来源商业新知网,原标题:开源鉴黄AI新鲜出炉:代码+预训练模型,还附手把手入门教程
要入门机器学习,一个自己感兴趣又有丰富数据的领域再好不过了。
今天我们就来学习用Keras构建模型,识别NSFW图片,俗称造个鉴黄AI。

资源来自一名印度小哥Praneeth Bedapudi,涉及图像分类和目标检测两个科目。他在GitHub上最新发布了NudeNet项目,包含代码和两个预训练模型:负责识别露不露的图像分类模型和负责找出关键部位(以便打码)的目标检测模型。
图像分类模型很简单,能区分两个类别:nude和safe,也就是露和不露,堪比经典的hotdog/not hotdog。
目标检测模型则能检测6个类别:不分性别的腹部、臀部,和区分了性别的不可描述部位。

资源链接全在文末,我们先来学习一番。
图像分类
从数据集开始
构建一个图像二分类模型,需要数据集当然也要包含两类图像。所以,第一项任务就是分别搜集露的图片(nude)和不露的图片(safe)。
不安全的nude图片 来自三处:
一 是用RipMe从website scrolller下载,这些图片来自Reddit论坛的各种NSFW板块;
图片来源: https://scrolller.com/nsfw(打开请慎重)
下载工具: https://github.com/RipMeApp/ripme
二 是P站的缩略图。引入这些缩略图是为了平衡图片质量——上边的的Reddit图片质量太高了,而一个鉴黄AI,在现实中遇到的图片大多是渣品质,这就需要分辨率很低的缩略图来平衡。
三 是之前广为流传的 同类数据集 ,来自alexkimxyz。
原数据集的5个类别,被映射到现在的两类之中。hentai和porn属于nude,而drawings、neutral和sexy属于safe。
搜集好数据之后,进行标准化和去重:
# Resizing and removing duplicates
mogrify -geometry x320 *fdupes -rdN ./
最终得到的不安全图片1,78,601张P站图片、1,21,644张Reddit图片和1,30,266张前辈数据集图片。
安全的图片 则有三个来源,一是alexkimxyz数据集中的普通图片;二是Facebook资料;三是Reddit论坛上那些老少皆宜的板块。
为什么已经有了现成的数据集,还需要去后两个来源抓取呢?
因为小哥发现,前辈收集的安全图片,有很多根本就不包含人。用这样的数据训练,模型很可能学到错误的特征,没学会判断“露不露”,直接变成了一个“有没有人”分类器。
最终得到的安全图片中,有68,948张来自Facebook资料、98,359张来自前辈数据集、55,137张来自Reddit。
数据收集完毕,接下来要进行数据增强。这里用的是Augmentor和Keras自带的fit_generator。
Augmentor地址:
https://github.com/mdbloice/Augmentor
使用的代码如下:
# Random rotation, flips, zoom, distortion, contrast, skew and brightness
pipeline.rotate(probability=0.2, max_left_rotation=20, max_right_rotation=20)pipeline.flip_left_right(probability=0.4)pipeline.flip_top_bottom(probability=0.8)pipeline.zoom(probability=0.2, min_factor=1.1, max_factor=1.5)pipeline.random_distortion(probability=0.2, grid_width=4, grid_height=4, magnitude=8)pipeline.random_brightness(probability=0.2, min_factor=0.5, max_factor=3)pipeline.random_color(probability=0.2, min_factor=0.5, max_factor=3)pipeline.random_contrast(probability=0.2, min_factor=0.5, max_factor=3)pipeline.skew(probability=0.2, magnitude=0.4)
训练与评估
小哥为这个任务选择了谷歌出品的Xception模型,直接从Keras使用,输入256x256尺寸的图片,批次大小设为32。
而训练的设备,是从vast.ai租来的云服务器,带一块GTX 1080Ti显卡。
Keras提供的图像分类模型有个问题:不带正则化。所以,还要用下面的代码,为每一层加上正则化(dropout或L2)。
# For l2
for layer in model.layers: layer.W_regularizer = l2(..)# Or for dropout add dropout between the fully connected layers and redefine the model using functional API.
使用SGD with momentum训练,模型可以在alexkimxyz数据集上收敛到0.9347的准确率。
训练完成后,他选择了Towards Data Science之前构建的一个测试集来测试模型性能。
测试集:
https://drive.google.com/drive/folders/18SY4oyZgTD_dh8-dc0wmsl1GvMsA7woY
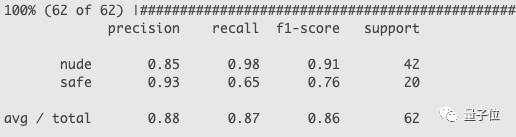
测试成绩如下:
目标检测
还是从数据集开始
训练目标检测模型需要的数据集,和图片分类可不一样。分类只需要图片和类别,而目标检测需要的,是用边界框标注了某样东西位置的图片。
因此,上边讲过的数据集不能用了,新科目的数据集来自Jae Jin的团队,包含5789张图片,各种标注的分布如下:
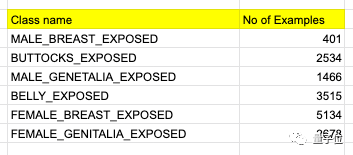
其实也就是模型能检测出的六类目标。
数据集没有公开,作者在这里:
https://github.com/Kadantte
有了数据,还是要做一些图像增强工作,随机加入一些模糊、翻转。使用的工具是albumentations:
https://github.com/albu/albumentations
训练与评估
这里的检测模型,选择的是FAIR推出的RetinaNet,它使用焦点损失(交叉熵损失的一种变体)来增强一阶目标检测的性能。
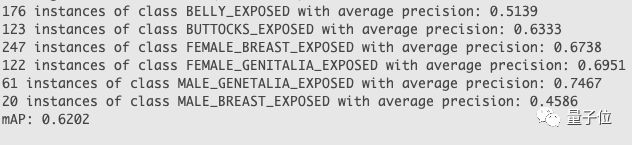
检测模型的基干使用了ResNet-101,在测试集上的成绩如下:
除了用来指出某个部位究竟出现在了图中什么位置之外,这个模型其实还可以当成分类器来用:
如果在图中检测到了BUTTOCKS_EXPOSED、*_GENETALIA_EXPOSED、F_BREAST_EXPOSED这四类,就可以判定图片NSFW,如果没有,这张图就是安全的。
所以,也可以用分类器的测试集来检测这个模型的性能。
得到的成绩,比纯粹的分类器好不少:

当然,目标检测更适合实现的功能,是打码。比如说见到一张NSFW图片,它就可以根据检测到的关键部位,自动遮挡:

预训练模型怎么用?
如果你想先用预训练模型看看效果,可以按照下面的安装指南来:
安装:
pip install nudenet
orpip install git+https://github.com/bedapudi6788/NudeNet
使用分类器:
from nudenet import NudeClassifier
classifier = NudeClassifier('classifier_checkpoint_path')classifier.classify('path_to_nude_image')# {'path_to_nude_image': {'safe': 5.8822202e-08, 'nude': 1.0}}
使用目标检测器:
from nudenet import NudeDetector
detector = NudeDetector('detector_checkpoint_path')# Performing detectiondetector.detect('path_to_nude_image')# [{'box': [352, 688, 550, 858], 'score': 0.9603578, 'label': 'BELLY'}, {'box': [507, 896, 586, 1055], 'score': 0.94103414, 'label': 'F_GENITALIA'}, {'box': [221, 467, 552, 650], 'score': 0.8011624, 'label': 'F_BREAST'}, {'box': [359, 464, 543, 626], 'score': 0.6324697, 'label': 'F_BREAST'}]# Censoring an imagedetector.censor('path_to_nude_image', out_path='censored_image_path', visualize=False)
传送门
GitHub:
https://github.com/bedapudi6788/NudeNet
教程原文 - 图像分类篇:
https://medium.com/@praneethbedapudi/nudenet-an-ensemble-of-neural-nets-for-nudity-detection-and-censoring-d9f3da721e3?sk=e19cdcc610e63b16274dd659050ea955
教程原文 - 目标检测篇:
https://medium.com/@praneethbedapudi/nudenet-an-ensemble-of-neural-nets-for-nudity-detection-and-censoring-c8fcefa6cc92?sk=f0a4786bf005cd4b7e89cf625f109af0
另外,你可能更关心数据集……小哥在Reddit论坛上对网友说,他收集的数据集大约有37GB大,还没有找到地方上传,但“绝对会共享出来”,到时候会在这里更新链接:
https://www.reddit.com/r/MachineLearning/comments/b78j1q/p_nudity_detection_and_censoring_in_images_with/
量子位之前介绍过一些数据集(和模型),先用它们练手也行:
内含20万“不可描述”图片,这个数据集千万别在办公室打开
那个20多万“不可描述”照片的数据集,有人用它做了鉴黄模型 | Demo
150多万张“不可描述”照片数据集新鲜出炉,这次一定不要在办公室打开