refresh Word list ##
words = []
else:
## word at index 0 ##
words.append(i.split()[0])
# did it work? #
for i in range(10):
print(corpus[i])
print(‘-’*10)
### Extracting POS ###
# Initialize empty list for storing word pos
w_pos = []
#initialize empty list for storing sentence pos #
POS = []
for i in tqdm(txt):
## blank sentence = new line ##
if i =='':
## previous words form a sentence POS ##
POS.append(' '.join(w_pos))
## Refresh words list ##
w_pos = []
else:
## pos tag from index 1 ##
w_pos.append(i.split()[1])
# did it work? #
for i in range(10):
print(corpus[i])
print(POS[i])
### Removing blanks form sentence and pos ###
corpus = [x for x in corpus if x!= '']
POS = [x for x in POS if x!= '']
### Check ###
For i in range(10):
print(corpus[i])
print(POS[i])
我们从数据集中提取了我们需要的基本方面。让我们继续第3步。
第3步:使用NLTK和Flair标记文本
· 使用NLTK进行标记
首先,输入所需的库资源:
import nltk
nltk.download('tagsets')
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
from nltk import word_tokenize
这将会下载所有所需的文件,用于使用NLTK进行标记。
### Tagging the corpus with NLTK ###
#for storing results#
nltk_pos = []
##for every sentence ##
for i in tqdm(corpus):
# Tokenize sentence #
text = word_tokenize(i)
#tag Words#
z = nltk.pos_tag(text)
# store #
nltk_pos.append(z)
POS标签采用以下格式:
[(‘token_1’, ‘tag_1’), ………….. , (‘token_n’, ‘tag_n’)]
让我们从中提取POS:
### Extracting final pos by nltk in a list ###
tmp = []
nltk_result = []
## every tagged sentence ##
for i in tqdm(nltk_pos):
tmp = []
## every word ##
for j in i:
## append tag (from index 1) ##
tmp.append(j[1])
# join the tags of every sentence #
nltk_result.append(' '.join(tmp))
### check ###
for i in range(10):
print(nltk_result[i])
print(corpus[i])
NLTK标签已准备就绪。
· 现在,关注一下使用Flair进行标记
首先,输入库资源:
!pip install flair
from flair.data import Sentence
from flair.models import SequenceTagger
使用Flair进行标记:
# initiating object #
pos = SequenceTagger.load('pos-fast')
#for storing pos tagged string#
f_pos = []
## for every sentence ##
for i in tqdm(corpus):
sentence = Sentence(i)
pos.predict(sentence)
## append tagged sentence ##
f_pos.append(sentence.to_tagged_string())
###check ###
for i in range(10):
print(f_pos[i])
print(corpus[i])
结果将为以下格式:
token_1 <tag_1>token_2 <tag_2>………………….. token_n
注意:我们可以在Flair库中使用不同的标记器,可以随意修补和实验。
用NLTK的方式提取句子标签
Import re
### Extracting POS tags ###
## in every sentence by index ##
for i in tqdm(range(len(f_pos))):
## for every words ith sentence ##
for j in corpus[i].split():
## replace that word from ith sentence in f_pos ##
f_pos[i] = str(f_pos[i]).replace(j,"",1)
## Removing < > symbols ##
for j in ['<','>']:
f_pos[i] = str(f_pos[i]).replace(j,"")
## removing redundant spaces ##
f_pos[i] = re.sub(' +', ' ', str(f_pos[i]))
f_pos[i] = str(f_pos[i]).lstrip()
### check ###
for i in range(10):
print(f_pos[i])
print(corpus[i])
啊哈!我们终于标记了语料库并从其中按顺序提取出句子。我们可以自由删除所有的标点和特殊符号。
### Removing Symbols and redundant space ###
## in every sentence by index ##
for i in tqdm(range(len(corpus))):
# Removing Symbols #
corpus[i] = re.sub('[^a-zA-Z]', ' ', str(corpus[i]))
POS[i] = re.sub('[^a-zA-Z]', ' ', str(POS[i]))
f_pos[i] = re.sub('[^a-zA-Z]', ' ', str(f_pos[i]))
nltk_result[i] = re.sub('[^a-zA-Z]', ' ', str(nltk_result[i]))
## Removing HYPH SYM (they are for symbols) ##
f_pos[i] = str(f_pos[i]).replace('HYPH',"")
f_pos[i] = str(f_pos[i]).replace('SYM',"")
POS[i] = str(POS[i]).replace('SYM',"")
POS[i] = str(POS[i]).replace('HYPH',"")
nltk_result[i] = str(nltk_result[i].replace('HYPH',''))
nltk_result[i] = str(nltk_result[i].replace('SYM',''))
## Removing redundant space ##
POS[i] = re.sub(' +', ' ', str(POS[i]))
f_pos[i] = re.sub(' +', ' ', str(f_pos[i]))
corpus[i] = re.sub(' +', ' ', str(corpus[i]))
nltk_result[i] = re.sub(' +', ' ', str(nltk_result[i]))
我们使用NLTK和Flair标记了语料库,提取并删除了所有不必要的元素,让我们一起看看:
for i in range(1000):
print('corpus '+corpus[i])
print('actual '+POS[i])
print('nltk '+nltk_result[i])
print('flair '+f_pos[i])
print('-'*50)
输出:

结果看起来非常有说服力!
第4步:针对标记数据集评估来自NLTK和Flair的PoS标记
在这里,我们将在定制评估器的帮助下对标签进行逐字评估。

请注意,在上面的示例中,与NLTK和flair标签相比,实际的POS标签包含冗余(如粗体所示)。因此,我们不会考虑句子长度不等的POS标记句子。
### EVALUATION FUNCTION ###
def eval(x,y):
# correct match #
count = 0
#Total comparisons made#
comp = 0
## for every sentence index in dataset ##
for i in range(len(x)):
## if the sentence length match ##
if len(x[i].split()) == len(y[i].split()):
## compare each word ##
for j in range(len(x[i].split())):
if x[i][j] == y[i][j] :
## Match! ##
count = count+1
comp = comp + 1
else:
comp = comp + 1
return (count/comp)*100
最后,我们根据数据集提供的POS标签评估NLTK和Flair的POS标签。
print("nltk Score ", eval2(POS,nltk_result))
print("Flair Score ", eval2(POS,f_pos))
结果是:
NLTK评估分数 : 85.38654023442645
Flair 评估分数 : 90.96172124773179
Flair显然在字嵌入和堆叠字嵌入方面占据优势。由于其高级的API,这些嵌入可以毫不费力地实现。