目录
1. 什么是布隆过滤器
判断某个key一定不存在
1. 本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构
2. 特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
3. 相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
使用:
- 布隆过滤器在NoSQL数据库领域中应用的非常广泛
- 当用户来查询某一个row时,可以先通过内存中的布隆过滤器过滤掉大量不存在的row请求,然后去再磁盘进行查询
- 布隆过滤器说某个值不存在时,那肯定就是不存在,可以显著降低数据库IO请求数量
2. 应用场景
1)场景1(给用户推荐新闻)
1. 当用户看过的新闻,肯定会被过滤掉,对于没有看多的新闻,可能会过滤极少的一部分(误判)。
2. 这样可以完全保证推送给用户的新闻都是无重复的。
2)场景2(爬虫url去重)
1. 在爬虫系统中,我们需要对url去重,已经爬取的页面不再爬取
2. 当url高达几千万时,如果一个集合去装下这些URL地址非常浪费空间
3. 使用布隆过滤器可以大幅降低去重存储消耗,只不过也会使爬虫系统错过少量页面
3. 布隆过滤器原理
布隆过滤器(Bloom Filter)的核心实现是一个超大的位数组和几个哈希函数。假设位数组的长度为m,哈希函数的个数为k
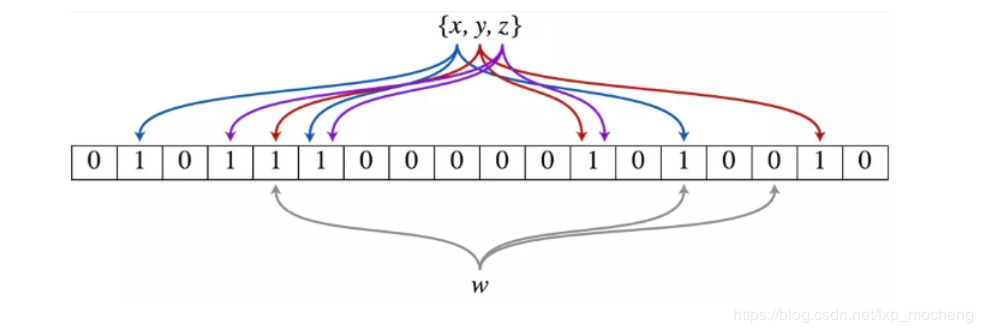
以上图为例,具体的操作流程:假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
添加元素
将要添加的元素给k个哈希函数
得到对应于位数组上的k个位置
将这k个位置设为1
查询元素
将要查询的元素给k个哈希函数
得到对应于位数组上的k个位置
如果k个位置有一个为0,则肯定不在集合中
如果k个位置全部为1,则可能在集合中